分布式搜索ES
- 11.分布式搜索 ES
- a.介绍ES
- b.IK分词器
- c.索引库操作 (类似于MYSQL的Table)
- d.查看、删除、修改 索引库
- e.文档操作 (类似MYSQL的数据)
- 1) 添加文档
- 2) 查看文档
- 3) 删除文档
- 4) 修改文档
- f.RestClient操作索引库
- 1) 创建索引库
- 2) 删除索引库/判断索引库
- g.RestClient操作文档
- 1) 新增文档
- 2) 查询文档
- 3) 修改文档
- 4) 删除文档
- 5) 批量导入数据到ES
- h.DSL查询文档
- 1) 查询所有
- 2) 全文检索查询
- 3) 精确查询
- 4) 地理查询
- 5) 复合查询
- 1) Function Score Query
- 2) Boolean Query
- i.DSL搜索结果处理
- 1) 排序
- 2) 分页
- 3) 高亮
- j.RestClient查询文档
- 1) 全文检索文档
- 2) 排序和分页
- 3) 高亮
11.分布式搜索 ES
a.介绍ES
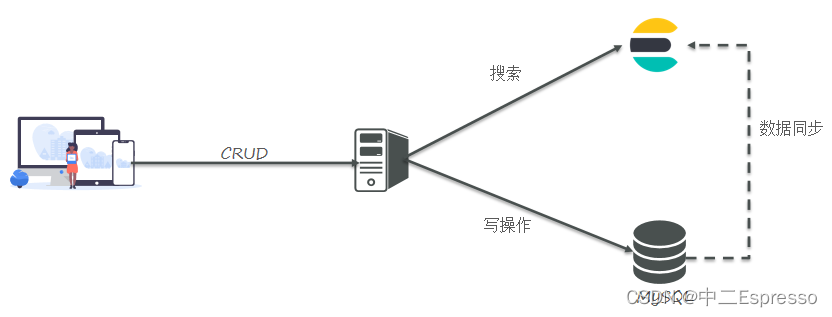
elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域。
elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
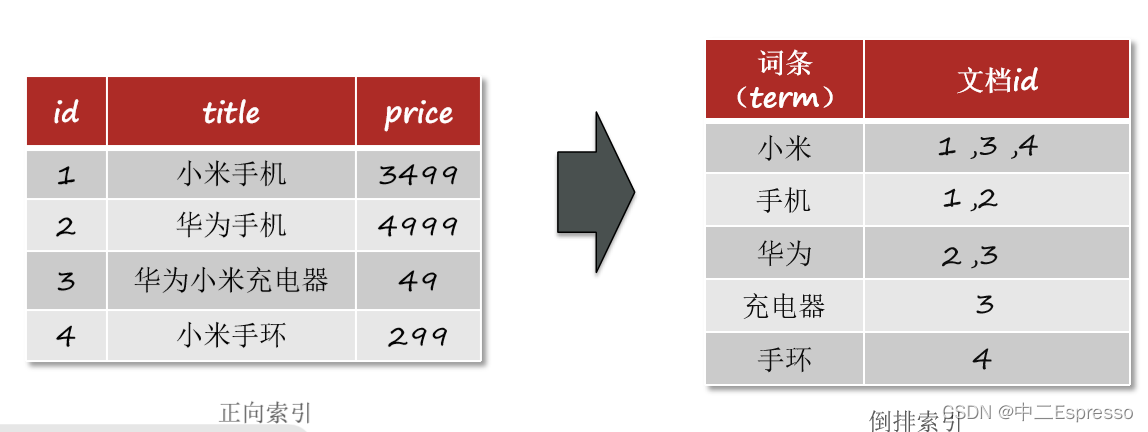
正向索引和倒排索引
传统数据库(如MySQL)采用正向索引
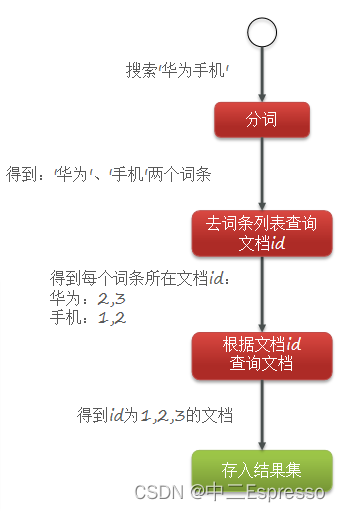
elasticsearch采用倒排索引:
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语
文档
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。
文档数据会被序列化为json格式后存储在elasticsearch中。

