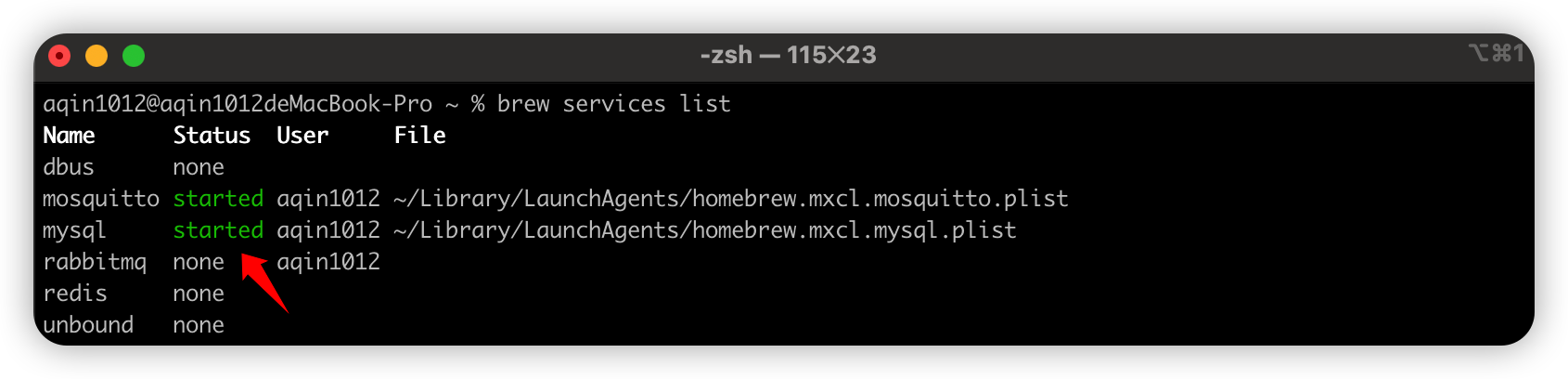
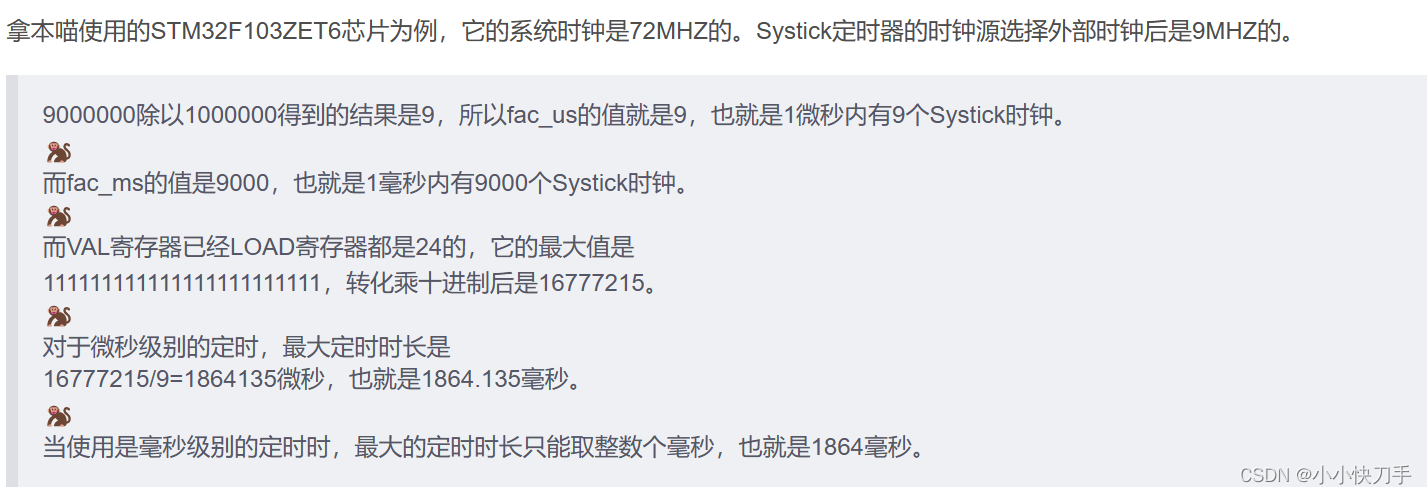
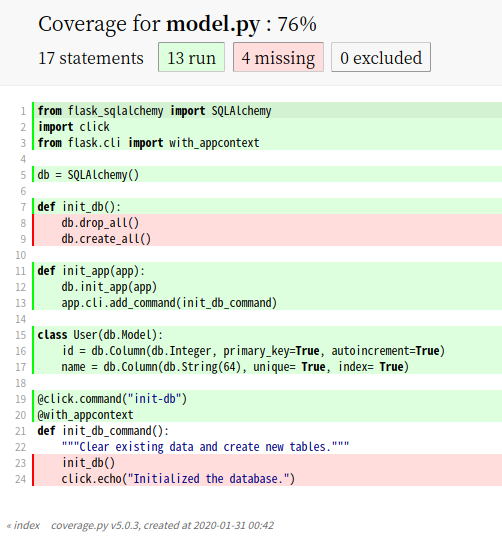
论文信息
题目:OVRL-V2: A simple state-of-art baseline for IMAGENAV and OBJECTNAV
作者:Karmesh Yadav, Arjun Majumdar, Ram Ramrakhya
来源:arxiv
时间:2023
代码地址: https://github.com/ykarmesh/OVRL
Abstract
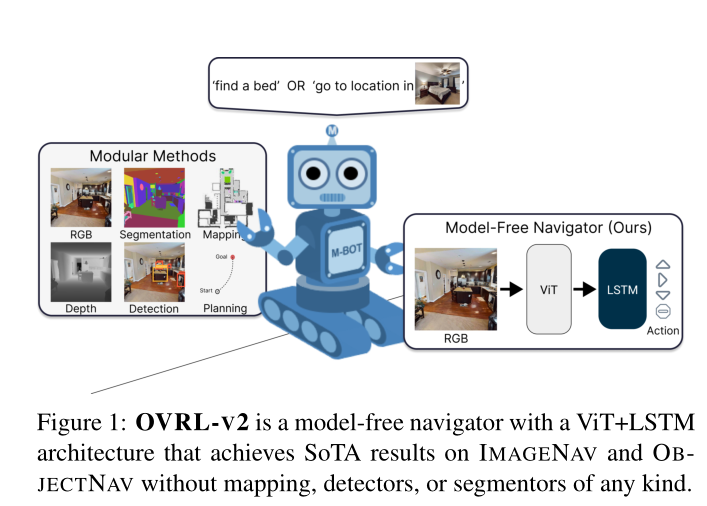
我们提出了一个由与任务无关的组件(ViT、卷积和 LSTM)组成的单一神经网络架构,该架构在 IMAGENAV(“转到 <这张图片> 中的位置”)和 OBJECTNAV(“查找椅子”)任务没有任何特定于任务的模块,如对象检测、分割、映射或规划模块。这种通用方法具有设计简单、利用可用计算进行正扩展以及对多种任务具有通用性等优点。
我们的工作建立在最近成功的预训练视觉变换器(ViT)自我监督学习(SSL)的基础上。然而,虽然卷积网络的训练方法是成熟且稳健的,但 ViT 的方法是偶然且脆弱的,并且就用于视觉导航的 ViT 而言,还有待充分发现。具体来说,我们发现普通 ViT 在视觉导航方面并不优于 ResNet。我们建议使用在 ViT 补丁表示上运行的压缩层来保留空间信息以及策略训练改进。这些改进使我们首次在视觉导航任务中展示正缩放定律。因此,我们的模型将 IMAGENAV 上的最先进性能从 54.2% 成功率提高到 82.0%,并且与 OBJECTNAV 上同时最先进的性能相比,成功率分别为 64.0% 和 65.0%。
总的来说,这项工作并没有提出一种全新的方法,而是提出了训练通用架构的建议,该架构可实现当今最先进的性能,并可以作为未来方法的强大基准。
