原创 | 文 BFT机器人

大型的、有标记的数据集的可用性是为了利用做有监督的深度学习方法的一个关键要求。但是在RGB-D场景理解的背景下,可用的数据非常少,通常是当前的数据集覆盖了一小范围的场景视图,并且具有有限的语义注释。
为了解决这个问题,本文介绍了一个ScanNet的大规模室内场景3D重建和语义分割数据集。该数据集包含1513个室内场景的2.5M视角,具有3D相机姿态、表面重建和语义分割的注释。并且为了收集这些数据,设计了一个易于使用和可伸缩的RGB-D捕获系统,其中包括自动表面重建和众包语义注释。实验结果表明使用这些数据有助于在几个三维场景理解任务上实现最先进的性能,表现在三维对象分类、语义体素标记和CAD模型检索几个方面。
背景
BACKDROP
随着RGB-D传感器的引入以来,3D几何捕获领域获得了广泛的关注,并开辟了广泛的新应用。在三维重建算法上已经有了大量的努力,但利用RGB-D数据进行的一般三维场景理解最近才开始流行起来。随着现代机器学习方法的快速发展,如神经网络模型,也大大促进了对语义理解的研究。
本文建立了一个来帮助初学者获得语义标记的场景3D模型。人们使用安装有深度摄像头的iPad上的一个应用程序来获取RGB-D视频,然后后台离线处理数据,并返回一个完整的语义标记的场景3D重建。确实开发这样一个框架的挑战是众多的,包括如何稳健地执行三维表面重建,以及如何众包语义标记。对这些问题的研究,并记录了在扩大RGB-D扫描收集(20人)和注释(500名人群工作者)方面的经验。
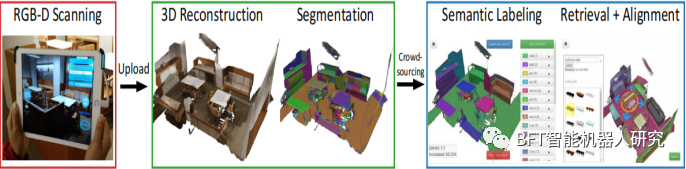
研究
STUDY
RGB-D重建和语义注释框架的概述。左图:一个新手用户使用一个手持RGB-D设备与我们的扫描界面来扫描一个环境。中间:RGB-D序列被上传到一个处理服务器,该服务器生成三维表面网格重建及其表面分割。右图为发布语义注释任务进行众包,获得实例级对象类别注释和三维CAD模型对齐重建。使用ScanNet提供的数据对三维深度网络进行了训练,并测试了它们在几个场景理解任务上的性能,包括三维对象分类、语义体素标记和CAD模型检索。对于语义体素标记任务,本文引入了一种新的体积CNN架构。

在校准时,本文使用RGB-D传感器需要解除深度数据的扭曲和深度和颜色数据的对齐。先前的研究工作主要集中在具有更精确设备的控制实验室条件上,以告知商品传感器的校准。然而这对于新手用户来说是不实用的。因此,用户只需要打印出一个棋盘图案,将它放在一个大的、平坦的表面上,并捕获一个从近距离观察表面的RGB-D序列。这个序列,以及一组查看棋盘格的红外线和彩色帧对,由用户上传作为校准的输入,我们的系统运行一个校准程序,以获得深度和颜色传感器的内在参数,以及深度到颜色的外部转换。
我们发现,这种校准程序易于用户,结果改善数据,从而提高重建质量。本文研究选择了捆绑融合(BundleFusion)系统,因为它是设计和评估类似的传感器设置,并提供实时速度,同时相当稳健的给定手持RGBD视频数据。在验证过程时候,当扫描上传到处理服务器并在无监督下运行时,将自动触发此重建过程。为了建立一个干净的快照来构建本文报道的ScanNet数据集,自动丢弃了较短、残差重建误差高或对齐帧比例低的扫描序列。然后我们手动检查和丢弃有明显失调的重建。
结论
CONCLUSION
文中还讨论了如何在可扩展的流水线中进行3D表面重建和如何进行众包语义标注的问题,并介绍了使用ScanNet数据进行3D场景理解任务的最新技术和结果。文章中在可扩展的流水线中使用一种新的体积卷积神经网络架构,用于解决语义体素标注任务。结果表明,使用ScanNet数据可以获得比现有数据集更好的性能,这证明了ScanNet数据集的重要性和实用性,该数据集还包括纹理网格、密集的物体级别语义分割和对齐的CAD模型。3D模型是使用RGB-D捕捉系统重建的,其中包括自动表面重建和众包语义注释。
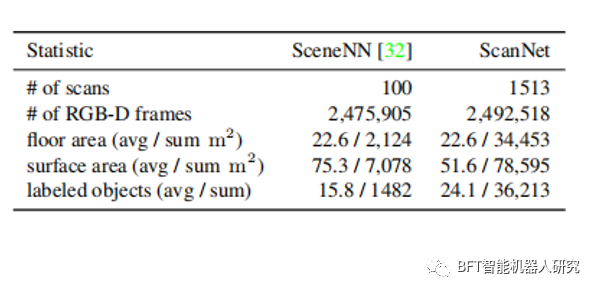
语义分割比任何先前的RGB-D数据集都要大一个数量级。模型使用估计的校准参数、相机姿态、3D表面重建、纹理网格、密集的物体级别语义分割和对齐的CAD模型进行注释。这使得ScanNet成为场景理解研究的宝贵资源。。此外还提供了新的RGB-D基准和改进的结果,这些结果可以用于3D对象分类、语义体素标注和CAD模型检索等场景理解任务。
作者 | ZZY
排版 | 春花
审核 | 猫
若您对该文章内容有任何疑问,请于我们联系,将及时回应。如果想要了解更多的前沿资讯,记得点赞关注哦~