一、RDD
Spark RDD(弹性分布式数据集),弹性是指Spark可以通过重新计算来自动重建丢失的分区。
从本质上讲,RDD 是数据元素的不可变分布式集合,跨集群中的节点进行分区,可以与提供转换和操作的低级 API 并行操作。
Spark RDD 相关操作:官方文档
1. 为什么 Spark 中需要 RDD?
RDD 解决了 MapReduce 在数据共享方面的缺点。当重用数据进行计算时,MapReduce 需要写入外部存储(HDFS、Cassandra、HBase 等)。作业之间的读写过程会消耗大量内存。
此外,由于复制、序列化和磁盘使用量的增加,任务之间的数据共享速度很慢。
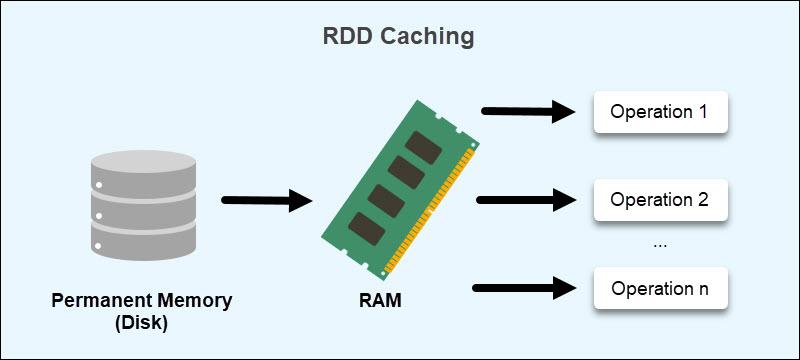
RDD 旨在通过利用内存计算操作存储来减少外部存储系统的使用。这种方法将任务之间的数据交换速度提高了 10 到 100 倍。
处理大量数据时,速度至关重要。Spark RDD 使训练机器学习算法和处理大量数据进行分析变得更加容易。
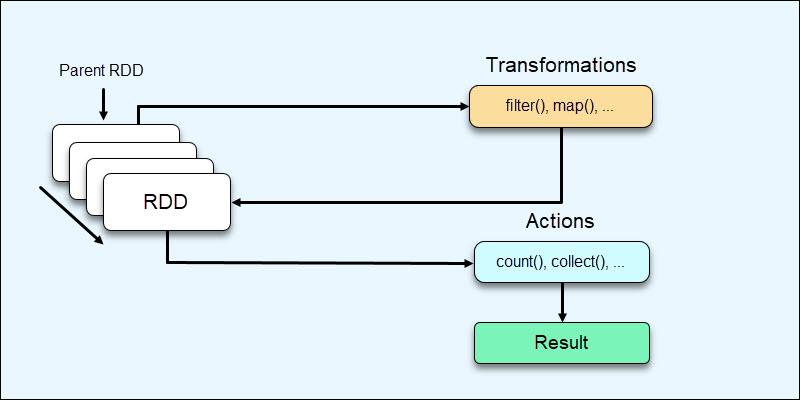
2. Spark RDD 操作
RDD 提供两种操作类型:
1.转换是对 RDD 进行的操作,从而创建 RDD。RDD的transformation操作是延迟计算的,只在遇到action时才真正进行计算。
2.action是不会导致 RDD 创建并提供一些其他值的操作。
2、RDD 持久化
Spark 中一个很重要的能力是将数据持久化(或称为缓存),在多个操作间都可以访问这些持久化的数据。当持久化一个 RDD 时,每个节点的其它分区都可以使用 RDD 在内存中进行计算,在该数据上的其他 action 操作将直接使用内存中的数据。这样会让以后的 action 操作计算速度加快(通常运行速度会加速 10 倍)。缓存是迭代算法和快速的交互式使用的重要工具。
RDD 可以使用 persist() 方法或 cache() 方法进行持久化。数据将会在第一次 action 操作时进行计算,并缓存在节点的内存中。Spark 的缓存具有容错机制,如果一个缓存的 RDD 的某个分区丢失了,Spark 将按照原来的计算过程,自动重新计算并进行缓存。
在 shuffle 操作中(例如 reduceByKey),即便是用户没有调用 persist 方法,Spark 也会自动缓存部分中间数据。这么做的目的是,在 shuffle 的过程中某个节点运行失败时,不需要重新计算所有的输入数据。如果用户想多次使用某个 RDD,强烈推荐在该 RDD 上调用 persist 方法。
3、RDD的cache和persist的区别
cache()调用的persist(),是使用默认存储级别的快捷设置方法
看一下源码
/*** Persist this RDD with the default storage level (`MEMORY_ONLY`).*/
def cache(): this.type = persist()/*** Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
通过源码可以看出cache()是persist()的简化方式,调用persist的无参版本,也就是调用persist(StorageLevel.MEMORY_ONLY),cache只有一个默认的缓存级别MEMORY_ONLY,即将数据持久化到内存中,而persist可以通过传递一个 StorageLevel 对象来设置缓存的存储级别。
二、执行器和集群管理器
本地模式 使用本地模式,有一个executor和driver运行在同一个JVM中,该模式一般是测试或小规模作业。这种模式主URL为local(一个线程)、local[n](n个线程)、local[*](每个内核一个线程)
standalone模式 运行了一个master和多个workder。当spark应用启动时,master要求worker代表应用启动多个executor线程。
YARN模式 YARN是Hadoop中的资源管理器。该模式优于独立模式集群管理器,因为考虑了在集群上运行的其他应用(MapReduce作业)的资源需求,并统筹实施调度策略。独立模式对集群资源采取静态分配方法,不能随时适应其他应用变化需求。
三、运行在YARN上的Spark
为了在YARN上运行,Spark提供了两种部署模式:YARN客户端模式和YARN集群模式。YARN客户端模式的driver在客户端运行,YARN集群模式的driver在YARN的application master集群上运行。
对于spark-shell必须使用YARN客户端模式,使用该模式,任何调试输出都是立即可见的。
另一方面,YARN集群模式适用生成作业,因为整个应用在集群上运行。如果application master出现故障,YARN可以尝试重新运行该应用。
在Spark on Yarn上,Driver会和AppMaster通信,资源的申请由AppMaster来完成,而任务的调度和执行则由Driver完成,Driver会通过与AppMaster通信来让Executor的执行具体的任务。
1. YARN客户端模式
在YARN客户端模式下,当driver构建新的SparkContext实例便启动了与Yarn的交互。该context向ResourceManager提交一个Yarn应用,ResourceManager启动NodeManager上的Yarn容器,运行一个application master。
ExecutorLauncher向ResourceManager申请资源来启动Yarn容器的executor。每个executor在启动时都会连接回sc,并注册自身。
2. YARN集群模式
对于YARN客户端模式和YARN集群模式的唯一区别在于,YARN客户端模式的Driver运行在本地,而AppMaster运行在YARN一个节点上,他们之间进行远程通信,AppMaster只负责资源申请和释放(当然还有DelegationToken的刷新),然后等待Driver的完成。
而YARN集群模式的Driver则运行在AppMaster所在的container里,Driver和AppMaster是同一个进程的两个不同线程,它们之间也会进行通信,AppMaster同样等待Driver的完成,从而释放资源。
参考链接
- 从源码角度看Spark on yarn client & cluster模式的本质区别
- Hadoop权威指南