索引(Index)
-
索引(index):相同类型的文档的集合
-
映射(mapping):索引中文档的字段约束信息,类似表的结构约束

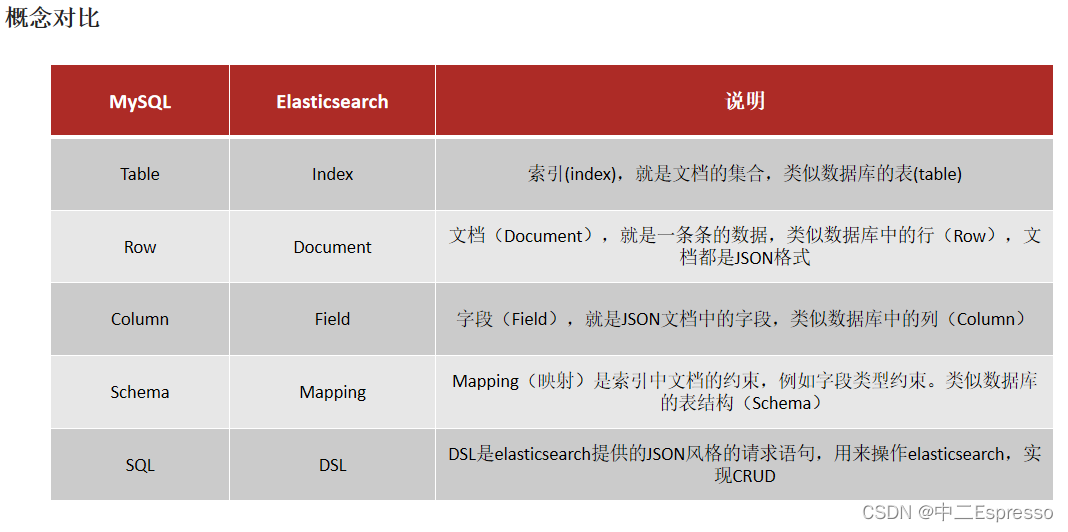
架构
- Mysql:擅长事务类型操作,可以确保数据的安全和一致性
- Elasticsearch:擅长海量数据的搜索、分析、计算
b.IK分词器
分词器的作用是什么?
- 创建倒排索引时对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
- 利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
- 在词典中添加拓展词条或者停用词条
c.索引库操作 (类似于MYSQL的Table)
mapping是对索引库中文档的约束,常见的mapping属性包括:
-
type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
-
index:是否创建索引,默认为true
-
analyzer:使用哪种分词器
-
properties:该字段的子字段

创建索引库
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:

# 创建索引库
PUT /heima
{"mappings": {"properties": {"info":{"type": "text","analyzer": "ik_smart"},"email":{"type":"keyword","index": false},"name":{"type":"object","properties": {"firstname":{"type": "keyword"},"lastname":{"type": "keyword"}}}}}
}
d.查看、删除、修改 索引库
查看索引库语法:
GET /索引库名
示例:
GET /heima
删除索引库的语法:
DELETE /索引库名
示例:
DELETE /heima
修改索引库
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}
示例:
PUT /heima/_mapping
{"properties": {"age":{"type": "integer"}}
}
e.文档操作 (类似MYSQL的数据)
1) 添加文档
新增文档的DSL语法如下:

# 插入文档
POST /heima/_doc/1
{"info": "黑马程序员","email": "abcd@qq.com","name":{"firstname": "云","lastname" : "赵"}
}
2) 查看文档
查看文档语法:
GET /索引库名/_doc/文档id
示例:
GET /heima/_doc/1
3) 删除文档
删除文档的语法:
DELETE /索引库名/_doc/文档id
示例:
DELETE /heima/_doc/1
4) 修改文档
方式一:全量修改,会先删除旧文档,再添加新文档

# 全量修改文档
PUT /heima/_doc/3
{"info": "黑马程序员","email": "zhaoyun@123.com","name":{"firstname": "云","lastname" : "赵"}
}
方式二:增量修改,修改指定字段值

