ICLR:International Conference on Learning Representations
CCF-A 国际表征学习大会:深度学习的顶级会议
生成对抗网络(GANs)的最新进展已经证明了生成令人惊叹的逼真肖像图像的能力。虽然之前的一些工作已经将这种图像gan应用于无条件的2D人像视频生成和静态的3D人像合成,但很少有工作成功地将gan扩展到生成3D感知人像视频。在这项工作中,我们提出了PV3D,这是第一个可以合成多视图一致人像视频的生成框架。具体来说,我们的方法通过推广3D隐式神经表示来模拟时空空间,将最近的静态3D感知图像GAN扩展到视频领域。为了将运动动力学引入到生成过程中,我们开发了一个运动生成器,通过叠加多个运动层,通过调制卷积合成运动特征。为了减轻由摄像机/人体运动引起的运动歧义,我们提出了一种简单而有效的PV3D摄像机条件策略,实现了时间和多视图一致的视频生成。此外,PV3D引入了两个判别器来正则化空间和时间域,以确保生成的人像视频的可信性。这些精心设计使PV3D能够生成具有高质量外观和几何形状的3d感知运动逼真的人像视频,显着优于先前的作品。因此,PV3D能够支持下游应用程序,如静态肖像动画和视图一致的运动编辑。代码和模型可在https://showlab.github.io/pv3d上获得。
PV3D的github代码和模型![]() https://showlab.github.io/pv3d我们的目标是:通过只学习2D单眼视频来减轻创建高质量3D感知人像视频的工作量,而不需要任何3D或多视图注释
https://showlab.github.io/pv3d我们的目标是:通过只学习2D单眼视频来减轻创建高质量3D感知人像视频的工作量,而不需要任何3D或多视图注释

最近3d感知肖像生成方法通过整合内隐神经表征INRs可以产生逼真的多视图一致的结果,但是这些方法仅限于静态人像生成,很难扩展到人像视频生成:
1)如何在生成框架中有效地建模三维动态人体肖像仍然不清楚;
2)在没有三维监督的情况下学习动态三维几何是高度受限的;
3)相机运动和人类运动/表情之间的纠缠给训练过程带来了模糊性。
为此,本篇文章提出了一种3D人像视频生成模型(PV3D),这是第一种可以在纯粹从单目2D视频中学习的情况下生成具有多种动作的高质量3D人像视频的方法。PV3D通过将3D三平面表示(Chan et al, 2022)扩展到时空域来实现3D人像视频建模。在本文中,我们综合分析了各种设计选择,得出了一套新颖的设计,包括将潜在代码分解为外观和运动组件,基于时间三平面的运动生成器,适当的摄像机姿态序列调理和摄像机条件视频鉴别器,可以显着提高3D人像视频生成的视频保真度和几何质量。
Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio
Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. Efficient geometry-aware 3d
generative adversarial networks. In CVPR, 2022.
EG3D: Efficient Geometry-aware 3D Generative Adversarial Networks![]() https://nvlabs.github.io/eg3d/
https://nvlabs.github.io/eg3d/
As shown in Figure 1, despite being trained from only monocular 2D videos, PV3D can generate a large variety of photo-realistic portrait videos under arbitrary viewpoints with diverse motions and high-quality 3D geometry. Comprehensive experiments on various datasets including VoxCeleb (Nagrani et al, 2017), CelebV-HQ (Zhu et al, 2022) and TalkingHead-1KH (Wang et al, 2021a) well demonstrate the superiority of PV3D over previous state-of-the-art methods, both qualitatively and quantitatively. Notably, it achieves 29.1 FVD on VoxCeleb, improving upon a concurrent work 3DVidGen (Bahmani et al, 2022) by 55.6%. PV3D can also generate high-quality 3D geometry, achieving the best multi-view identity similarity and warping error across all datasets.
Our contributions are three-fold. 1) To our best knowledge, PV3D is the first method that is capable to generate a large variety of 3D-aware portrait videos with high-quality appearance, motions, and geometry. 2) We propose a novel temporal tri-plane based video generation framework that can synthesize 3D-aware portrait videos by learning from 2D videos only. 3) We demonstrate state-ofthe-art 3D-aware portrait video generation on three datasets. Moreover, our PV3D supports several downstream applications, i.e., static image animation, monocular video reconstruction, and multiview consistent motion editing.
如图1所示,尽管PV3D仅从单眼2D视频进行训练,但它可以在任意视点下生成大量具有多种运动和高质量3D几何形状的逼真人像视频。在各种数据集上的综合实验,包括VoxCeleb (Nagrani等人,2017),CelebV-HQ (Zhu等人,2022)和TalkingHead-1KH (Wang等人,2021a),都很好地证明了PV3D在定性和定量上优于以前最先进的方法。值得注意的是,它在VoxCeleb上实现了29.1 FVD,比并发工作3DVidGen (Bahmani et al, 2022)提高了55.6%。PV3D还可以生成高质量的3D几何图形,在所有数据集上实现最佳的多视图识别相似性和翘曲误差。
我们的贡献有三方面。1)据我们所知,PV3D是第一种能够生成各种具有高质量外观,运动和几何形状的3d感知人像视频的方法。2)提出了一种新的基于时间三平面的视频生成框架,该框架仅通过学习2D视频即可合成3d感知人像视频。3)我们在三个数据集上展示了最先进的3d感知人像视频生成。此外,我们的PV3D支持几个下游应用,即静态图像动画,单目视频重建和多视图一致的运动编辑。
DATASET PREPROCESSING
VoxCeleb (Nagrani et al, 2017; Chung et al, 2018) is an audio-visual speaker verification dataset containing interview videos for more than 7,000 speakers. It provides speaker labels for each video clip. For each speaker, we sample two video clips that have the highest video resolutions.
CelebV-HQ (Zhu et al, 2022) is a large-scale face video dataset that provides high-quality video clips involving 15,653 identities. Compared with VoxCeleb, it contains diverse lighting conditions.
TalkingHead-1KH (Wang et al, 2021a) consists of talking head videos extracted from 2,900 long video conferences.
VoxCeleb (Nagrani et al, 2017;Chung等人,2018)是一个视听演讲者验证数据集,包含超过7000名演讲者的采访视频。它为每个视频剪辑提供扬声器标签。对于每个讲话者,我们采样两个具有最高视频分辨率的视频剪辑。
CelebV-HQ (Zhu et al, 2022)是一个大规模的人脸视频数据集,提供了涉及15,653个身份的高质量视频剪辑。与VoxCeleb相比,它包含了多样化的照明条件。
TalkingHead-1KH (Wang et al ., 2021a)由从2900个长视频会议中提取的talking head视频组成。
EVALUATION METRICS
FVD: Frechet Video Distance 视频距离
ID: Multi-view Identity Consistency 多视图身份一致性
CD: Chamfer Distance 倒角距离 使用正面和侧面点云之间的倒角距离来测量3D几何的多视图一致性
WE: Multi-view Image Warping Errors 多视图图像扭曲错误

