💓博主csdn个人主页:小小unicorn💓
⏩专栏分类:C++🚚代码仓库:小小unicorn的学习足迹🚚
🌹🌹🌹关注我带你学习编程知识
栈
- 栈的介绍
- 栈的概念
- 栈的结构
- 栈的实现
- 初始化栈
- 销毁栈
- 入栈
- 出栈
- 获取栈顶元素
- 检测栈是否为空
- 获取栈中有效元素个数
- 栈的作用:
- 栈的应用-------递归:
- 斐波那契数列的实现:
- 递归的定义:
栈的介绍
栈的概念
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
压栈:栈的插入操作叫做进栈 / 压栈 / 入栈。(入数据在栈顶)
出栈:栈的删除操作叫做出栈。(出数据也在栈顶)
理解栈的定义需要注意:
首先它是一个线性表,也就是说,栈元素具有线性关系,即前驱后继关系。只不过它是一种特殊的线性表而已。定义中说是在线性表的表尾进行插入和删除操作,这里表7 尾是指栈顶,而不是栈底。
它的特殊之处就在于限制了这个线性表的插入和删除位置,它始终只在栈顶进行。这也就使得:栈底是固定的,最先进栈的只能在栈底。
栈的插入操作,叫作进栈,也称压栈、入栈。类似子弹入弹夹,如左下图所示。
栈的删除操作,叫作出栈,有的也叫作弹栈。如同弹夹中的子弹出夹,如右下图所示。
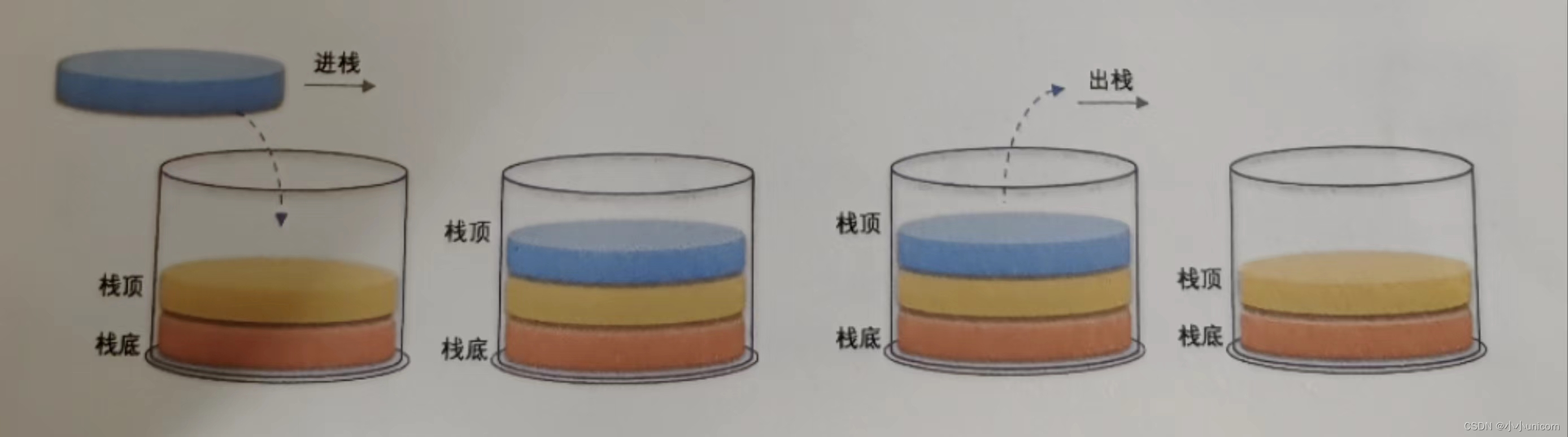
栈的结构
首先观看下面的动图,对栈概念进一步的加深理解。
栈
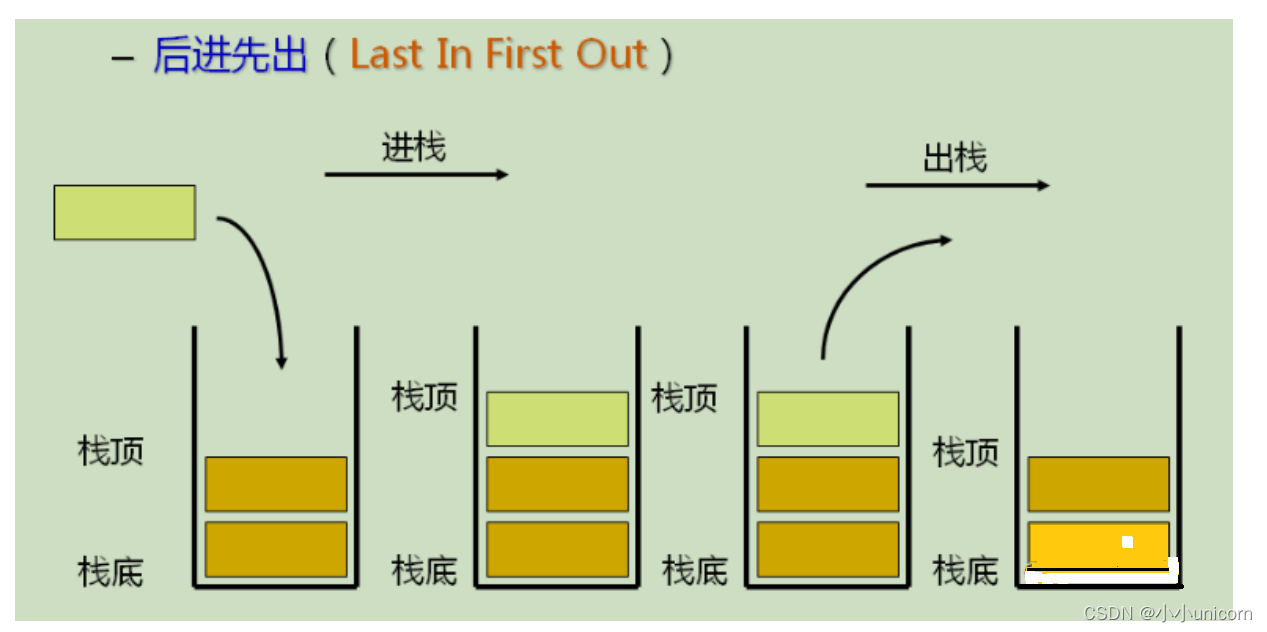
栈的实现
初始化栈
首先,我们需要用结构体创建一个栈,这个结构体需要包括栈的基本内容(栈,栈顶,栈的容量)
//栈中存储的元素类型(这里用整型举例)
typedef int STDataType;typedef struct Stack
{STDataType* a; //栈int top; //栈顶 int capacity; //容量,方便增容
}Stack;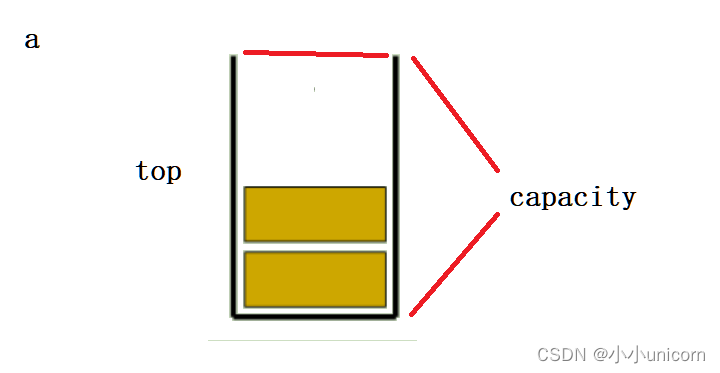
然后呢,我们需要一个初始化函数,对刚创建的栈进行初始化。
//初始化栈
