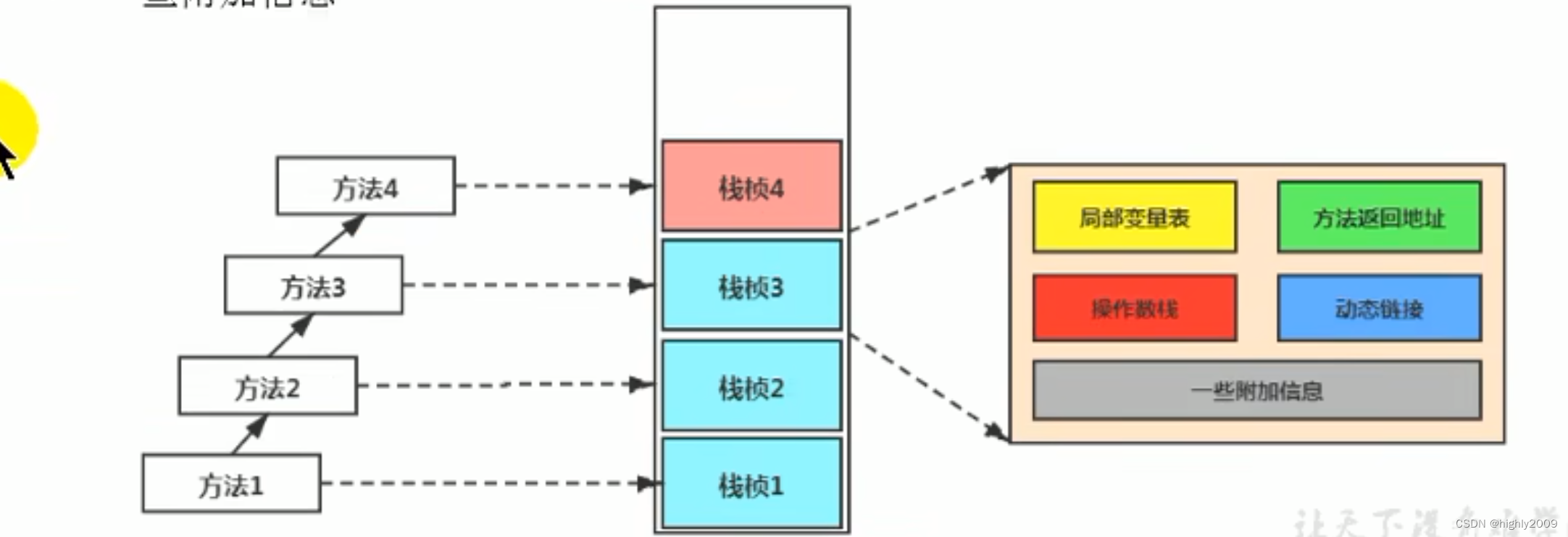
目录
前言
一、概述
1、什么是shell?
2、shell脚本的用途有哪些?
3、常见的shell有哪些?
4、学习shell应该从哪几个方面入手?
4.1、表达式
1)变量
2)运算符
4.2、语句
1)条件语句:
a)单分支if
b)双分支if
c)多分支if
2)分支语句:
a)使用shell脚本编写Nginx启停命令
3)循环语句:
4.3、函数
4.4、正则表达式
1)基础正则
a)查找特定字符
b)利用[]查找集合字符
c)查找行首"^"与行尾"$"
编辑
2)扩展正则
a)+,重复一个或一个以上的前一个字符
b)?,零个或者一个前一个字符
c)|,使用或者的方式找出多个字符
d)(),查找组字符串
e)()+,辨别多个重复的组
3)常见正则表达式
a)数字
b)字符串
c)Email
d)Url
e)IP
f)Tel
g)日期校验
4.5、文件操作四剑客
1)grep进阶
2)egrep
3)find进阶
4)sed
a)语法
b)选项
c)操作
d)案例
5)awk
a)语法
b)选项
c)内建变量
d)案例:
5、使用shell脚本应该注意些什么?
5.1、shell命名
5.2、常见的shell脚本编写规范
5.3、shell脚本
5.4、shell运行规则
5.5.、 shell脚本运行追踪
6、read -p "提示语" 变量名
7、拓展知识
7.1、返回100内随机数
7.2、返回1到10 的连续数字
7.3、返回1.1 2.1 3.1.... 10.1
二、表达式
1、变量
1.1、组成
1.2、类型
1)系统内置变量(环境变量)
2)自定义变量
3)位置变量
4)预定义变量
1.3、作用域
1.4、输出
1.5、shell中的字符串
2、运算符
2.1、数学运算
2.2、赋值
2.3、比较运算
1)数值比较
2)字符串比较
3)文件比较
2.4、逻辑运算符
总结
前言
纯属本人个人看法,目前对shell脚本也是一知半解,经过查阅资料,整理内容,写出这篇shell脚本基础,大多数内容简单易懂,可能会篇幅略长,请耐心观看。
一、概述
1、什么是shell?
Shell脚本是一种用于执行一系列命令的脚本程序。它由一系列Shell命令组成,可以自动化执行一些任务或操作。Shell脚本通常由文本文件组成,其中包含一系列命令,这些命令按照顺序执行。
2、shell脚本的用途有哪些?
Shell脚本可以在Unix、Linux和类Unix系统(如Mac OS)中使用。它们使用Shell解释器来执行命令,并且支持多种Shell解释器,如Bash、Sh、Ksh等。
Shell脚本的目的可以是自动化常见任务,例如文件操作、系统管理、软件安装和配置等。它们可以接受命令行参数、进行条件判断和循环操作,还可以利用变量、函数和控制流语句来实现更复杂的逻辑。
编写Shell脚本需要具备一些基本的Shell编程知识,包括如何声明变量、使用条件语句、创建循环和函数等。脚本还可以利用系统提供的各种命令和工具来完成特定的任务。
3、常见的shell有哪些?
常见的Shell脚本文件扩展名包括.sh(Bash脚本)、.sh、.ksh、.csh等,可以在Shell命令行中运行脚本文件,也可以将其配置为可执行文件并直接运行。
Bourne Shell (sh):Bourne Shell是Unix操作系统中最早的原始shell,它提供了基本的命令和功能。它的特点是简单、高效,但功能相对有限。
Bourne Again Shell (bash):Bash是Bourne Shell的改进版本,也是目前最常用的shell。它保留了Bourne Shell的特性,并增加了许多新功能,如命令补全、历史命令、条件语句等,使得用户交互更方便、功能更强大。
C Shell (csh):C Shell是以C语言为基础的shell,它提供了许多C语言风格的语法和功能,如循环、条件判断、命令别名等。C Shell在交互性和用户友好性方面有所提升。
Korn Shell (ksh):Korn Shell是基于Bourne Shell的一个进化版本,它兼容Bourne Shell,并添加了许多新特性,如数组、命令行编辑等。Korn Shell是一种功能强大且通用的shell,被广泛用于类Unix系统。
Z Shell (zsh):Z Shell是Bourne Shell的扩展版本,它增加了更多的功能和特性,并提供了更好的用户交互体验。Z Shell支持命令补全、自动纠正命令、自定义主题等,使得使用起来更加方便和高效。
4、学习shell应该从哪几个方面入手?
4.1、表达式
1)变量
变量是计算机编程中用来存储和表示数据的一个名称,可以将其视为一个容器,用于存储各种类型的值。变量在程序中可以被多次使用,并且可以在其中存储不同的数据。
(个人感觉)归根结底变量可分为三大类:
系统变量:系统变量是指在操作系统中预先定义的变量,用于存储一些系统级的信息或配置。系统变量可以被所有的程序或用户访问和使用。
环境变量:环境变量是在操作系统中定义的一种特殊变量,用于存储系统的各种配置信息、路径和运行时参数。环境变量可以通过操作系统设置或在程序中动态定义和使用,对整个操作系统和所有程序起作用。常见的环境变量有PATH、HOME等。
echo $PATH 命令所示路径,以冒号为分割;
echo $HOME 打印用户家目录;
echo $SHELL 显示当前Shell类型;
echo $USER 打印当前用户名;
echo $ID 打印当前用户id信息;
echo $PWD 显示当前所在路径;
echo $TERM 打印当前终端类型;
echo $HOSTNAME 显示当前主机名;
echo $PS1 定义主机命令提示符的;
echo $HISTSIZE 历史命令大小,可通过 HISTTIMEFORMAT 变量设置命令执行时间;
echo $RANDOM 随机生成一个 0 至 32767 的整数;
echo $HOSTNAME 主机名
用户变量:用户变量是指在特定用户环境中定义的变量,用于存储用户自己的信息或配置。这些变量通常具有用户自定义的名称,并且只对该用户有效。用户变量可以用于个性化定制用户的工作环境。
从上述类别分别延伸出以下变量类别:
位置变量:位置变量是指在程序中根据其在参数列表中的位置来进行传递的变量。当程序调用函数或方法时,传递的参数可以按顺序对应函数或方法定义中的参数位置。在命令行中执行程序时,也可以通过位置参数传递数据。
自定义变量:自定义变量是程序员自己声明和定义的变量,用于存储数据或表示特定的值。自定义变量的命名由开发者自己决定,可以根据需要进行赋值和操作。
整型变量(int):整型变量用于存储整数值,可以进行基本的数值运算。整数可以是正数、负数或零。例如,x = 5,y = -10。
浮点型变量(float):浮点型变量用于存储带有小数点的数值,也可以进行数值运算。例如,x = 3.14,y = -0.25。
字符串变量(str):字符串变量是用来存储文本或字符序列的数据类型。字符串需要被包裹在引号(单引号或双引号)内。例如,x = "Hello",y = 'World'。
布尔型变量(bool):布尔型变量是用来存储真(True)或假(False)的数据类型。它主要用于控制流程和条件判断。例如,x = True,y = False。
预定义变量是指在程序执行过程中由解释器或其他库定义的变量。它们是一些特殊的变量,事先已经定义好,并具有特定的含义。在Linux操作系统中,一些常见的预定义变量包括:
ARGV:表示命令行参数的列表。
argc:表示命令行参数的数量。
ENV:表示操作系统的环境变量。
等等还有很多,这里就不一一列举了。
2)运算符
| 算术运算符 | 用于执行数学运算,如加法、减法、乘法、除法等。 常见的算术运算符有 |
| 比较运算符 | 用于比较两个值或表达式的大小、相等性等关系。 常见的比较运算符有 |
| 逻辑运算符 | 用于对布尔值进行逻辑运算。 常见的逻辑运算符有 |
| 赋值运算符 | 用于将一个值赋给一个变量。 常见的赋值运算符有 |
| 成员运算符 | 用于判断一个值是否属于一个集合(列表、元组、字典、集合等)。 常见的成员运算符有 |
| 身份运算符 | 用于比较两个对象的内存地址是否相同。 常见的身份运算符有 |
| 位运算符 | 用于对二进制数进行位级操作。 常见的位运算符有 |
4.2、语句
1)条件语句:
a)单分支if
使用方式:
if condition;then
command;
fi
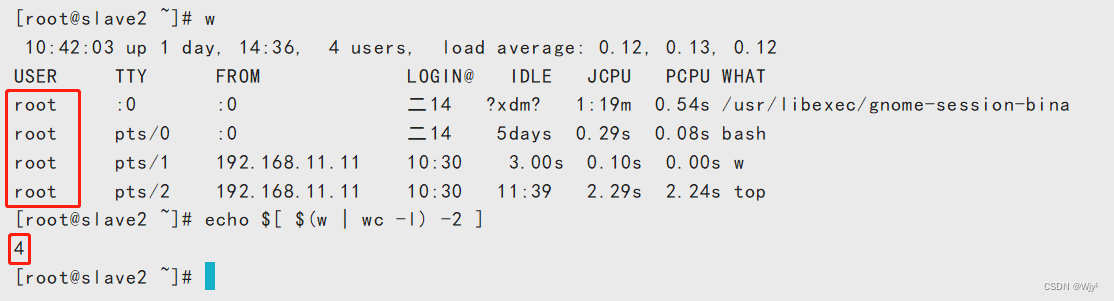
编写脚本查看
#!/bin/bash
#条件语句
#定义一个变量方便后续使用
user_num=$[ $(w | wc -l) -2 ]#单分支if
if [ $user_num -gt 2 ];thenecho "当前登录过多!"
fi

