笔者今天上午收到了之前北大课题组老板的通知,得知研究生期间和学长合作的论文终于被siam接收,终于为自己研究生涯画上了一个句号。这里打算分享一下个人的科研过程以及这篇论文的工作,即将读研或者打算读研的同学或许可以从中获得益处。论文今天被接收,距离见刊尚有一段时间,因此这里只能提供arxiv上的论文链接添加链接描述
,有兴趣的同学可以下载看看,论文题目是AONN: An adjoint-oriented neural network method for all-at-once solutions of parametric optimal control problems。
学术论文的产出过程
研究方向和选题
科研成果的产出首先就需要选择一个合适的方向,之前本人和导师交流的时候对方给了一句非常形象的比喻:“做科研就好比搂草打兔子,导师的作用主要就是凭借自己的经验来判断那一块区域更可能打着兔子。”这个所谓的区域就可以理解为是研究方向,数学已经发展几百年了,这个学科现在是苍天大树,大部分学者能够做的就是增加一两片叶子,但即便如此仍然很难产出新的结果,如果选择的方向不对,很容易出现付出没有回报的后果。
比如说笔者之前读研的方向是深度学习求解PDE,当时导师给我提供了两个方向,另外一个偏高性能计算方向。然而当时笔者几乎没得选,因为那时候刚刚本科毕业,编程基础特别拉跨,高性能计算方向需要熟练掌握C和C++这类基础编程语言,然而我当时的情况是连python都还用不熟悉,而且大四那一年跟着另一个学长学习了小半年的深度学习求解PDE,当时觉得连这一套都还学不明白,说明我自己就不擅长编程,选高性能计算方向一定会饱受折磨。不过后来到了北大跟着老师上了一两年课,就觉得高性能计算入门其实也没那么难,不过那也是在我有一定编程基础的情况下了。之前不少粉丝通过我那个介绍深度学习求解PDE的文章私信我,想了解这个方向是否有入坑的必要,现在我还是很劝退这个方向。主要的原因有两个:第一,经过我之前研究生调研查找的情况来看,深度学习求解PDE已经发展太快了,杰出的成果早期就被人摘了桃子,后来看了许多文章都觉得在灌水,没什么意思。第二个原因就跟本人的求职经历有关了,2022年求职的时候我就发现几乎所有大厂都没有深度学习求解PDE这种对口的岗位,除非是一些企业想搞工业仿真,但那种岗位往往希望熟练掌握传统数值算法,有限元,有限体积等等,至于深度学习求解PDE这种新兴的算法。用别人的一句话来评价就是:“目前还是学术界学者的自嗨,工业上的应用还不成熟,收敛性等保证还不齐全,马斯克的火箭肯定不敢用这一套来数值仿真。”不过有一说一,深度学习求解PDE这个方向确实好上手,编程比较容易,甚至于可以这么说,计算数学的那些传统数值算法往往只有数学系的同学才更容易写出代码,但是深度学习求解PDE的原理和编程其实反而不需要那么强的数学知识和理论,很容易入门,所以之前笔者经常给本科同学推荐自己的博客,因为在我的认知里面,深度学习求解PDE这一套编程实现确实很简单了,也很适合数学系的同学学习python和pytorch。
现在聊一聊选题,上面也说过了,作者之前方向就是深度学习求解PDE,也清楚这个方向很难产出新的好的成果,一度心灰意冷。但是研一快结束的时候课题组开组会,学长PF做了一个优化控制问题的报告,当时令作者眼前一亮,这个优化控制问题的基本形式很简单,不妨参考下面这个例子:
{ min y , u J ( y , u ) = 1 2 ∥ y − y d ∥ L 2 ( Ω ) 2 + α 2 ∥ u ∥ L 2 ( Ω ) 2 , subject to { − Δ y = u , in Ω , y = 1 , on ∂ Ω , and u a ≤ u ≤ u b a.e. in Ω , \left\{\begin{aligned} &\min _{y, u} J\left(y, u\right)=\frac{1}{2}\left\|y-y_{d}\right\|_{L_{2}\left(\Omega\right)}^{2}+\frac{\alpha}{2}\left\|u\right\|_{L_{2}\left(\Omega\right)}^{2}, \\ &\text { subject to } \left\{\begin{aligned} -\Delta y &=u , \text { in } \Omega, \\ y&=1 ,\text { on }\partial \Omega,\\ \end{aligned}\right.