void StackInit(Stack* pst)
{assert(pst);pst->a = (STDataType*)malloc(sizeof(STDataType)* 4); //初始化栈可存储4个元素pst->top = 0; //初始时栈中无元素,栈顶为0pst->capacity = 4; //容量为4
}}销毁栈
前面栈的空间是我们自己动态开辟出来的,当我们使用完后必须释放其内存空间,防止内存泄漏。
//销毁栈
void StackDestroy(Stack* pst)
{assert(pst);free(pst->a); //释放栈pst->a = NULL; //及时置空pst->top = 0; //栈顶置0pst->capacity = 0; //容量置0
}入栈
进行入栈操作前,我们首先需要检测栈的当前状态,若已满,则需要先对其进行增容,然后才能进行入栈操作。
//入栈
void StackPush(Stack* pst, STDataType x)
{assert(pst);if (pst->top == pst->capacity) //栈已满,需扩容{STDataType* tmp = (STDataType*)realloc(pst->a, sizeof(STDataType)*pst->capacity * 2);if (tmp == NULL){printf("realloc fail\n");exit(-1);}pst->a = tmp;pst->capacity *= 2; //栈容量扩大为原来的两倍}pst->a[pst->top] = x; //栈顶位置存放元素xpst->top++; //栈顶上移
}出栈
出栈操作比较简单,即让栈顶的位置向下移动一位即可。但需检测栈是否为空,若为空,则不能进行出栈操作。
//出栈
void StackPop(Stack* pst)
{assert(pst);assert(!StackEmpty(pst)); //检测栈是否为空pst->top--; //栈顶下移
}获取栈顶元素
获取栈顶元素,即获取栈的最上方的元素。若栈为空,则不能获取。