赋予执行权限并进行检查

b)双分支if
使用方式:
if condition;then
command;
else
command;
fi
#!/bin/bash
#条件语句
#定义一个变量方便后续使用
user_num=$[ $(w | wc -l) -2 ]#双分支if
if [ $user_num -gt 5 ];thenecho "当前登录过多!"
elseecho "当时登录用户适中!"
fi


c)多分支if
使用方式:
if condition;then
command;
elif
condition;then
command;
elif
condition;then
command;
else
command;
fi
#!/bin/bash
#多分支if#设定一个数值范围
#A:90~100
#B:80~89
#C:60~79
#D:0~59read -p "请输入你要查询的成绩:" score
if [ $score -lt 0 -o $score -gt 100 ];thenecho "输入错误!请输入0~100的数字进行查询"$0
elseif [ $score -ge 90 -a $score -le 100 ];thenecho "等级:A 评定:优秀"elif [ $score -ge 80 -a $score -le 89 ];thenecho "等级:B 评定:良好"elif [ $score -ge 60 -a $score -le 79 ];thenecho "等级:C 评定:及格"elseecho "等级:D 评定:不及格"fi
fi

2)分支语句:
case
使用方式:
case $1 in
条件1)
语句
;;
条件2)+-+
语句
;;
*)
帮助信息
;;
esac
使用 case 编辑一个简单的shell脚本:
#!/bin/bash
#简单的case使用方式case $1 in
[0-9])echo "数字"
;;
[a-z]|[A-Z])echo "字母"
;;
*)echo "只能输入数字或字母!请重新输入:"
;;
esac

这里显示11、aa、AA均不可用,因为我们在定义时,只定义了单数字或字母的查询,如果需要显示多数字或字母可以:
#!/bin/bash
#简单的case使用方式case $1 in
[0-9]|[0-9][0-9])echo "数字"
;;
[a-z]|[a-z][a-z]|[A-Z]|[A-Z][A-Z])echo "字母"
;;
*)echo "只能输入数字或字母!请重新输入:"
;;
esac

a)使用shell脚本编写Nginx启停命令
刚才的脚本是一个简单的case使用脚本,接下来我们配置一个简单的 nginx 启停脚本:
第一步:下载源码包进行编译安装
nginx官方网站:nginx news
第二步:将下载好的软件包放置在虚拟机中
第三步:解压归档包并进行编译安装
tar xf nginx-1.20.2.tar.gz
cd nginx-1.20.2/
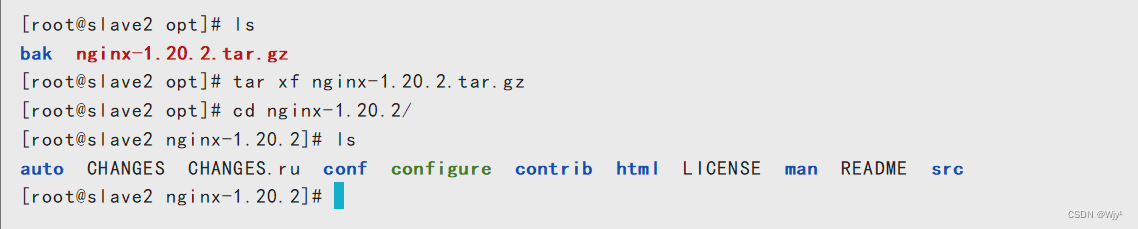
./configure --prefix=/usr/local/nginx
依次补全缺失的依赖:( ps:每次补全缺失的依赖时,需要再次进行一次上述./conmfig ...命令检查是否缺失依赖,如有缺失,需执行下述命令进行补充)
yum install -y pcre-devel
yum install -y zlib-devel
编译安装:
make && make install

安装 nginx 时指定的路径,nginx 启动脚本所在位置:

进入 /etc/init.d/ 编辑我们自己的启停脚本
/etc/init.d/目录解析:
/etc/init.d目录是用于存放系统启动和停止的脚本文件的目录。这些脚本文件通常在系统启动和关闭过程中被执行,用于启动和停止各种系统服务和进程。这些脚本文件可以包含启动、关闭、重启和卸载等不同的操作,通过在相应的运行级别(runlevel)中执行,控制系统服务的启动和停止。
创建脚本
vim /etc/init.d/ngninx
#!/bin/bash
#Nginx启停脚本( start | stop | restart | reload ),支持多台Nginx同时启动。
#Mr.王#定义服务启动优先级
#chkconfig: 35 85 75#定义变量
NGINX="/usr/local/nginx/sbin/nginx"
ProfilePath=$2#使用定义if语句(双分支)定义函数if [ -z $ProfilePath ];thenfunction start(){$NGINX}function stop(){$NGINX -s stop}function reload(){$NGINX -s reload}elsefunction start(){$NGINX -c $ProfilePath}function stop(){$NGINX -s stop -c $ProfilePath}function reload(){$NGINX -s reload -c $ProfilePath}fi
#设置开关语句case $1 instart)startif [ $? -eq 0 ];thenecho "+---------------------------------------------+"echo -e "|服务正在启动 ------> OK! |"echo "+---------------------------------------------+"elseecho "+---------------------------------------------------------+"echo "|服务已启动或出现其他故障,请依据提示信息进行排查! |"echo "+---------------------------------------------------------+"fi;;stop)stop 2> /dev/nullif [ $? -ne 0 ];thenecho "+----------------------------------+"echo "|服务器未启动,不需要停止! |"echo "+----------------------------------+"elseecho "+----------------------------------+"echo "|服务正在停止 ------> OK! |"echo "+----------------------------------+"fi;;reload)reloadif [ $? -eq 0 ];thenecho "+-------------------------------------+"echo "|平滑加载配置文件中 ------> OK! |"echo "+-------------------------------------+"elseecho "+-----------------------------------------------------+"echo "|服务未启动或者加载失败,请依据错误信息进行排查! |"echo "+-----------------------------------------------------+"fi;;restart)stop 2> /dev/null && startif [ $? -eq 0 ];thenecho "+-------------------------------------------------------+"echo "|服务重启成功,正在加载 -------> |"echo "| 服务加载完毕,Nginx 启动!|"echo "+-------------------------------------------------------+"elseecho "+-----------------------------------------------------+"echo "|服务未启动或者加载失败,请依据错误信息进行排查! |"echo "+-----------------------------------------------------+"fi;;*)echo "+---------------------------------------------------------------------+"echo "|请输入正确选项: $0 | start | stop | restart | reload |"echo "+---------------------------------------------------------------------+";;esac
脚本写完以后,赋予其执行权限,对其进行检测,看其是否正常工作
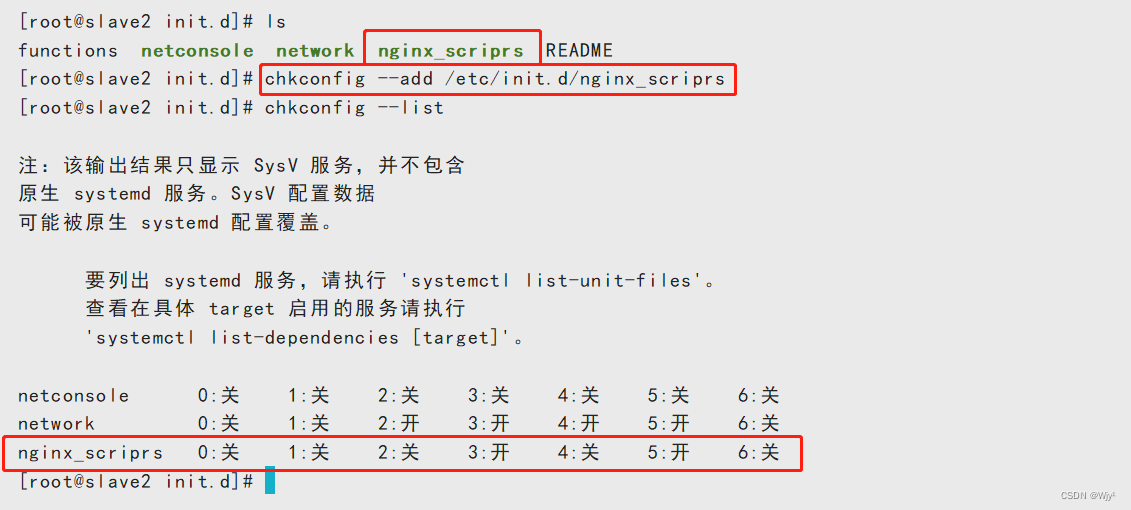
chmod +x /etc/init.d/nginx_scriprs

两种启停方式:
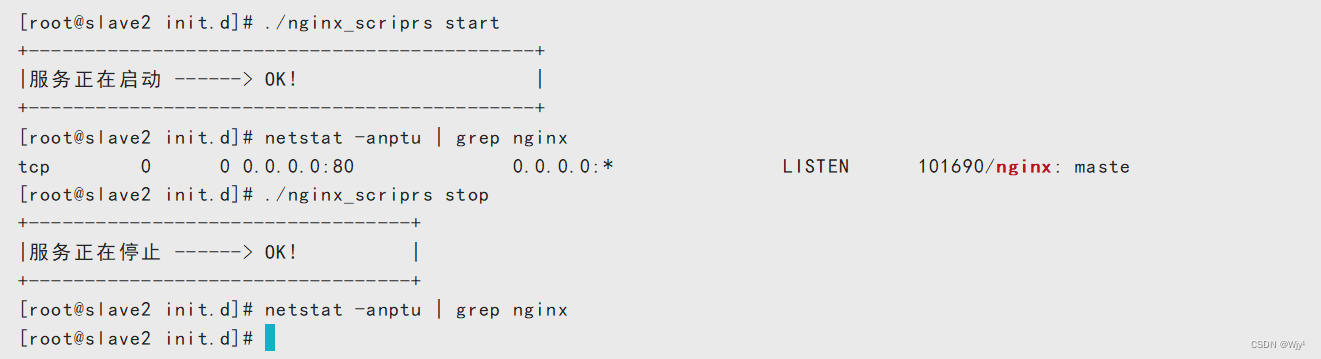
./nginx_scriprs start
./nginx_scriprs stop
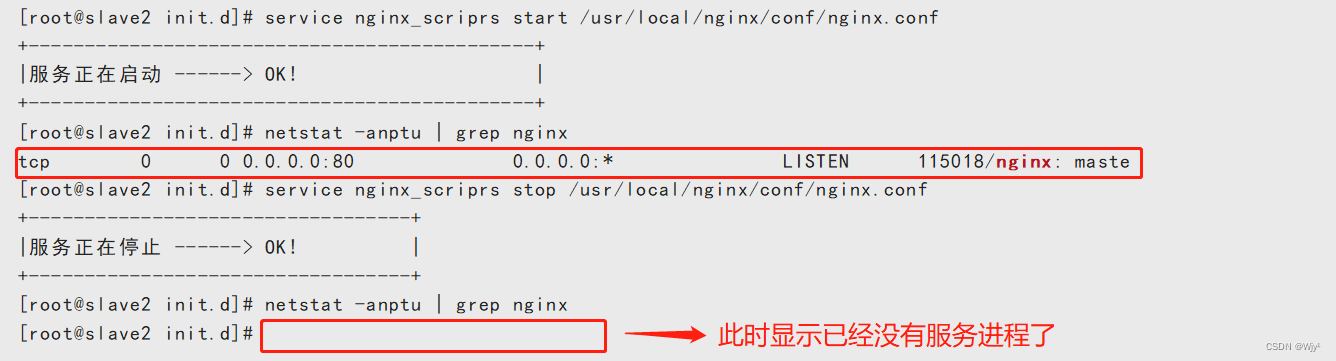
service nginx_scriprs start /usr/local/nginx/conf/nginx.conf
service nginx_scriprs stop /usr/local/nginx/conf/nginx.conf
重启: 
重载配置文件:
./nginx_scriprs reload
service nginx_scriprs reload /usr/local/nginx/conf/nginx.conf
启动前先关闭服务,不然报错信息显示不出来

然后将脚本交给 server 服务管理
随便进行输入,检测语句定义最后一个提醒内容:
./nginx_scriprs aaaaaaaaaaaa

至此,我们自己的Nginx启停脚本就已编写完毕,经测试,已经可以正常使用了。
3)循环语句:
for
for循环由while循环演变
for 条件(i in 值)|((i=1;i<=10;i++))
do
语句
done
while
i=1
while 条件
do
语句
let i++
done
4.3、函数
在shell脚本中,有以下几种类型的函数:
内置的函数:这些函数是shell特定的,可以直接调用。例如,echo、cd、pwd等。这些函数通常用于执行基本的系统操作。
自定义函数:这些函数是由用户自己定义的,用于封装一系列的操作,以便在脚本中多次调用。自定义函数以关键字
function或函数名开头,并在{}中包含函数的具体操作。
外部命令函数:这些函数实际上是调用外部命令或脚本文件。可以使用
source或.来加载外部脚本文件,然后在脚本中调用外部脚本中的函数。
匿名函数(匿名代码块):在某些shell解释器中,可以使用
{}来定义一个匿名函数或匿名代码块,然后在脚本中直接调用。
需要注意的是,不同的shell解释器可能对函数的定义和调用方式有所不同。例如,Bash和Korn Shell(ksh)中的函数定义使用关键字
function,而在其他Shell中,可以直接使用函数名进行定义。
4.4、正则表达式
正则表达式(Regular Expression)是一种用于匹配、搜索和处理文本的强大工具,它可以通过一种简洁的语法描述模式,并与文本进行匹配。
标准正则和扩展正则是正则表达式中的两种语法标准。
标准正则是指符合基本正则表达式语法标准的正则表达式。基本正则表达式语法只包含最基本的元字符和操作符,例如*、+、.等。标准正则通常用于一些较旧的工具和操作系统中,如grep、sed等。
扩展正则是在标准正则的基础上扩展出来的更加强大和丰富的正则表达式语法。扩展正则语法引入了更多的元字符和操作符,例如{}、()、|等。扩展正则通常用于一些较新的工具和操作系统中,如egrep、awk等。
需要注意的是,不同的工具和操作系统对正则表达式的支持可能有所差异,有些工具可能支持扩展正则,有些工具可能只支持标准正则。因此在使用正则表达式时需要根据具体的工具和环境选择合适的语法标准。
在Shell基础中,正则表达式通常用于以下操作:
模式匹配:使用正则表达式可以匹配文本中符合某种模式的字符串。例如,可以使用正则表达式匹配所有以字母开头的单词。
字符串搜索和替换:使用正则表达式可以在文本中搜索符合某种模式的字符串,并进行替换或修改。例如,可以使用正则表达式找到文本中的所有数字,并替换为特定字符串。
字符串分割和提取:使用正则表达式可以将一个字符串分割成多个部分,或者提取出符合某种模式的子字符串。例如,可以使用正则表达式将一个CSV格式的文本分割成多个字段。
常见的正则表达式元字符包括:
字符类:用方括号
[]括起来,例如[abc]表示匹配单个字符a、b或c。元字符:具有特殊含义的字符,例如
.表示匹配任意字符,*表示匹配前一个字符的零个或多个重复,+表示匹配前一个字符的一个或多个重复等。量词:用于指定匹配的数量,例如
{n}表示精确匹配n次,{m,n}表示匹配至少m次至多n次。锚点:用于指定匹配的位置,例如
^表示匹配字符串开头,$表示匹配字符串结尾。转义字符:用于取消元字符的特殊含义,例如
\可以将特殊字符转义为普通字符。在Shell中,常用的正则表达式匹配工具包括
grep、sed和awk等命令。这些工具可以结合正则表达式来处理文本数据,并实现各种功能,如文本搜索、替换和处理等。
1)基础正则
创建一个文件用于适配下列各项,内容如下:
shirt
short
good
food
wood
wooooooood
gooood
adcxyzxyzxyz
abcABC
best
besssst
ofion
ofson
ofison
AxyzxyzC
test
tast
hoo
boo
joo
a)查找特定字符
cat 1 | grep -n 'good'