\\ &\text{and} \quad u_a \leq u \leq u_b \quad \text { a.e. in } \Omega, \end{aligned}\right. ⎩ ⎨ ⎧y,uminJ(y,u)=21∥y−yd∥L2(Ω)2+2α∥u∥L2(Ω)2, subject to {−Δyy=u, in Ω,=1, on ∂Ω,andua≤u≤ub a.e. in Ω,
这个问题需要在满足偏微分方程的约束条件下优化两个函数 y , u y,u y,u,使得目标函数 J J J最小,当时本人觉得这个偏微分方程比较亲切,本质上也就是一个约束优化问题,看起来比较简单,所以就跟导师沟通,打算加入学长的工作,这个就是本人的选题过程了。之前读研的时候接触过很多同学,有的同学的科研题目是导师给的,有的同学的科研题目是自己看论文然后想出来的,但是不管是怎么选题,一定要多看论文,要不然很难知道自己应该走什么路线。
现有工作的调研
选好题目以后,马上要做的事情就是疯狂查阅文献,看看目前到底有哪些工作,这一点非常重要。有的同学写论文之前调研工作没有做好,等到自己论文写的差不多了,突然发现自己所谓的“创新点”原来是别人早就做过的,这时会非常崩溃,这样的案例有很多。我记得大工数学专业课的《数学分析》书上专门提到了一个混沌现象好像就是如此,一个学者提出了这样一个现象,结果发现是几十年前俄罗斯一个数学家早就发表的工作。查阅文献的方法很多,而且几乎所有的网站都要试一试,比如说最简单的百度学术,谷歌学术,arxiv,siam,science,nature等等期刊网站,都需要搜索关键词去查找论文,这样查找的论文加起来肯定也有几百篇,但是对于做科研的同学来说是不可避免的过程,而且这几百篇论文肯定都要看,不管是粗略还是细致,都要过一遍。像作者这种英语不太好的同学,当时看这些论文的时候非常痛苦,只好每次看论文直接看method,看看里面的数学公式,即便如此效率还是很低,而且当时笔者查找文献的手段受限(根本不知道怎么查找),幸好学长比我熟悉,要不然太难了。后来导师听说这种情况,还专门给作者打气说:“北大数院有一个学生据说一学期看了几百篇论文,…”这样人在北大确实存在,也是我们这种科研小白的学习对象。比如说当时本人和学长一起调研关于优化控制问题(一开始我们没也是考虑固定参数,后来发现可以直接求解含参问题,这个也算是我们工作一个创新点)的现有工作,就看见了有传统数值算法,先对问题做离散化转换为有限维向量约束优化问题求解,或者先推导出问题的KKT条件,然后离散化求解,又或者当时比较时髦的深度学习求解优化控制问题的算法,包括惩罚函数方法(也叫PINN),增广拉格朗日+NN算法(hPINN),还有深度学习求解最优性条件算法(extend PINN)算法,这些算法的介绍可以参考本人下面这篇文章添加链接描述。
调研这些现有工作除了避免自己将来重复以外,更重要的是需要了解目前算法的特点,或者说是缺点,因为这些现有算法的缺点很可能就是我们创新点的来源。比如说传统数值算法求解优化控制问题需要对问题做离散化处理,可能是有限差分离散,或者有限元离散,但是数学系的同学都知道这种离散会带来维度灾难,只能求解低维问题。这么解释维度灾难好了,如果是五点差分求解二维泊松方程(本人之前介绍过很多遍)往往在一个矩形区域打网格,网格的规模是 ,其中N表示一个维度的剖分,如果是三维方程,就需要在一个立方体打网格,网格规模就是 ,维度继续提高,这个网格规模就会迅速上升,一方面编写代码很困难,另一方面存储网格也很困难,所以我们上来就排除了传统数值算法。