# 局部修改
POST /heima/_update/1
{"doc":{"email": "zYUN@qq.com"}
}
f.RestClient操作索引库
1.引入es的RestHighLevelClient依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version>
</dependency>
2.因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
<properties><java.version>1.8</java.version><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
3.初始化RestHighLevelClient:
public class HotelIndexTest {private RestHighLevelClient client;@Testvoid testInit(){System.out.println(client);}@BeforeEachvoid setUp(){this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.58.128:9200")));}@AfterEachvoid afterAll() throws Exception {this.client.close();}
}
1) 创建索引库
创建索引库代码如下:
@Test
void createHotelIndex() throws Exception {// 1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("hotel");// 2.准备请求的参数:DSL语句request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.发送请求client.indices().create(request, RequestOptions.DEFAULT);
}
在constants/HotelConstant中写入已编辑好的DSL语句
package cn.itcast.hotel.constants;public class HotelConstants {public static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\":{\n" +" \"properties\": {\n" +" \"id\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
}
2) 删除索引库/判断索引库
删除索引库代码如下:
/*** 删除索引库* @throws Exception*/
@Test
void testDeleteHotelIndex() throws Exception{// 1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("hotel");// 2.发送请求client.indices().delete(request, RequestOptions.DEFAULT);
}
判断索引库代码如下:
/*** 判断索引库是否存在* @throws Exception*/
@Test
void testExistsHotelIndex() throws Exception{// 1.创建Request对象GetIndexRequest request = new GetIndexRequest("hotel");// 2.发送请求boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);// 3.输出System.out.println(exists ? "索引库已经存在" : "索引库不存在");
}
g.RestClient操作文档
1) 新增文档
先查询酒店数据,然后给这条数据创建倒排索引,即可完成添加:
@Autowired
private IHotelService hotelService;/*** 新增文档*/
@Test
void testAddDocument() throws IOException {// 根据id查询酒店数据Hotel hotel = hotelService.getById(61083L);// 转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 1.准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());// 2.准备json文档request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);
}
2) 查询文档
根据id查询到的文档数据是json,需要反序列化为java对象:
/*** 查询文档* @throws Exception*/
@Test
void testGetDocument() throws Exception{// 1.准备RequestGetRequest request = new GetRequest("hotel", "61083");// 2.发送请求,得到响应GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3.解析响应结果String json = response.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println(hotelDoc);
}
3) 修改文档
修改文档数据有两种方式:
- 方式一:全量更新。再次写入id一样的文档,就会删除旧文档,添加新文档
- 和新增代码没有区别
- 方式二:局部更新。只更新部分字段
/*** 更新文档* @throws Exception*/
@Test
void testUpdateDocumentById() throws Exception {// 1.创建Request对象UpdateRequest request = new UpdateRequest("hotel", "61083");// 2.准备参数,每2个参数为一对 key valuerequest.doc("price","952","starName","四钻");// 3.更新文档client.update(request, RequestOptions.DEFAULT);
}
4) 删除文档
删除文档代码如下:
/*** 删除文档* @throws Exception*/
@Test
void testDeleteDocument() throws Exception{// 1.创建Request对象DeleteRequest request = new DeleteRequest("hotel", "61083");// 3.更新文档client.delete(request, RequestOptions.DEFAULT);
}
5) 批量导入数据到ES
需求:批量查询酒店数据,然后批量导入索引库中
- 1.利用mybatis-plus查询酒店数据
- 2.将查询到的酒店数据(Hotel)转换为文档类型数据(HotelDoc)
- 3.利用JavaRestClient中的Bulk批处理,实现批量新增文档,示例代码如下
/*** 批量导入数据到ES* @throws Exception*/
@Test
void testBulkRequest() throws Exception {// 批量查询酒店数据List<Hotel> hotels = hotelService.list();// 1.创建Request对象BulkRequest request = new BulkRequest();// 2.准备参数, 添加多个新增的Requestfor (Hotel hotel : hotels) {// 转换为文档类型HotelDocHotelDoc hotelDoc = new HotelDoc(hotel);// 创建新增文档的Request对象request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}// 3.发送请求client.bulk(request, RequestOptions.DEFAULT);
}
h.DSL查询文档
ES提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
- 查询所有:查询出所有数据,一般测试用。例如:match_all
- 全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。
- match_query
- multi_match_query
- 精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。
- ids
- range
- term
- 地理(geo)查询:根据经纬度查询。
- geo_distance
- geo_bounding_box
- 复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。
- bool
- function_score
1) 查询所有
DSL Query基本语法
查询的基本语法如下: 查询所有不需要指定条件值

# 查询所有
GET /hotel/_search
{"query": {"match_all": {}}
}
2) 全文检索查询
全文检索查询,会对用户输入内容分词,常用于搜索框搜索:
- match查询 (推荐):全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索