//获取栈顶元素
STDataType StackTop(Stack* pst)
{assert(pst);assert(!StackEmpty(pst)); //检测栈是否为空return pst->a[pst->top - 1]; //返回栈顶元素
}检测栈是否为空
检测栈是否为空,即判断栈顶的位置是否是0即可。若栈顶是0,则栈为空。
//检测栈是否为空
bool StackEmpty(Stack* pst)
{assert(pst);return pst->top == 0;
}获取栈中有效元素个数
因为top记录的是栈顶,使用top的值便代表栈中有效元素的个数。
//获取栈中有效元素个数
int StackSize(Stack* pst)
{assert(pst);return pst->top; //top的值便是栈中有效元素的个数
}栈的作用:
有人可能就产生疑问了,用数组或者链表直接实现功能不就行了吗?干嘛还要引入栈这样的数据结构呢?
回答这个问题,就好比:其实这和我们明明可以有两只脚走路,干嘛还要乘坐汽车,火车,飞机性质一样。理论上,陆地上的任何地方,我们都是可以靠双脚走到的,可那需要耗费的时间和精力可想而知。我们更关注的是到达而不是如何去的过程。
栈的引入可以简化程序设计的问题,划分了不同关注层次,使得思考范围缩小,更利于解决问题核心。
栈的应用-------递归:
栈有一个很重要的应用:在程序设计语言中实现了递归。那么什么是递归呢?
当你往镜子前面一站,镜子里面就有一个你的像。但你试过两面镜子对着一起照吗?如果A、B两面镜子相互面对面放着,你往中间一站,嘿,两面镜子里都有你的千百个“化身”。为什么会有这么奇妙的现象呢?原来,A镜子里有B镜子的像,B镜子里也有A镜子的像,这样反反复复,就会产生一连串的“像中像”。这是一种递归现象,如下图所示。

我们先来看一个经典的递归例子:斐波那契数列(Fibonacci)。为了说明这个数列,这位斐老还举了一个很形象的例子。
斐波那契数列的实现:
斐老说如果兔子在出生两个月后,就有繁殖能力,一对兔子每个月能生出一对小兔子来。假设所有兔子都不死,那么一年以后可以繁殖多少对兔子呢?