Introduction
在这项工作中,我们推进了一个替代研究计划——训练由与任务无关的神经组件构建的通才智能体,而无需任何特定于任务的模块。这种通用方法具有设计简单、可用计算积极扩展(结合“惨痛教训”[35])以及对多种任务的通用性等优点。
最近一系列关于图像和视频理解的工作发现,由自监督表示学习驱动的视觉变换器 [13] (ViT) 可以为识别 [3, 11, 18] 和生成 [4, 6] 提供通用视觉表示] 任务。然而,虽然卷积网络的训练方法是成熟且稳健的,但 ViT 的方法是偶然且脆弱的,并且就用于视觉导航的 ViT 而言,尚未得到充分发现 - 而这种发现是我们工作的重点。
我们的主要技术贡献和发现如下:
-
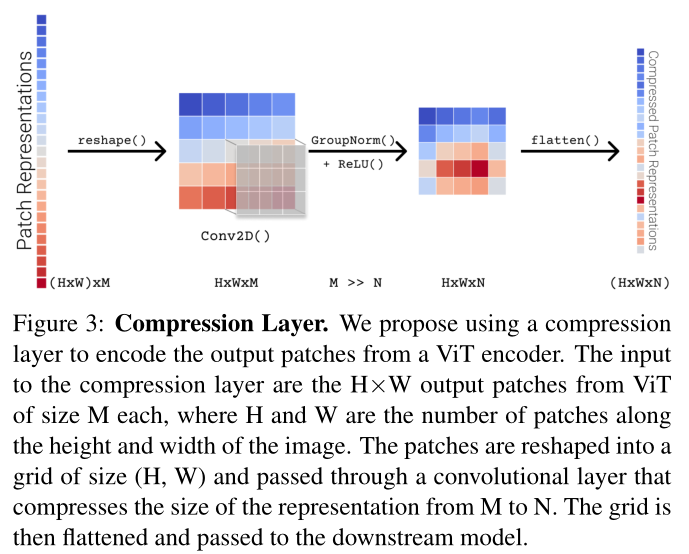
视觉导航中的 ViT 需要压缩层。我们发现,与 RESNET 相比,从头开始训练的基于 ViT 的智能体表现较差(例如,在 IMAGENAV 上仅实现 36.1% 的成功率 (SR),而在 RESNET 上则为 59.9%)。尽管模型容量要高得多(ViT-SMALL 的参数比半宽 ResNet50 多约 4 倍)。我们发现使用 ViT 解决导航问题的一个关键问题是 [CLS] 令牌嵌入和全局平均池都删除了对任务很重要的空间结构。我们建议使用压缩层(由 2D 卷积加扁平化组成)在 ViT patch 表示上运行来保留空间信息,并发现它导致 ViT 优于 RESNET(IMAGENAV 上的 SR 为 67.4% vs. 59.9%)。
-
视觉预训练首次解锁正标度法则。我们首次在 IMAGENAV 上展示了基于 ViT 的代理的正标度律。具体来说,我们发现视觉表示学习(使用掩码自动编码(MAE)[18])不仅可以提高性能,还可以使用 ViT 进行模型缩放。通过这种预训练,我们能够将模型大小从 ViT-SMALL 增加到 ViT-BASE,并观察到成功率从 80.5% 增加到 82.0% (+1.5%),SPL(按路径效率加权的成功)从 55.2% 增加到58.7%(+3.5%)。