那么现有的深度学习算法求解优化控制问题有哪些缺点呢,比如说惩罚参数方法,这个需要把约束条件作为二次惩罚项加入目标函数得到一个无约束的目标函数,需要选择适当的惩罚系数,然后不断优化这个新的目标函数来更新参数,最终达到求解的目的。很显然这种方法如果惩罚系数选的不好,一定会出大问题,惩罚系数太小就和原始问题不等价,太大就会造成病态。而增广拉格朗日(hPINN)算法可以减缓这个趋势,这个引入了一个一次项改善这个问题,但是只能改善,不会解决,最终数值精度还是会收到这些拉格朗日系数和惩罚系数影响,而且还涉及到数值积分的离散化,数学系的同学就知道积分离散化很有讲究,高斯积分精度高,中心积分精度低,因此这个也被排除了。最后剩下深度学习求解最优性条件算法(extend PINN)算法,这个算法其实不错,还有求解含参问题的潜力,但是我们查找的那几篇论文只能求解最简单的问题,如果包含额外的不等式约束,那么这种算法就不行了,惩罚系数太多了。有了这些经验,我们下面可以考虑改进现有算法,尝试给出自己的创新点。
数值实现现有算法
不要为了创新而创新:一开始笔者看见惩罚参数算法缺点那么明显,打算直接加一个拉格朗日项(其实后来我反复比对发现就是hPINN的做法),这种做法一开始我以为创新非常明显,自己实现了几个简单案例觉得也还不错,相比于惩罚参数算法(PINN)还是提升不少,另一个学长看见也说这种算法创新点挺多了。但是后来拿去求解其他问题,发现效果就不明显了,当时还想继续改一改,后来就被指出这种算法没必要去试探了,已经看出这种算法不稳定,精度不高速度不快,就算是创新点别人没做过,那也没价值,我们做科研要保证自己的成果肯定是比现有的好才行。
当然了,目前许多论文代码根本不开源,本人也非常讨厌这种做法,尤其是之前看了不少论文,我严重怀疑他们论文的算法根本不可能有那么好的结果, 或者就是参数做了特别调整,甚至于怀疑数据造假,但是苦无源代码对比,只好忍气吞声,自己实现。像上面本人提到的那些算法,本人基本上都实现了一些数值算例,代码也全部放到了本人博客添加链接描述上。在实现这些算法的过程中,我们就能发现不同算法的特点,更容易体会这些现有算法可能的改进应该会在什么地方。由此才有了我们自己的创新点,并且通过代码验证自己的想法。
一个创新点的提出和验证
在我们做科研的时候针对一个具体的问题,往往可以有好几个不同的创新点,如果我们自己不去实现这些想法,那么很难确定下来到底那种想法是更合适的。有的人可能觉得既然一个创新点不够,那能不能一篇论文放好几个创新点。关于这个想法,我的导师有这么一句评价:“一篇论文最好就一个创新点,并且这个创新点可以起到显著效果,如果有N个创新点,每个创新点只能提供一点点助力,最后加起来可以提供一个OK的结果,这样也不行。”这里本人想到一个非常生动的比喻,就好像男生去找对象,大部分人的情况都是:相貌一般,身材一般,经济条件一般,情商一般,总之这个人从整体来看没啥问题,但是也没看出什么特别突出。但是此时要是我别的都一般,偏偏情商很高(或者钞能力强),这种时候肯定更好找对象。这就是所谓的:“虽然我的缺点像天上的星星一样多,但是我的一个优点比太阳还耀眼,太阳都出来了,谁还能看见星星呢?”对于科研成果也是如此,我们需要做的是抓住当下最严重的问题,尝试给出一种好方法来改进结果,如果我们的数值实现发现这样的算法是可行的,当然了,我们需要多做一些数值实验,看看这种想法到底适用范围有多广,那么就可以开始编写我们的论文了。
这里千万注意,也许我们的创新点经过验证以后发现对于有不少问题是不适用的,得不到理想的好效果,这个时候也没必要全盘否定,推倒重来,因为这种事情很常见,如果最后想不出什么好方法来解决,我们就在论文上指出自己算法的适用范围即可,也不失为一个有用的策略。后面本人将会提高本人的毕业论文工作就是这么处理的。
学术论文的编写和投稿