# match查询
GET /hotel/_search
{"query": {"match": {"all": "外滩如家"}}
}
- multi_match:与match查询类似,只不过允许同时查询多个字段 (参与查询的字段越多,会降低性能)
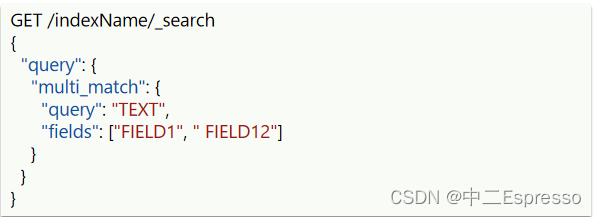
# multi_match查询
GET /hotel/_search
{"query": {"multi_match": {"query": "外滩如家","fields": ["brand", "name", "business"]}}
}
3) 精确查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
- term:根据词条精确值查询 (如:品牌名,城市名,城市星级)
- range:根据值的范围查询 (如:价格,日期,评分)

# term查询
GET /hotel/_search
{"query": {"term": {"city": {"value": "深圳"}}}
}
# range查询
GET /hotel/_search
{"query": {"range": {"price": {"gte": 1000,"lte": 3000}}}
}
gte 大于等于,gt 大于,lte 小于等于,lt 小于
4) 地理查询
根据经纬度查询。常见的使用场景包括:
- 携程:搜索我附近的酒店
- 滴滴:搜索我附近的出租车
- 微信:搜索我附近的人
根据经纬度查询,官方文档。例如:
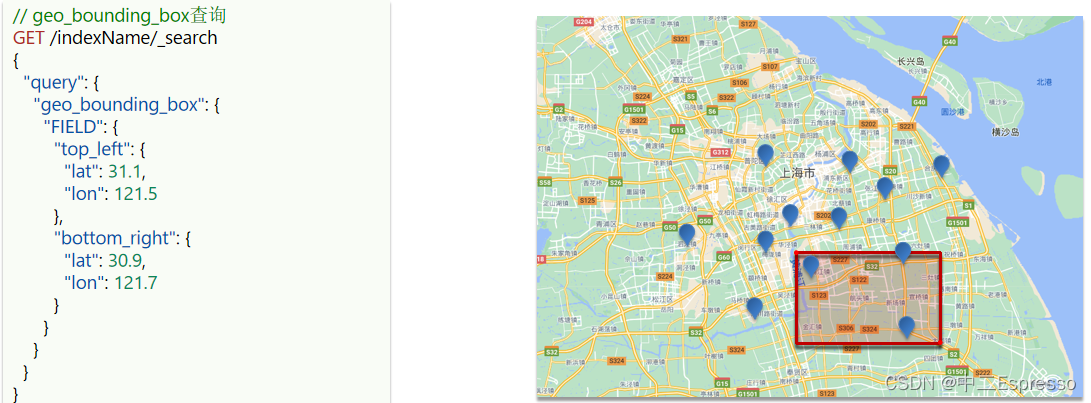
- geo_bounding_box:查询geo_point值落在某个矩形范围的所有文档
- geo_distance:查询到指定中心点小于某个距离值的所有文档
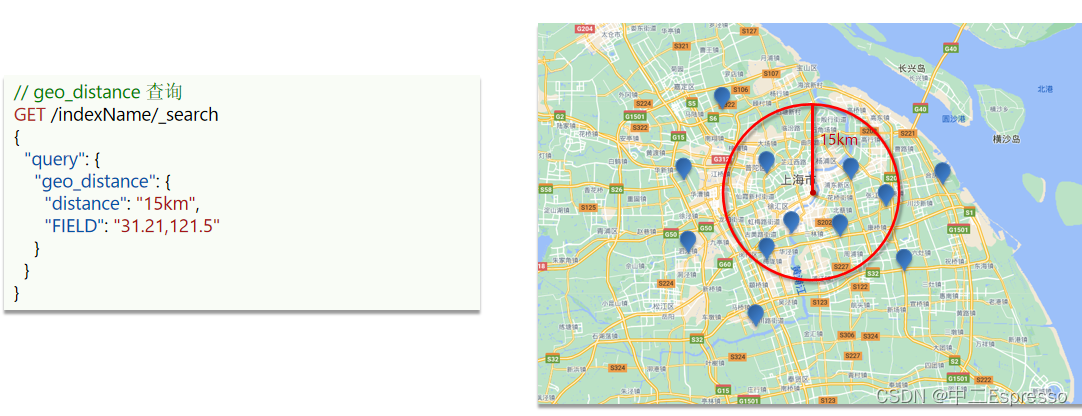