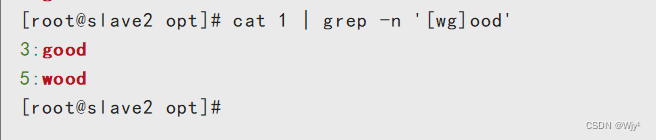
b)利用[]查找集合字符
cat 1 | grep -n '[wg]ood'
匹配 g 或者 w
cat 1 | grep -n '[^o]'
排除o

这里显示排除不掉,因为符合条件 o 的还有很多
cat 1 | grep -n '[^hbjo]'
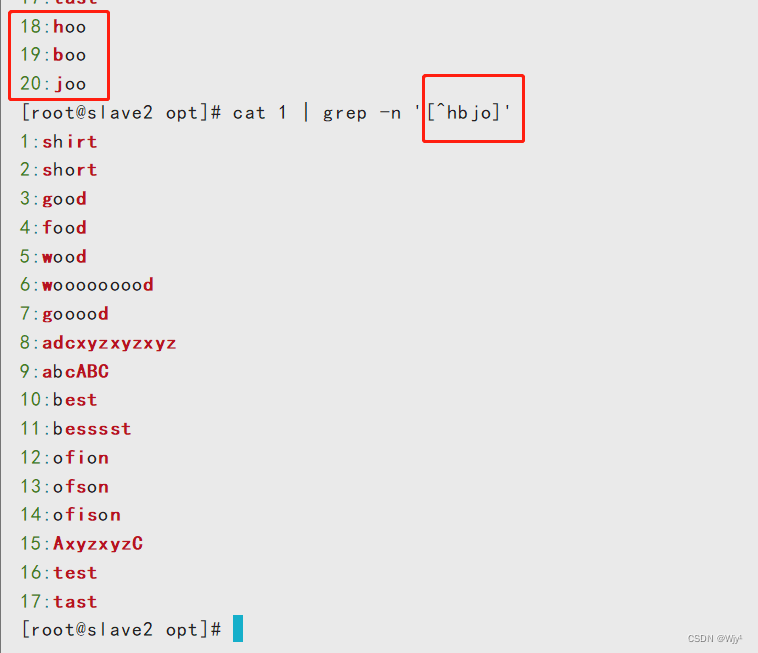
cat 1 | grep -n '[a-z]oo'

cat test.txt | grep -n '[0-9]'
c)查找行首"^"与行尾"$"
cat 1 | grep -n '^[g]'

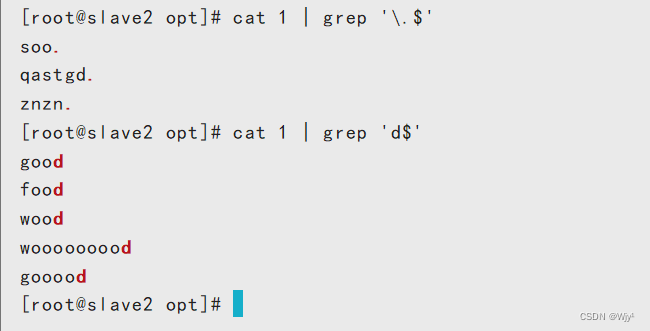
cat 1 | grep '\.$'
cat 1 | grep 'd$'
\ 为转义符
d)查找任意一个字符"."与重复字符"*"
cat 1 | grep -n 'g..d'

cat 1 | grep -n 'ooo*'

e)查找连续的字符范围"{}",需要使用转义符,"\{\}"
cat 1 | grep -n 'o\{2\}'

cat 1 | grep -n 'o\{2,5\}d'
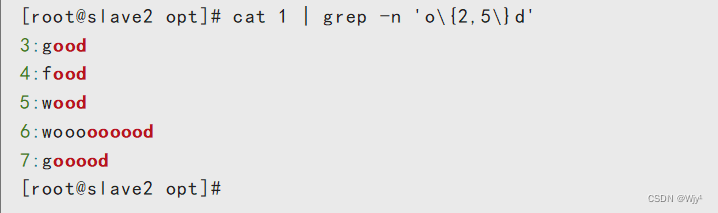
cat 1 | grep -n 'o\{2,\}d'

2)扩展正则
a)+,重复一个或一个以上的前一个字符
cat 1 | grep -nE 'wo+d'
cat 1 | egrep -n 'wo+d'

b)?,零个或者一个前一个字符
cat 1 | egrep -n 'goo?d'

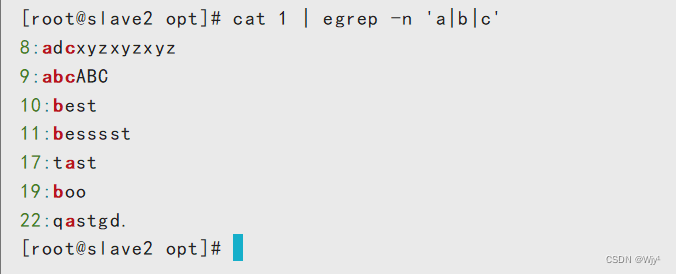
c)|,使用或者的方式找出多个字符
cat 1 | egrep -n 'a|b|c'
d)(),查找组字符串
cat 1 | egrep -n 't(a|e|s)st'

e)()+,辨别多个重复的组
cat 1 | egrep -n 'A(x|y|z)+C'

3)常见正则表达式
a)数字
创建随机正整数,负正整数,正浮点数,负浮点数,用做实验
echo $[$RANDOM%100] > 2
echo $[$RANDOM%100] >> 2
echo -$[$RANDOM%100] >> 2
echo -$[$RANDOM%100] >> 2
echo -$[$RANDOM%100].1 >> 2
echo -$[$RANDOM%100].1 >> 2
echo $[$RANDOM%100].1 >> 2
echo $[$RANDOM%100].1 >> 2
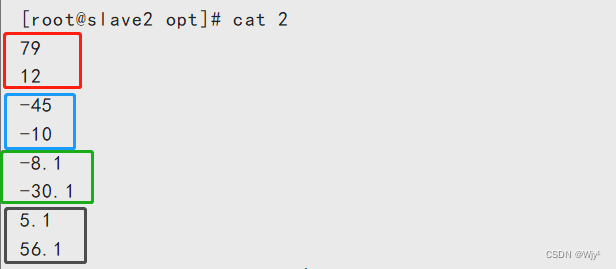
“^[0-9]*[1-9][0-9]*$” //正整数
cat 2 | grep "^[0-9]*[1-9][0-9]*$"
“^((-\d+)|(0+))$” //非正整数(负整数 + 0)
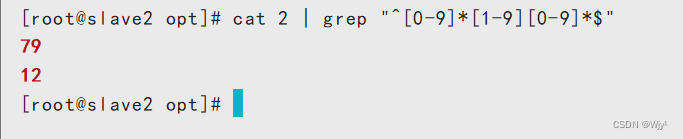
“^-[0-9]*[1-9][0-9]*$” //负整数
cat 2 | grep "^-[0-9]*[1-9][0-9]*$"