-
单一架构在IMAGENAV和OBJECTNAV上实现SoTA。将所有这些(ViT、压缩层、预训练、策略训练改进和扩展)放在一起,我们提出了 OVRL-V2(离线视觉表示学习 v2),这是一个简单的 ViT+压缩层+LSTM 架构,作为现有技术的后继者。 - 最先进的方法,OVRL [43]。 OVRL-V2 将 IMAGENAV 上最先进的成功率从 54.2%(在[43]中)提高到 82.0%(+27.8% 绝对改进和 51.3% 相对改进),并且在 OB-JECTNAV 上实现了 64.0% 的成功率,与 stateof 相当-最先进的(65.0%,通过并行但正交的工作获得[31])。 OVRL-V2代理仅使用RGB和GPS+Compass传感器;没有以自我为中心的深度(如[32]所使用),没有语义分割(如[32]所使用),没有对象检测(如[46]所使用),没有语义或几何映射(如[8, 49, 29、37、9])。
Background:Tasks and Visual Pretraining
我们研究两种视觉导航任务:图像目标导航(IMAGENAV)[51]和对象目标导航(OBJECTNAV)[5]。为了解决这些任务,我们设计了一个利用视觉转换器(ViT)的实体代理[13]。
本节概述了每项任务,然后描述了我们用于预训练 ViT 的方法。
Visual Navigation

图 2 说明了 IMAGENAV [51] 和 OBJECTNAV [5] 任务。在这两种情况下,代理都从未知 3D 场景中的随机位置和方向开始。代理必须探索环境才能找到目标位置。在 IMAGENAV 中,目标是从目标位置拍摄的图像(例如沙发的照片)。在 OBJECTNAV 中,代理被赋予了它必须找到的对象的名称(例如“沙发”)。
