需求背景
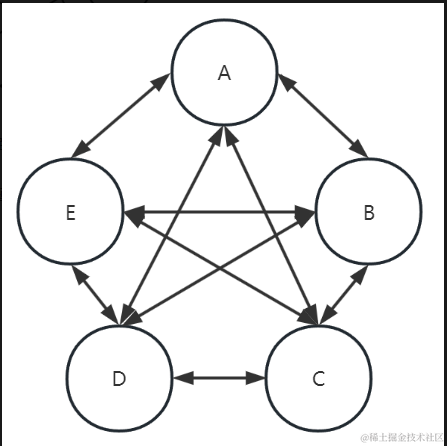
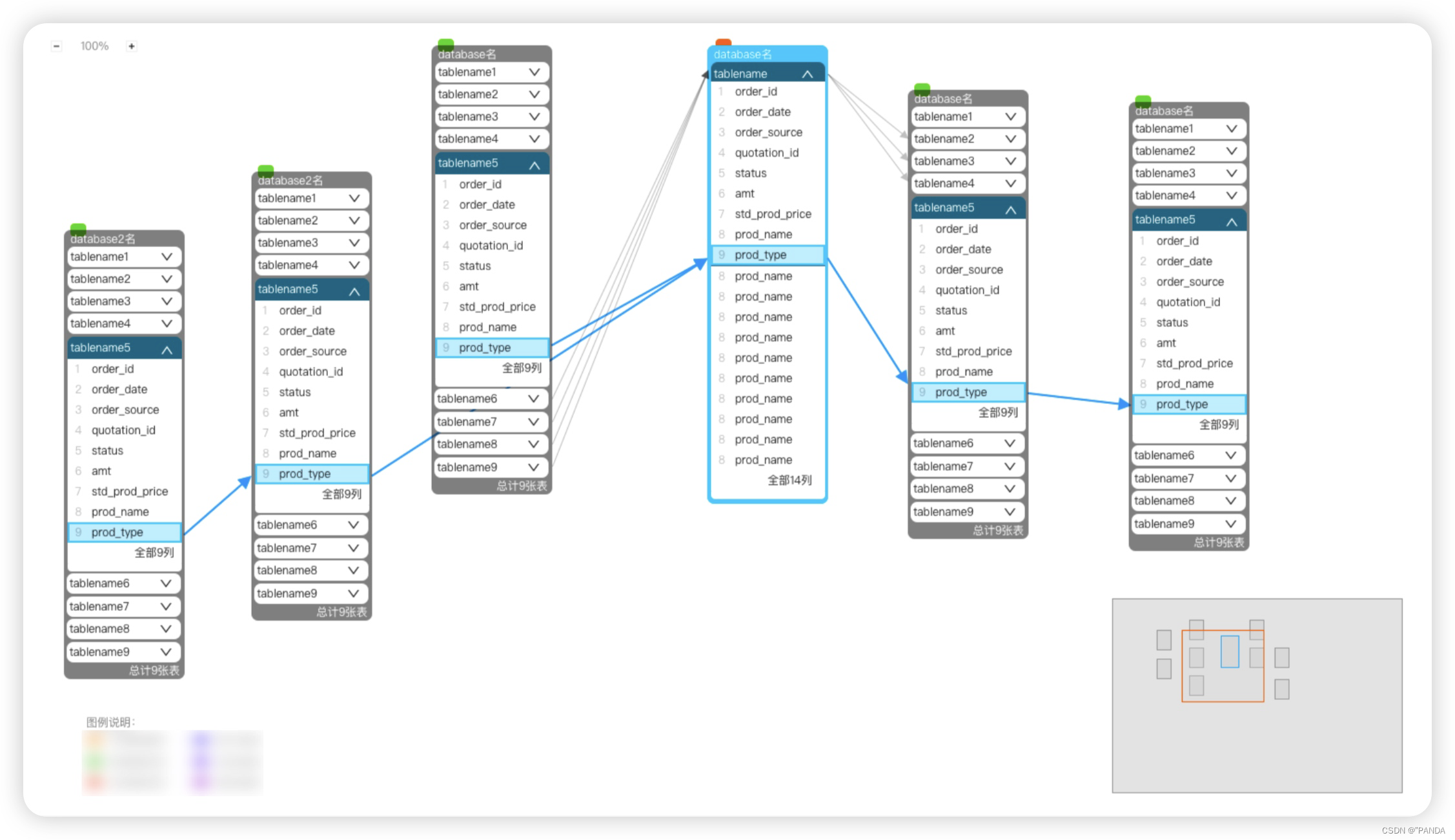
需要在前端页面展示当前表字段的所有上下游血缘关系,以进一步做数据诊断治理。大致效果图如下:
 首先这里解释什么是表字段血缘关系,SQL 示例:
首先这里解释什么是表字段血缘关系,SQL 示例:
CREATE TABLE IF NOT EXISTS table_b
AS SELECT order_id, order_status FROM table_a;
如上 DDL 语句中,创建的 table_b 的 order_id 和 order_status 字段来源于 table_a,代表table_a 就是 table_b 的来源表,也叫上游表,table_b 就是 table_a 下游表,另外 table_a.order_id 就是 table_b.order_id 的上游字段,它们之间就存在血缘关系。
INSERT INTO table_c
SELECT a.order_id, b.order_status
FROM table_a a JOIN table_b b ON a.order_id = b.order_id;
如上 DML 语句中,table_c 的 order_id 字段来源于 table_a,而 order_status 来源于 table_b,表示 table_c 和 table_a、table_b 之间也存在血缘关系。
由上也可看出想要存储血缘关系,还需要先解析 sql,这块儿主要使用了开源项目 calcite 的解析器,这篇文章不再展开,本篇主要讲如何存储和如何展示
环境配置
参考另一篇:SpringBoot 配置内嵌式 Neo4j
Node 数据结构定义
因为要展示表的字段之间的血缘关系,所以直接将表字段作为图节点存储,表字段之间的血缘关系就用图节点之间的关系表示,具体 node 定义如下:
public class ColumnVertex {// 唯一键private String name;public ColumnVertex(String catalogName, String databaseName, String tableName, String columnName) {this.name = catalogName + "." + databaseName + "." + tableName + "." + columnName;}public String getCatalogName() {return Long.parseLong(name.split("\\.")[0]);}public String getDatabaseName() {return name.split("\\.")[1];}public String getTableName() {return name.split("\\.")[2];}public String getColumnName() {return name.split("\\.")[3];}
}
通用 Service 定义
public interface EmbeddedGraphService {// 添加图节点以及与上游节点之间的关系void addColumnVertex(ColumnVertex currentVertex, ColumnVertex upstreamVertex);// 寻找上游节点List<ColumnVertex> findUpstreamColumnVertex(ColumnVertex currentVertex);// 寻找下游节点List<ColumnVertex> findDownstreamColumnVertex(ColumnVertex currentVertex);
}
Service 实现
import javax.annotation.Resource;
import org.neo4j.graphdb.GraphDatabaseService;
import org.neo4j.graphdb.Result;
import org.neo4j.graphdb.Transaction;
import org.springframework.stereotype.Service;@Service
public class EmbeddedGraphServiceImpl implements EmbeddedGraphService {@Resource private GraphDatabaseService graphDb;@Overridepublic void addColumnVertex(ColumnVertex currentVertex, ColumnVertex upstreamVertex) {try (Transaction tx = graphDb.beginTx()) {tx.execute("MERGE (c:ColumnVertex {name: $currentName}) MERGE (u:ColumnVertex {name: $upstreamName})"+ " MERGE (u)-[:UPSTREAM]->(c)",Map.of("currentName", currentVertex.getName(), "upstreamName", upstreamVertex.getName()));tx.commit();}}@Overridepublic List<ColumnVertex> findUpstreamColumnVertex(ColumnVertex currentVertex) {List<ColumnVertex> result = new ArrayList<>();try (Transaction tx = graphDb.beginTx()) {Result queryResult =tx.execute("MATCH (u:ColumnVertex)-[:UPSTREAM]->(c:ColumnVertex) WHERE c.name = $name RETURN"+ " u.name AS name",Map.of("name", currentVertex.getName()));while (queryResult.hasNext()) {Map<String, Object> row = queryResult.next();result.add(new ColumnVertex().setName((String) row.get("name")));}tx.commit();}return result;}@Overridepublic List<ColumnVertex> findDownstreamColumnVertex(ColumnVertex currentVertex) {List<ColumnVertex> result = new ArrayList<>();try (Transaction tx = graphDb.beginTx()) {Result queryResult =tx.execute("MATCH (c:ColumnVertex)-[:UPSTREAM]->(d:ColumnVertex) WHERE c.name = $name RETURN"+ " d.name AS name",Map.of("name", currentVertex.getName()));while (queryResult.hasNext()) {Map<String, Object> row = queryResult.next();result.add(new ColumnVertex().setName((String) row.get("name")));}tx.commit();}return result;}
}
遍历图节点
实现逻辑:
- restful 接口入参:当前表(catalogName, databaseName, tableName)
- 定义返回给前端的数据结构,采用 nodes 和 edges 方式返回,然后前端再根据节点与边关系渲染出完整的血缘关系图;
public class ColumnLineageVO {List<ColumnLineageNode> nodes;List<ColumnLineageEdge> edges;
}public class ColumnLineageNode {private String databaseName;private String tableName;private List<String> columnNames;
}public class ColumnLineageEdge {private ColumnLineageEdgePoint source;private ColumnLineageEdgePoint target;
}public class ColumnLineageEdgePoint {private String databaseName;private String tableName;private String columnName;
}
- 查询表字段;
- 采用递归的方式,利用当前表字段遍历与当前表字段关联的所有上下游图节点;
- 将所有节点封装成 List ColumnLineageVO 返回给前端 。
public ColumnLineageVO getColumnLineage(Table table) {ColumnLineageVO columnLineageVO = new ColumnLineageVO();List<ColumnLineageNode> nodes = new ArrayList<>();List<ColumnLineageEdge> edges = new ArrayList<>();// DeduplicationSet<String> visitedNodes = new HashSet<>();Set<String> visitedEdges = new HashSet<>();Map<String, List<ColumnVertex>> upstreamCache = new HashMap<>();Map<String, List<ColumnVertex>> downstreamCache = new HashMap<>();ColumnLineageNode currentNode =ColumnLineageNode.builder().databaseName(table.getDatabaseName()).tableName(table.getTableName()).type(TableType.EXTERNAL_TABLE.getDesc()).build();nodes.add(currentNode);visitedNodes.add(currentNode.getDatabaseName() + "." + currentNode.getTableName());for (String columnName : table.getColumnNames()) {ColumnVertex currentVertex =new ColumnVertex(table.getScriptId(), table.getDatabaseName(), table.getTableName(), columnName);traverseUpstreamColumnVertex(currentVertex, nodes, edges, visitedNodes, visitedEdges, upstreamCache);traverseDownstreamColumnVertex(currentVertex, nodes, edges, visitedNodes, visitedEdges, downstreamCache);}columnLineageVO.setNodes(nodes);columnLineageVO.setEdges(edges);return columnLineageVO;}private void traverseUpstreamColumnVertex(ColumnVertex currentVertex,List<ColumnLineageNode> nodes,List<ColumnLineageEdge> edges,Set<String> visitedNodes,Set<String> visitedEdges,Map<String, List<ColumnVertex>> cache) {List<ColumnVertex> upstreamVertices;if (cache.containsKey(currentVertex.getName())) {upstreamVertices = cache.get(currentVertex.getName());} else {upstreamVertices = embeddedGraphService.findUpstreamColumnVertex(currentVertex);cache.put(currentVertex.getName(), upstreamVertices);}for (ColumnVertex upstreamVertex : upstreamVertices) {String nodeKey = upstreamVertex.getDatabaseName() + "." + upstreamVertex.getTableName();if (!visitedNodes.contains(nodeKey)) {ColumnLineageNode upstreamNode =ColumnLineageNode.builder().databaseName(upstreamVertex.getDatabaseName()).tableName(upstreamVertex.getTableName()).type(TableType.EXTERNAL_TABLE.getDesc()).build();nodes.add(upstreamNode);visitedNodes.add(nodeKey);}String edgeKey =upstreamVertex.getDatabaseName()+ upstreamVertex.getTableName()+ upstreamVertex.getColumnName()+ currentVertex.getDatabaseName()+ currentVertex.getTableName()+ currentVertex.getColumnName();if (!visitedEdges.contains(edgeKey)) {ColumnLineageEdge edge = createEdge(upstreamVertex, currentVertex);edges.add(edge);visitedEdges.add(edgeKey);}traverseUpstreamColumnVertex(upstreamVertex, nodes, edges, visitedNodes, visitedEdges, cache);}}private void traverseDownstreamColumnVertex(ColumnVertex currentVertex,List<ColumnLineageNode> nodes,List<ColumnLineageEdge> edges,Set<String> visitedNodes,Set<String> visitedEdges,Map<String, List<ColumnVertex>> cache) {List<ColumnVertex> downstreamVertices;if (cache.containsKey(currentVertex.getName())) {downstreamVertices = cache.get(currentVertex.getName());} else {downstreamVertices = embeddedGraphService.findDownstreamColumnVertex(currentVertex);cache.put(currentVertex.getName(), downstreamVertices);}for (ColumnVertex downstreamVertex : downstreamVertices) {String nodeKey = downstreamVertex.getDatabaseName() + "." + downstreamVertex.getTableName();if (!visitedNodes.contains(nodeKey)) {ColumnLineageNode downstreamNode =ColumnLineageNode.builder().databaseName(downstreamVertex.getDatabaseName()).tableName(downstreamVertex.getTableName()).type(TableType.EXTERNAL_TABLE.getDesc()).build();nodes.add(downstreamNode);visitedNodes.add(nodeKey);}String edgeKey =currentVertex.getDatabaseName()+ currentVertex.getTableName()+ currentVertex.getColumnName()+ downstreamVertex.getDatabaseName()+ downstreamVertex.getTableName()+ downstreamVertex.getColumnName();if (!visitedEdges.contains(edgeKey)) {ColumnLineageEdge edge = createEdge(currentVertex, downstreamVertex);edges.add(edge);visitedEdges.add(edgeKey);}traverseDownstreamColumnVertex(downstreamVertex, nodes, edges, visitedNodes, visitedEdges, cache);}}




![[管理与领导-49]:IT基层管理者 - 8项核心技能 - 4 - 团队激励](https://img-blog.csdnimg.cn/img_convert/f1b7ae8168218cb0e9b11d6fa23f2fd5.jpeg)