之前作者去天津旅游的时候见到了自己的本科同学当时在编写毕业论文,当时看见他使用的工具都惊呆了,对方使用的是一个ctex软件编写自己的论文,那种软件安装在自己电脑上,肯定只能自己编写论文。但是在北大里面,我除了一开始半年用ctex软件以外,后来一直都是用overleaf这种在线编辑器来编写论文的。其实这两种方式本来没什么差别,但是overleaf这种在线编辑器更加适合多人协作,因为我们要知道目前国内外大部分工作肯定都不止一个作者,往往好几个作者一起完成的,因此一个在线编辑器就能搞定多人协作这个问题,而且overleaf上面一般可以找到科研论文的模板,这里我们要指出不同期刊的模板一般是不一样的,比如说我们投递的是siam,就要用siam专门的模板,如果万一这个拒绝了,想投其他期刊,也需要找到对应期刊模板来做修改。
这里必须要指出一点,虽然科研论文作者很多,但是大部分的论文署名顺序是很重要的,第一作者往往才会被认为是主力,用一句话来概括“第一作者往往有95%的贡献”,就好像我们编写这个论文。我得承认一件事情,那就是学长PF的贡献确实比我大得多,我做的工作或许不能说是边边角角,但是确实不怎么地(所以我自己在宣传的时候也必须要说明这一点,以免引起误会)。也正是这次的科研过程,让我开始意识到我一开始绞尽脑汁想读博的想法或许是错的,连论文都写不明白的人,还卯足劲去读博,我都觉得以后博士生涯会不会很难熬,有很多人一开始保研的时候申请直博,结果搞了三四年连基本的论文都发不出来,无疑就是和作者一样的缺乏学术素养的人(基础数学博士除外,基础数学确实不太一样),像我们这种应用方向,尤其是计算机方向,科研论文是一个试金石,能看出自己是不是该转硕,是不是该硕士毕业以后去工作。当然了,如果想灌水,拿一个水博士学位,就当我没说过这话。
我的导师经常给我们强调学术规范,用他的话来说:“我不希望我的学生论文拿去投递水刊,要么别投,要么就投好的。”这一点虽然作者学术水平差,但是也深以为然,本人也非常看不惯那么多灌水论文,尤其是之前调研现有工作的时候,看了那么多灌水论文,当时就想骂人:“这种垃圾论文怎么好意思发出去。”现在我们国家讲究“破四维,破五维”,这句话不是说论文不重要,反而是强调论文的重要,尤其是质量的重要性。不管以后破什么玩意,我们都要强调质量,尤其是进入高校找教职,论文非常重要,论文质量也非常重要。当然了,相比于灌水,在学术界更让人忌讳的是学术不端,之前许多人都吐槽中国人为了避开学术不端造出了多少词汇,什么“图片误用”,“引用不规范”都来了,其实本质上就是学术道德不佳,因此在我们编写论文的时候尽量保证所有的图片都是自己画的,否则就要给出出处,要不然将来功成名就被人关注,很容易树大招风,这个时候被扒出来论文有问题,就会产生非常严重的后果。
另一个说明本人学术垃圾的证据就是:作者到现在都不太了解期刊,会议,都有哪些,什么区别。这一点我怀疑凡是大连理工大学数学出来的同学,可能大部分都和我一样,一窍不通。我来北大读研以后听室友介绍什么期刊,什么论文,什么等级的是顶会,哪些期刊论文有DDL,说实话我什么都不了解,我们这个论文投递的SIAM,也是当时导师敲定的,我自己也不知道这是什么概念,只知道是个不错的期刊。像数学界有四大,去年中国华中科技大学数学科学院的女老师huan真就因为以独立作者的身份中了四大,成为了继苏步青以后50年中国大陆的首位独立作者中四大,然后各种自媒体到处宣传,当时大家都说有这么一个论文,“杰青”肯定没跑了。然而今年前几天我听说这个事情闹了大乌龙,似乎当时只是投稿四大,八字还没一撇,然后就被到处宣传,而且当时作者明明知道这个事情,却一直没站出来澄清,现在搞得不知道怎么收场。本人对基础数学不太了解,huan老师的工作我也不熟悉,只是后来我一个中科院基础数学的博士同学跟我聊天说:“那篇论文我看了一下,是相当不错的工作”,虽然因为四大闹了乌龙,但应该也不至于被贬的一无是处,只能说这件事情给华中科技大学打了一巴掌,也给学术界再次提了醒,凡是没确定接收的消息,就不要傻了吧唧第到处宣传。就好像本人和学长PF合作的这个论文,其实arxiv上挂上去好几个月了,本人也是今天上午明确看到了邮件确定接收,才敢出来介绍宣传。