# geo_distance查询
GET /hotel/_search
{"query": {"geo_distance": {"distance": "5km","location": "31.21, 121.5"}}
}
5) 复合查询
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑
- fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名。例如百度竞价
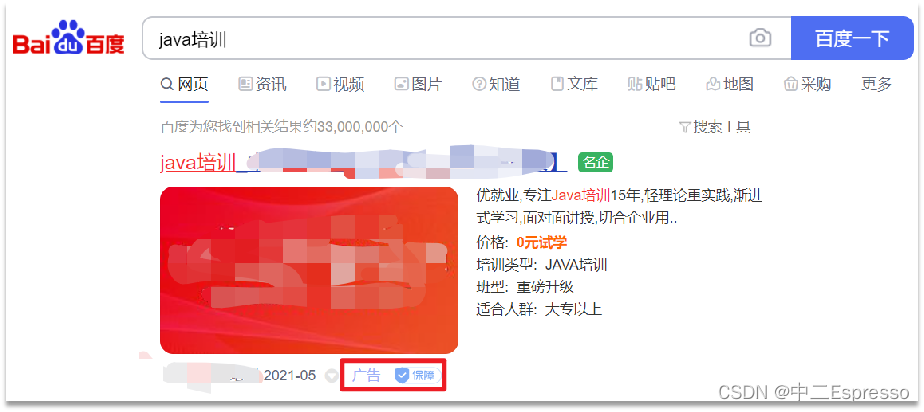
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
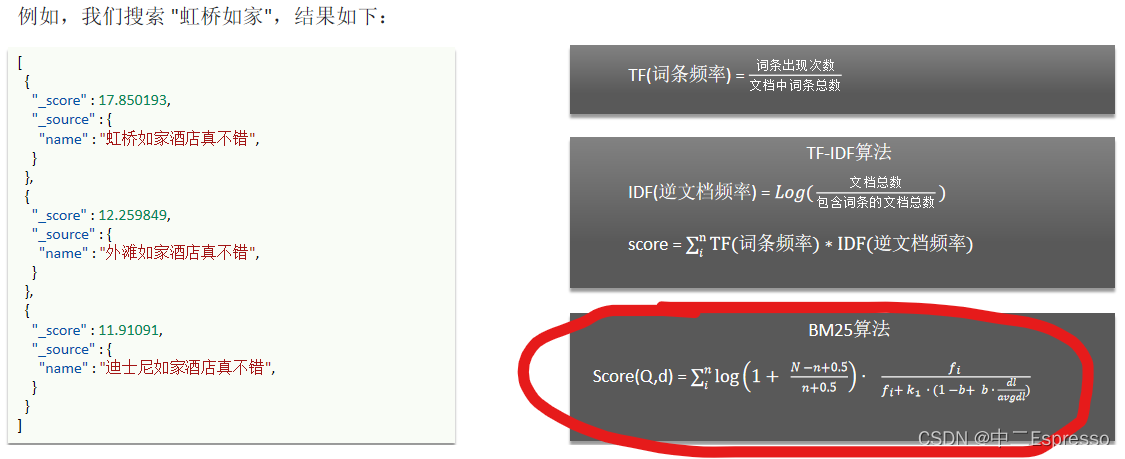
1) Function Score Query
使用 function score query,可以修改文档的相关性算分(query score),根据新得到的算分排序。
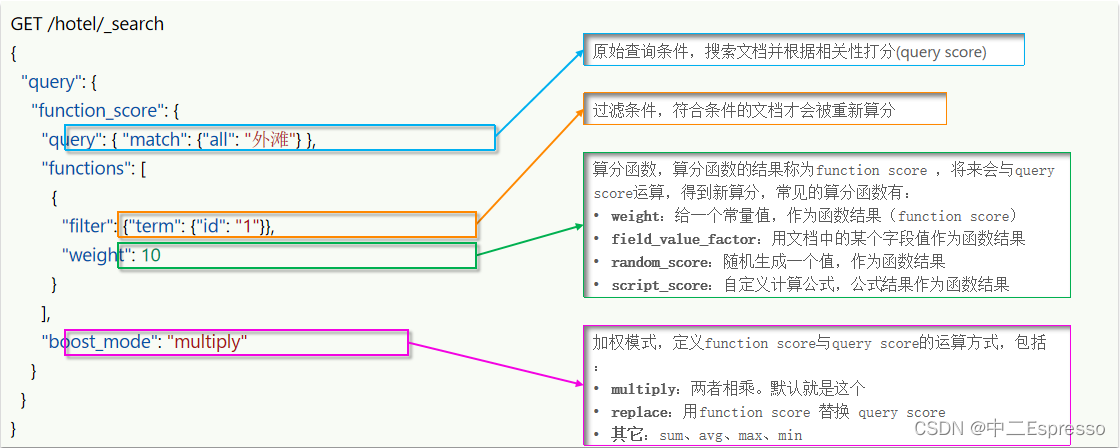
案例:给“外滩如家”这个品牌的酒店排名靠前一些
- 1.哪些文档需要算分加权? 品牌为如家的酒店
- 2.算分函数是什么? weight就可以
- 3.加权模式是什么? 求和
# function_score查询
GET /hotel/_search
{"query": {"function_score": {"query": {"match": {"all": "外滩"}},"functions": [{"filter": {"term": {"brand": "如家"}},"weight": 10}],"boost_mode": "sum"}}
}
2) Boolean Query
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分

