【项目初始化】


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/10419.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

一文读懂 Faiss:开启高维向量高效检索的大门
一、引言
在大数据与人工智能蓬勃发展的当下,高维向量数据如潮水般涌现。无论是图像、音频、文本,还是生物信息领域,都离不开高维向量来精准刻画数据特征。然而,在海量的高维向量数据中进行快速、准确的相似性搜索,却…

基于Django的Boss直聘IT岗位可视化分析系统的设计与实现
【Django】基于Django的Boss直聘IT岗位可视化分析系统的设计与实现(完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介
该系统采用Python作为主要开发语言,利用Django这一高效、安全的W…

python 语音识别
目录
一、语音识别
二、代码实践
2.1 使用vosk三方库
2.2 使用SpeechRecognition
2.3 使用Whisper 一、语音识别
今天识别了别人做的这个app,觉得虽然是个日记app 但是用来学英语也挺好的,能进行语音识别,然后矫正语法,自己说的时候 ,实在不知道怎么说可以先乱说,然…

栈和队列特别篇:栈和队列的经典算法问题
图均为手绘,代码基于vs2022实现 系列文章目录
数据结构初探: 顺序表 数据结构初探:链表之单链表篇 数据结构初探:链表之双向链表篇 链表特别篇:链表经典算法问题 数据结构:栈篇 数据结构:队列篇 文章目录 系列文章目录前言一.有效的括号(leetcode 20)二.用队列实现栈(leetcode…

使用 OpenResty 构建高效的动态图片水印代理服务20250127
使用 OpenResty 构建高效的动态图片水印代理服务
在当今数字化的时代,图片在各种业务场景中广泛应用。为了保护版权、统一品牌形象,动态图片水印功能显得尤为重要。然而,直接在后端服务中集成水印功能,往往会带来代码复杂度增加、…


Java开发vscode环境搭建
1 几个名词
JDK Java Development Kit JRE Java Runtion Environment JVM
JDK 包括 Compiler,debugger,JRE等。JRE包括JVM和Runtime Library。
2 配置环境
2.1 安装JDK
类比 C/C的 g工具
官网:https://www.oracle.com/java/technologies/downloads/ 根据自己使…

pytorch基于FastText实现词嵌入
FastText 是 Facebook AI Research 提出的 改进版 Word2Vec,可以: ✅ 利用 n-grams 处理未登录词 比 Word2Vec 更快、更准确 适用于中文等形态丰富的语言
完整的 PyTorch FastText 代码(基于中文语料),包含࿱…

riscv xv6学习笔记
文章目录 前言util实验sleeputil实验pingpongutil实验primesxv6初始化代码分析syscall实验tracesyscall实验sysinfoxv6内存学习笔记pgtbl实验Print a page tablepgtbl实验A kernel page table per processxv6 trap学习trap实验Backtracetrap实验Alarmlazy实验Lazy allocationxv…

FFmpeg(7.1版本)编译:Ubuntu18.04交叉编译到ARM
一、本地编译与交叉编译
1.本地编译
① 本地编译:指的是在目标系统上进行编译的过程 , 生成的可执行文件和函数库只能在目标系统中使用。
如 :
在 Ubuntu中,本地编译的可执行文件只能在Ubuntu 系统中执行 , 无法在 Windows / Mac / Android / iOS 系…

创新创业计划书|建筑垃圾资源化回收
目录 第1部分 公司概况........................................................................ 1 第2部分 产品/服务...................................................................... 3 第3部分 研究与开发.................................................…

如何利用天赋实现最大化的价值输出
这种文章,以我现在的实力很难写出来。所以需要引用一些视频。 上92高校容易吗
如果基于天赋努力,非常容易。
如果不是这样,非常非常难。 高考失败人生完蛋?复读考上交大,进入社会才发现学历只是一张纸,98…

LigerUI在MVC模式下的响应原则
LigerUI是基于jQuery的UI框架,故他也是遵守jQuery的开发模式,但是也具有其特色的侦听函数,那么当LigerUI作为View层的时候,他所发送后端的必然是表单的数据,在此我们以俩个div为例:
{Layout "~/View…