我们拿新出生的一对小兔子分析一下:第一个月小兔子没有繁殖能力,所以还是一对;两个月后,生下一对小兔子共有两对;三个月以后,老兔子又生下一对,因为小兔子还没有繁殖能力,所以一共是三对……以此类推可以列出下表。

表中数字1,1,2,3,5,8,13,…构成了一个序列。这个是咧有个十分明显的特点,那就是:前面向量两项之和,构成了后一项。如下图所示:
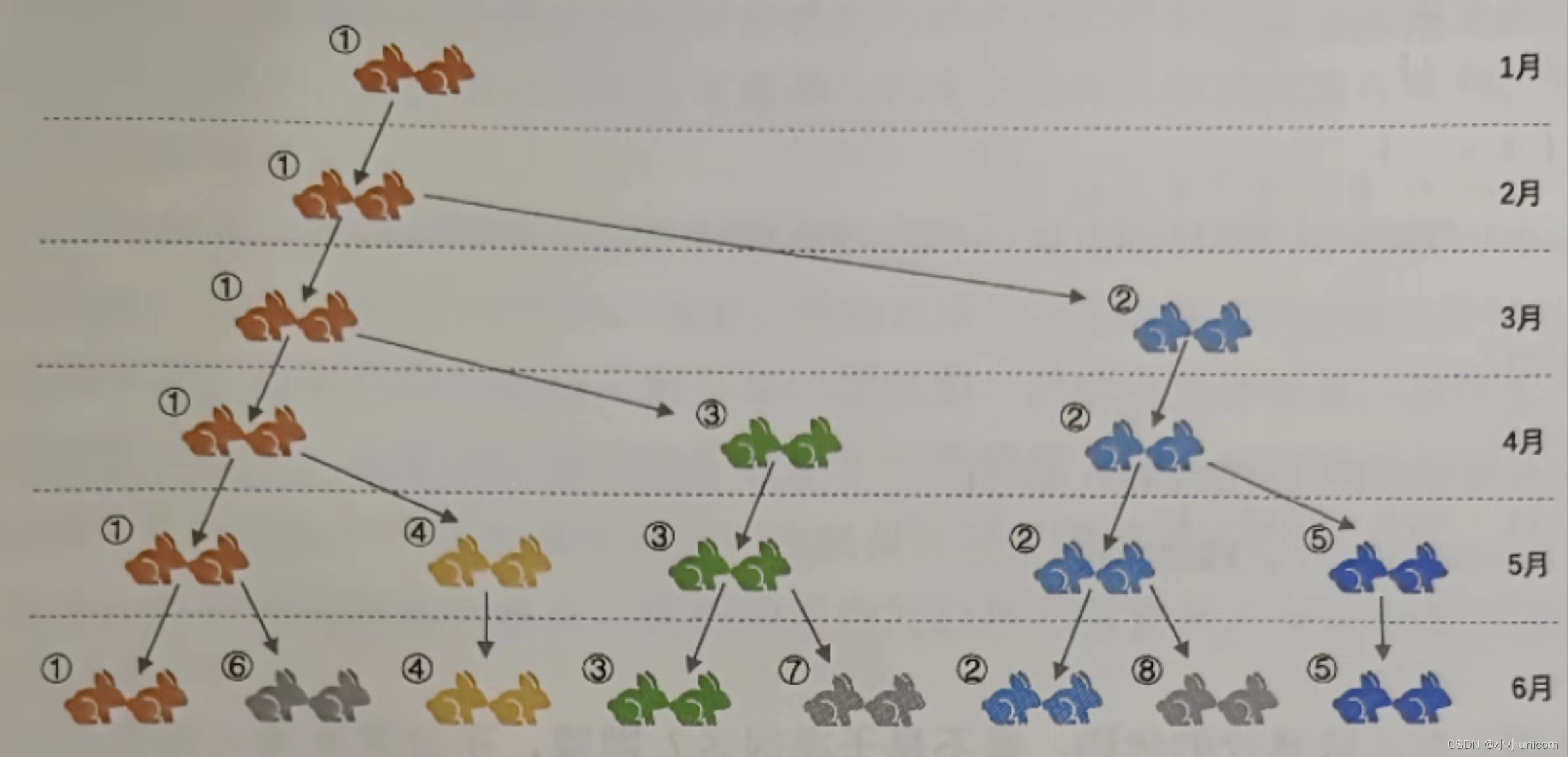
会发现,编号1的一对兔子经过6个月就变成8对兔子了,如果用数学函数公式来定义的话,那就是:
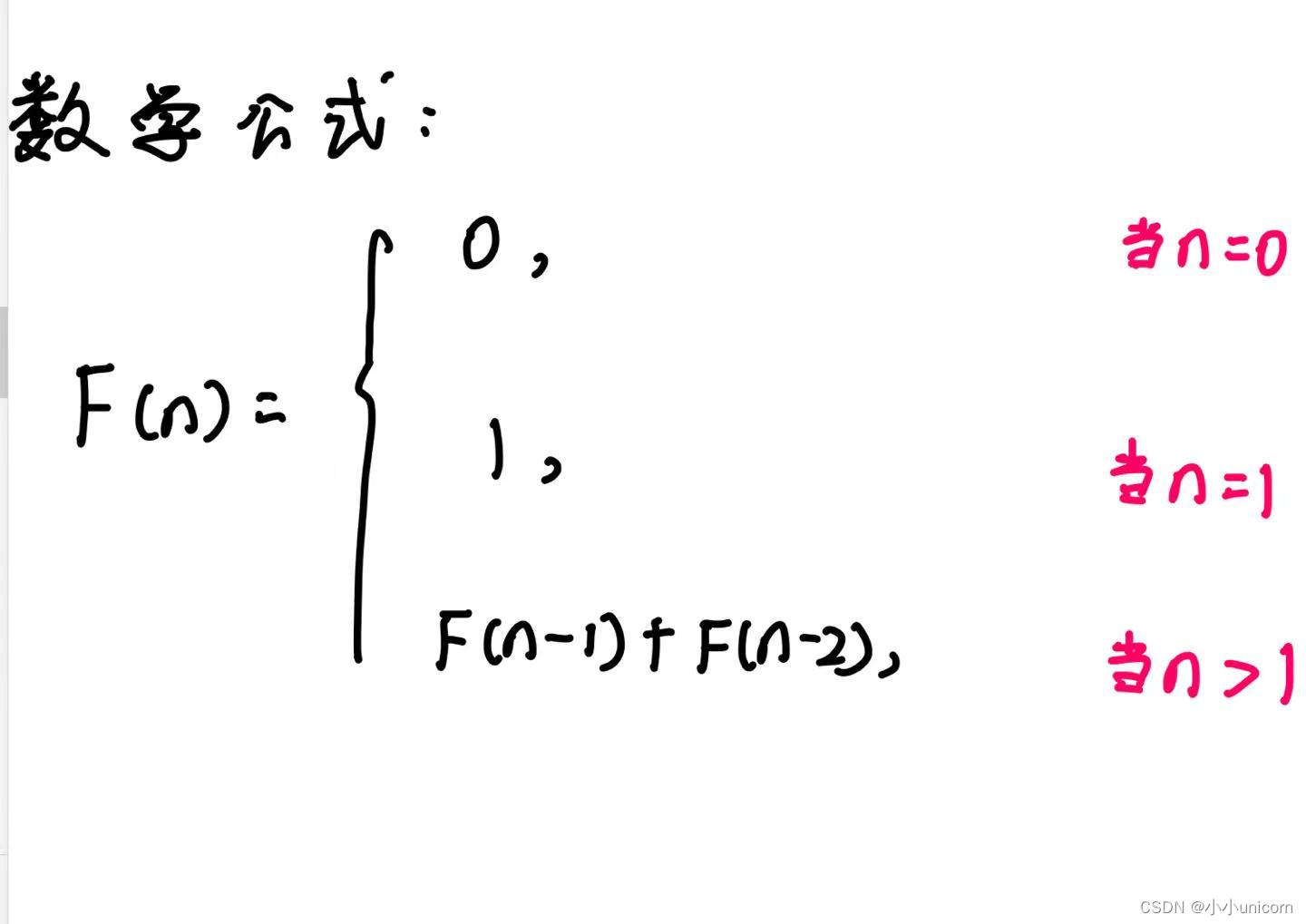
思考一下,如果我们要实现这样的数列用常规迭代方法如何操作。以前40位的斐波那契数列为例。
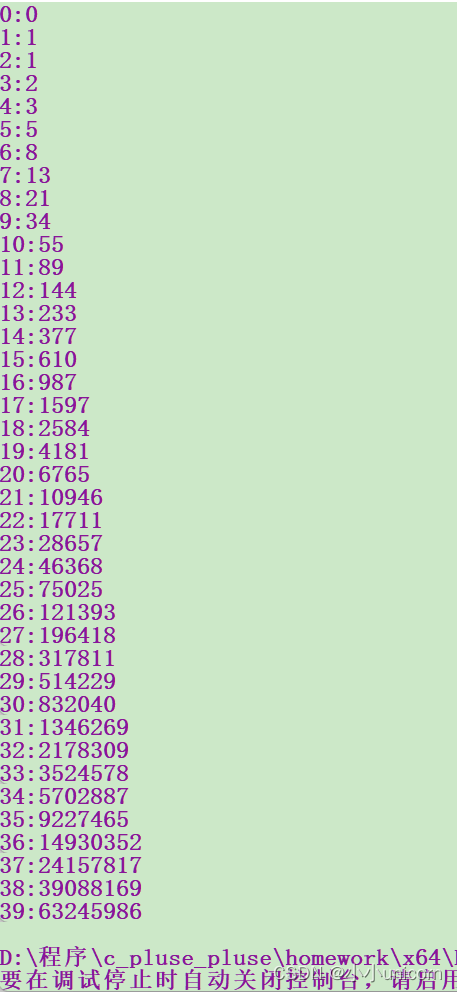
//前40位
int main()
