深度学习经典的检测方法
two-stage(两阶段):Faster-rcnn Mask-Rcnn系列
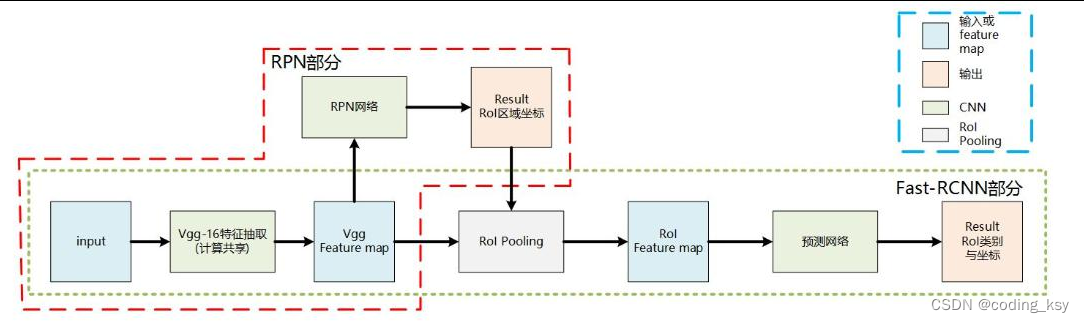
两阶段(two-stage)是指先通过一个区域提取网络(region proposal network,RPN)生成候选框,再通过一个分类回归网络进行目标检测。Faster R-CNN和Mask R-CNN就是经典的两阶段目标检测模型。
Faster R-CNN将RPN和分类回归网络结合在一起,可以实现端到端的训练和推理。Mask R-CNN在Faster R-CNN的基础上增加了一个分割分支,可以同时进行目标检测和实例分割。两阶段模型在准确率上表现优秀,但相对于单阶段模型速度较慢。
one-stage(单阶段):YOLO系列
YOLO(You Only Look Once,你只需要看一次)系列是一种先进的目标检测算法,其中包括YOLOv1、YOLOv2、YOLOv3和YOLOv4等版本。这些算法采用了单阶段的检测方式,即所有目标的检测和分类都在一个单独的网络中完成。在YOLO系列中,图像被分成一个固定的网格,每个网格预测一个定量的边界框和类别。相比于传统的两阶段检测(如Faster R-CNN和Mask R-CNN),YOLO系列具有更快的检测速度和更高的实时性能,但也存在一定的精度损失。

one-stage:
最核心的优势:速度非常快,适合做实时检测任务!
但是缺点也是有的,效果通常情况下不会太好!
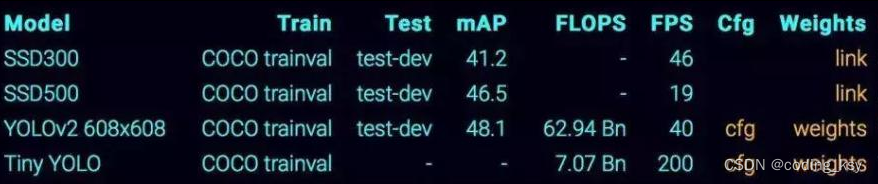
two-stage:
速度通常较慢(5FPS),但是效果通常还是不错的!
非常实用的通用框架MaskRcnn,建议熟悉下!
指标分析
map指标:综合衡量检测效果;单看精度和recall不行吗?

 检测任务中的精度和召回率分别代表什么?
检测任务中的精度和召回率分别代表什么?
在机器学习和数据挖掘中,精度和召回率是常用的评估指标,用于评估分类模型的效果。它们通常用于度量分类模型的性能,以确定模型在确定类别时的准确性和完整性。
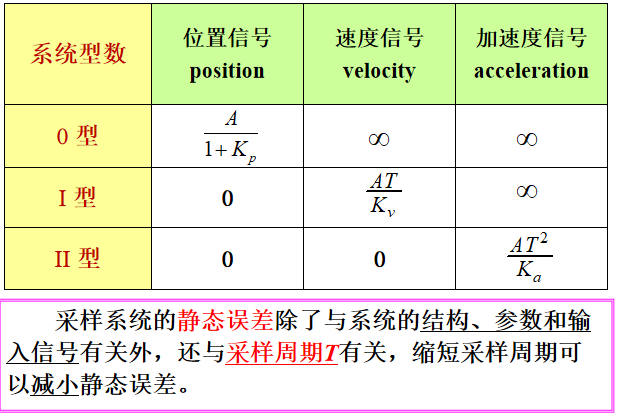
精度指的是模型预测正确的样本数占总样本数的比例,即:
精度 = T P + T N T P + T N + F P + F N 精度 = \frac{TP + TN}{TP + TN + FP + FN} 精度=TP+TN+FP+FNTP+TN
其中, T P TP TP 表示真正例(True Positive),即正类被预测为正类的数量; T N TN TN 表示真负例(True Negative),即负类被预测为负类的数量; F P FP FP 表示假正例(False Positive),即负类被预测为正类的数量; F N FN FN 表示假负例(False Negative),即正类被预测为负类的数量。
召回率指的是模型能够正确识别出的正类样本占所有正类样本的比例,即:
召回率 = T P T P + F N 召回率 = \frac{TP}{TP + FN} 召回率=TP+FNTP
其中, T P TP TP 和 F N FN FN 的含义与精度相同。
简单来说,精度反映了模型分类的准确性,而召回率反映了模型覆盖所有样本的能力。在实际应用中,需要根据具体的场景和需求来选择更为重要的指标。