“^-?\d+$” //整数
“^\d+(\.\d+)?$” //非负浮点数(正浮点数 + 0)
“^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$” //正浮点数
“^((-\d+(\.\d+)?)|(0+(\.0+)?))$” //非正浮点数(负浮点数 + 0)
“^(-?\d+)(\.\d+)?$” //浮点数
b)字符串
“^[A-Z]+$” //由26个英文字母的大写组成的字符串
“^[a-z]+$” //由26个英文字母的小写组成的字符串
“^[A-Za-z0-9]+$” //由数字和26个英文字母组成的字符串
“^\w+$” //由数字、26个英文字母或者下划线组成的字符串
c)Email
“^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$” //email地址
“^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$” //Email
d)Url
“^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$” //url
e)IP
“^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$” //IP地址
f)Tel
/^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9]+)?$/ //电话号码
g)日期校验
/^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日 yyyy-MM-dd / yy-MM-dd 格式
"^[0-9]{4}-((0([1-9]{1}))|(1[1|2]))-(([0-2]([0-9]{1}))|(3[0|1]))$" // 年-月- 日 yyyy-MM-dd 格式
/^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年
4.5、文件操作四剑客
文件操作四剑客指的是Linux/Unix系统中的四个常用命令/工具,包括grep、awk、sed和find。这些工具都是用来处理文本文件的,可以通过各种方式查找、过滤和修改文件内容,是Linux/Unix系统中非常强大和灵活的工具。
grep:grep命令用于在文本中搜索匹配指定模式的行,并将其打印出来。可以使用正则表达式进行模式匹配,支持在多个文件中搜索,具有强大的过滤和查找功能。
awk:awk是一种数据处理和报表生成语言,也是一个命令行工具。它可以用来从文本文件中提取和处理数据,支持对文件的逐行扫描和处理,可以根据分隔符对数据进行分割,并根据需要进行计算和格式化输出。
sed:sed是一种流编辑器,用于对文本文件进行流式编辑。它可以按照指定的规则对文件进行替换、删除、插入和追加等操作。sed具有强大的文本转换和处理能力,是文本处理中的重要工具。
find:find命令用于在指定目录下搜索满足指定条件的文件,并将其找出来。可以通过文件名、文件类型、文件大小、修改时间等多种条件进行查找。find命令还可以与其他命令配合使用,实现更复杂的文件操作。
这四个工具在Linux/Unix系统中广泛应用于文本处理、数据分析、系统管理等场景,可以大大提高工作效率和操作灵活性。
1)grep进阶
选项
-r 递归扫描指定目录下的每一个文件
-l 只显示匹配到指定关键字的文件名,而不是文件内容
案例
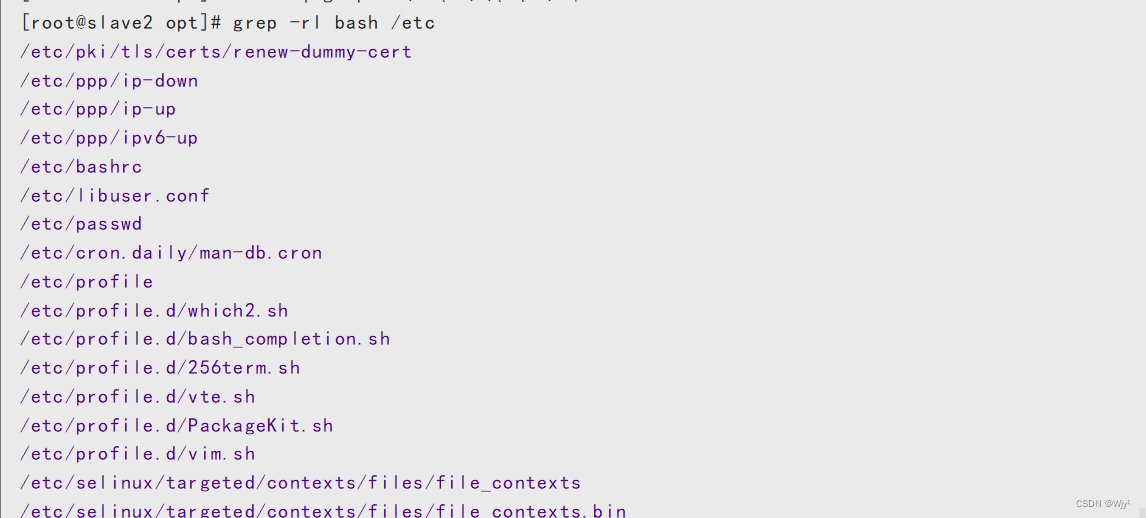
查看/etc目录下所有包含bash的文件名
grep -rl bash /etc
2)egrep
完美支持正则表达式
egrep(扩展的grep)是grep命令的一个变种,用于在文本文件中搜索匹配指定模式的行。它支持更广泛的正则表达式语法,以及一些额外的功能。
与grep相比,egrep支持以下扩展的正则表达式元字符:
|:用于指定多个模式之间的"或"关系。():用于分组模式。+:表示前面的模式出现一次或多次。?:表示前面的模式出现零次或一次。*:表示前面的模式出现零次或多次。{n}:表示前面的模式出现恰好 n 次。{n,}:表示前面的模式出现至少 n 次。{n,m}:表示前面的模式出现 n 到 m 次。此外,egrep还提供了一些命令行选项,如-i(忽略大小写)、-v(反向匹配)等。
总的来说,egrep比grep更强大,更灵活,可以处理更复杂的模式匹配需求。但在许多系统中,grep和egrep是等效的,可互换使用。
3)find进阶
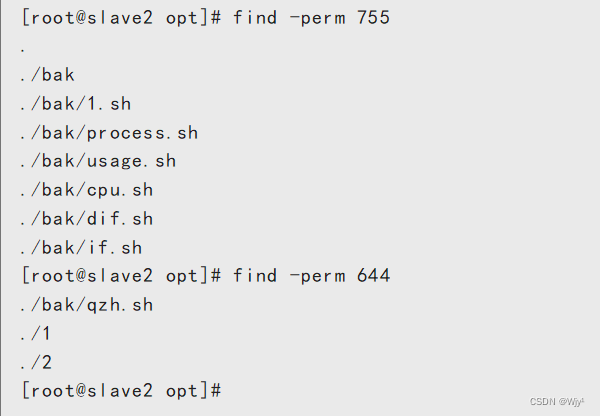
按照权限查找
find -perm 755
find -perm 644
按照时间戳查找
find -atime 1
find -mtime 1
find -ctime 1
 -exec:
-exec:
-exec是 find 命令自带的一个参数,用于执行一条命令来处理每一个查找到的文件(或目录)。对于每一个匹配到的文件,都会调用一次命令,因此速度较慢。
find /opt/zn/ -type f -exec ls -lh {} \;
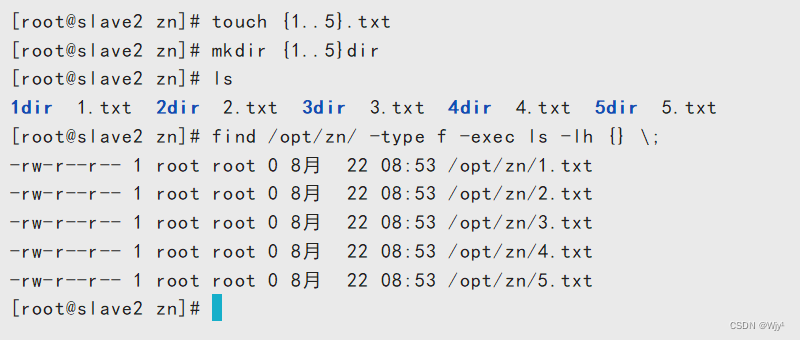
xargs:
而 xargs 是一个独立的命令,它可以从标准输入中读取数据,并将其作为参数传递给其他命令执行。相比于 -exec,xargs 可以批量处理文件,速度更快。
find /opt/zn/ -type f | xargs rm -rf

注:结合上述,如果需要逐个处理每个文件,可以使用 -exec;如果需要批量处理文件,可以使用 xargs。
4)sed
a)语法
sed [选项] '操作' 参数
sed [选项] -f scriptfile 参数
b)选项
-e:表示用指定命令或脚本处理
-f:指定脚本文件
-h:帮助
-n:表示仅显示处理后的结果
-i:直接编辑文本文件
-r:支持扩展正则
c)操作
a:增加,在当前行下面以行增加指定内容
c:替换,将选定行替换
d:删除,删除指定行
i:插入,在选定行的上面插入一行
p:打印
s:替换,替换指定字符
y:字符转换
d)案例
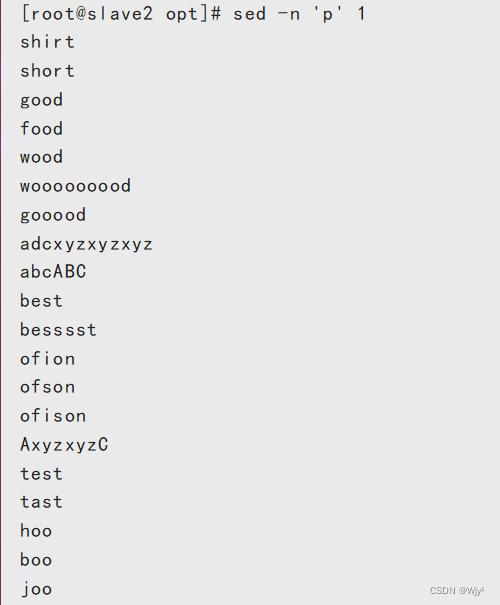
1.输出符合条件的文本:
相当于cat
sed -n 'p' 1
打印第3行
sed -n '3p' 1