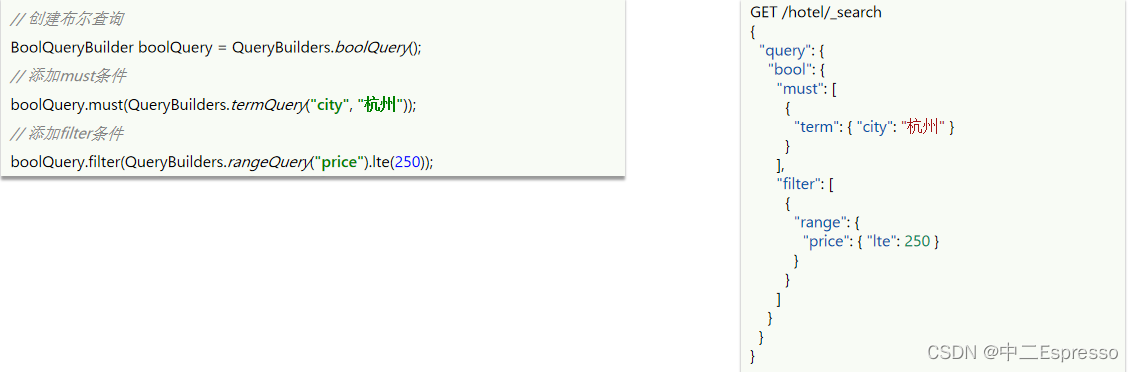
案例:利用bool查询实现功能,需求:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
# boolean查询
GET /hotel/_search
{"query": {"bool": {"must": [{"match": {"name": "如家"}}],"must_not": [{"range": {"price": {"gt": 400}}}],"filter": [{"geo_distance": {"distance": "10km","location": {"lat": 31.21, "lon": 121.5}}}]}}
}
i.DSL搜索结果处理
1) 排序
ES支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
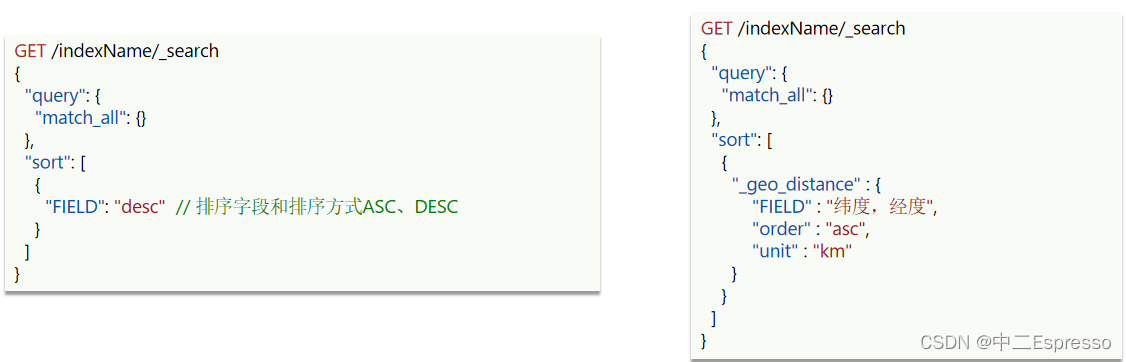
案例:对酒店数据按照用户评价降序排序,评价相同的按照价格升序排序
- 评价是score字段,价格是price字段,按照顺序添加两个排序规则即可。
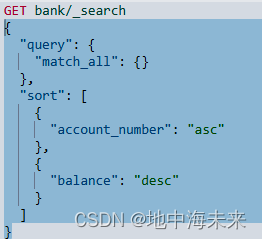
# sort排序
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"score": "desc"},{"price": "asc"}]
}
案例:实现对酒店数据按照到你的位置坐标的距离升序排序
- 获取经纬度的方式:https://lbs.amap.com/demo/jsapi-v2/example/map/click-to-get-lnglat/
- lon:113.766782, lat:23.012575
# 距离排序
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"location": {"lat": 23.012575,"lon": 113.766782},"order": "asc","unit": "km"}}]
}
2) 分页
ES 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
ES中通过修改from、size参数来控制要返回的分页结果:

