前言:Hello大家好,我是Dream。 在本次实战中,我们将一起完成知识图谱Neo4j安装到实践全过程,探索其中的关系和属性。知识图谱是一种以三元组形式存储的数据结构,由实体、关系和属性组成,能够帮助我们更好地理解和分析复杂的知识关系,一起来看看吧~
一、语义网络写入图形数据库
实验目的
(1)了解向数据库中写入语义网络的方法。
(2)简单使用Neo4j呈现语义网络。
实验要求
本次实验后,能理解语义网络的 节点(Node)和关系(Relationship) 在数据库中是如何呈现的。
实验原理
将一个事实用语义网络表示,首先要找出它的节点,再描述它与其他节点的关系,最后用Python 写入数据库中。
实验准备
1.安装JDK
下载neo4j之前,首先要安装JDK。
1.1 下载
官网下载链接:https://www.oracle.com/java/technologies/javase-downloads.html
JDK版本的选择一定要恰当,建议jdk1.8 比较稳定 版本太高或者太低都可能导致后续的neo4j无法使用。
以下是安装路径:
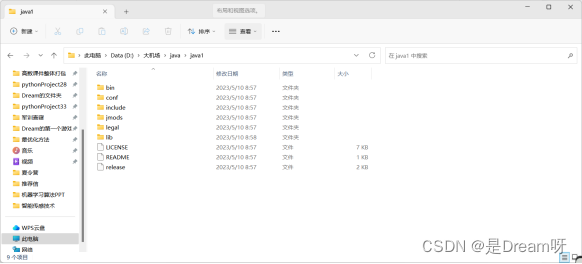
1.2 配置环境变量
安装好JDK之后就要开始配置环境变量了。 配置环境变量的步骤如下:
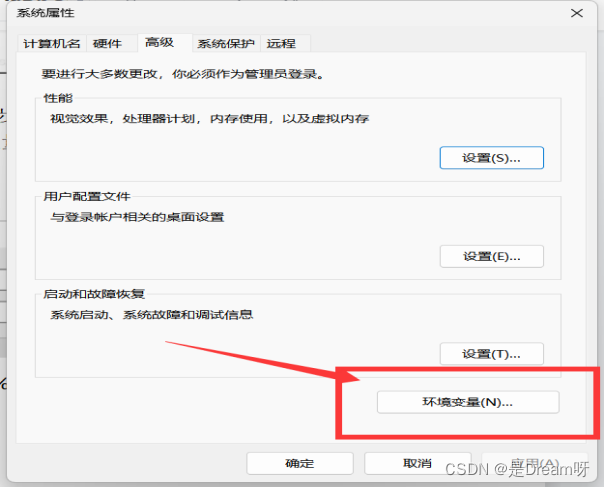
在开始处直接搜索环境变量,打开后会出现如下界面,然后点击右下角处环境变量:
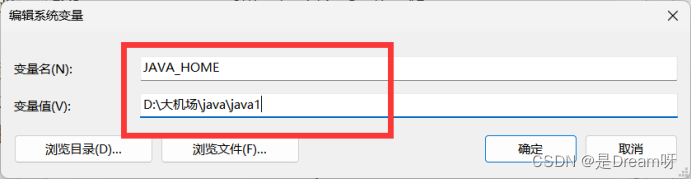
在下方的系统变量区域,新建环境变量,命名为JAVA_HOME,变量值设置为刚才JAVA的安装路径,我这里是D:\大机场\java\java1。
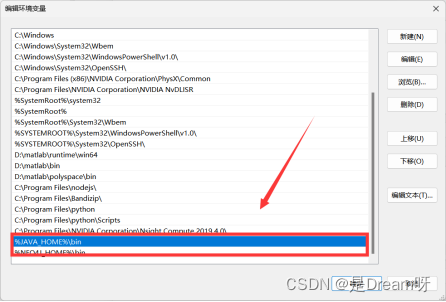
编辑系统变量区的Path,点击新建,然后输入 %JAVA_HOME%\bin
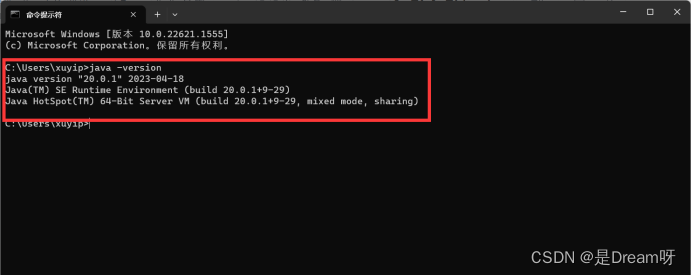
打开命令提示符CMD(WIN+R,输入cmd),输入 java -version,若提示Java的版本信息,则证明环境变量配置成功:
2. 安装neo4j
安装好JDK之后,就可以安装neo4j了。
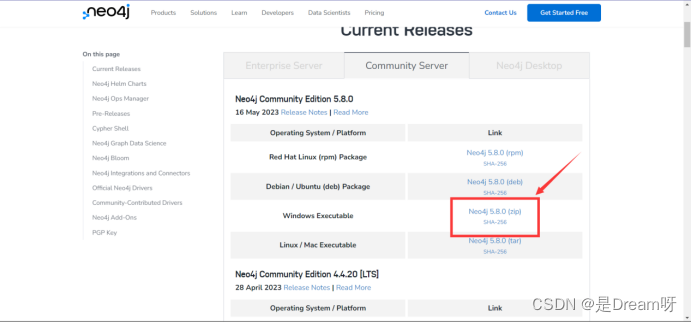
2.1 下载
官方下载链接:https://neo4j.com/download-center/#community
在这里,我下载的是neo4j社区版5.8.0。
