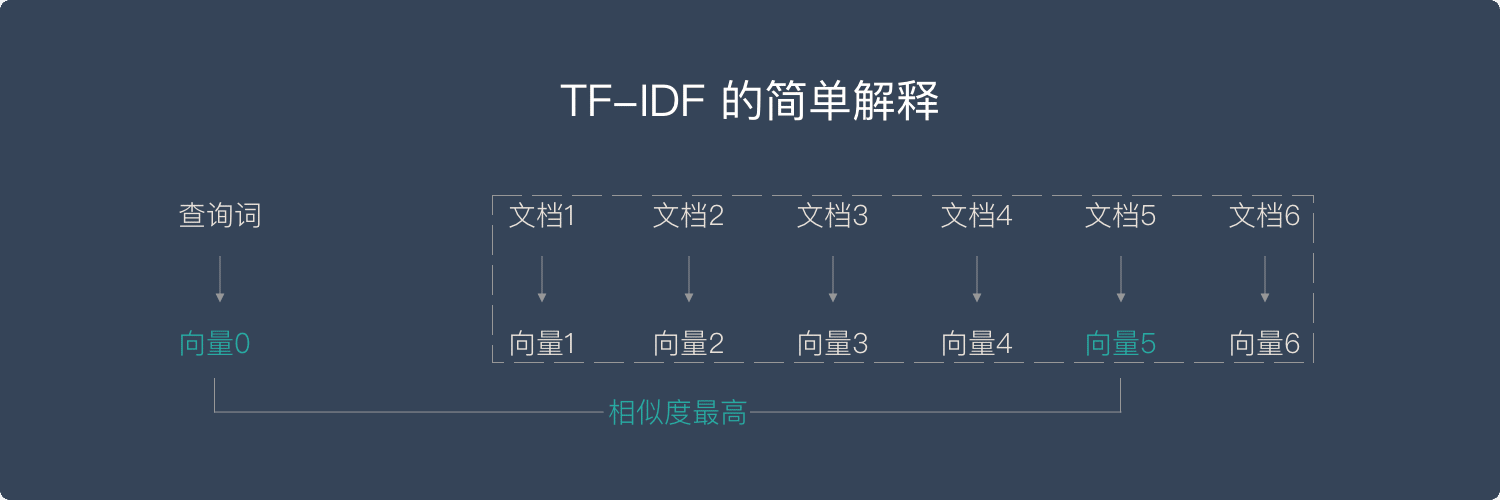
简单来说,向量空间模型就是希望把查询关键字和文档都表达成向量,然后利用向量之间的运算来进一步表达向量间的关系。比如,一个比较常用的运算就是计算查询关键字所对应的向量和文档所对应的向量之间的 “相关度”。
简单解释TF-IDF
TF (Term Frequency)—— “单词频率”
意思就是说,我们计算一个查询关键字中某一个单词在目标文档中出现的次数。举例说来,如果我们要查询 “Car Insurance”,那么对于每一个文档,我们都计算“Car” 这个单词在其中出现了多少次,“Insurance”这个单词在其中出现了多少次。这个就是 TF 的计算方法。
TF 背后的隐含的假设是,查询关键字中的单词应该相对于其他单词更加重要,而文档的重要程度,也就是相关度,与单词在文档中出现的次数成正比。比如,“Car” 这个单词在文档 A 里出现了 5 次,而在文档 B 里出现了 20 次,那么 TF 计算就认为文档 B 可能更相关。
然而,信息检索工作者很快就发现,仅有 TF 不能比较完整地描述文档的相关度。因为语言的因素,有一些单词可能会比较自然地在很多文档中反复出现,比如英语中的 “The”、“An”、“But” 等等。这些词大多起到了链接语句的作用,是保持语言连贯不可或缺的部分。然而,如果我们要搜索 “How to Build A Car” 这个关键词,其中的 “How”、“To” 以及 “A” 都极可能在绝大多数的文档中出现,这个时候 TF 就无法帮助我们区分文档的相关度了。
IDF(Inverse Document Frequency)—— “逆文档频率”
就在这样的情况下应运而生。这里面的思路其实很简单,那就是我们需要去 “惩罚”(Penalize)那些出现在太多文档中的单词。
也就是说,真正携带 “相关” 信息的单词仅仅出现在相对比较少,有时候可能是极少数的文档里。这个信息,很容易用 “文档频率” 来计算,也就是,有多少文档涵盖了这个单词。很明显,如果有太多文档都涵盖了某个单词,这个单词也就越不重要,或者说是这个单词就越没有信息量。因此,我们需要对 TF 的值进行修正,而 IDF 的想法是用 DF 的倒数来进行修正。倒数的应用正好表达了这样的思想,DF 值越大越不重要。
TF-IDF 算法主要适用于英文,中文首先要分词,分词后要解决多词一义,以及一词多义问题,这两个问题通过简单的tf-idf方法不能很好的解决。于是就有了后来的词嵌入方法,用向量来表征一个词。
TF-IDF 的4个变种

TF-IDF常见的4个变种
变种1:通过对数函数避免 TF 线性增长
很多人注意到 TF 的值在原始的定义中没有任何上限。虽然我们一般认为一个文档包含查询关键词多次相对来说表达了某种相关度,但这样的关系很难说是线性的。拿我们刚才举过的关于 “Car Insurance” 的例子来说,文档 A 可能包含 “Car” 这个词 100 次,而文档 B 可能包含 200 次,是不是说文档 B 的相关度就是文档 A 的 2 倍呢?其实,很多人意识到,超过了某个阈值之后,这个 TF 也就没那么有区分度了。
