作者 | 智商掉了一地、兔子酱
AI 新闻速递来咯!搬好小板凳,一起了解近期发生了什么新鲜事~
领英职场退出中国

领英是一个专注于职业发展、招聘和营销等方面的社交平台。Linkdein 官方公众号发布公告称,由于面临日趋激烈的市场竞争和宏观经济环境带来的挑战,其在中国的本土化求职平台——“领英职场”将于2023年8月9日起正式停止服务。同时,领英将在过渡期间为用户提供帮助,并支持用户下载“领英职场”个人账号数据等操作。
尽管这对部分用户来说是不利消息,但对于在中国市场的未来发展,领英在文中表示将继续深耕中国市场,通过人才和营销解决方案,以及即将落地中国内地的领英学习解决方案,来支持中国企业的全球化发展,这也还算是一个积极的信号吧
参考链接:
https://mp.weixin.qq.com/s/jJqEcQkbCm4vwFSmpLYL1A
各个大模型的研究测试传送门
阿里通义千问传送门:
https://tongyi.aliyun.com
百度文心一言传送门:
https://yiyan.baidu.com
ChatGPT传送门(免墙,可直接测试):
https://yeschat.cn
GPT-4传送门(免墙,可直接测试,遇到浏览器警告点高级/继续访问即可):
https://gpt4test.com
谷歌 Bard 或将集成进 Pixel 手机

近日有消息称,Google 正在为其 AI 聊天机器人 Bard 开发一个主屏幕小部件,Pixel 手机的用户可以准备体验咯。根据报道显示,Bard 将会在不久之后与安卓系统相结合,这可能包括或者围绕着这个主屏幕小部件展开。
不过,目前所了解到的信息还比较少,并没有透露这个 Bard 小部件具体的功能,它可能只是Bard聊天机器人的一个主屏幕版本,类似于在 Web 浏览器中已经能够使用的 Bard 聊天机器人,但也说不准会提供更多功能。
另外,从这个报道中还可以挖掘到一些有趣的细节。首先,这个 Bard 小部件可能会在一段时间内只在 Pixel 手机上使用。其次,Bard 目前需要用户加入等待列表才能开始使用,但 Pixel 用户可能会例外,或者等待列表可能很快就会取消。不管怎样,Pixel 手机用户都会是最大的赢家。
参考链接:
https://mashable.com/article/google-bard-ai-chatbot-pixel-widget
陆奇北京站公开演讲「新范式 新时代 新机会」

在近日北京的公开演讲中,陆奇围绕新范式的缔造者 OpenAI 的崛起进行了深入的分析。
他指出技术驱动着人类社会发展的结构与范式产生更迭,我们现在正处在一个新范式的重要拐点,其中包括信息生态系统、模型系统和行动系统三个体系的组合。我们已经走过信息无处不在的互联网范式阶段,在当前阶段中“模型”知识无处不在,基于大模型的新一代认知思考能力工具已经在逐步替代重复的脑力劳动。
陆奇认为大模型技术的创新,将模型的成本从边际走向固定,未来唯一有价值的是人类自己的见解。而在大模型之后,他对于下一个可能的范式也进行了畅想,下个拐点将是行动无处不在的时代,也就是自动驾驶、机器人、空间计算的到来。大模型在国内的发展机会巨大,要奋起直追。他还对创业公司给出了一定的建议,包括勤学、有规划地采取行动以及明确未来的导向等。最后,他还介绍了当前的机会板块,主要包括改造世界和认识世界两部分。
参考链接:
https://new.qq.com/rain/a/20230508A00SSL00
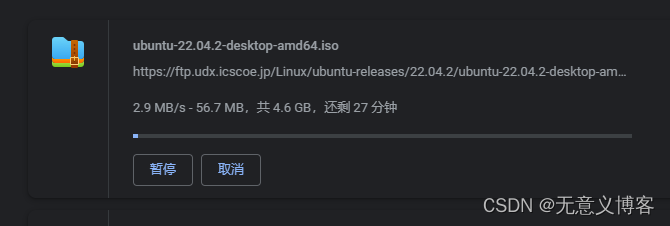
Huggingface 遭禁,国内 IP 无法访问?虚惊一场!
昨天早上,在群里突然看到一则消息“Huggingface 在国内无法正常访问”,评论区有网友甚至贴出了下面这张测速的全红截图:

小编到中午去尝试的时候还发现无法正常访问,不过还好只是虚惊一场,昨晚已经恢复正常了,甚至感觉比平时访问还要快~

参考链接:
https://www.zhihu.com/pin/1638708324932714496?utm_source=wechat_session&utm_medium=social&utm_oi=768452431364227072&utm_id=0
Huggingface 简介
或许在许多人眼中,Huggingface 只是一个用于寻找预训练模型的开源网站,但近期它也有了大动作,推出了号称媲美 GPT-3.5 的聊天机器人 HuggingChat,它搭载了Open Assistant开发的模型,可以聊天也可以拿来改代码。
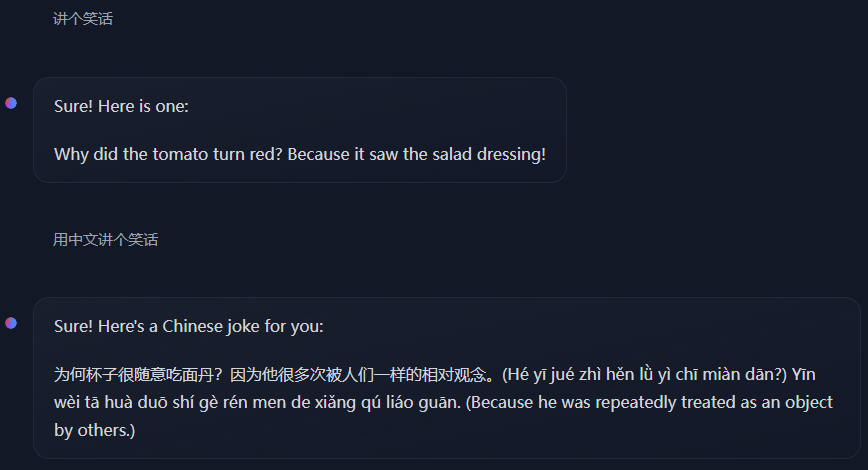
不过显然,虽然懂中文,但不多:
此外,Huggingface 上还可以部署新的大模型,让用户能便捷体验一些对话机器人的 Demo,比如咱们之前介绍过的AudioGPT和StableLM。
Huggingface 提供了一系列处理自然语言的强大工具和模型,可以帮助研究人员、开发者和初学者快速构建、训练和部署自然语言处理相关的应用程序。以下是 Huggingface 的一些玩法:
- Models:各种预训练的开源模型;
- Datasets:用于自然语言处理任务的库,包含了许多热门数据集,例如 GLUE 和 SuperGLUE 等。这些数据集可用于研究和开发自然语言处理模型;
- Transformers:流行的自然语言处理模型库,包含了大量预训练模型,例如 GPT-2、XLNet 和 BERT 等。开发者可以利用这些预训练模型进行微调,以便更好地适应他们的特定应用程序;
- Tokenizers:用于自然语言处理的快速分词库,支持包括Unicode和多语言在内的多种语言。它可以分词文本以及训练和保存词汇表;
- Space:旨在为自然语言处理社区提供一个交流平台,开发者和研究人员可以在这里分享想法、模型和代码,并且可以发布和管理自己的模型。可以看成是 AI 模型及其应用的有趣榜单,近期最热门的几个项目貌似都与 Stable Diffusion 有关;
- Docs:各种开源模型和数据集的文档,教程非常详尽,大多质量都很高,对于入门者很友好。

Huggingface 在科学研究和生产之间架起了一座桥梁,为开源社区和科学研究者提供平台,实现了科学与生产的紧密结合。可以说,Huggingface 已经成为了“AI界的GitHub”。尤其是 AI 初学者,几乎都会通过这个开源网站接触到 BERT 等经典的自然语言处理模型,可见其影响甚广。



本文由mdnice多平台发布