一篇论文的产生是非常久的,就好像PF学长和本人合作的这个论文,2021年暑假开始研究,2022年初写了初稿,迭代了一年到2023年初才确定终稿,年初投稿以后今年三四月份被打回来修改了一次,然后一直到今天才确定接收,两年时间直接消耗了。而且这还是比较快的,像我了解的基础数学方向,许多人从博士一年级开始研究,一直到博士毕业说不定才挂上arxiv,博士后的时候能被接收就不错了。还有就是我们课题组做系统方向的学长学姐,听说那个方向没有两三年,是很难出成果的,我们硕士就三年,许多人硕士毕业,甚至于博士毕业还啥成果也没有,这个是非常正常的现象。所以才说读博需要谨慎,不是每个人都有耐心去熬的,一开始本人也以为自己能坐冷板凳,后来发现自己喜动不喜静,这也是硕士毕业决定直接找工作的原因之一。
AONN: An adjoint-oriented neural network method for all-at-once solutions of parametric optimal control problems
下面我们来介绍一下这篇论文的工作,这篇论文求解的是含参优化控制问题,注意含参两个字,下面是一个通用的数学形式:
{ min ( y ( x ) , u ( x ) ) ∈ Y × U J ( y ( x ) , u ( x ) ) , s.t. F ( y ( x ) , u ( x ) ) = 0 in Ω , and u ( x ) ∈ U a d , \left\{\begin{aligned} &\min _{(y(\mathbf{x}), u(\mathbf{x})) \in Y \times U} J(y(\mathbf{x}), u(\mathbf{x}) ),\\ &\text { s.t. } \ \mathbf{F}(y(\mathbf{x}),u(\mathbf{x})) = 0 \ \text{ in } \Omega, \text{ and } \ u(\mathbf{x})\in U_{ad}, \end{aligned}\right. ⎩ ⎨ ⎧(y(x),u(x))∈Y×UminJ(y(x),u(x)), s.t. F(y(x),u(x))=0 in Ω, and u(x)∈Uad,
其中 J J J往往就是积分形式的目标函数, F \mathbf{F} F表示一个偏微分算子,在我们论文里面出现的有椭圆偏微分算子,NS算子等等,这个 U a d U_{ad} Uad往往是一个不等式约束,比如说上面我们提到的那个例子就存在这样的不等式约束。
一般来说,学术论文需要有摘要,问题介绍,现有工作,自己工作,数值实验,以及总结,其中摘要,问题介绍,现有工作往往都是一些背景说明,自己的工作和数值实验是核心内容。但是并不意味着那些内容可以直接抄袭,哪怕是内容类似,我们也需要自己撰写文字,比如说我们这个论文的Introduction和摘要,其实大家多看看其他类似的论文,发现内容好像差不多,不过写法不一样,这是很正常的,包括我在内的许多人看论文往往直接跳过这部分,直接看核心内容,这个不失为一种快速阅读方法,下面我们重点介绍的也是这些内容。
adjoint-oriented neural network method
AONN(adjoint-oriented neural network method)是我们算法的简称,这个算法的流程是这样的:
首先需要推导出原始问题的最优性条件,这里的最优性条件也就是KKT系统如下所示:
{ J y ( y ∗ ( μ ) , u ∗ ( μ ) ; μ ) − F y ∗ ( y ∗ ( μ ) , u ∗ ( μ ) ; μ ) p ∗ ( μ ) = 0 , F ( y ∗ ( μ ) , u ∗ ( μ ) ; μ ) = 0 , ( d u J ( y ∗ ( μ ) , u ∗ ( μ ) ; μ ) , v ( μ ) − u ∗ ( μ ) ) ≥ 0 , ∀ v ( μ ) ∈ U a d ( μ ) , \left\{\begin{aligned} &J_y(y^{*}( \boldsymbol{\mu}),u^{*}( \boldsymbol{\mu}); \boldsymbol{\mu}) - \mathbf{F}^{*}_{y}(y^{*}( \boldsymbol{\mu}),u^{*}(\boldsymbol{\mu});\boldsymbol{\mu})p^{*}(\boldsymbol{\mu}) =0, \\ &\mathbf{F}(y^{*}( \boldsymbol{\mu}),u^{*}( \boldsymbol{\mu});\boldsymbol{\mu}) = 0, \\ &(\mathrm{d}_u J(y^{*}(\boldsymbol{\mu}),u^{*}(\boldsymbol{\mu});\boldsymbol{\mu}),v(\boldsymbol{\mu})-u^{*}(\boldsymbol{\mu})) \geq 0, \ \forall v(\boldsymbol{\mu}) \in U_{ad}(\boldsymbol{\mu}), \end{aligned}\right. ⎩ ⎨ ⎧Jy(y∗(μ),u∗(μ);μ)−Fy∗(y∗(μ),u∗(μ);μ)p∗(μ)=0,F(y∗(μ),u∗(μ);μ)=0,(duJ(y∗(μ),u∗(μ);μ),v(μ)−u∗(μ))≥0, ∀v(μ)∈Uad(μ),
KKT系统包含三个部分,前两个部分是等式约束,第一个叫伴随方程(adjoint equation),第二个叫状态方程(state adjoint),第三个是不等式约束,其中 这个其实就是目标函数J关于u的梯度,这个形式看起来比较复杂而已, F ∗ \mathbf{F}^{*} F∗ 称之为 的伴随算子,这个是《泛函分析》的一个概念,后面我们结合一个例子来说明一个具体问题的伴随算子怎么推导。其中那个p就是伴随函数,y是状态函数,u是控制函数。
有了这个KKT系统以后,我们开始搭建三个神经网络分别拟合y,u,p,假设网络分别是 y ^ ( x ( μ ) ; θ y ) , u ^ ( x ( μ ) ; θ u ) , p ^ ( x ( μ ) ; θ p ) \hat{y}\left(\mathbf{x}(\boldsymbol{\mu}); \boldsymbol{\theta}_{y}\right), \hat{u}\left(\mathbf{x}(\boldsymbol{\mu}); \boldsymbol{\theta}_{u}\right),\hat{p}\left(\mathbf{x}(\boldsymbol{\mu}); \boldsymbol{\theta}_{p}\right) y^(x(μ);θy),u^(x(μ);θu),p^(x(μ);θp) ,那么我们要做的就是不断更新三个神经网络的参数 θ \boldsymbol{\theta} θ来逼近最优解。注意这里出现了两个参数意思,首先是含参优化控制问题的参数指的是 μ \boldsymbol{\mu} μ,然后是近似解的神经网络参数 θ \boldsymbol{\theta} θ,不要弄混了。
然后就是更新神经网络参数的过程,假设初始化神经网络参数。
1:在计算区域采集样本点 x ( μ ) = [ x 1 , … , x d , μ 1 , … , μ D ] . \mathbf{x}(\boldsymbol{\mu})=\left[\begin{array}{llllll} x_{1}, & \ldots, & x_{d}, & \mu_{1}, & \ldots, & \mu_{D} \end{array}\right]. x(μ)=[x1,…,xd,μ1,…,μD]. 注意这个样本点包含坐标和问题参数,一定要多采集样本点,所以神经网络的输入维度自然也就是d+D了。