用 Log,也就是对数函数,对 TF 进行变换,就是一个不让 TF 线性增长的技巧。具体来说,人们常常用 1+Log(TF) 这个值来代替原来的 TF 取值。在这样新的计算下,假设 “Car” 出现一次,新的值是 1,出现 100 次,新的值是 5.6,而出现 200 次,新的值是 6.3。很明显,这样的计算保持了一个平衡,既有区分度,但也不至于完全线性增长。
变种2:标准化解决长文档、短文档问题
经典的计算并没有考虑 “长文档” 和“短文档”的区别。一个文档 A 有 3,000 个单词,一个文档 B 有 250 个单词,很明显,即便 “Car” 在这两个文档中都同样出现过 20 次,也不能说这两个文档都同等相关。对 TF 进行 “标准化”(Normalization),特别是根据文档的最大 TF 值进行的标准化,成了另外一个比较常用的技巧。
变种3:对数函数处理 IDF
第三个常用的技巧,也是利用了对数函数进行变换的,是对 IDF 进行处理。相对于直接使用 IDF 来作为 “惩罚因素”,我们可以使用 N+1 然后除以 DF 作为一个新的 DF 的倒数,并且再在这个基础上通过一个对数变化。这里的 N 是所有文档的总数。这样做的好处就是,第一,使用了文档总数来做标准化,很类似上面提到的标准化的思路;第二,利用对数来达到非线性增长的目的。
变种4:查询词及文档向量标准化
还有一个重要的 TF-IDF 变种,则是对查询关键字向量,以及文档向量进行标准化,使得这些向量能够不受向量里有效元素多少的影响,也就是不同的文档可能有不同的长度。在线性代数里,可以把向量都标准化为一个单位向量的长度。这个时候再进行点积运算,就相当于在原来的向量上进行余弦相似度的运算。所以,另外一个角度利用这个规则就是直接在多数时候进行余弦相似度运算,以代替点积运算。
TF-IDF
是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
在信息检索中,tf-idf或TFIDF(术语频率 – 逆文档频率的缩写)是一种数字统计,旨在反映单词对集合或语料库中的文档的重要程度。它经常被用作搜索信息检索,文本挖掘和用户建模的加权因子。tf-idf值按比例增加一个单词出现在文档中的次数,并被包含该单词的语料库中的文档数量所抵消,这有助于调整某些单词在一般情况下更频繁出现的事实。Tf-idf是当今最受欢迎的术语加权方案之一; 数字图书馆中83%的基于文本的推荐系统使用tf-idf。
搜索引擎经常使用tf-idf加权方案的变体作为在给定用户查询的情况下对文档的相关性进行评分和排序的中心工具。tf-idf可以成功地用于各种主题领域的停用词过滤,包括文本摘要和分类。