Redis 中列表(List)类型是用来存储多个有序的字符串,列表中的每个字符串成为元素 Eelement),一个列表最多可以存储 2^32-1 个元素。
在 Redis 中,可以对列表两端插入(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等。列表是一种比较灵活的数据结构,可以充当栈和队列的角色,在实际开发中有很多应用场景。
文章目录
- 1、List数据类型
- 1.1、List类型简介
- 1.2、List应用场景
- 2、List底层结构
- 2.1、List底层结构介绍
- 2.2、压缩列表ZipList
- 2.3、双向链表LinkedList
- 2.4、快速链表QucikList
- 3、List常用命令
- 3.1、将新值加入列表头部
- 3.2、将新值加入列表尾部
- 3.3、获取列表中某区间的值
- 3.4、移除列表中头部的值,并返回此值
- 3.5、移除列表中尾部的值,并返回此值
- 3.6、通过下标获取列表中的值
- 3.7、 删除指定值及数量的元素值
- 3.8、得到列表长度
- 3.9、截断列表
- 3.10、将值从一个列表移动到另一个列表
- 3.11、替换列表中某个值
- 3.12、指定位置将新值插入列表
1、List数据类型
1.1、List类型简介
Redis 中列表(List)类型是用来存储多个有序的字符串,列表中的每个字符串成为元素 Eelement),一个列表最多可以存储 2^32-1 个元素。
在 Redis 中,可以对列表两端插入(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等。列表是一种比较灵活的数据结构,可以充当栈和队列的角色,在实际开发中有很多应用场景。
列表类型有以下特点:
-
列表中的元素是有序的,即可以通过索引下标获取某个元素或者某个范围内的元素列表;
-
列表中的元素可以是重复的
1.2、List应用场景
根据 Redis 双向列表的特性,因此其也被用于异步队列的使用。实际开发中将需要延后处理的任务结构体序列化成字符串,放入 Redis 的队列中,另一个线程从这个列表中获取数据进行后续处理。
使用场景:
- 消息队列:消息队列在存取消息时,必须要满足三个需求,分别是消息保序、处理重复的消息和保证消息可靠性。Redis 的 List 和 Stream 两种数据类型,就可以满足消息队列的这三个需求;
- 最新消息排队功能:与消息队列类似
但另一方面,使用 Redis List 作为消息队列也有一些不足,比如:
- 消息持久化 :Redis 是内存数据库,虽然有 Aof 和 Rdb 两种机制进行持久化,但这只是辅助手段,这两种手段都是不可靠的。当 Redis 服务器宕机时一定会丢失一部分数据,这对于很多业务都是没法接受的;
- 热 Key 性能问题:不论是用 Codis 还是 Twemproxy 这种集群方案,对某个队列的读写请求最终都会落到同一台 Redis 实例上,并且无法通过扩容来解决问题。如果对某个 List 的并发读写非常高,就产生了无法解决的热 Key,严重可能导致系统崩溃;
- 每当执行 Rpop 消费一条数据,那条消息就被从 List 中永久删除了。如果消费者消费失败,这条消息也没法找回了。你可能说消费者可以在失败时把这条消息重新投递到进队列,但这太理想了,极端一点万一消费者进程直接崩了呢,比如被 kill -9,panic,coredump…
- 一条消息只能被一个消费者消费,Rpop 之后就没了。如果队列中存储的是应用的日志,对于同一条消息,监控系统需要消费它来进行可能的报警,BI 系统需要消费它来绘制报表,链路追踪需要消费它来绘制调用关系……这种场景 Redis List 就没办法支持了;
- 不支持二次消费 :一条消息 Rpop 之后就没了。如果消费者程序运行到一半发现代码有 Bug,修复之后想从头再消费一次就不行了
对于上述的不足,目前看来第一条(持久化)是可以解决的。很多公司都有团队基于 Rocksdb Leveldb 进行二次开发,实现了支持 Redis 协议的 kv 存储。这些存储已经不是 Redis 了,但是用起来和 Redis 几乎一样。它们能够保证数据的持久化,但对于上述的其他缺陷也无能为力了。
其实 Redis 5.0 开始新增了一个 Stream 数据类型,它是专门设计成为消息队列的数据结构,借鉴了很多 Kafka 的设计,但是依然还有很多问题…直接进入到kafka的世界它不香吗?
2、List底层结构
2.1、List底层结构介绍
在 Redis3.2 版本前,Redis 列表 List 使用两种数据结构作为底层实现:
- 压缩列表 ZipList:插入元素过多或字符串太大,就需要调用 Realloc 扩展内存;
- 双向链表 LinkedList:需附加指针 Prev 和 Next,较浪费空间,加重内存的碎片化
Redis3.2 首先以 ZipList 进行存储,在不满足 ZipList 的存储要求后转换为 LinkedList 列表。当列表对象同时满足以下两个条件时,列表对象使用 ZipList 进行存储,否则用 LinkedList 存储。
- 列表对象保存的所有字符串元素的长度小于 64 字节;
- 列表对象保存的元素数量小于 512 个
在 Redis3.2 版本后,Redis 列表使用 快速链表 QucikList 结构作为底层实现。
2.2、压缩列表ZipList
在 Redis3.2 版本前压缩列表不仅是 List 的底层实现之一,同时也是 Hash、 ZSet 两种数据类型底层实现之一。
压缩列表是一块连续的内存空间 (像内存连续的数组,但每个元素长度不同),一个 ziplist 可以包含多个节点(entry)。元素之间紧挨着存储,没有任何冗余空隙。

