目录
- 5.1 Kafka的消费方式
- 5.2 Kafka 消费者工作流程
- 1、总体流程
- 2、消费者组原理
- 3、==消费者组初始化流程==
- 4、==消费者组详细消费流程==
- 5.3 消费者API
- 1 独立消费者案例(订阅主题)
- 2 独立消费者案例(订阅分区)
- 3 消费者组案例
- 5.4 生产经验——分区的分配以及再平衡
5.1 Kafka的消费方式
pull(拉)模 式:consumer采用从broker中主动拉取数据。Kafka采用这种方式。
缺点: pull模式不足之处是,如 果Kafka没有数据,消费者可能会陷入循环中,一直返回空数据
push(推)模式:Kafka没有采用这种方式,因为由broker决定消息发送速率,很难适应所有消费者的消费速率
5.2 Kafka 消费者工作流程
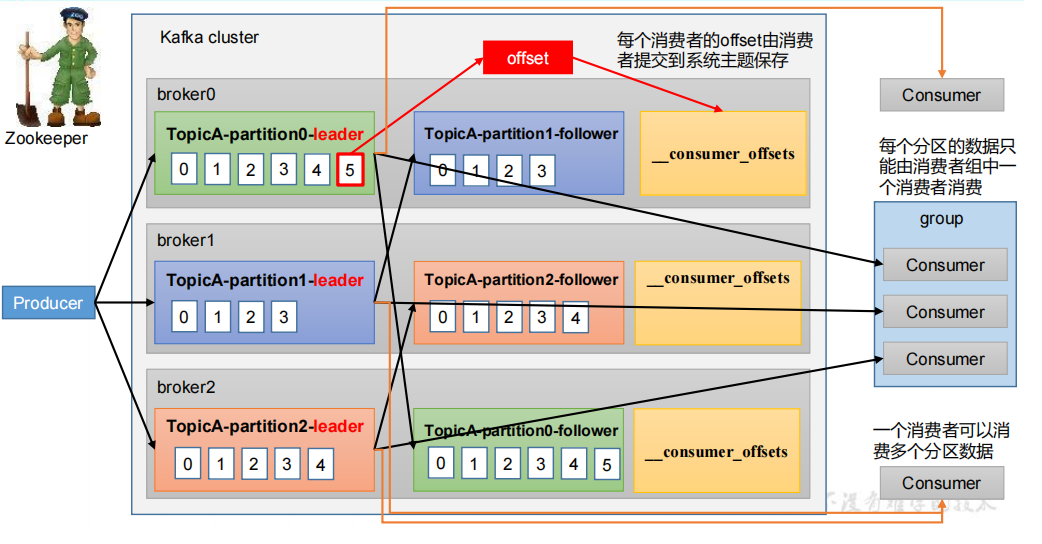
1、总体流程
【注意】
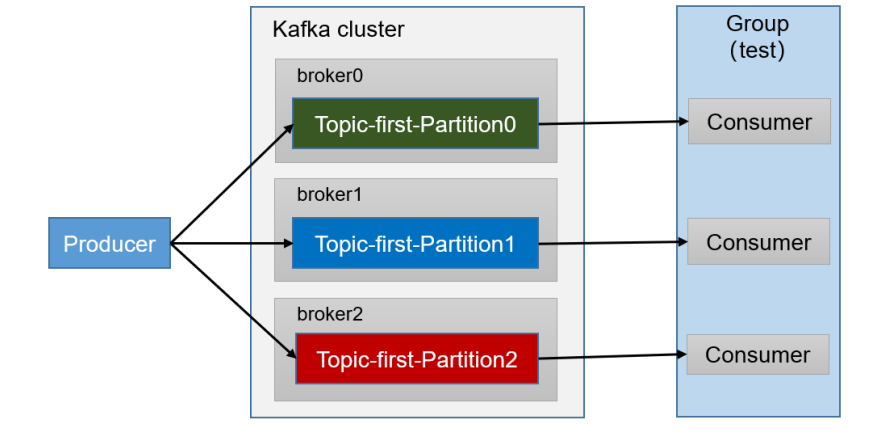
- 消费者只能从主分区上拉取数据,从节点起到同步和冗余数据的作用
- 每个分区的数据只能由消费者组中一个消费者消费
- 一个消费者可以消费多个分区数据
- 每个消费者的offset由消费者提交到系统主题保存
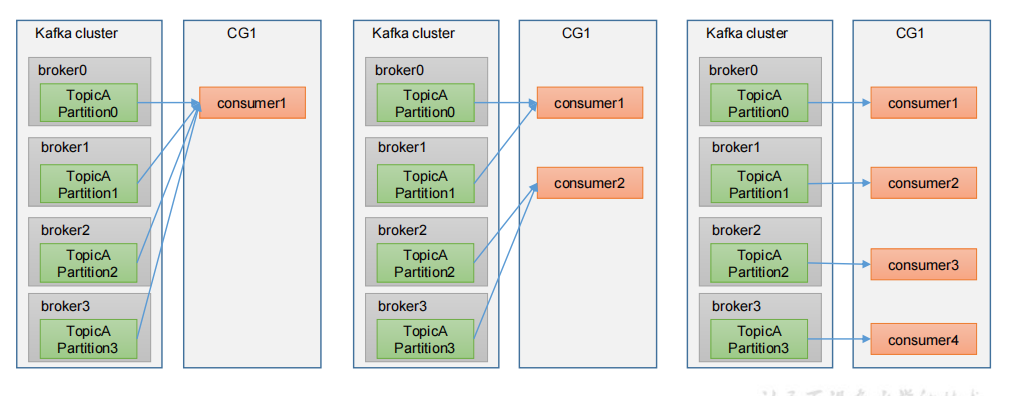
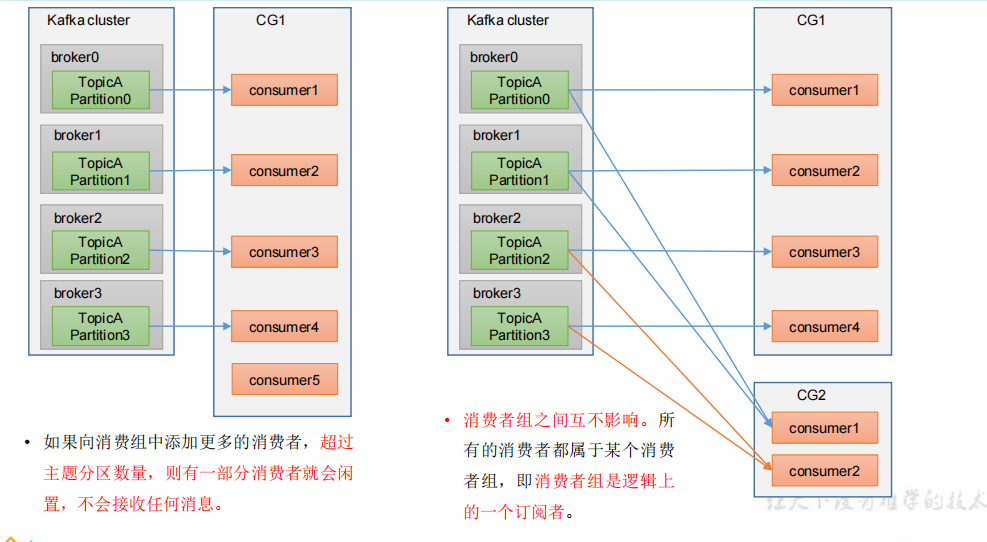
2、消费者组原理
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
3、消费者组初始化流程
4、消费者组详细消费流程

5.3 消费者API
1 独立消费者案例(订阅主题)
public class CustomConsumer {public static void main(String[] args) {// 0 配置Properties properties = new Properties();// 连接 bootstrap.serversproperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.239.11:9092");// 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test5");// 设置分区分配策略// 1 创建一个消费者 "", "hello"KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题 firstArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);// 3 消费数据while (true){ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}kafkaConsumer.commitAsync();}}
}

2 独立消费者案例(订阅分区)
public class CustomConsumerPartition {public static void main(String[] args) {// 0 配置Properties properties = new Properties();// 连接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");// 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");// 1 创建一个消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题对应的分区ArrayList<TopicPartition> topicPartitions = new ArrayList<>();topicPartitions.add(new TopicPartition("first",0));kafkaConsumer.assign(topicPartitions);// 3 消费数据while (true){ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}}
}3 消费者组案例
1)需求:测试同一个主题的分区数据,只能由一个消费者组中的一个消费










![java八股文面试[JVM]——类加载器](https://img-blog.csdnimg.cn/7a478168f1c649029829e68945891a2c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcXFfMzkwOTM0NzQ=,size_20,color_FFFFFF,t_70,g_se,x_16)