打印第3到6行的内容
sed -n '3,6p' 1

打印奇数行
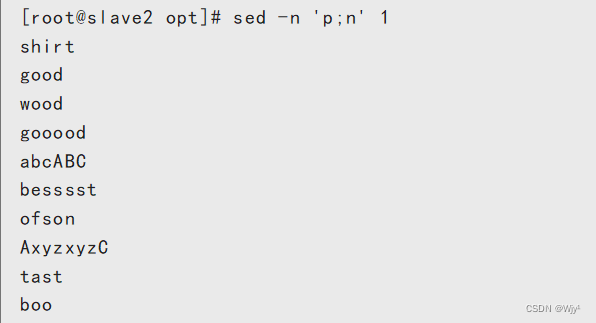
打印偶数行
sed -n 'n;p' 1
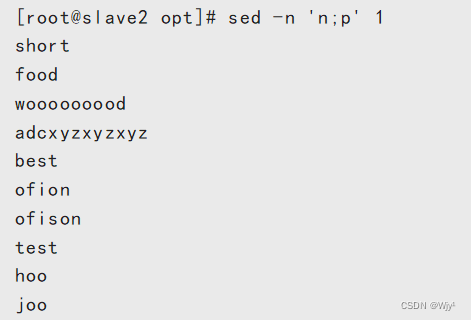
打印1到6行之间的奇数行
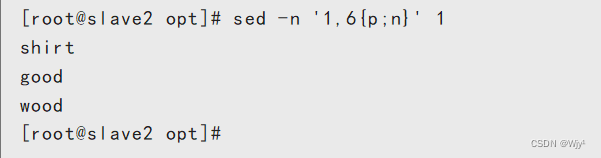
sed -n '1,6{p;n}' 1
从第5行开始打印奇数行
sed -n '5,${p;n}' 1

匹配 abc
sed -n '/abc/p' 1
匹配从第5行开始到包含 oo 的行
sed -n '5,/oo/p' 1

sed -n '/the/,10p' test.txt #匹配从包含the的行到第10行结束
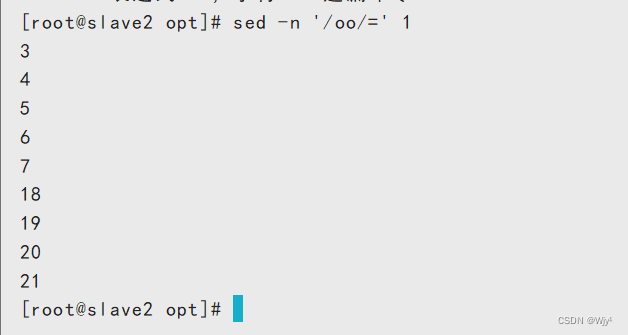
打印包含 oo 的行号
sed -n '/oo/=' 1
2.删除符合条件的文本
删除第1行
nl 1 | sed '1d'

范围删除1-20行
nl 1 | sed '1,20d'

注:删除时不能跳着进行删除,不然会进行报错。例如:
nl 1 | sed '1,3,5d'

删除 good 所在行
nl 1 | sed '/good/d'

3.替换符合条件的文本
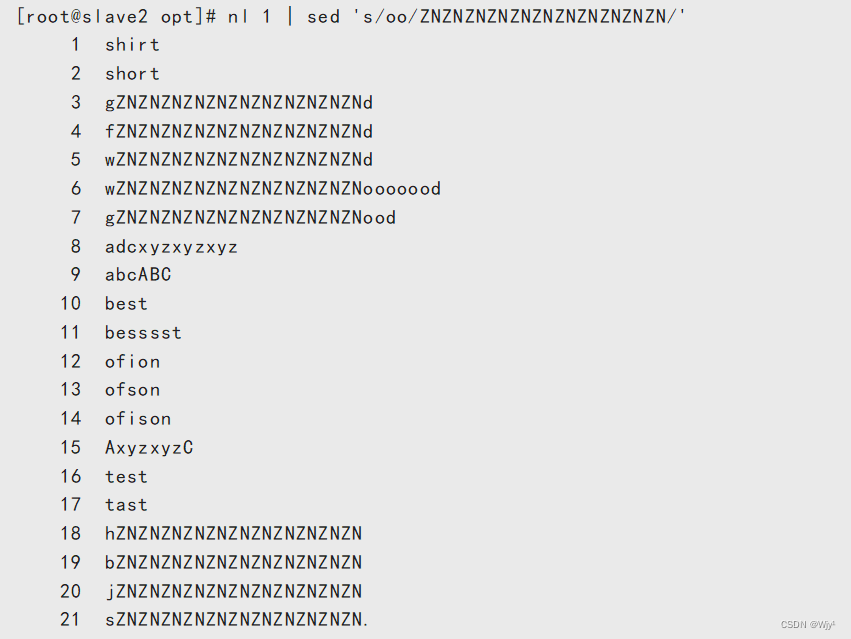
替换全文本
nl 1 | sed 's/oo/ZNZNZNZNZNZNZNZNZNZNZN/'
替换第4行
nl 1 | sed '3s/oo/ZNZNZN/'

替换匹配到的第 2 个 oo
nl 1 | sed 's/oo/OO/2'

注:这里可以看到,我们匹配出来的第一个 oo 并没有任何变化,
4.迁移符合条件的文本
H:复制;g:覆盖;G:追加行;w:保存;r:读取;a:追加内容
sed '/the/{H;d};$G' test.txt #匹配the所在行并迁移至文件末尾
sed '3aTest' test.txt #在第3行下面新建行并写入Test
sed '/the/aTest' test.txt #匹配the所在行并在下一行写入Test
5.使用脚本编辑文件内容
vim opt.txt
1,5H
1,5d
16G
sed -f opt.txt test.txt #将1到5行迁移至16行后
6.以上修改想要直接修改文本源文件,只需要加入选项"-i"
5)awk
a)语法
awk 选项 '模式或条件{编辑命令}' 文件1 文件2 ...
awk -f 脚本文件 文件1 文件2 ...
b)选项
-F 指定每行的分隔符(默认分隔符为空格)
c)内建变量
FS:指定每行的分隔符
NF:指定当前处理行的字段个数
NR:当前处理行的行号
$0:当前处理行的整行内容
$n:当前处理的第n个字段
FILENAME:处理文件名
RS:数据记录分隔,默认是\n
d)案例:
1.按行输出
awk '{print}' test.txt #等同cat
awk 'NR>=1&&NR<=3{print}' test.txt
awk 'NR==1,NR==3{print}' test.txt #打印1到3行
awk 'NR%2==0{print}' test.txt #打印偶数行
2.按段输出
默认以"空格"分段!
ifconfig ens33 |awk '/netmask/{print $2}' #筛选IP地址
cat /etc/shadow | awk -F : '$2=="!!"{print $1}' #打印不能登录系统的用户
3.调用shell命令
cat /etc/passwd | awk -F : '/bash$/{print | "wc -l"}' /etc/passwd #统计能够登录系统的用户个数
5、使用shell脚本应该注意些什么?
5.1、shell命名
shell脚本的名称一般命名为英文(大写或xiaox),后缀以.sh、.zsh等结尾。不能使用特殊符合以及空格,最好是命名的时候一眼就能看出来这个脚本或命令是干什么用的,方便自己进行操作亦方便后面使用的人进行操作。
| .sh | 这是最常见的Shell脚本后缀,表示该脚本是Bash Shell脚本 |
| .bash | 这个后缀也用来表示Bash Shell脚本 |
| .ksh | 表示Korn Shell脚本 |
| .csh | 表示C Shell脚本 |
| .tcsh | 表示Tenex C Shell脚本 |
| .zsh | 表示Z Shell脚本 |
| .shar | 表示Shell存档,通常用于将多个Shell脚本合并为一个文件 |
| .rpm | 表示RPM软件包,其中可能包含Shell脚本 |
| .ebuild | 表示Gentoo Linux系统中的Portage软件包的构建脚本 |
| 需要注意的是,这些后缀并不是严格规定的,可以根据个人或组织的喜好进行自定义 | |
5.2、常见的shell脚本编写规范
通常情况下 第一行 为:
#!/bin/bash一般情况下,使用Bash作为默认解释器,可以写为#!/bin/bash。这样系统会自动调用Bash来解释执行脚本。如果需要使用其他Shell,可以相应修改为对应的路径。
第二行 为:
#脚本的说明在第二行可以写上对脚本的简短说明,用注释符号"#"开头。例如:# 脚本的说明。
第三行及以后 为:
脚本正文从第三行开始,编写脚本的正文部分,实现具体的功能。
此外,还有一些常见的Shell脚本编写规范:
- 使用有意义的变量名:使用有描述性的变量名,可以提高代码的可读性和可维护性。
- 使用缩进:使用适当的缩进来使代码结构清晰,方便阅读。
- 添加注释:在关键的地方添加注释,解释代码的作用和用法,方便其他开发者理解和维护代码。
- 错误处理和日志记录:对于可能出现错误的地方,进行错误处理,并记录日志。可以使用条件语句、函数等来实现错误处理和记录日志的功能。
- 使用函数和模块化:将脚本分成多个函数,提高代码的可维护性和重用性。
- 使用命令行参数:可以为脚本添加命令行参数,增加脚本的灵活性。
- 添加退出状态码:在脚本结尾处使用"exit"命令并指定退出状态码,便于根据脚本的执行结果进行后续处理。
5.3、shell脚本
shell脚本的变量不能以数字、特殊符号开头,可以使用下划线( _ ),但不能使用破折号( - )
5.4、shell运行规则
没有x权限
bash 脚本所在路径/脚本文件
source 脚本所在路径/脚本文件
. 脚本所在路径/脚本文件
注:后两个执行命令,在脚本中若存在 cd 时,会切换到目标目录
有x权限
./脚本文件
脚本绝对路径/脚本文件5.5.、 shell脚本运行追踪
bash -x 脚本所在路径/脚本文件6、read -p "提示语" 变量名
读取键盘输入并赋值给变量名
7、拓展知识
7.1、返回100内随机数
$[$RANDOM%100]