压缩列表的本质就是一个数组,只不过是增加了 “列表长度”、“尾部偏移量”、“列表元素个数” 以及 “列表结束标识”,这样的话就有利于快速的寻找列表的首、尾节点.压缩列表将表中每一项存放在前后连续的地址空间内,每一项因占用的空间不同,而采用变长编码。由于内存是连续分配的,所以遍历速度很快。
当我们的 List 列表数据量比较少的时候,且存储的数据轻量的(如小整数值、短字符串)时候, Redis 就会通过压缩列表来进行底层实现。
+--------+--------+--------+-------+----+--------+-------+
| zlbytes| zltail | zllen | entry1 | .. | entryN | zlend |
+--------+--------+--------+-------+----+--------+-------+
| 属性 | 说明 |
|---|---|
| “zlbytes” | 表示压缩列表的长度(包括所有的字节) |
| “zltail” | 表示压缩列表尾部的指针(偏移量) |
| “zllen” | 表示压缩列表中节点(Entry)的个数 |
| “entry” | 存储区,可以包含多个节点,每个节点可以存放整数或者字符串 |
| “zlend” | 表示列表结束 |
如果查找定位首个元素或最后1个元素,可以通过表头 “zlbytes”、“zltail_offset” 元素快速获取,复杂度是 O(1)。但是查找其他元素时,就没有这么高效了,只能逐个查找下去,比如 entryN 的复杂度就是 O(N)。
2.3、双向链表LinkedList
LinkedList 是标准的双向链表,Node 节点包含 prev 和 next 指针,分别指向后继与前驱节点,因此从双向链表中的任意一个节点开始都可以很方便地访问其前驱与后继节点。