下载好之后,直接解压到合适的路径就可以了,无需安装:
2.2 配置环境变量
接下来要配置环境变量了,与刚才JAVA环境变量的配置方法极为相似,因此在这里只进行简单描述。
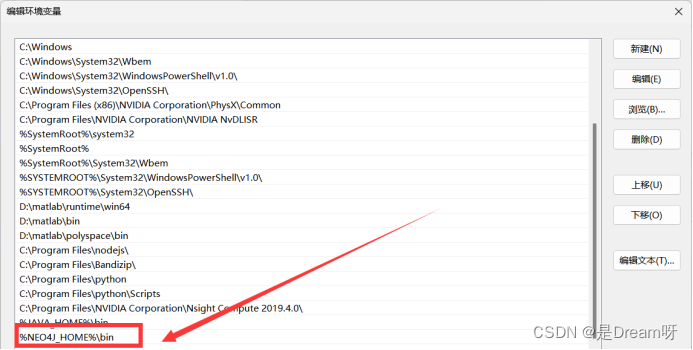
在系统变量区域,新建环境变量,命名为NEO4J_HOME,变量值设置为刚才neo4j的安装路径,我这里是D:\大机场\neo4j\neo4j1。
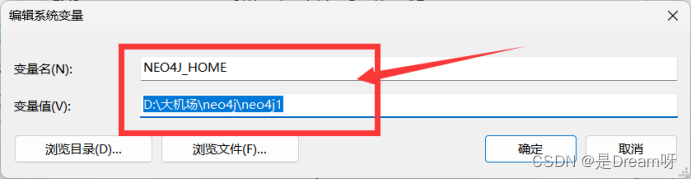
编辑系统变量区的Path,点击新建,然后输入 %NEO4J_HOME%\bin,最后,点击确定进行保存就可以了。
3. 启动neo4j
以管理员身份运行cmd。
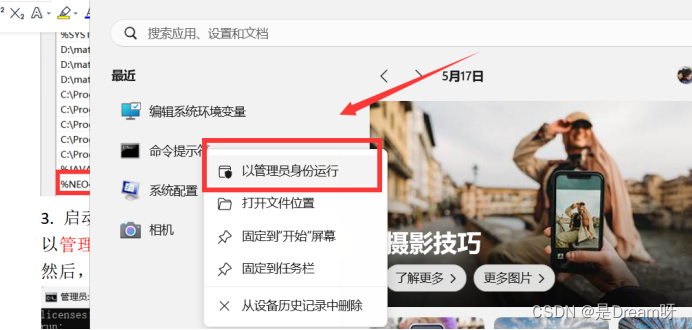
然后,在命令行处输入neo4j.bat console
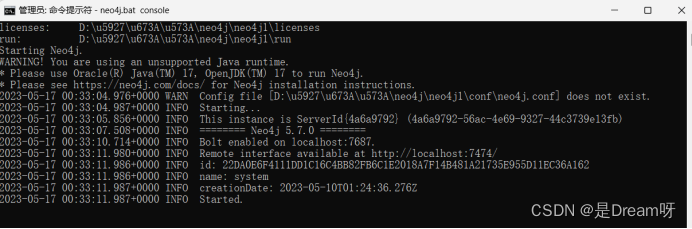
如出现此界面,则证明neo4j启动成功。
在浏览器中输入界面中给出的网址http://localhost:7474/,则会显示如下界面。
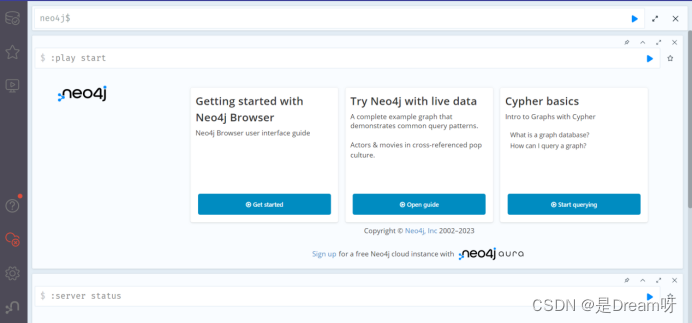
默认的用户名和密码均为neo4j。
至此,neo4j安装完毕~
实验步骤
1.从neomodel包导入类。
from neomodel import StructuredNode, StringProperty, RelationshipTo, RelationshipFrom, config
2.连接Neo4j图形数据库。
config.DATABASE URL= 'bolt://neo4i:neo4ialocalhost:7687'
即将要构造的事实为“树和草都是植物。树和草都有叶和根。水早是早,且生长在水中。果树是树,日会结里、烈树是里树的一种,它会结梨”。
3.编写节点类。
植物、树、草、叶、根、水草、水、果树、结果、梨树、结架赵些节点英继承自StructuredNode类,包括节点属性和连接关系。
class Plant(StructuredNode):name = StringProperty(unique_index=True)has1 = RelationshipFrom("Tree", "AKO")has2 = RelationshipFrom('Grass', 'AKO')have1 =RelationshipTo('Leaf', 'Have')have2 = RelationshipTo('Root', 'Have')