7.2、返回1到10 的连续数字
seq 1 10
{1..10}

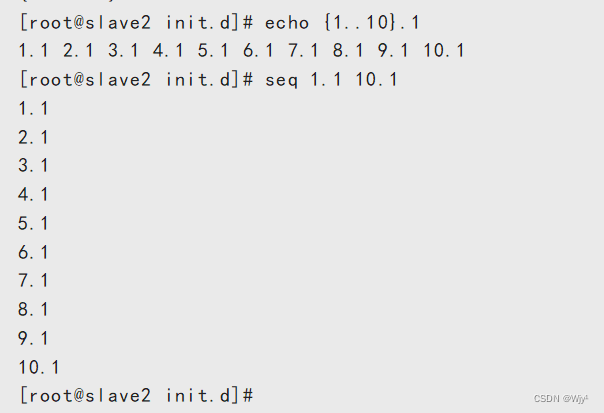
7.3、返回1.1 2.1 3.1.... 10.1
{1..10}.1
seq 1.1 10.1

二、表达式
查看系统中支持的shell
cat /etc/shells
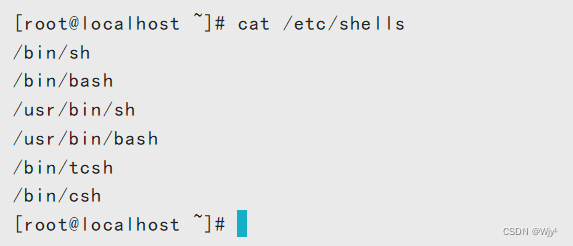
查看系统默认shell
echo $SHELL

查看默认字符集
locale


1、变量
1.1、组成
变量名不会发生变化
例如:杯子、瓢、容器等等。
声明规范
不能是数字或数字开头
以字母或_开头
变量名中不能包含特殊字符

声明方法
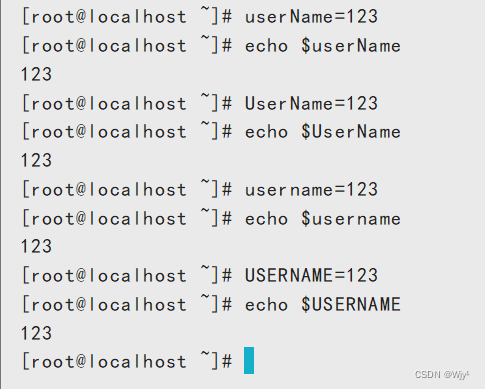
驼峰式 userName
双驼峰 UserName
shell写法 user_name
username
USERNAME
ps:字母全为大写可称为常量
变量值可以不断发生变化(数字、字符)
例如上面提到的容器,其内所承载的物体
1.2、类型
1)系统内置变量(环境变量)
env
2)自定义变量
zn=zm

等号两边不能有空格
数字形式:
zn=1

重复输入同一条则上一条会被顶替。
字符串形式:
shell中可以不使用引号
当包含有空格时,需要使用引号

引号的用法
不会引用变量值
单引号 '
会应用变量值
双引号 "
引用命令结果
反撇号 `
$(命令) 应用场景较多
单引号‘’:强引用,六亲不认,变量和命令都不识别,都当成了普通的字符串,“最傻”
双引号”“:弱引用,不能识别命令,可以识别变量,“半傻不精”
反撇号··:里面的内容必须是能执行的命令并且有输出信息,变量和命令都识别,并且会将反向单引号的内容当成命令进行执行后,再交给调用反向单引号的命令继续,“最聪明
引用变量命 令 执 行 结 果 {} 命令执行结果命令执行结果()
运算$[] $(())
$() 或 ``引用命令执行的结果
( ( ) ) 或 (()) 或(())或[]进行运算
使用或 " {}或"或"变量名” 划定变量名的起止范围
3)位置变量
脚本后参数所在的位置
$1 ~~ $9


系统定义下的 ls 的带颜色说明的,此时没有,因为我们没有进行定义。

系统定义下的 ls

进行更改,使其带有颜色

查看

4)预定义变量
创建一个脚本进行实验,且注意前文命名规则!
vim shellscript.sh
chmod +x /root/shellscript.sh注意:需要赋予脚本执行权限( x )
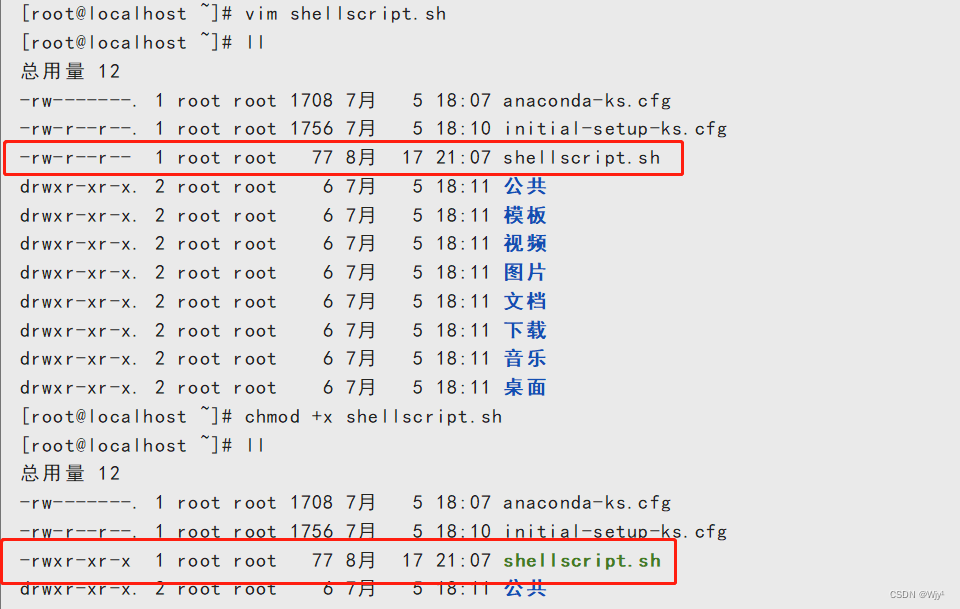
$0 脚本本身的名称