LinkedList 可以进行双向遍历;添加删除元素快 O(1),查找元素慢 O(n),高效实现了 LPUSH 、RPOP、RPOPLPUSH,但由于需要为每个节点分配额外的内存空间,所以会浪费一定的内存空间。这种编码方式适用于元素数量较多或者元素较大的场景。
LinkedList 结构为链表提供了表头指针 head、表尾指针 tail,以及节点数量计算 len。下图展示一个由 list 结构和三个 listNode 节点组成的链表:
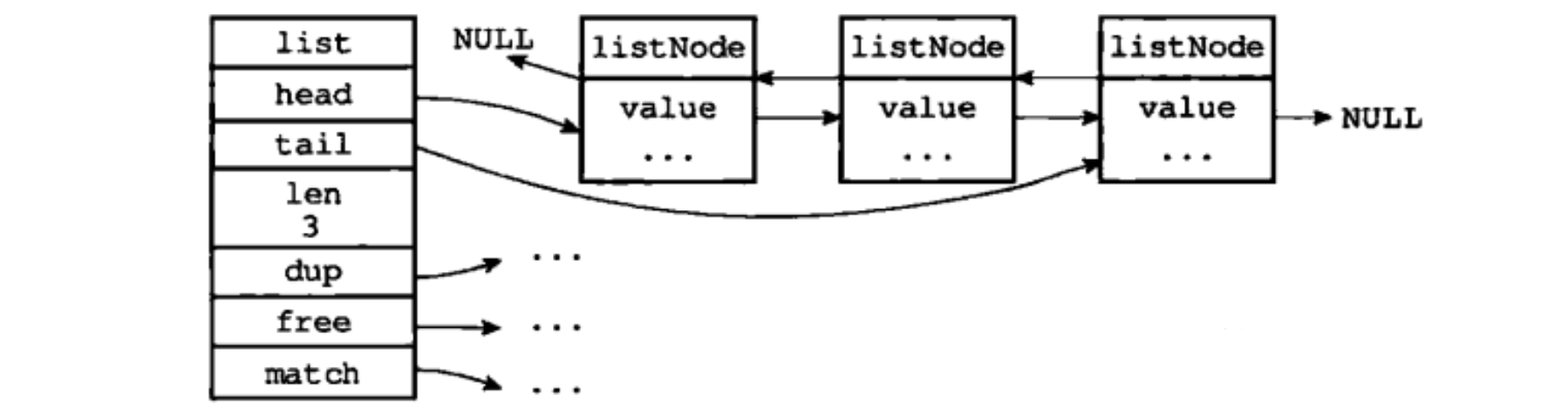
Redis 的链表实现的特性可以总结如下:
- 双端:链表节点带有 prev 和 next 指针,获取某个节点的前一节点和后一节点的复杂度都是 O(1);
- 无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问以 NULL 为终点;
- 表头指针/表尾指针:通过 list 结构的 head 指针和 tail 指针,获取链表的表头节点和表尾节点的复杂度为 O(1);
- 链表长度计数器:通过 list 结构的 len 属性来对 list 的链表节点进行计数,获取节点数量的复杂度为O(1);
- 多态:链表节点使用 void* 指针来保存节点值,并通过 list 结构的 dup、free、match 三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。
使用链表的附加空间相对太高,因为 64bit 系统中指针是 8 个字节,所以 prev 和 next 指针需要占据 16 个字节,且链表节点在内存中单独分配,会加剧内存的碎片化,影响内存管理效率
2.4、快速链表QucikList
Redis3.2 版本开始,List 类型数据使用的底层数据结构是快速链表,快速列表是以压缩列表为节点的双向链表,将双向链表按段切分,每一段使用压缩列表进行内存的连续存储,多个压缩列表通过 prev 和 next 指针组成的双向链
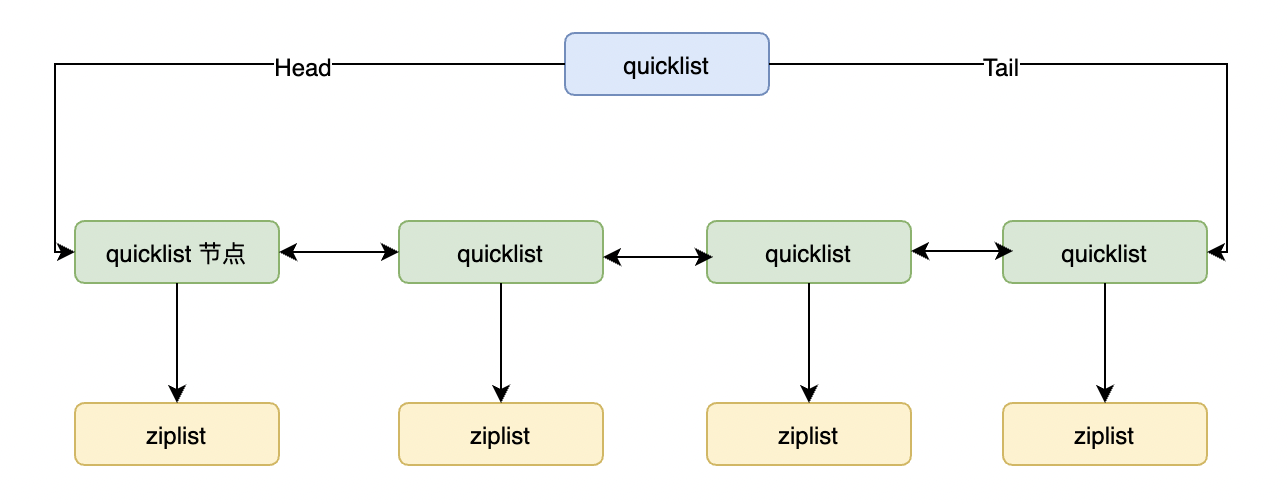
考虑到链表的以上缺点,Redis 后续版本对列表数据结构进行改造,使用 QucikList 代替了 ZipList 和 LinkedList。 作为 ZipList 和 LinkedList 的混合体,它将 LinkedList 按段切分,每一段使用 ZipList 来紧凑存储,多个 ZipList 之间使用双向指针串接起来。
这样,性能就的得到了更大的提升。
| 说明 | |
|---|---|
| “head” | 表示快速链表的头部节点 |
| “tail” | 表示快速链表的尾部节点 |
| “count” | 表示快速链表中所有节点中元素的总数 |
| “len” | 表示快速链表中节点的个数 |
| “fill” | ziplist 节点的最大大小,值默认 8kb,大小超出后会新建一个 Ziplist,对应 list-max-ziplist-size 参数,占 16bit。 |
| “compress” | 节点压缩深度,表示节点是否使用 LZF 算法压缩,对应 list-compress-depth 参数,占1 6bit |
对于 “fill” 当数字为负数:
- -1:每个 ZipList 节点大小不能超过 4kb(建议)
- -2:每个 ZipList 节点大小不能超过 8kb(默认配置)
- -3:每个 ZipList 节点大小不能超过 16kb(一般不建议)
- -4:每个 ZipList 节点大小不能超过 32kb(不建议)
- -5:每个 ZipList 节点大小不能超过 64kb(正常工作量不建议)
对于 “fill” 当数字为正数:ZipList 节点最多包含的元素个数,最大值为 215215
对于 “compress” 节点,数字含义如下:
-
0:不压缩(默认)
-
1:QucikList 列表的两端各有1个ziplist节点不压缩,中间的节点压缩
-
2:QucikList 列表的两端各有2个ziplist节点不压缩,中间的节点压缩
-
3:QucikList 列表的两端各有3个ziplist节点不压缩,中间的节点压缩
-
以此类推,最大为 216216
3、List常用命令
3.1、将新值加入列表头部
使用 LPUSH 命令将新值加入列表头部:
LPUSH list value [value2 ...]
将一个或多个值插入到列表头部。如果 key 值不存在,会先创建再执行 LPUSH 命令,如果 key 值存在但不是列表类型时,返回一个错误。