基于置信度阈值来计算,例如分别计算0.9;0.8;0.7
0.9时:TP+FP = 1,TP = 1 ;FN = 2;Precision=1/1;Recall=1/3;
 如何计算AP呢?需要把所有阈值都考虑进来;MAP就是所有类别的平均
如何计算AP呢?需要把所有阈值都考虑进来;MAP就是所有类别的平均
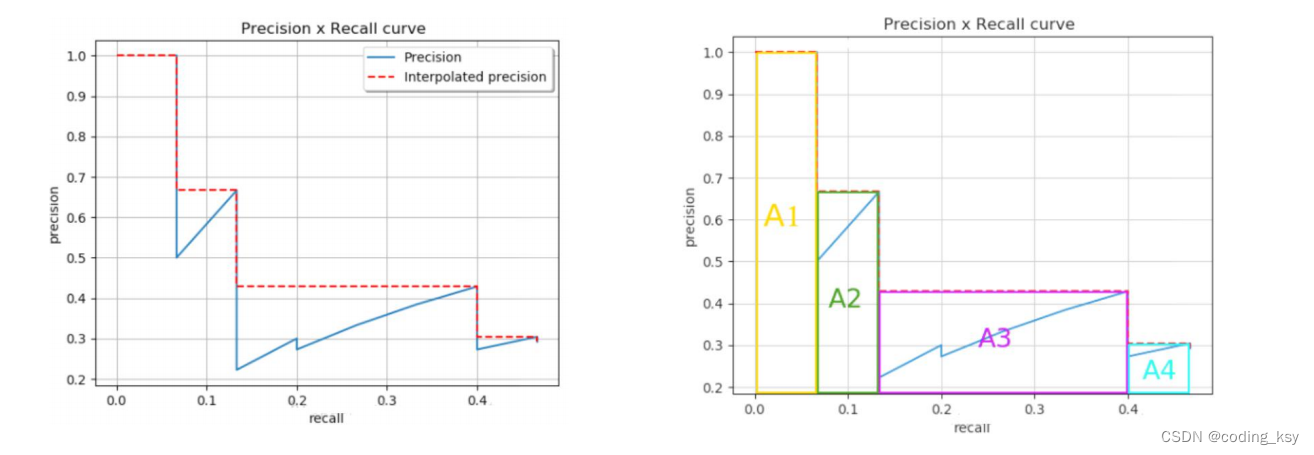
在深度学习中,mAP(mean Average Precision)是一种广泛使用的评估指标,其用于衡量在目标检测任务中模型的性能。mAP可以简单地理解为所有类别的平均精度。
在目标检测中,一个模型会生成一系列的预测结果。每个预测结果包含一个目标的类别和位置信息,可能与实际的目标进行匹配,也可能与其它目标进行匹配。通过比较预测结果和真实目标之间的差异,我们可以计算出模型的精度。
在多类别情况下,我们需要计算每个类别的精度。对于每个类别,我们可以计算出一个AP(Average Precision)值。AP值是在不同阈值下的精度(Precision)和召回率(Recall)的计算结果。AP值是一个0到1之间的值,0表示模型没有正确预测任何目标,1表示模型完全正确地预测了所有目标。
平均精度mAP是所有类别的AP值的平均值。
计算mAP的公式如下:
m A P = ∑ i = 1 c A P i c mAP=\frac{\sum_{i=1}^cAP_i}{c} mAP=c∑i=1cAPi
其中,c表示类别数,APi表示第i个类别的AP值。
mAP是一个常用的目标检测评估指标,因为它能够同时考虑模型的准确性和召回率。在实际使用中,我们会使用各种工具和框架来计算mAP值,比如Python的sklearn.metrics库。





![[PyTorch][chapter 51][Auto-Encoder -1]](https://img-blog.csdnimg.cn/ad287288c7c942129815f6fced4716db.png)