class Tree(StructuredNode):name = StringProperty(unique_index=True)ako = RelationshipTo('Plant', 'AKO')have = RelationshipFrom('Fruiter', 'AKO')
class Grass(StructuredNode):name = StringProperty(unique_index=True)ako = RelationshipTo('Plant' , 'AKO')has = RelationshipFrom('Waterweeds', 'AKO')
class Leaf(StructuredNode):name = StringProperty(unique_index=True)have = RelationshipFrom('Plant', 'Have')
class Root(StructuredNode):name = StringProperty(unique_index=True)have = RelationshipFrom('Plant', 'Have')
class Waterweeds(StructuredNode):name = StringProperty(unique_index=True)ako = RelationshipTo('Grass' , 'AKO')live = RelationshipTo('Water', 'Live')
class Water(StructuredNode):name = StringProperty(unique_index=True)have = RelationshipFrom('Waterweeds', 'Live')class Fruiter(StructuredNode):name = StringProperty(unique_index=True)ako = RelationshipTo('Tree', 'AKO')can = RelationshipTo('Bear', 'Can')have = RelationshipFrom('Pear','AKO')class Bear(StructuredNode):name = StringProperty(unique_index=True)have = RelationshipFrom('Fruiter' , 'Can')class Pear(StructuredNode):name = StringProperty(unique_index = True)ako = RelationshipTo('Fruiter', 'AKO')can = RelationshipTo('BearPear', 'Can')class BearPear(StructuredNode):name = StringProperty(unique_index=True)have = RelationshipFrom('Pear', 'Can')plant =Plant(name="植物").save()
tree = Tree(name="树").save()
grass = Grass(name="草" ).save()
leaf = Leaf(name= "叶" ).save()
root = Ro
4.根据类生成实例。
leaf = Leaf(name= "叶" ).save()
root = Root(name="根").save()
waterweeds = Waterweeds(name="水草").save()
water = Water(name="水" ).save()
fruiter = Fruiter(name="果树").save()
bear = Bear(name="结果").save()
pear = Pear(name="梨树").save()
bearpear = BearPear(name="结梨").save()
5.创建实例之间的连接关系。
pear.ako.connect(fruiter)
pear.can.connect(bearpear)
fruiter.ako.connect(tree)
fruiter.can.connect(bear)
waterweeds.ako.connect(grass)
waterweeds.live.connect(water)
plant.have1.connect(leaf)
plant.have2.connect(root)
tree.ako.connect(plant)
grass.ako.connect(plant)
实验结果
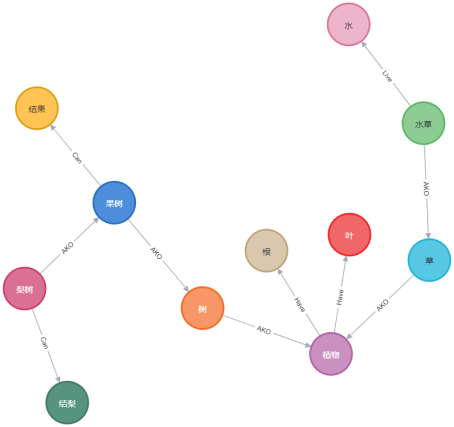
二、水浒传知识图谱构建
启动neo4j
以管理员身份运行cmd,
在命令行处输入neo4j.bat console
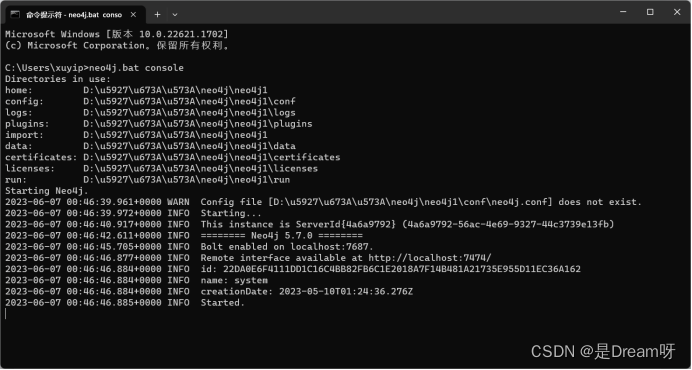
如出现此界面,则neo4j启动成功