3.2、将新值加入列表尾部
使用 RPUSH 命令将新值加入列表尾部:
RPUSH list value [value2 ...]
将一个或多个值插入到列表尾部。如果 key 值不存在,会先创建再执行 LPUSH 命令,如果 key 值存在但不是列表类型时,返回一个错误

3.3、获取列表中某区间的值
使用 LRANGE 命令获取列表中某区间的值:
LRANGE 列表名 start end
获取列表中指定区间的元素,0 表示列表中第一个元素,-1 表示列表中最后一个元素

3.4、移除列表中头部的值,并返回此值
使用 LPOP 命令移除列表中头部的值,并返回此值:
LPOP list

3.5、移除列表中尾部的值,并返回此值
使用 RPOP 命令移除列表中尾部的值,并返回此值:
RPOP list

3.6、通过下标获取列表中的值
使用 LINDEX 通过下标获取列表中的值:
LINDEX list index

3.7、 删除指定值及数量的元素值
使用 LREM 删除指定值及数量的元素值:
LREM list num value

3.8、得到列表长度
使用 LLEN 得到列表长度
llen list

3.9、截断列表
使用 LTRIM 截断列表
LTRIM list start end

3.10、将值从一个列表移动到另一个列表
使用 RPOPLPUSH 将值从一个列表移动到另一个列表
RPOPLPUSH source distination
将 source 列表中最后一个元素移除,并将该元素添加到 destination 列表中,可简单理解为 “尾删头插”

3.11、替换列表中某个值
使用 LSET 替换列表中某个值
LSET list index value

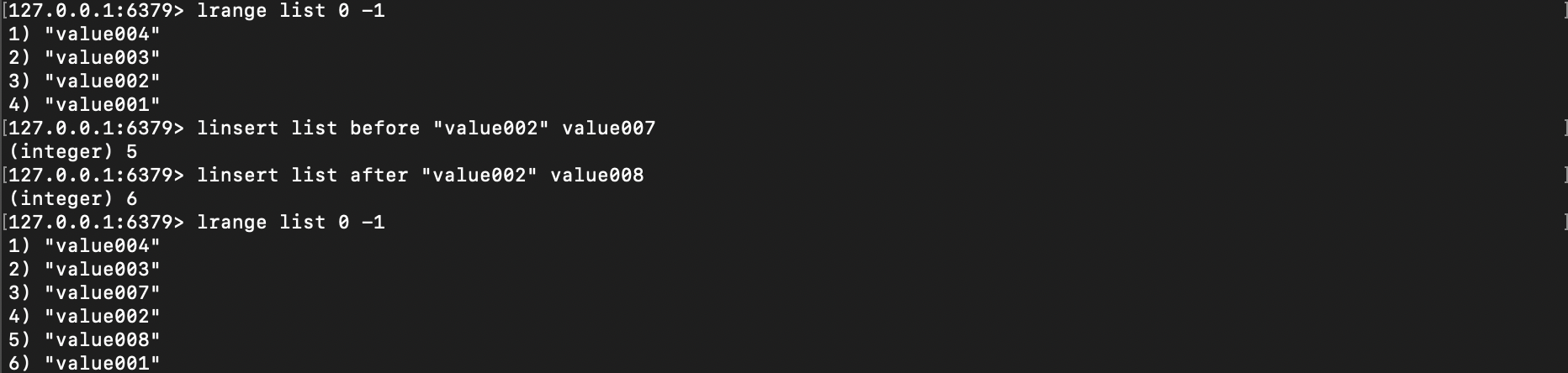
3.12、指定位置将新值插入列表
使用 LINSERT 指定位置将新值插入列表
LINSERT list BEFORE / AFTER old-value new-value