我们的PV3D有几个限制:
1)PV3D是在最多包含48帧的视频剪辑上训练和测试的。该模型对长期(分钟级)动态建模的能力尚不清楚。
2) 2D视频数据集质量无法与FFHQ、CelebA等图像数据集相比。我们的模型具有灵活的架构,可以支持图像数据集的预训练或联合训练,然而这种增强策略尚未被探索,尽管它很有前途和意义。对于未来的工作,我们将探索用更适合3D视频生成的新型3D表示建模长期动态,并利用高质量的图像数据集进行数据增强。

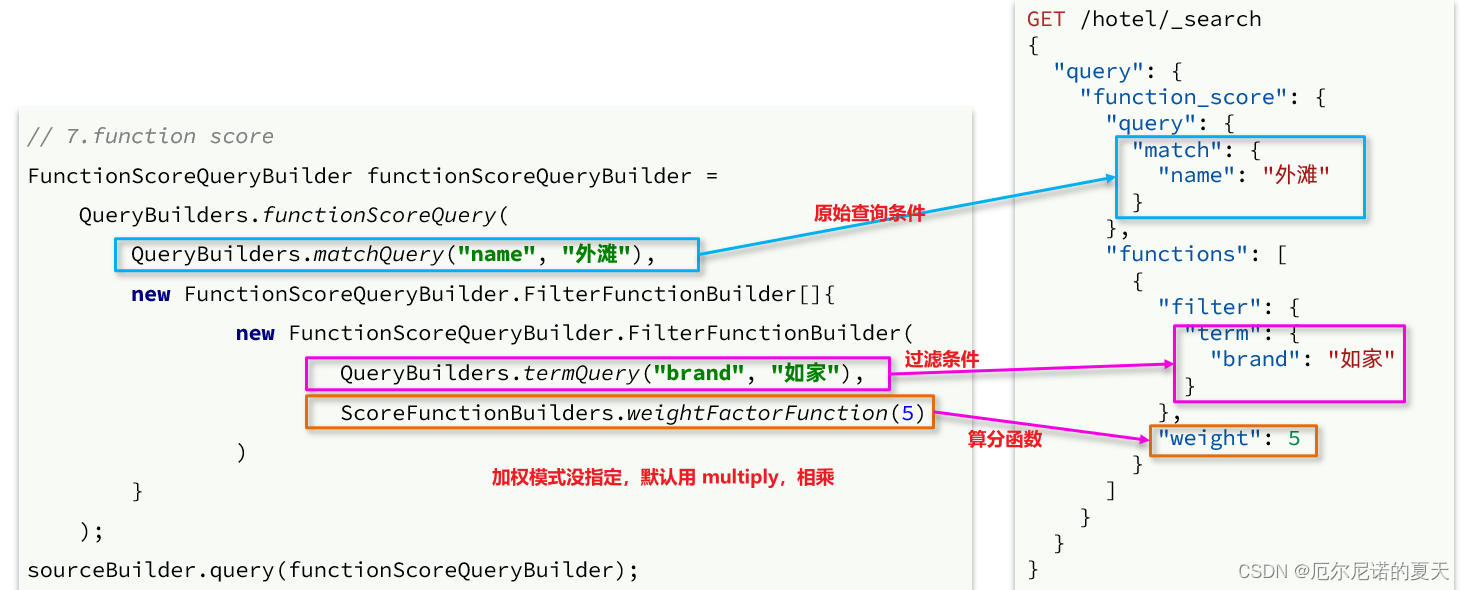
![[保研/考研机试] KY212 二叉树遍历 华中科技大学复试上机题 C++实现](https://img-blog.csdnimg.cn/39a1403c94a349c0b5200197e7bf3965.png)


![【LeetCode-经典面试150题-day9]](https://img-blog.csdnimg.cn/img_convert/782086183cb0869cded4e389e8150bd7.jpeg)