在浏览器中输入界面中给出的网址http://localhost:7474/,即可打开neo4j的可视化界面。
打开jupyter notebook
1.进入 jupyter notebook:
在命令行中输入"jupyter notebook"命令并回车后,会自动跳转到jupyter notebook的工作区页面。这样,我们就可以开始进行知识图谱的构建了。
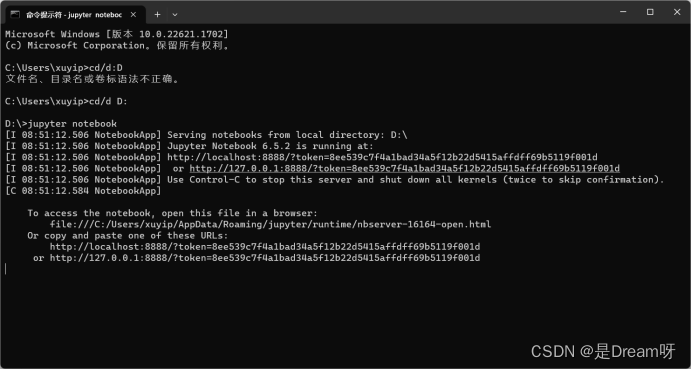
2.数据集下载
数据集:triples.csv
链接:https://pan.baidu.com/s/19vrJ1vkEf2lgchBkF8OALQ?pwd=gn8o
提取码:gn8o
数据说明:构建知识图谱需要把数据处理成三元组<实体1,关系,实体2>或<实体,属性,属性值>的形式,每个三元组(triples)可看成是由subject(主语)、predicate(谓语)和object(宾语)组成。知识图谱中的三元组主要包含两种,一种是关系三元组relation triples,另一种是属性三元组attribute triples,relation triples中的subject和object均是实体,而predicate通常被称为关系。attribute triples中的subject是实体,而object则是取值(value),该值通常是一个数值或者文本,其predicate通常称为属性。
数据又分为非结构化数据(例如:文本、文档、图片等),半结构化文本(如:日志文件、XML文档、JSON文档等)和结构化数据,本实验使用的数据集是结构化的三元组数据,无需做额外处理,可以直接使用。
3.安装第三方库
为了能够顺利进行知识图谱构建,我们需要安装一些必要的第三方库:
- 安装py2neo库:用于与neo4j图数据库进行交互。
- 安装pyahocorasick,numpy和pandas库:用于处理数据集和进行相关操作。
!pip install py2neo pyahocorasick numpy pandas
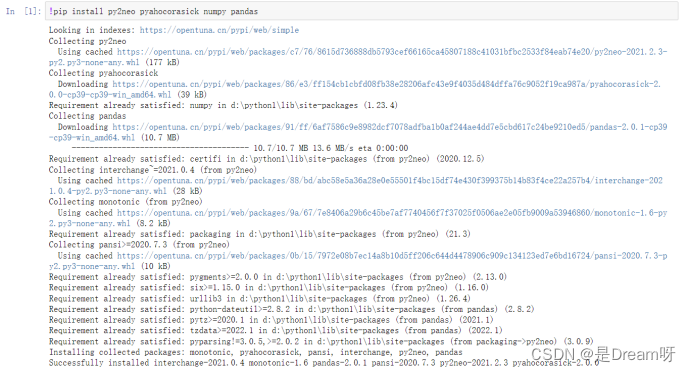
!pip install pytest-cov==2. 0
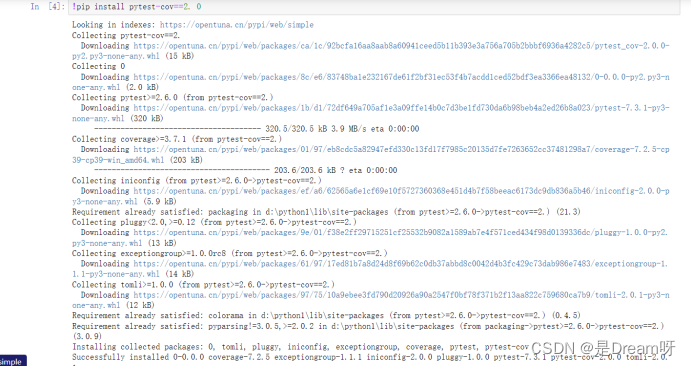
!pip install pytest-filter-subpackage==0. 1
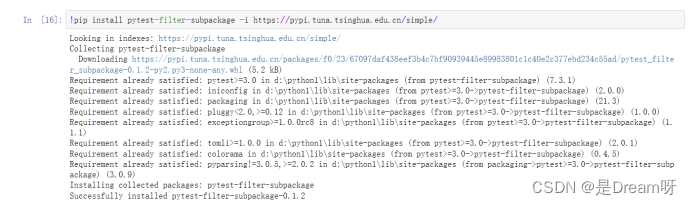
