如何统计文章中高频词?是我们经常遇到的问题,也是多场合考察个人知识整合能力的重要手段。招聘经典问题:linux中命令行统计文件中前10个高频词。
在讨论此问题中,主要应用到的知识点有:排序、去重、单词查询、grep、sed和awk使用。
本文分四种情况,逐一分析讨论。
一、单列多行单词
这种情况比较简单,不需要作分隔处理,直接进行单词排序与去重,再排序。
1.文本素材
cat test1.txt
hello
world
you
hello
are
world
hello
2.命令
cat test1.txt |sort |uniq -c |sort -r
通过查看文件,所有单词都显示出来了。
sort 排序后,相同的单词排在一起(这是去重的必要条件)。
uniq –c 统计单词重复的次数
sort -r 指定顺序为从大到小
3.效果

二、第一列单词
这种情况比较简单,不需要作分隔处理,直接进行单词排序与去重,再排序。
1.文本素材
为了简单起见,假设文本素材中只包括小写字母和 ' '。
cat test2.txt
hello a1234
world weripa
you are working
hello alice
are one
world two
hello six
2.命令
相较于第一类情况,统计难度加大。我们要解决的问题是如何获取第一列内容。获得第一列后就可以与前一类情况同样处理了。
a.cut
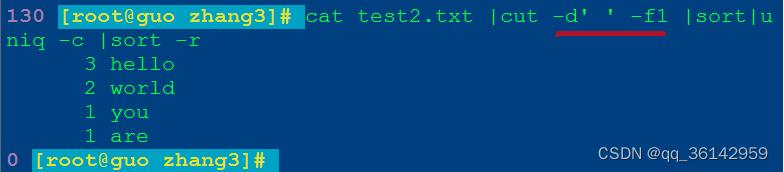
cat test2.txt |cut -d' ' -f1 |sort|uniq -c |sort –r
-f1 切割后仅保留第1列
b.grep
grep -Eo '^[[:alpha:]]+' test2.txt|sort|uniq -c|sort -r
grep -E 执行扩展正则,-o仅显示匹配单词
^[[:alpha:]]+ 开头的第一个英语单词
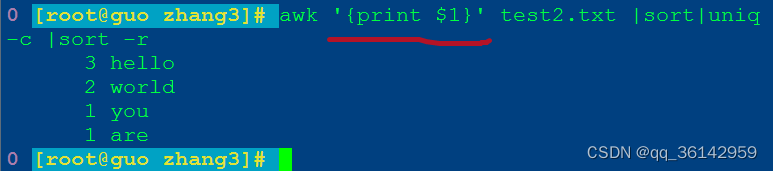
c.awk
awk '{print $1}' test2.txt |sort|uniq-c |sort -r
'{print $1}' 仅输出文件第1列
3.效果
cut命令执行效果
grep命令执行效果
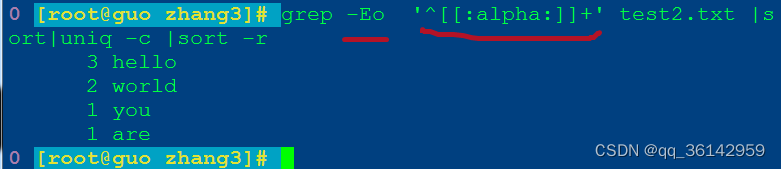
awk命令执行效果
三、单词与空格
这种情况仅需要作分隔处理,把单个或多个空格替换为换行符。然后进行单词排序与去重,再排序。
1.文本素材
为了简单起见,假设文本素材中每个单词只由小写字母组成,单词间由一个或多个空格字符分隔。
cat test3.txt
my name is shantong
my qq num is 845537614
my ip is 192.168.1.171
123 222 345
12345 789
my email is 845537614
my telephone num is 13523072436
servername is chaoxing
company site is hnqz
mmmmmmmm
192.168.89.115
2.命令
相较于前两类情况,此类问题难度也不大。我们仅需要把空格替换为换行符。所有单词变为一列内容后就可以与前两类情况同样处理。
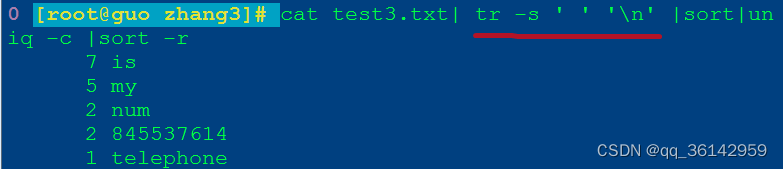
a.tr
cat test3.txt| tr -s ' ' '\n'|sort|uniq -c |sort -r
tr -s ' ' '\n' #空格换行并清除空行
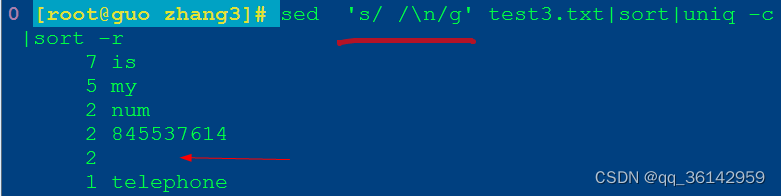
b.sed
sed 's/ /\n/g' test3.txt|sort|uniq -c |sort -r
sed 's/ /\n/g'
s表示替换,\n表示换行符,s/ /\n/将空格替换为换行符,最后的g标志表示全部替换
整理文本内容,使得每个单词占一行:
sed '/^$/d' #删除所有空行
3.效果
tr命令执行效果
sed命令执行效果
删除空行后效果

四、任意文本
这种情况是最普通的。不作任何设定,对任意一个文件进行高频词统计。
主要思路就是:把文本进行分隔,仅保留单词。根据文本的常用格式,需要用不同的分隔符。
处理单词时,先排序,再去重,最后仍然要排序。
此类情况,需要把前面的命令综合起来,完成高频词统计
1.文本素材
cat test4.txt
123 222 345
my name is shantong
12345 789
my qq number is 36142959
my email is 36142959@qq.com
my ip is 192.168.1.141
my name is zhange
My telephone num is 13523072436
My qq number is 845537614
Server_name is Softeem
Company Site is http://www.pili-zz.net
MMMM1234
192.168.89.115
2.命令
相较于前三类情况,此类问题难度很大。我们不仅需要分隔单词,还需要把单词排序、去重和再排序。考虑到文本中单词较多,可以仅获取前5个单词。
a.sed awk
sed 's/[,.:;/!_@?]/ /g' test4.txt |awk '{for(i=1;i<=NF;i++)array[$i]++;}END{for(i in array) print i,array[i]}' |sort -nr -k 2 |head -5
b.awk
awk 'BEGIN{RS="[,.:;/!?]"} {for(i=1;i<=NF;i++)array[$i]++;}END{for(i in array) print i,array[i]}' test4.txt |sort -nr -k 2 |head -5
我们经常会说,awk是基于行列操作文本的,但如何定义“行”呢?这就是RS的作用。
默认情况下,RS的值是\n。我们可以改变RS变量的值,为不同的分隔符。本案例中,RS的值是多个字符。
3.效果
sed awk

awk

小结
通过统计文本中的高频单词,综合应用命令cat cut tr sort uniq等,特别是linux三剑客grep、sed和awk。在实际应用中,情况会更复杂,可能需要编程处理。但掌握基本命令的各种应用十分重要,值得学习与巩固。