2:保持神经网络 u ^ ( x ( μ ) ; θ u ) \hat{u}\left(\mathbf{x}(\boldsymbol{\mu}); \boldsymbol{\theta}_{u}\right) u^(x(μ);θu)别动,借助于PINN原理优化(3.1a + 3.1b)对应的损失函数,这个其实就是求解了两个PDE,也就是使用PINN原理优化y,p来求解状态方程和伴随方程,里面涉及的函数u直接用初始化的神经网络 u ^ ( x ( μ ) ; θ u ) \hat{u}\left(\mathbf{x}(\boldsymbol{\mu}); \boldsymbol{\theta}_{u}\right) u^(x(μ);θu)代替即可。
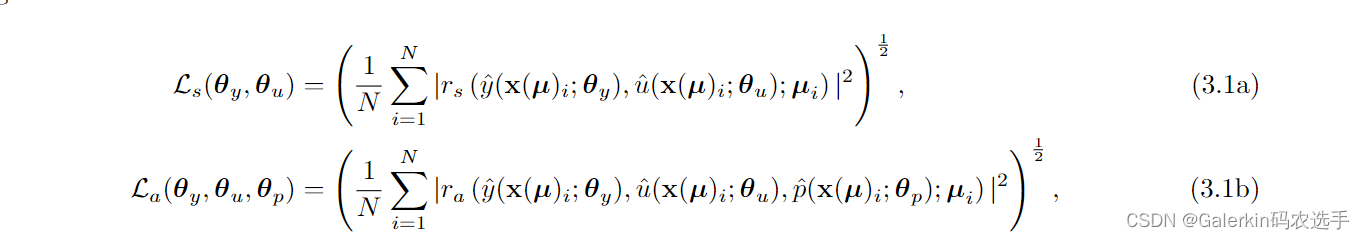
3:假设迭代一定次数了,损失函数 L s + L a L_s + L_a Ls+La被优化接近0了,那么我们利用下面这个公式来更新样本点上近似解u的取值(之前采集了样本点,我们就是通过u对应的那个神经网络通过正向传播得到这些样本点上的取值),
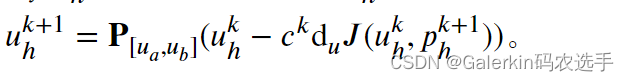
我们看这个数学形式的括号里面其实就是一个负梯度方向,也就是最速下降法,事实上这个AONN就可以理解为NN+最速下降法,但是为了保证u满足不等式约束,所以我们在外面加了一个投影算子,这个投影算子的定义如下所示:
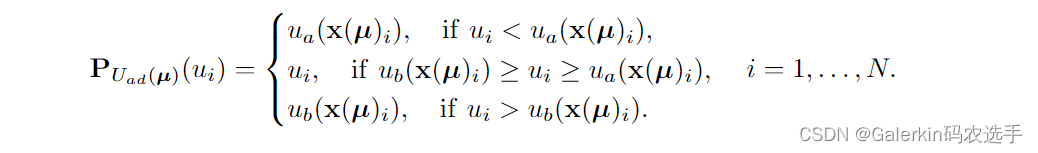
4:有了样本点上u的近似值以后,我们以 u s t e p ( μ ) u_{\mathsf{step}}(\boldsymbol{\mu}) ustep(μ)来表示样本点上的近似值,这其实就是一个向量,向量长度跟样本点数目保持一致,表示每个样本点上的近似值。
5:然后我们调用MSE优化神经网络 u ^ ( x ( μ ) ; θ u ) \hat{u}\left(\mathbf{x}(\boldsymbol{\mu}); \boldsymbol{\theta}_{u}\right) u^(x(μ);θu),这其实就是一个高斯回归过程,参考下面这个损失函数的定义。
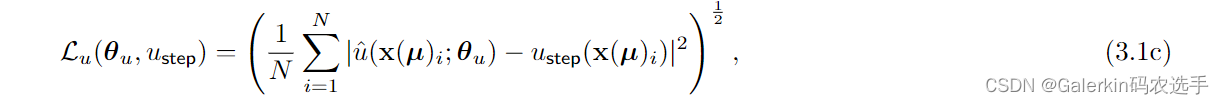
假设优化差不多了, L u L_u Lu也接近0 了,那么我们回到步骤2,其中步骤2里面的u就可以用更新完以后的神经网络 u ^ ( x ( μ ) ; θ u ) \hat{u}\left(\mathbf{x}(\boldsymbol{\mu}); \boldsymbol{\theta}_{u}\right) u^(x(μ);θu)正向传播得到。
直到循环结束,就完成了整个求解过程。
AONN算法评估
首先是AONN的优点,相比于传统数值算法而言,这里使用NN来拟合近似解,不需要网格剖分,成功避开唯独灾难(这其实是所有神经网络算法的优势)。利用NN以迭代方式求解KKT系统,相比于惩罚参数算法和增广拉格朗日算法,AONN没有惩罚项,不用担心数值结果会因此受到影响,而且也不用担心数值积分给结果带来干扰。除此以外,AONN求解的是含参问题,神经网络接收的输入包括坐标和参数,那么只需要多采集样本点,训练结束以后就可以随便给出任意一组参数的最优解。这一点非常重要,比如说上面本人给那个例子其实就可以理解为一个定参数问题,每次变化不等式约束 u a , u b u_a,u_b ua,ub 的取值,都是一个新的问题,一般的方法都要重新求解,非常麻烦。我们的AONN干脆直接把 u a , u b u_a,u_b ua,ub也当成数据喂给神经网络,这样就可以避免反复仿真。
AONN的缺点也比较明显,首先这个算法整体架构其实是最速下降法,我们都知道最速下降法不是一个好方法,收敛比较慢也就算了,最要命的这个负梯度方向的不长,也就是步骤3里面的 c k c^k ck其实非常重要,如果步长太小,收敛很慢,如果太大,就不会收敛。我们在这篇论文里面没有解决这个问题,步长调节全靠经验。我们后面展示的数值实验也都是在特殊的步长下才能获得这样的精度,换一个步长就很难保证结果了。