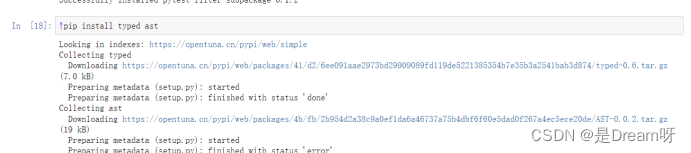
!pip install typed ast== 1. 4. 0
4.导包
在jupyter notebook中,我们需要导入一些必要的库来进行知识图谱的构建。在代码开始的地方加入以下代码即可:
import py2neo
from py2neo import Graph,Node,Relationship,NodeMatcher
5.连接图数据库
为了能够与neo4j图数据库进行交互,我们需要先连接到该数据库。接下来,我们可以使用以下代码来连接图数据库:
auth的值分别为neo4j登录时的账号和密码,一定要使用安装时更改之后的密码,否则无法连接到图数据库。
g=Graph("neo4j://localhost:7687", auth=("neo4j", "mima"))
6.图谱构建
import csv
with open(r"D:\PycharmProjects\知识表示\triples.csv",'r', encoding='utf-8') as f:reader=csv.reader(f)for item in reader:if reader.line_num==1:continueprint('当前行数:',reader.line_num,"当前内容:",item)start_node=Node("Person" ,name=item[0])end_node=Node("Person", name=item[1])relation=Relationship(start_node,item[3],end_node)g.merge(start_node,"Person", "name")g. merge(end_node,"Person","name")g.merge(relation,"Person","name")
这段代码将逐行读取数据集文件,并将每行数据转换为三元组的形式进行图谱构建。
运行代码后,可以在控制台上看到当前行数和对应的内容。
结果显示:
结果显示:
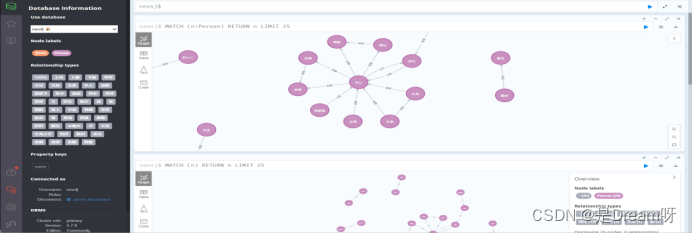
运行成功后,我们可以在neo4j的可视化界面中查看已经构建好的知识图谱。

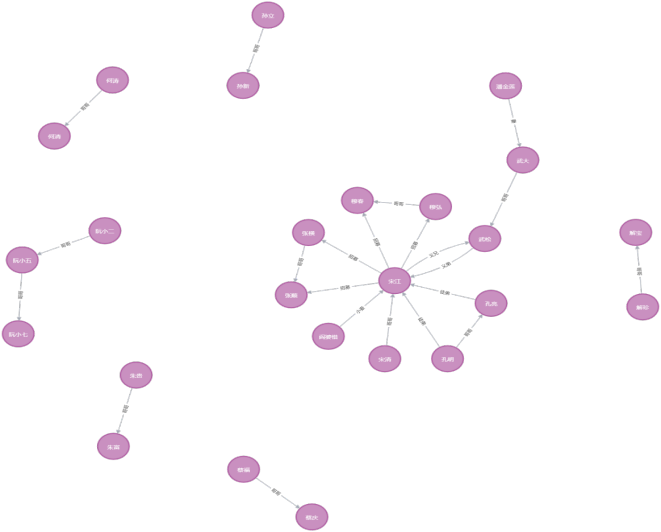
图谱可视化结果
我们可以在neo4j的可视化界面中,通过查询相关节点和关系,来查看已经构建好的水浒传知识图谱的可视化结果。
在界面中输入相应的Cypher查询语句即可。