./shellscript.sh
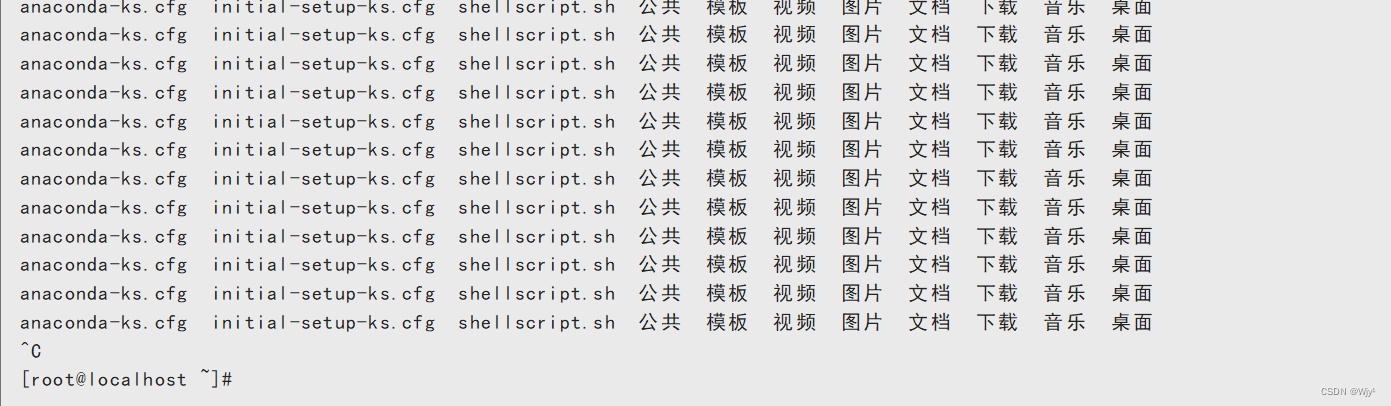 此时就陷入了无限调自己的命令(死循环),除非打断进程运行( ctrl+c )
此时就陷入了无限调自己的命令(死循环),除非打断进程运行( ctrl+c )
$# 脚本后参数的个数

此时我们可以看到,显示了三个内容。

不管输入的内容是否有效,$#只显示数量
$* 脚本运行时参数的内容(整体输出)

跟 echo 一样,直接打印内容

$@ 脚本运行时参数的内容(逐个输出)


这样查看的话,$* 和 $@并没有什么区别
我们写一个简单的脚本进行查看

$* 整体输出, $@ 单个输出

$? 脚本运行完毕后的返回值
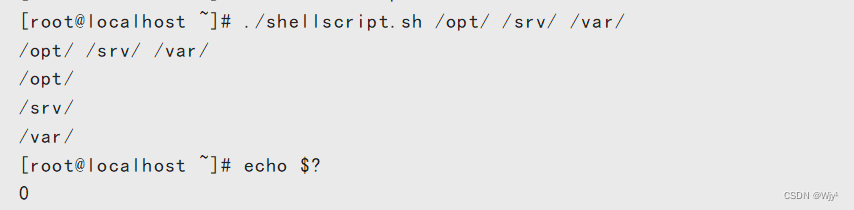
例如:

默认情况
0 成功
非0 失败
1.3、作用域
默认变量只在当前shell下生效

bash进行刷新
若要在当前及其子shell下生效,需要声明为全局变量( export )

1.4、输出
echo $varName

1.5、shell中的字符串
string
赋值: str1=foodfornoting.gpg
1)获得字符串的长度
语法: ${#StringName}
案例: echo ${#str1}
输出结果:17
2)字符串取子串
语法: ${#StringName:position:lenght}
案例: echo ${str1:0:3}
输出结果:foo
注意:lenght没有定义时,一直取到字符串的结尾!
3)字符串的截取
a)从左至右截取最后一个匹配字符串string之后的所有字符串
语法: ${StringName##*string}
案例: echo ${str1##*fo}
输出结果:rnoting.gpg
b)从左至右截取第一个匹配字符串string之后的所有字符串
语法: ${StringName#*string}
案例: echo ${str1#*fo}
输出结果:odfornoting.gpg
c)从右至左截取最后一个匹配字符串string之后的所有字符串
语法: ${StringName%%string*}
案例: echo ${str2%%o*}
输出结果:f
d)从右至左截取第一个匹配字符串string之后的所有字符串
语法: ${StringName%string*}
案例: echo ${str2%o*}
输出结果:foodforn
4)字符串的拼接
语法: StringName3=${StingName1}${StringName2}
案例: str1=Hello
str2=,Jack!
str3=${str1}${str2}
echo ${str3}
输出结果: Hello,Jack!
5)字符串替换:
语法: ${StringName/OldString/NewString}
案例: str1=foodfornoting.gpg
echo ${str1/oo/kk}
输出结果:fkkdfornoting.gpg
2、运算符
2.1、数学运算
+ - * / %+ 等于加
- 等于减
* 等于乘
/ 等于除
% 等于取余同时 * 作为乘号时需要加转义符\ 例如 \*在Linux操作系统中,反斜杠(\)被用作转义字符,用于表示特殊字符或者序列。它可以与一些特定的字母或符号组合在一起,形成一种转义序列,具有特殊的含义。
以下是一些常见的转义序列和它们的含义:
\n:表示换行符。在打印输出或者文本编辑器中,\n会使得光标移到下一行的开头。
\t:表示制表符。在打印输出或者文本编辑器中,\t会在当前位置插入一个制表符(通常是光标移到下一个制表符位置)。
\b:表示退格符。在打印输出或者文本编辑器中,\b会使得光标往前移动一个位置,可以用来删除前一个字符。
\r:表示回车符。在打印输出或者文本编辑器中,\r会使得光标移到当前行的开头,可以用来覆盖之前的内容。
\:表示反斜杠字符本身。在某些需要显示反斜杠的情况下,需要使用两个反斜杠来表示。
此外,还有其他一些转义序列,如\’表示单引号,\”表示双引号,\a表示警报声等。这些转义序列可以在字符串或输出格式中使用。
运算方法
2.2、赋值
a=1
b=2
expr $a + $b

expr $((a+b))

echo $((a+b))

echo $[a+b]
expr $[a+b]

expr $a - $b

在乘作为运算时需要添加转义符,因为 * 号有通配符的意思,代表所有

expr $a / $b

注意
shell不支持浮点数的显示


2.3、比较运算
| && | 条件 && 输出结果 |
| 条件为真输出 |
| || | 条件 || 输出结果 |
| 条件为假输出 |
1)数值比较
| -eq | 等于 |
| -ne | 不等于 |
| -lt | 小于 |
| -le | 小于等于 |
| -gt | 大于 |
| -ge | 大于等于 |



2)字符串比较
| = | 字符串一致 |
| != | 字符串不一致 |
| -z | 字符串为空 |
| ! -z | 字符串不为空 |


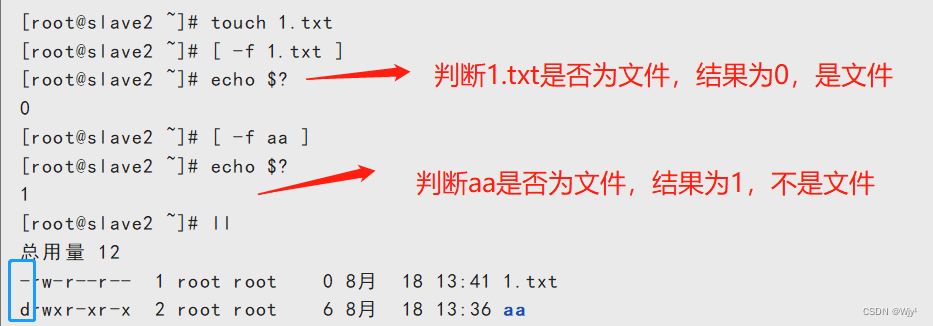
3)文件比较
| -e | 文件或目录是否存在 |
| -f | 是否为文件 |
| -d | 是否为目录 |
| -r | 判断文件是否可读 |
| -w | 判断文件是否可写 |
| -x | 判断文件是否可执行 |



2.4、逻辑运算符
| && | 并且,有假则假,全真为真 |
| -a |
| || | -o | 或者,有真则真,全假为假 |
| ! | 取反 | 有真则假,有假则真 |
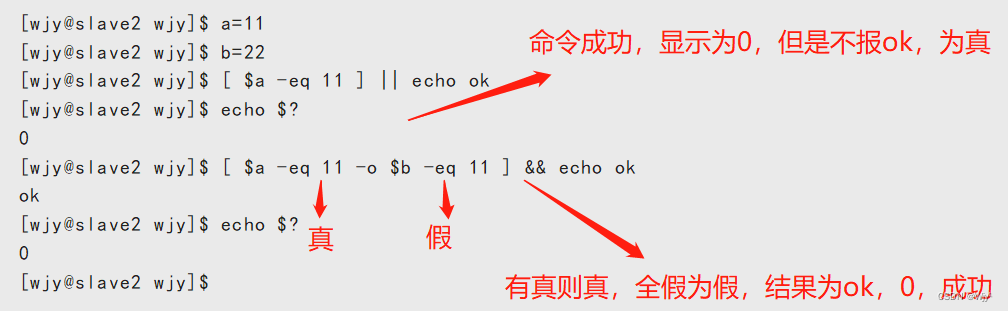
条件测试
[ $a -eq $b ] && echo OK
echo $?
[ $a -eq $b ] || echo OK
echo $?

总结
在编写Shell脚本时,可以参考官方文档、教程和示例代码等来学习和理解不同的概念和用法。最重要的是,要不断练习和进行实践。通过编写简单的脚本并逐渐增加复杂度,逐渐熟悉Shell脚本编程。网络上有很多的shell脚本示例,大家可以多去观摩借鉴,先了解命令的使用方式、语法等,再开始手动编写脚本内容。