1. GLM
https://arxiv.org/pdf/2103.10360.pdf
GLM是General Language Model的缩写,是一种通用的语言模型预训练框架。它的主要目标是通过自回归的空白填充来进行预训练,以解决现有预训练框架在自然语言理解(NLU)、无条件生成和有条件生成等任务中表现不佳的问题。
具体来说,GLM通过随机遮盖文本中连续的标记,并训练模型按顺序重新生成这些遮盖的部分。这种自回归的空白填充目标使得GLM能够更好地捕捉上下文中标记之间的依赖关系,并且能够处理可变长度的空白。通过添加二维位置编码和允许任意顺序预测空白,GLM改进了空白填充预训练的性能。
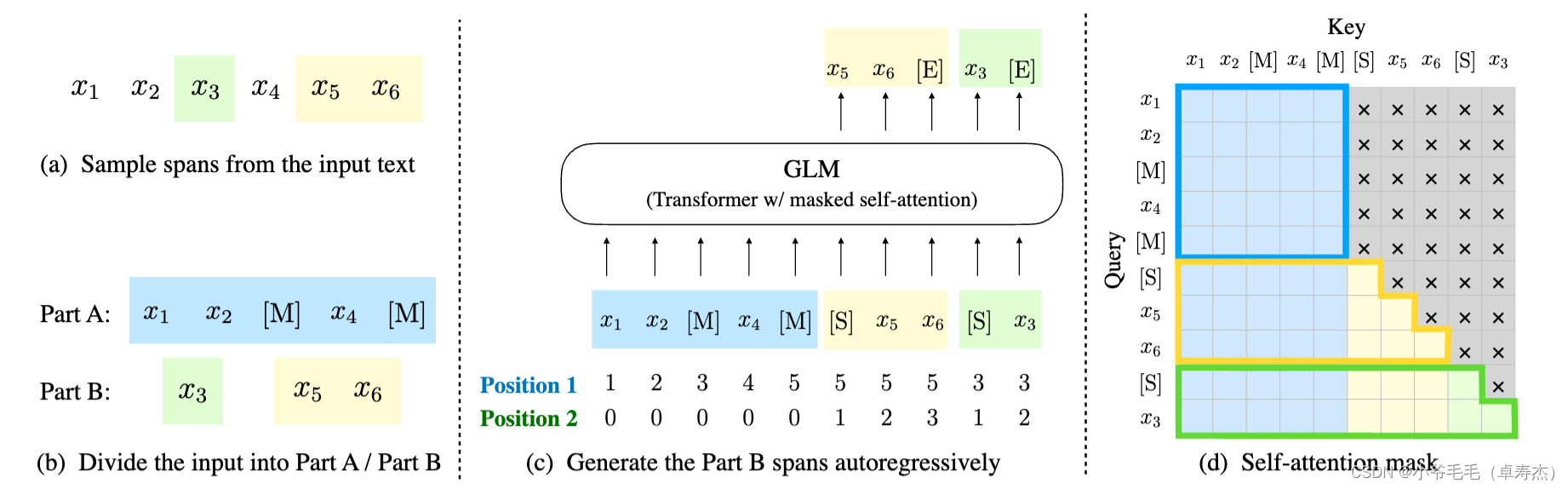
这个图示说明了GLM预训练的过程,具体解释如下:
a) 原始文本:给定一个原始文本,例如[x1, x2, x3, x4, x5, x6]。在这个例子中,我们随机选择了两个连续的词片段[x3]和[x5, x6]作为样本。
b) 替换和洗牌:在Part A中,我们将被选择的词片段替换为[M](表示遮盖)。在Part B中,我们将被选择的词片段进行洗牌,即改变它们的顺序。在这个例子中,我们将[x3]和[x5, x6]洗牌为[x5, x6]和[x3]。
c) 自回归生成:GLM使用自回归的方式生成Part B。每个词片段都以[S]作为输入的前缀,以[E]作为输出的后缀。在生成过程中,模型可以根据之前生成的词片段和Part A中的上下文来预测下一个词片段。
d) 自注意力掩码:为了限制模型的注意力范围,







![[管理与领导-55]:IT基层管理者 - 扩展技能 - 1 - 时间管理 -2- 自律与自身作则,管理者管好自己时间的五步法](https://img-blog.csdnimg.cn/6d9e69c1648344bcbc09817f085f7693.png)