{int i;int a[40] = { 0 };a[0] = 0;a[1] = 1;printf("0:%d\n", a[0]);printf("1:%d\n", a[1]);for (i = 2; i < 40; i++){a[i] = a[i - 1] + a[i - 2];printf("%d:%d\n", i,a[i]);}return 0;
}
看看结果:
用递归实现的话:
//斐波那契递归实现:
int Fbi(int i)
{if (i < 2){return i == 0 ? 0 : 1;}return Fbi(i - 1) + Fbi(i - 2);
}int main()
{int i;printf("递归显示斐波那契数列:\n");for (i = 0; i < 40; i++){printf("%d:%d\n",i, Fbi(i));}return 0;
}
看下结果:

通过比较发现,明显递归版的代码干净很多。这就是递归,估计有人难以理解,函数怎么可以自己调用自己?我们可以换种思路,它调用函数时调用的函数跟它本身一样。
我们可以模拟一下Fbi(5)具体是怎么实现的。
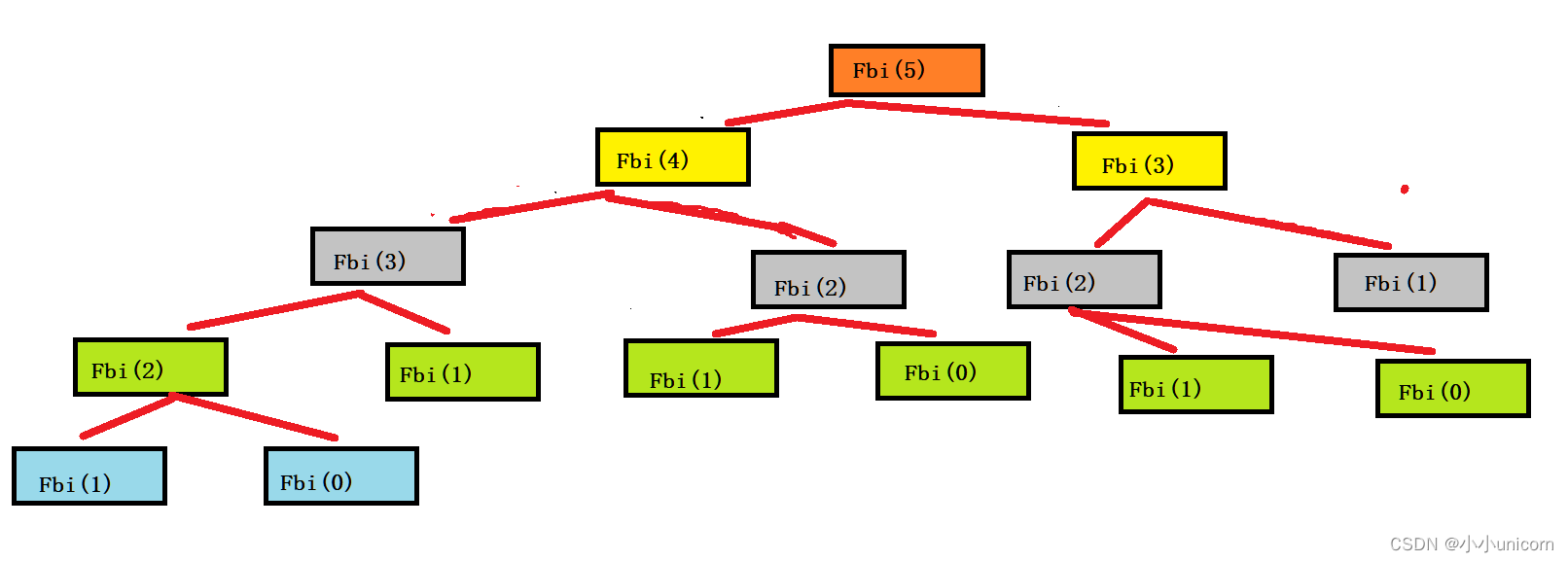
递归的定义:
在高级语言中,调用自己和其他函数并没有本质的不同。我们把一个直接调用自己或通过一系列的调用语句间接地调用自己的函数,称做递归函数。
当然,写递归程序最怕的就是陷入永不结束的无穷递归中,所以,每个递归定义必须至少有一个条件,满足时递归不再进行,即不再引用自身而是返回值退出。
比如刚才的例子,总有一次递归会使得i<2的,这样就可以执行return i的语句而不用继续递归了。
对比了两种实现斐波那契的代码。迭代和递归的区别是:迭代使用的是循环结构,递归使用的是选择结构递归能使程序的结构更清晰、更简洁、更容易让人理解,从而减少读懂代码的时间。但是大量的递归调用会建立函数的副本,会耗费大量的时间和内存。迭代则不需要反复调用函数和占用额外的内存。因此我们应该视不同情况选择不同的代码实现方式。
那么我们讲了这么多递归的内容,和栈有什么关系呢?这得从计算机系统的内部说起。
前面我们已经看到递归是如何执行它的前行和退回阶段的。递归过程退回的顺序是它前行顺序的逆序。在退回过程中,可能要执行某些动作,包括恢复在前行过程中存储起来的某些数据。
这种存储某些数据,并在后面又以存储的逆序恢复这些数据,以提供之后使用的需求,显然很符合栈这样的数据结构,因此,编译器使用栈实现递归就没什么惊奇的了。
简单地说,就是在前行阶段,对于每一层递归,函数的局部变量、参数值以及返回地址都被压入栈中。在退回阶段,位于栈顶的局部变量、参数值和返回地址被弹出,用于返回调用层次中执行代码的其余部分,也就是恢复了调用的状态。
当然,对于现在的高级语言,这样的递归问题是不需要用户来管理这个栈的,一切都由系统代劳了。
文章到这里就要告一段落了,有更好的思路或问题的,欢迎留言评论区。
下棋预告:初阶数据结构(六) 队列的介绍与实现





![java八股文面试[多线程]——线程的生命周期](https://img-blog.csdnimg.cn/img_convert/1b2b2dfa02fa1ce4ec1c7972390a506f.png)