另一个缺点就是,原本对于固定参数问题来说,空间维度较低,比如说我们最上面那个例子空间维度就是2,但是含参问题把参数也当成输入,就提高了空间维度变成了d + D,那么样本点就变多了,数据变多了——>神经网络参数要多一些才能拟合好那么多数据——>神经网络训练时间就很长。就好像我们论文给出的那些数值实验,比如说最后那个圆形的L1问题,我记得得一两天才能训练出来,虽然这个时间对于别的工作来说不算长,但是我还是觉得很复杂,很难熬。因此这个给了我毕业设计灵感,我毕业设计就是专门解决这个问题的,后面我们会介绍这个加速。
加速求解含参优化控制问题
下面这部分内容是本人的毕业论文工作,论文放到北大图书馆里面了,暂时还没有公开,因此只打算粗略介绍一下:
首先本人仅仅考虑下面这种形式的含参优化控制问题:

也就是说,我毕业论文仅仅考虑特殊的线性椭圆问题,太复杂的PDE不考虑,因为我发现PDE太复杂,我的方法也不好使,所以必须要指定适用范围。为了简化记号,类似地我们采用上面差不多的记号: J ( y ( μ ) , u ( μ ) ; μ ) ≜ Q ( y ( μ ) , u ( μ ) ) + β ( μ ) j ( u ( μ ) ) J(y(\boldsymbol{\mu}), u(\boldsymbol{\mu}) ; \boldsymbol{\mu}) \triangleq Q(y(\boldsymbol{\mu}),u( \boldsymbol{\mu})) + \beta(\boldsymbol{\mu}) j(u( \boldsymbol{\mu})) J(y(μ),u(μ);μ)≜Q(y(μ),u(μ))+β(μ)j(u(μ)),用 G ( y ( μ ) ; μ ) = u ( μ ) G(y(\boldsymbol{\mu});\boldsymbol{\mu}) = u(\boldsymbol{\mu}) G(y(μ);μ)=u(μ)来表示约束PDE。其中目标泛函里面的 α ( μ ) > 0 , β ( μ ) ≥ 0 \alpha(\boldsymbol{\mu}) > 0,\beta(\boldsymbol{\mu}) \geq 0 α(μ)>0,β(μ)≥0 ,当目标泛函中的L1系数 β ( μ ) \beta(\boldsymbol{\mu}) β(μ)严格大于0则称之为稀疏最优控制问题,此时 − ∞ < u a ( μ ) < 0 < u b ( μ ) < + ∞ -\infty < u_a(\boldsymbol{\mu}) < 0 < u_b(\boldsymbol{\mu}) < +\infty −∞<ua(μ)<0<ub(μ)<+∞ 。Y,U都是定义在区域 Ω ( μ ) \Omega(\boldsymbol{\mu}) Ω(μ)的Banach函数空间,其中 y ∈ Y , u ∈ U y \in Y,u \in U y∈Y,u∈U 分别称为状态函数和控制函数。

含参优化控制问题的区域分解算法
区域分解策略和参数的维度有关,比如说下面展示了不同维度下的区域分解策略。
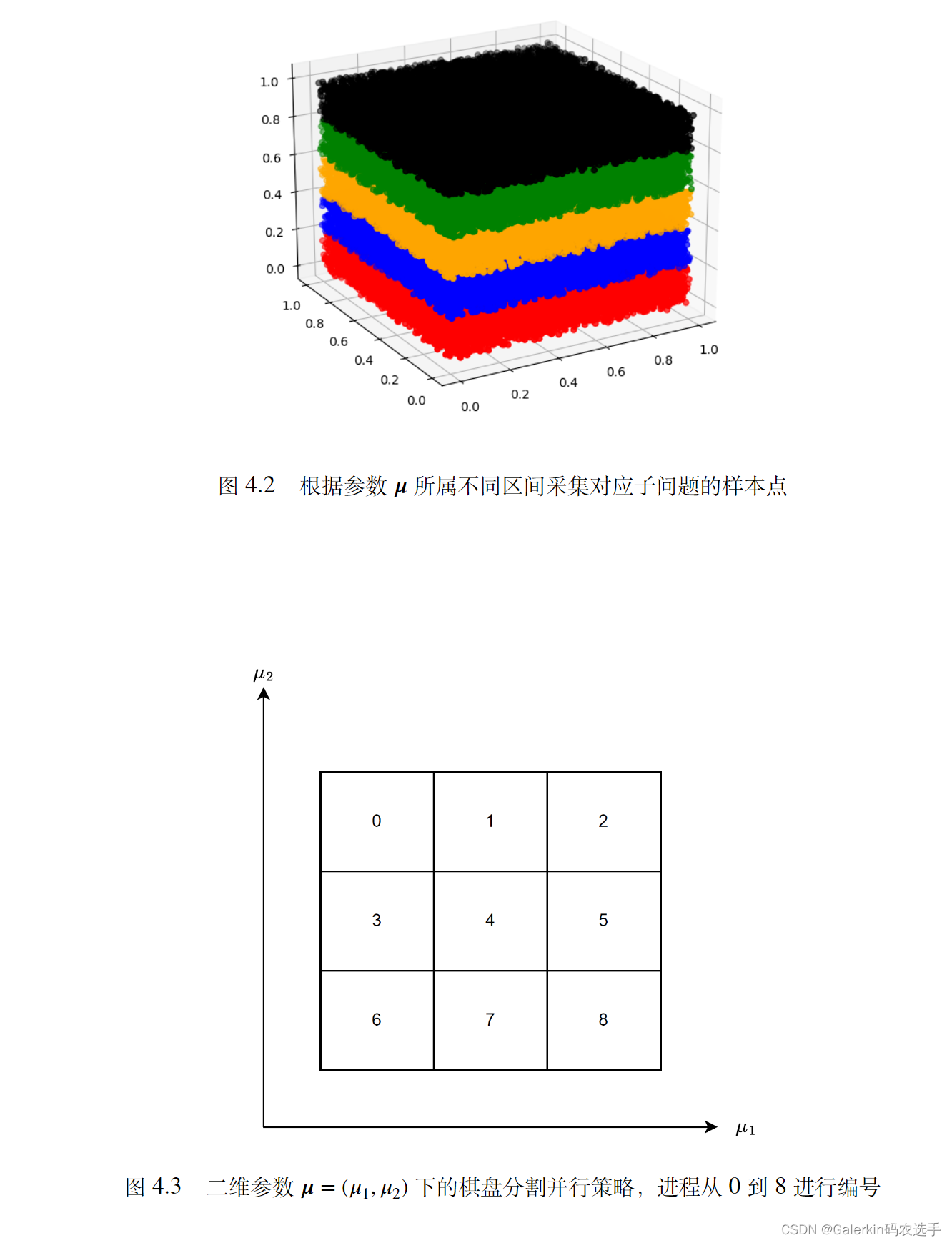
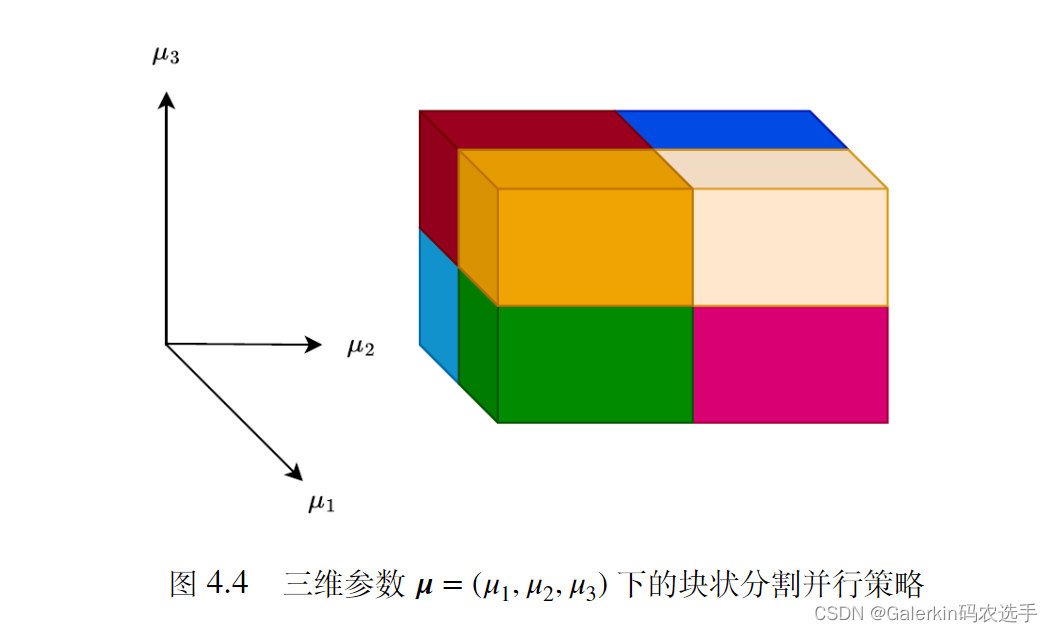
把问题做区域分解以后,就可开辟多进程来分别求解子问题,然后并行训练,得到子问题最优解以后再利用特殊的规约操作合并即可,根据我的数值实验,这种做法可以超线性加速收敛。本来8小时,加速以后20分钟就可以出结果,详细细节参考本人博客添加链接描述吧。
最后希望大家保持学术诚信,宁缺毋滥,以及享受读研过程,入职以后就会发现还是学生时代舒服。





![java八股文面试[多线程]——线程的生命周期](https://img-blog.csdnimg.cn/img_convert/1b2b2dfa02fa1ce4ec1c7972390a506f.png)