2023年8月第3周大模型荟萃
- 2023.8.22
- 版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
1、LLM-Adapters:可将多种适配器集成到大语言模型
来自新加坡科技设计大学和新加坡管理大学的研究人员发布了一篇题为《LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models》的论文。该论文介绍了一种名为 LLM-Adapters 的适配器系列,用于大型语言模型的参数高效微调。该适配器系列可在不影响模型性能的情况下减少微调所需的参数数量,从而提高微调效率。
LLM-Adapters框架设计在研究、efficient、模块化和可扩展方面表现良好,允许集成新的适配器和用新的更大规模的语言模型进行评估。实验结果表明,在简单的数学推理任务上,使用较小规模语言模型的参数高效微调仅需要很少的可训练参数,就能达到强大语言模型在零样本推断中可比的性能。总体而言,LLM-Adapters 框架提供了一个有希望的框架来微调大型语言模型用于下游任务。
2、手机的算力也能运行大模型
开源社区有很多人都在探索大模型的优化方法。有一个叫 llama.cpp 的项目用原始 C++ 重写了 LLaMa 的推理代码,效果极好,获得了人们的广泛关注。GitHub 链接:https://github.com/ggerganov/llama.cpp
通过一些优化和量化权重,它能让我们在各种以前无法想象的硬件上本地运行 LLaMa 模型。其中:
- 在谷歌 Pixel5 手机上,它能以 1 token/s 的速度运行 7B 参数模型。
- 在 M2 芯片的 Macbook Pro 上,使用 7B 参数模型的速度约为 16 token/s
- 我们甚至于可以在 4GB RAM 的树莓派上运行 7B 模型,尽管速度只有 0.1 token/s
3、Candle:Hugging Face 开源的新 ML 框架
GitHub 链接:https://github.com/huggingface/candle,Hugging Face 开源了一款新机器学习框架 Candle,它一改机器学习惯用 Python 的做法,而是 Rust 编写,重点关注性能(包括 GPU 支持)和易用性。
根据 Hugging Face 的介绍,Candle 的核心目标是让 Serverless 推理成为可能。像 PyTorch 这样的完整机器学习框架非常大,这使得在集群上创建实例的速度很慢。Candle 允许部署轻量级二进制文件。另外,Candle 可以让用户从生产工作负载中删除 Python。Python 开销会严重影响性能,而GIL是众所周知的令人头疼的问题。
4、字节跳动的大模型“豆包”正式上线使用
字节跳动的首个AI对话式APP“豆包”及其网页版已在近日上线,目前已开放安卓端的下载通道。豆包APP也就是为此前字节内部代号为“Grace”的AI项目,目前拥有文生文、文生图的功能。
官网主页:https://www.doubao.com/,可使用抖音账号直接扫描二维码使用。我使用了几天,主观感受是挺不错的。而根据字节跳动在大模型投入方面的信息来判断(比如采购10亿美元的英伟达显卡),字节大模型很可能会后来居上,排国内前三问题不大,问鼎也极有可能。
5、科大讯飞大模型演进到2.0
8月15日下午,科大讯飞“如期”在合肥召开了星火认知大模型V2.0升级发布会。按照此前“剧透”,本次升级是在星火1.5版本突破开放式问答、数学能力和多轮对话能力基础上的再一次飞跃,重点在代码能力、多模态交互能力上取得重大突破,同时发布了面向老师、学校、企业、开发者等多元的应用落地产品。
作为一名讯飞星火大模型的中度/重度用户,我个人的体会是:星火大模型从V1.0升级到V1.5,再从V1.5升级到V2.0,我的主观使用感受是大模型的智力没有任何提升,仍然时不时会出现答非所问,乱答一通的现象。而讯飞星火的两次大升级,真正明显进步的是大模型的应用场景和应用产品增加了,比如新增了编程助手iFlyCode。一句话,是大模型业务数量的增加。
6、GPT-4 新增内容审核能力
最近OpenAI表示,其开发了一种使用GPT-4进行内容审核的解决方案,有望减轻人工审核员的负担。将GPT-4用于内容策略开发和内容审核决策,从而实现更一致的标记、更快的策略优化反馈循环,以及减少人工审核人员的参与。内容审核在维持数字平台的健康方面发挥着至关重要的作用。使用GPT-4的内容审核系统可以更快地迭代策略更改,将周期从几个月缩短到几个小时。GPT-4还能够解释长内容策略文档中的规则和细微差别,并立即适应策略更新,从而实现更一致的标记。。
7、艾伦AI推出业界最大文本数据集Dolma
艾伦AI研究所(AI2)于8月19日在其官方博客发布用于训练大型语言模型(LLM)的文本数据集Dolma,包含3万亿个Tokens(词例),是迄今为止最大的开放文本数据集。
AI2声称,在AI竞争激烈的当下,大部分科技巨头都倾向于保守自家大模型开发的机密。而AI2公司希望通过公开透明化其数据集及之后的大模型,帮助更多的研究者在此基础上进一步进行研究和开发等工作。