在这些任务中,代理使用以自我为中心的 RGB 相机感知环境。代理使用离散的动作空间进行导航。在 IMAGENAV 中,标准动作集包括:向前移动 (0.25m)、向左转 (30°)、向右转 (30°) 和停止,以指示智能体认为它已达到目标。在 OBJECTNAV 中,代理还可以“向上查找”(30°) 和“向下查找”(30°)。
代理在以前未见过的环境中进行评估,这可以测量导航行为的泛化程度。使用两个标准指标来评估代理的导航性能:成功率(SR)和按(逆)路径长度加权的成功率(SPL)[2]。 SPL 奖励采取较短路径到达目标的智能体,从而衡量智能体探索新环境的效率。
Masked Autoencoders(MAEs)
视觉导航任务需要理解视觉提示才能在新环境中导航。因此,代理需要强大的视觉表示。我们使用屏蔽自动编码(MAE)[18]——一种高效的自监督视觉表示学习算法,专为预训练视觉变换器[13](ViTs)而设计——来提高基于 ViT 的代理的性能。 MAE 的效率源自非对称编码器-解码器设计。具体来说,输入图像首先被分成不重叠的补丁,其中很大一部分(75%)在预训练期间被随机屏蔽。编码器仅处理剩余的未屏蔽补丁,这减少了预训练期间的计算负担。小型解码器的任务是重建完整的输入图像。编码器和解码器都是 ViT,它们自然会处理可变数量的补丁。由于现实世界图像中各块之间的自然冗余,可以实现高掩蔽百分比,这使得仅从组成部分的一小部分子集即可预测完整图像。预训练后,解码器被丢弃,仅编码器用于下游任务。
Approach
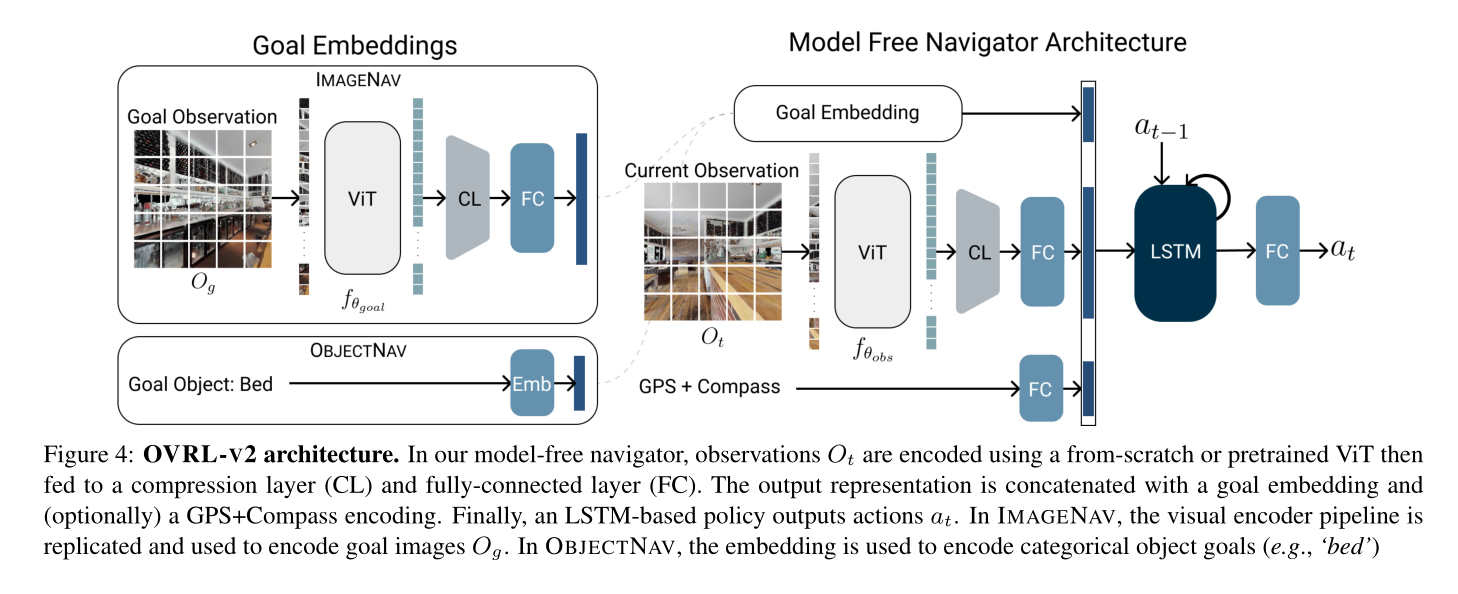
我们对视觉导航任务(IMAGENAV 和 OBJECTNAV)使用通用代理架构。如图 4 所示,两个代理主要由视觉编码器(随机初始化或使用 MAE 预训练的 ViT)、目标编码器和循环策略网络组成。本节描述了我们方法的几个关键组成部分。
Compression layers for ViTs