深度分页解决方案
针对深度分页,ES提供了两种解决方案:
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
- scroll:原理将排序数据形成快照,保存在内存。官方已经不推荐使用。
from + size:
- 优点:支持随机翻页
- 缺点:深度分页问题,默认查询上限(from + size)是10000
- 场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
after search:
-
优点:没有查询上限(单次查询的size不超过10000)
-
缺点:只能向后逐页查询,不支持随机翻页
-
场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
scroll:
-
优点:没有查询上限(单次查询的size不超过10000)
-
缺点:会有额外内存消耗,并且搜索结果是非实时的
-
场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议用 after search方案。
3) 高亮
高亮:就是在搜索结果中把搜索关键字突出显示。
原理是这样的:
- 将搜索结果中的关键字用标签标记出来
- 在页面中给标签添加css样式

默认情况下,ES搜索字段与高亮字段一致
- 可以加上是否匹配的参数 “require_field_match”: “false”,默认true
# 高亮查询,
GET /hotel/_search
{"query": {"match": {"all": "如家"}},"highlight": {"fields": {"name": {"require_field_match": "false"}}}
}
j.RestClient查询文档
通过match_all来演示下基本的API,先看请求DSL的组织:


/*** match_all* @throws IOException*/
@Test
void testMatchAll() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSLrequest.source().query(QueryBuilders.matchAllQuery());// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果handleResponse(response);
}/*** 抽取出解析结果的代码*/
private void handleResponse(SearchResponse response) {// 4.解析结果SearchHits searchHits = response.getHits();// 4.1.查询的总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 4.2.查询的文档数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// 4.3.获取文档sourceString json = hit.getSourceAsString();// 4.4.反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println("hotelDoc = " + hotelDoc);}
}
RestAPI中其中构建DSL是通过HighLevelRestClient中的resource()来实现的,其中包含了查询、排序、分页、高亮等所有功能:
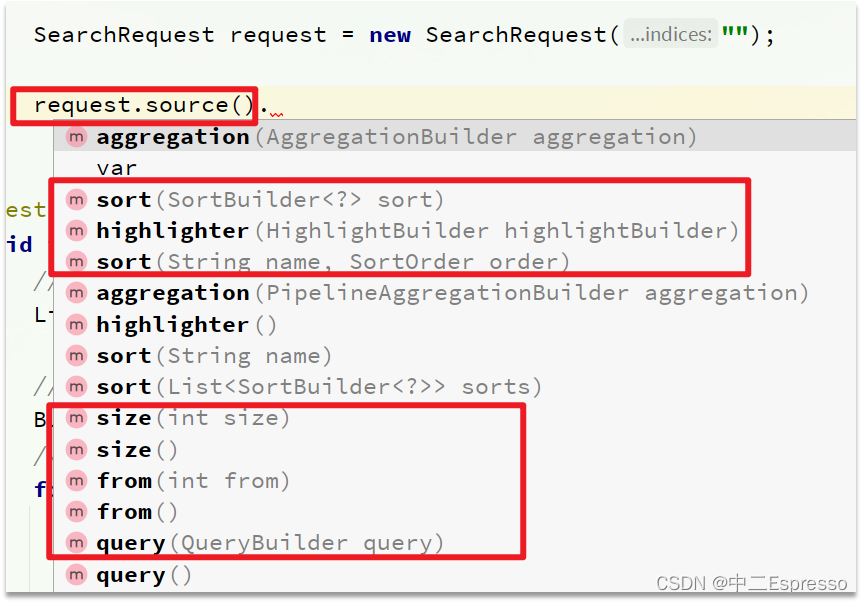
RestAPI中其中构建查询条件的核心部分是由一个名为QueryBuilders的工具类提供的,其中包含了各种查询方法:

1) 全文检索文档
全文检索的match和multi_match查询与match_all的API基本一致。差别是查询条件,也就是query的部分。
同样是利用QueryBuilders提供的方法:


/*** match / multi_match / term / range / Boolean Query* @throws IOException*/
@Test
void testMatch() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL
// request.source().query(QueryBuilders.matchQuery("all", "上海如家")); // match
// request.source().query(QueryBuilders.multiMatchQuery("上海如家", "name", "brand", "business")); // match_all
// request.source().query(QueryBuilders.termQuery("city", "深圳")); // term
// request.source().query(QueryBuilders.rangeQuery("price").gte(100).lte(550)); // range// Boolean Query 创建布尔查询BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 添加must条件boolQuery.must(QueryBuilders.termQuery("city", "深圳"));// 添加filter条件boolQuery.filter(QueryBuilders.rangeQuery("price").gte(200).lte(500));request.source().query(boolQuery);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果handleResponse(response);
}
要构建查询条件,只要记住一个类:QueryBuilders
2) 排序和分页
搜索结果的排序和分页是与query同级的参数,对应的API如下:
/*** 排序和分页* @throws IOException*/
@Test
void testPageAndSort() throws IOException {// 模拟前端传值的 页码,每页大小int page = 1, size = 5;// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL// 2.1.queryrequest.source().query(QueryBuilders.matchAllQuery());// 2.2.排序sortrequest.source().sort("price", SortOrder.ASC);// 2.3.分页 from、sizerequest.source().from((page - 1) * size).size(size);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果handleResponse(response);
}
3) 高亮
高亮API包括请求DSL构建和结果解析两部分。

/*** 高亮* @throws IOException*/
@Test
void testHighlight() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL// 2.1.queryrequest.source().query(QueryBuilders.matchQuery("all", "如家"));// 2.2.highlightrequest.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果handleResponse(response);
}
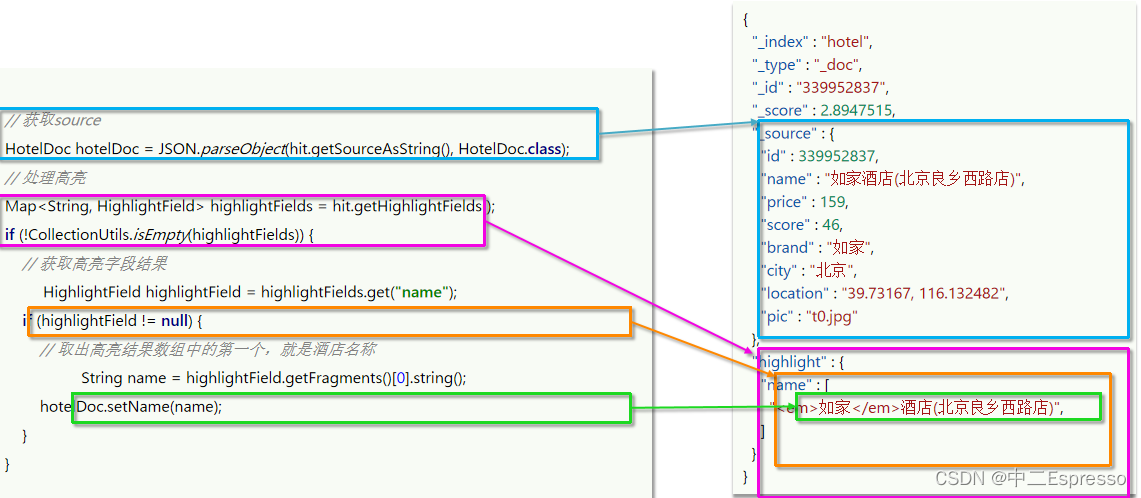
在解析结果的类上,加上解析高亮的处理逻辑
private void handleResponse(SearchResponse response) {// 4.解析结果SearchHits searchHits = response.getHits();// 4.1.查询的总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 4.2.查询的文档数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// 4.3.获取文档sourceString json = hit.getSourceAsString();// 4.4.反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);// 获取高亮结果Map<String, HighlightField> highlightFields = hit.getHighlightFields();if (!CollectionUtils.isEmpty(highlightFields)) {// 根据字段名获取高亮结果HighlightField highlightField = highlightFields.get("name");if (highlightField != null){// 获取高亮值String name = highlightField.getFragments()[0].string();// 覆盖非高亮结果hotelDoc.setName(name);}}System.out.println("hotelDoc = " + hotelDoc);}
}