专栏系列文章地址:https://blog.csdn.net/qq_26437925/article/details/145290162
本文目标:
- 理解锁,能自定义实现锁
- 通过自定义锁的实现复习Thread和Object的相关方法
- 开始尝试理解Aqs, 这样后续基于Aqs的的各种实现将能更好的理解
目录
- 锁的自定义实现
- lock 自旋加锁
- 改进1: 自旋加锁失败的尝试让出cpu(yield操作)
- 改进2: yield 换成sleep
- 改进3: 仿照ObjectMonitor,加上一个等待队列
- AbstractQueuedSynchronizer
- Aqs核心思想归纳
- AbstractQueuedSynchronizer 抽象类的说明和实现
- 同步器说明
- Aqs独占模式
- Aqs共享模式
- 基于Aqs再次实现自定义锁
锁的自定义实现
线程基础和cas操作知晓后,可以开始自己实现锁了。
例子代码实现多线程的count++
import sun.misc.Unsafe;import java.lang.reflect.Field;
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.TimeUnit;class MyLock {volatile int status = 0;Unsafe unsafe;// 引用Unsafe需使用如下反射方式,否则会抛出异常java.lang.SecurityException: Unsafepublic Unsafe reflectGetUnsafe() throws NoSuchFieldException, IllegalAccessException {Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");theUnsafe.setAccessible(true);//禁止访问权限检查(访问私有属性时需要加上)return (Unsafe) theUnsafe.get(null);}boolean compareAndSet(int expect, int newValue) {try {Field field = this.getClass().getDeclaredField("status");field.setAccessible(true);long offset = unsafe.objectFieldOffset(field);//cas操作return unsafe.compareAndSwapInt(status, offset, expect, newValue);} catch (Exception e) {return false;}}public MyLock() {try {unsafe = reflectGetUnsafe();} catch (Exception e) {e.printStackTrace();}}public void lock() {while (!compareAndSet(0, 1)) {}}public void unlock() {compareAndSet(1, 0);}}public class Main {static int count = 0;static int N = 100;public static void main(String[] args) throws Exception {MyLock lock = new MyLock();List<Thread> list = new ArrayList<>();for (int i = 0; i < N; i++) {Thread thread = new Thread(() -> {try {lock.lock();TimeUnit.MILLISECONDS.sleep(1);count++;} catch (Exception e) {} finally {lock.unlock();}}, "myThread-" + i);list.add(thread);}for (Thread thread : list) {thread.start();}for (Thread thread : list) {thread.join();}System.out.println("count:" + count);}
}
lock 自旋加锁
volatile int status = 0;public void lock() {while (!compareAndSet(0, 1)) {}
}
问题:没有竞争得到锁的线程会一直占用CPU资源进行CAS操作,假如一个线程耗费n秒处理业务逻辑,那另外一个线程就会白白花费n秒的CPU资源在那里自旋。
改进1: 自旋加锁失败的尝试让出cpu(yield操作)
所以可以yield尝试让出CPU(可复习:https://blog.csdn.net/qq_26437925/article/details/145400968)
public void lock() {while (!compareAndSet(0, 1)) {Thread.yield();}
}
问题:yield是将线程设置为就绪状态,需要获取到CPU时间片才能执行变成真正的RUNNABLE状态。但是当线程很多的时候,重新竞争的时候很可能某些线程老是获取不到CPU执行,这样就会出现线程饥饿现象
改进2: yield 换成sleep
public void lock() {while (!compareAndSet(0, 1)) {try {TimeUnit.MILLISECONDS.sleep(100);} catch (Exception e) {}}
}
sleep 也是让出CPU,但是和yield不同,其是把线程设置为TIMED_WAITING状态(A thread that is waiting for another thread to perform an action for up to a specified waiting time is in this state)。不过sleep使用的问题是,不确定sleep多久
改进3: 仿照ObjectMonitor,加上一个等待队列
获取不到的锁的线程,加入到一个等待队列中,释放其CPU; 当有线程要释放锁了,则从头部队列移除线程,开始继续获取锁
import sun.misc.Unsafe;import java.lang.reflect.Field;
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.TimeUnit;class MyLock {volatile int status = 0;Unsafe unsafe;Queue<Thread> waitQueue;// 引用Unsafe需使用如下反射方式,否则会抛出异常java.lang.SecurityException: Unsafepublic Unsafe reflectGetUnsafe() throws NoSuchFieldException, IllegalAccessException {Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");theUnsafe.setAccessible(true);//禁止访问权限检查(访问私有属性时需要加上)return (Unsafe) theUnsafe.get(null);}boolean compareAndSet(int expect, int newValue) {try {Field field = this.getClass().getDeclaredField("status");field.setAccessible(true);long offset = unsafe.objectFieldOffset(field);//cas操作return unsafe.compareAndSwapInt(status, offset, expect, newValue);} catch (Exception e) {return false;}}public MyLock() {try {unsafe = reflectGetUnsafe();waitQueue = new ArrayDeque<>();} catch (Exception e) {e.printStackTrace();}}public void lock() {while (!compareAndSet(0, 1)) {park(Thread.currentThread());}}public void unlock() {compareAndSet(1, 0);// 有线程要释放锁了,公平方式,头部线程可以不等待了, 开始去获取锁// 1.得到要唤醒的线程头部线程Thread t = waitQueue.poll();// 2. 唤醒等待线程if (t != null) {unsafe.unpark(t);}}private void park(Thread thread) {if (waitQueue.contains(thread)) {return;}// 将线程加入到等待队列中waitQueue.add(thread);// 将当期线程释放CPU 阻塞thread.yield();}
}public class Main {static int count = 0;static int N = 100;public static void main(String[] args) throws Exception {MyLock lock = new MyLock();List<Thread> list = new ArrayList<>();for (int i = 0; i < N; i++) {Thread thread = new Thread(() -> {try {lock.lock();TimeUnit.MILLISECONDS.sleep(1);count++;} catch (Exception e) {} finally {lock.unlock();}}, "myThread-" + i);list.add(thread);}for (Thread thread : list) {thread.start();}for (Thread thread : list) {thread.join();}System.out.println("count:" + count);}
}
AbstractQueuedSynchronizer
如上上述自定义锁实现能够理解,那么就是理解aqs了
- 锁的实现框架
参考:美团技术文章:从ReentrantLock的实现看AQS的原理及应用
参考:《The java.util.concurrent Synchronizer Framework》 JUC同步器框架(AQS框架)原文翻译
论文地址
docs api
Provides a framework for implementing blocking locks and related synchronizers (semaphores, events, etc) that rely on first-in-first-out (FIFO) wait queues. This class is designed to be a useful basis for most kinds of synchronizers that rely on a single atomic int value to represent state. Subclasses must define the protected methods that change this state, and which define what that state means in terms of this object being acquired or released. Given these, the other methods in this class carry out all queuing and blocking mechanics. Subclasses can maintain other state fields, but only the atomically updated int value manipulated using methods getState(), setState(int) and compareAndSetState(int, int) is tracked with respect to synchronization.
Aqs核心思想归纳
AQS核心思想是:如果被请求的共享资源空闲,那么就将当前请求资源的线程设置为有效的工作线程,将共享资源设置为锁定状态;如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程加入到队列中
CLH:Craig、Landin and Hagersten队列,链表结构,AQS中的队列是CLH变体的虚拟双向队列(FIFO),AQS是通过将每条请求共享资源的线程封装成一个节点来实现锁的分配。