ViT 的压缩层。如图 4 所示,我们的视觉导航代理使用基于 ViT 的视觉编码器 fθobs 处理 RGB 观察值 Ot。具体来说,输入图像在数据增强后被转换为不重叠的 16×16 块,与 [CLS] 令牌连接,然后用 ViT 进行处理,输出每个块和 [CLS] 令牌的表示。在图像分类等任务中,通常使用(a)[CLS]令牌输出或(b)补丁表示的平均池化(即全局平均池化)来表示图像。
Visual Navigation with ViTs
使用 ViT 进行视觉导航 如图 4 所示,视觉编码器遥控钥匙的输出与目标表示和嵌入提供姿势信息的 GPS+罗盘传感器(仅用于 OBJECTNAV)相连接。连接的输出由基于 LSTM 的循环策略网络进行处理,该网络可预测操作。
每个任务的代理之间的区别在于用于编码目标的方法。在 IMAGENAV 中,图像目标 Og 使用视觉编码器 fθgoal 进行编码,其架构与 fθobs 相同。对于 OBJECTNAV,目标对象类别(例如“沙发”)通过学习的嵌入层进行编码。
我们使用 DD-PPO [39] 以及未来小节中描述的奖励函数通过强化学习(RL)来训练我们的 IMAGENAV 代理。对于 OBJECTNAV,我们使用人类演示和分布式行为克隆版本来训练我们的代理 [32]。
Visual Encoder Pretraining
视觉编码器预训练。我们提出的在无模型导航代理中使用基于 ViT 的视觉编码器的方法(图 4)可以从头开始进行端到端训练(例如,使用下一节中描述的 RL 奖励)。
此外,我们研究了使用第 2 节中描述的掩码自动编码(MAE)算法对基于 ViT 的视觉编码器进行预训练。 3.2.对于预训练,我们从 HM3D [30] 和 Gibson [40] 场景收集域内图像数据集。这遵循了先前工作中的观察结果(例如,[43]),该观察表明对域内数据(而不是像 ImageNet 这样的数据集)进行预训练可以提高下游性能。
ImageNav rewards