【力扣】49.字母异位词分组
AC截图 题目 思路
由于互为字母异位词的两个字符串包含的字母相同,因此对两个字符串分别进行排序之后得到的字符串一定是相同的,故可以将排序之后的字符串作为哈希表的键。
可以遍历strs,将其中每一个str排序,然后用unodered_ma…

docker安装nacos2.2.4详解(含:nacos容器启动参数、环境变量、常见问题整理)
一、镜像下载
1、在线下载
在一台能连外网的linux上执行docker镜像拉取命令 docker pull nacos:2.2.4 2、离线包下载
两种方式:
方式一:
-)在一台能连外网的linux上安装docker执行第一步的命令下载镜像
-)导出 # 导出镜像到…

【图床配置】PicGO+Gitee方案
【图床配置】PicGOGitee方案 文章目录 【图床配置】PicGOGitee方案为啥要用图床图床是什么配置步骤下载安装PicGoPicGo配置创建Gitee仓库Typora中的设置 为啥要用图床
在Markdown中,图片默认是以路径的形式存在的,类似这样 可以看到这是本地路径&#x…

【C++】类与对象(下)
🦄 个人主页: 小米里的大麦-CSDN博客 🎏 所属专栏: 小米里的大麦——C专栏_CSDN博客 🎁 代码托管: 小米里的大麦的Gitee仓库 ⚙️ 操作环境: Visual Studio 2022 文章目录 1. 再谈构造函数1.1 构造函数体赋值1.2 初始化列表1.3 explicit 关键…

SpringBoot笔记
1.创建
使用idea提供的脚手架创建springboot项目,选上需要的模块,会自动进行导包 打成jar包,之前直接用原生的maven打包的是一个瘦jar,不能直接跑,把服务器上部署的jar排除在外了,但是现在加上打包查件&am…
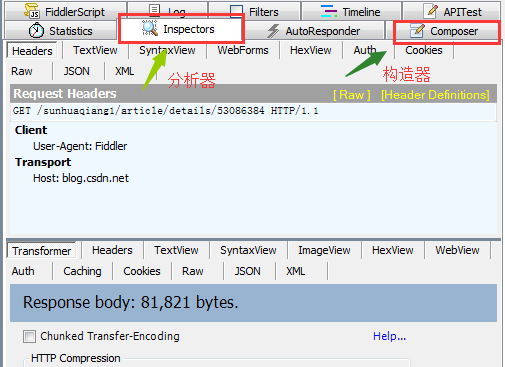
Fiddler(一) - Fiddler简介_fiddler软件
文章目录 一、为什么选择Fiddler作为抓包工具? 二、什么是Fiddler?三、Fiddler使用界面简介四、延伸阅读
一、为什么选择Fiddler作为抓包工具?
抓包工具有很多,小到最常用的web调试工具firebug,大到通用性强大的抓包工具wireshark。为什么使用fid…

受击反馈HitReact、死亡效果Death Dissolve、Floating伤害值Text(末尾附 客户端RPC )
受击反馈HitReact
设置角色受击标签
(GameplayTag基本了解待补充) 角色监听标签并设置移动速度 创建一个受击技能,并应用GE 实现设置角色的受击蒙太奇动画 实现角色受击时播放蒙太奇动画,为了保证通用性,将其设置为一个函数,并…
推荐文章
- 30 分钟从零开始入门 CSS
- 《redis哨兵机制》
- 《艾尔登法环》运行时弹窗“由于找不到vcruntime140.dll,无法继续执行代码”要怎么解决?
- 《探秘鸿蒙Next:非结构化数据处理与模型轻量化的完美适配》
- 《重生到现代之从零开始的C++生活》—— 类和对象1
- 【ARM】MDK如何将变量存储到指定内存地址
- 【C++初阶】第11课—vector
- 【Elasticsearch】simple_query_string
- 【Elasticsearch】分析器的构成
- 【GDB】 断点的相关设置
- 【git】【reset全解】Git 回到上次提交并处理提交内容的不同方式
- 【NLP 25、模型训练方式】