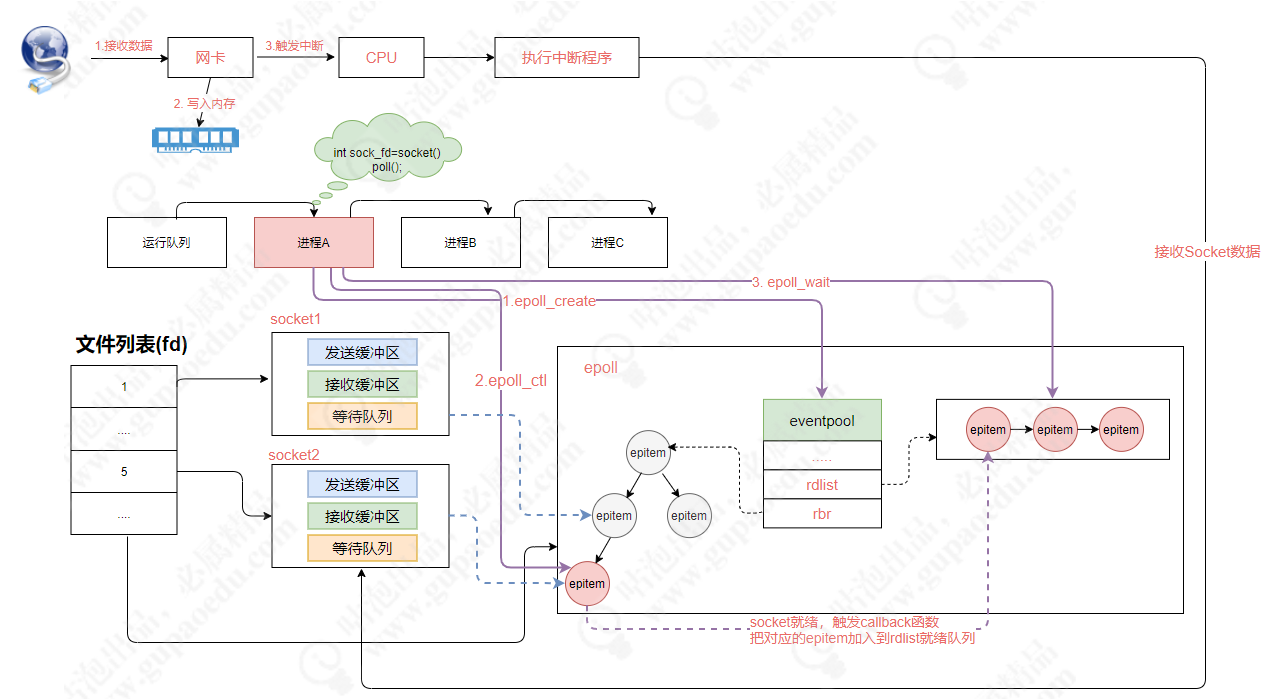
最近不少人私信我,说有些SCI文章报了两个P值一个是P for overall,一个是P for nonlinear,就像下图这样,问我P for overall怎么计算。
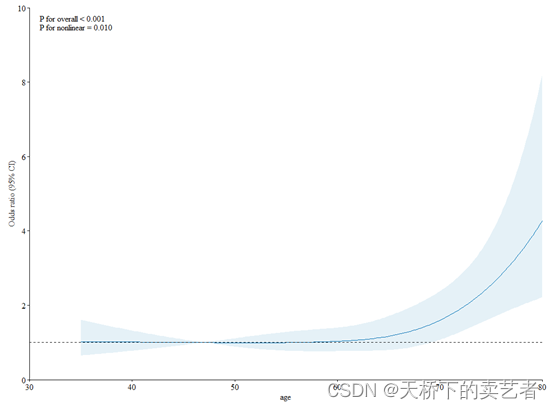
P for overall我也不清楚是什么,有些博主说这个是总效应的P值,但是我没有找到相关出处。但是怎么做出来这个P for overall我是清楚的,有个R包叫plotRCS,这个包是可以生成出P for overall这个结果的,我就以这个包的方法来演示一下怎么做P for overall。
library(plotRCS)
bc<-cancer
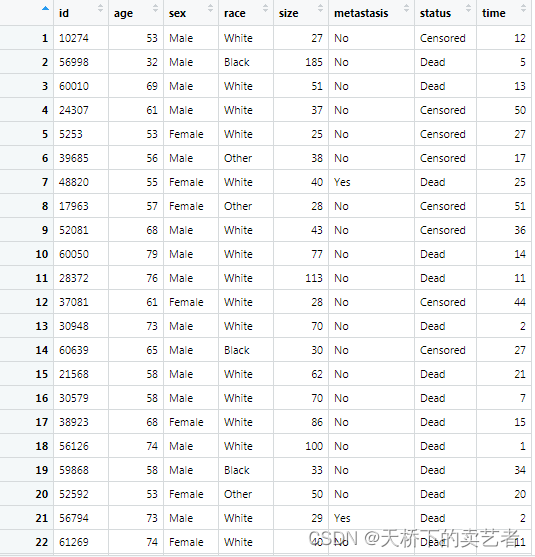
这个是plotRCS包自带的癌症的生存数据,age是年龄,sex是性别,race是种族,size是肿瘤大小,status是生存结局。
plotRCS做P for overall是分成两种情况的,就是一个结局变量是连续变量和结局变量是二分类变量的。
咱们先来演示一下二分类变量的。
做限制立方样条(RCS)的步骤都是原来一样的。
逻辑回归:
library(rms)
转成分类变量
bc$sex<-as.factor(bc$sex)
bc$race<-as.factor(bc$race)
为后续程序设定数据环境
dd <- datadist(bc) #为后续程序设定数据环境
options(datadist='dd') #为后续程序设定数据环境
建立模型,我们这里要研究的变量是age年龄,
fit<-lrm(status ~ rcs(age, 4)+sex+race,data=bc)
计算P for overal和P for nonlinear
out<-anova(fit)
out<-as.data.frame(out)
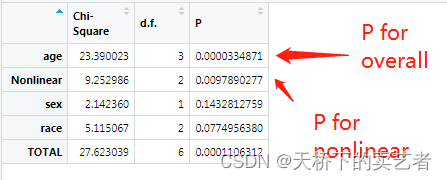
这样结果就出来来了,也是和作者R包算得一样

接下来来个线性回归,改一下结局变量就行
fit1<-ols(size ~ rcs(age, 4)+sex+race,data=bc)
计算P for overal和P for nonlinear
out1<-anova(fit1)
out1<-as.data.frame(out1)
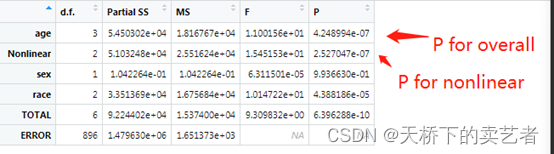
其实都差不多哈,就是写包的时候代码稍微有点不同,如果大家确实需要,ggrcs包改版后也可以加进去,这个很简单的。
文章到此结束啦,内容有点短,主要是最近有点头绪了,正在编写Nhanes数据,也就是复查加权数据的亚组交互效应函数(P for interaction),用于一键生成交互效应表,占用了部分时间,这个工程量稍微有点大,主要是分类变量的难写。