AQS使用一个volatile的int类型的成员变量state来表示同步状态,通过内置的FIFO队列来完成资源获取的排队工作,通过CAS完成对state值的修改。
AbstractQueuedSynchronizer 抽象类的说明和实现
- AbstractQueuedSynchronizer 提供了一个框架,用来实现blocking locks 和 一些同步器,且是基于一个FIFO队列的
- AbstractQueuedSynchronizer 被设计为使用一个
single atomic {@code int} value来表示状态 - AbstractQueuedSynchronizer的子类必须去定义状态,并提供protected方法去操作状态:getState、setState以及compareAndSet
- 基于AQS的具体实现类必须根据暴露出的状态相关的方法定义tryAcquire和tryRelease方法,以控制acquire和release操作。当同步状态满足时,tryAcquire方法必须返回true,而当新的同步状态允许后续acquire时,tryRelease方法也必须返回true。这些方法都接受一个int类型的参数用于传递想要的状态。
同步器说明
两个操作
acquire操作:阻塞调用的线程,直到或除非同步状态允许其继续执行。release操作:则是通过某种方式改变同步状态,使得一或多个被acquire阻塞的线程继续执行。
同步器需要支持如下:
- 阻塞和非阻塞(例如tryLock)的同步
- 可选的超时设置,让调用者可以放弃等待
- 通过中断实现的任务取消,通常是分为两个版本,一个acquire可取消,而另一个不可以
同步器的实现根据其状态是否独占而有所不同。独占状态的同步器,在同一时间只有一个线程可以通过阻塞点,而共享状态的同步器可以同时有多个线程在执行。一般锁的实现类往往只维护独占状态,但是,例如计数信号量在数量许可的情况下,允许多个线程同时执行。为了使框架能得到广泛应用,这两种模式都要支持。
j.u.c包里还定义了Condition接口,用于支持监控形式的await/signal操作,这些操作与独占模式的Lock类有关,且Condition的实现天生就和与其关联的Lock类紧密相关
Aqs独占模式

Aqs共享模式
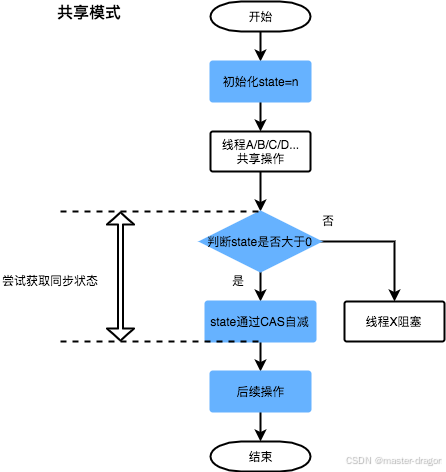
基于Aqs再次实现自定义锁
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;class MyLock {private static class Sync extends AbstractQueuedSynchronizer {// 加锁的cas操作@Overrideprotected boolean tryAcquire (int arg) {return compareAndSetState(0, 1);}@Overrideprotected boolean tryRelease (int arg) {setState(0);return true;}@Overrideprotected boolean isHeldExclusively () {return getState() == 1;}}private Sync sync = new Sync();public void lock () {sync.acquire(1);}public void unlock () {sync.release(1);}
}public class Main {static int count = 0;static int N = 100;public static void main(String[] args) throws Exception {MyLock lock = new MyLock();List<Thread> list = new ArrayList<>();for (int i = 0; i < N; i++) {Thread thread = new Thread(() -> {try {lock.lock();TimeUnit.MILLISECONDS.sleep(1);count++;} catch (Exception e) {} finally {lock.unlock();}}, "myThread-" + i);list.add(thread);}for (Thread thread : list) {thread.start();}for (Thread thread : list) {thread.join();}System.out.println("count:" + count);}
}

















![[Collection与数据结构] B树与B+树](https://i-blog.csdnimg.cn/direct/b96afb008a104ddca272db3e6e105ace.png)