8、Meta将推出免费版编程工具
Meta即将于下周推出一款开源AI软件Code Llama,旨在帮助开发人员自动生成编程代码,是继Llama 2大语言模型后又一项可能颠覆人工智能领域的大胆举措。Code Llama将“暴力对标”OpenAI旗下的Codex模型,并较Meta的开源大语言模型Llama 2显著增强。Code Llama的开源属性将令企业用户更容易开发自有AI助手,后者可在开发人员键入时自动推荐代码,并与由Codex支持的微软GitHub Copilot等付费编程助手工具争夺客户。
有分析称,企业用户可能更倾向于使用开源的编程模型来开发自己的编程助手,以期保护其源代码。生成自动代码建议一直是大语言模型的最流行用途之一。Code Llama等开源模型可以帮助业内后起之秀更快地参与竞争,也令担心源代码安全的大公司更容易建构自己的内部模型,令外部付费供应商变得冗余,直接颠覆了行业动态。


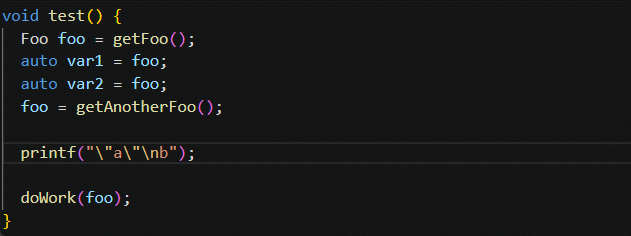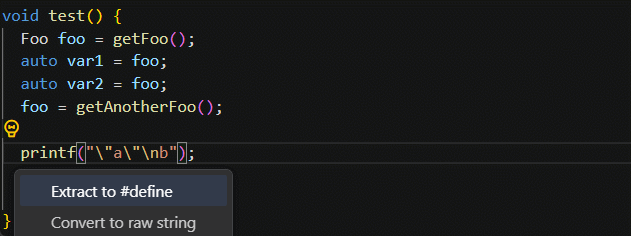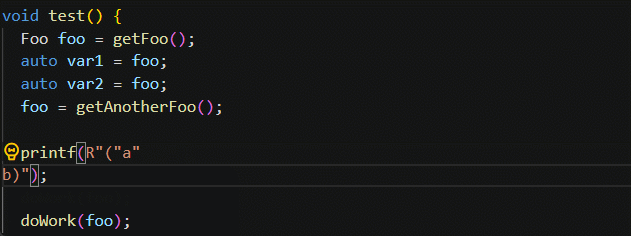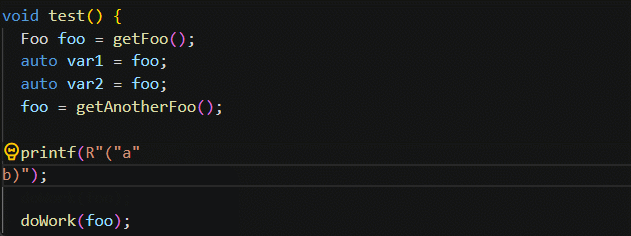



![java八股文面试[java基础]——final 关键字作用](https://img-blog.csdnimg.cn/551c0546795d4fba9e2b18a5fdc77b75.png)


![[保研/考研机试] KY124 二叉搜索树 浙江大学复试上机题 C++实现](https://img-blog.csdnimg.cn/597052c09e38465a885e775ff4caafeb.png)