IMAGENAV 奖励。用于视觉导航的奖励通常由三个部分组成:(a)成功完成任务的稀疏奖励 c s c_s cs,(b)用于激励效率的每时间步惩罚 γ,以及(c)一个或多个奖励塑造项来简化优化问题。一个常见的奖励塑造术语是到目标的(测地线)距离的变化。形式上,令 dt 表示智能体在时间 t 时到目标的测地距离;现在,奖励塑造项可以写为: d t − 1 − d t d_{t−1} − d_t dt−1−dt。将所有三个奖励项放在一起,该奖励定义为:

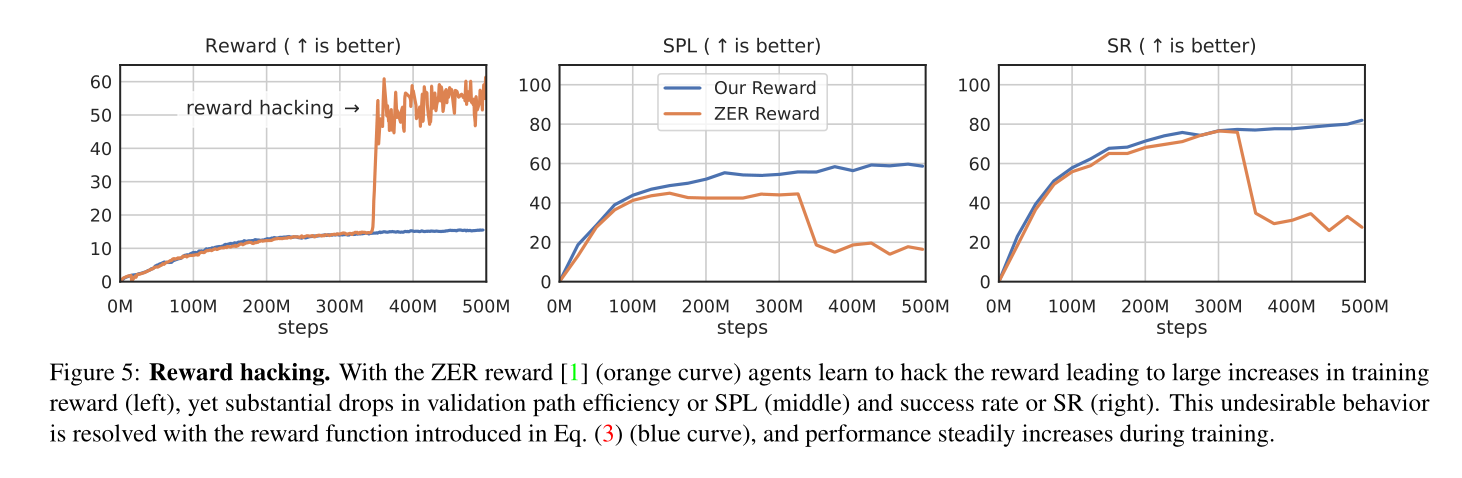
等式中奖励函数的一个限制。 (1) 是它对终止时智能体的“航向”无关紧要——智能体既不会因为注视目标物体而受到奖励(这是一种理想的行为,因为导航通常是操纵的前兆),也不会因注视目标物体而受到惩罚。结束这一集,将目光从物体上移开。为了解决这个问题,[1]提出了两个额外的角度奖励项来激励,1)转向目标(使用角度到目标( θ t θ_t θt)奖励塑造项)和2)在看着目标时停下来(使用最终奖励)。这两种奖励仅在智能体进入目标半径 rg 后才会授予。虽然 [1] 证明了他们的奖励可以提高 IMAGENAV 性能,但我们发现我们的 OVRL-V2 代理能够通过永不结束情节、进入目标半径、转向目标、向外移动来破解奖励函数目标半径,返回并重复。我们提供了有关此奖励的更多详细信息,并在附录 F 中可视化了代理的行为。我们假设之前的工作没有注意到这种可利用性,因为只有当实验规模适当时它才会变得明显。
我们在[1]中提出了对奖励函数的原则性修复。
我们的主要见解是,我们可以将角度到目标的奖励塑造项转化为潜在函数的差异,这被证明对于奖励塑造是最佳的[26]。具体来说,我们定义一个目标角度函数 θ ^ t \hat{θ}_t θ^t,它等于目标半径之外的 π,否则等于目标角度:

Experimental findings
在本节中,我们首先建立与现有 SoTA 方法竞争的 IMAGENAV 基线。然后,我们使用这个强大的基线来系统地解决以下研究问题:
-
ViT 是否可以在 IMAGENAV 中开箱即用?不。我们发现,尽管模型容量更高,但从头开始训练的基于 ViT 的智能体的表现比较小的 ResNet 智能体要差很多。
-
添加压缩层对性能有何影响?我们发现使用压缩层来维护图像表示中的空间结构可以显着提高 IMAGENAV 上的导航性能。
-
性能是否会随着 ViT 的增加而扩展?当从头开始训练时,我们观察到不同的结果。然而,自我监督的视觉预训练会带来一致的全面改进以及缩放强大的视觉导航代理能否“破解”等式 3 中的新奖励函数? 不可以。可以“破解”ZER 奖励 [1] 的智能体不再能够通过我们提出的修正来“破解”奖励函数。
-
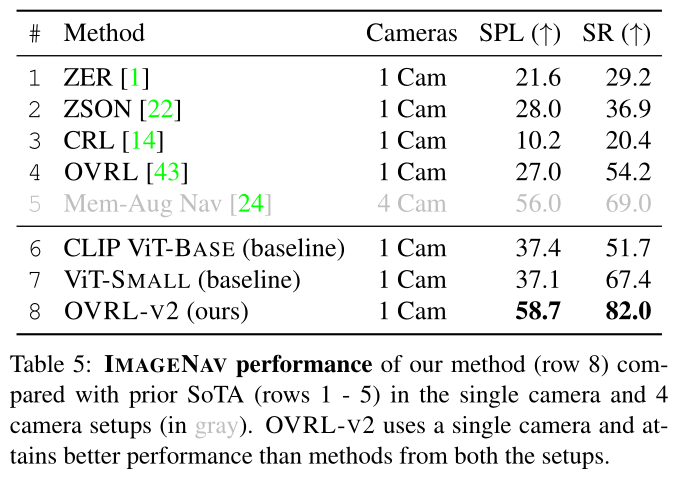
OVRL-V2 性能与 IMAGENAV SoTA 相比如何? OVRL-V2 比之前的工作有了显着改进,包括使用额外摄像机提供环境全景的方法。
-
架构改进是否会转移到 OBJECTNAV 上?是的。 OVRL-V2 在 SR 方面优于 OBJECTNAV SoTA,甚至无需使用 OBJECTNAV 常用的深度传感器或分割模块
Comparisions with the ImageNav SoTA
Conclusion
在本文中,我们证明了由任务无关组件(ViT、卷积和 LSTM)组成的无模型导航代理 (OVRL-V2) 可以在 IMAGENAV 和 OBJECTNAV 上实现最先进的结果。为了实现这一目标,我们证明需要一个在 ViT 补丁表示上运行的压缩层,它可以保留空间信息。最后,我们发现使用 MAE 进行视觉预训练可以通过更大的 ViT 架构实现积极的扩展趋势。

![java八股文面试[Spring]——如何实现一个IOC容器](https://img-blog.csdnimg.cn/img_convert/f021207ca7c074ef3cc030ca5c3691f9.png)