ES是什么
ES是一个天生支持分布式的搜索、聚合分析的存储引擎
基于Java开发 基于Lucene的开源分布式搜索引擎
ELK : elasticSearch Logstah Kibana
加入 Beats 后
ELK 改为 :Elastic stack
ES解决了什么问题
ES解决的核心问题 : 1.海量数据 2.全文检索
ES不擅长的场景 : 管理数据、事务场景、大单页查询、数据实时写入更新

ES生产模式和开发模式
生产环境 :用于生产环境的运行模式,生产模式下要考虑高可用、故障转移、性能优化等安全因素 ,要求比较高
开发环境 :用于测试的运行环境、相对要求比较低
引导检查 :
单节点发现 :会将自己设置为主节点,不允许其他节点加入,会放弃一些检查
ES存储和索引
ES是面向文档存储的,索引 :相同类型的文档的集合
文档(document) :每条数据是一个文档
词条(term) : 文档按照语义分成词条
ES和MYSQL 对比

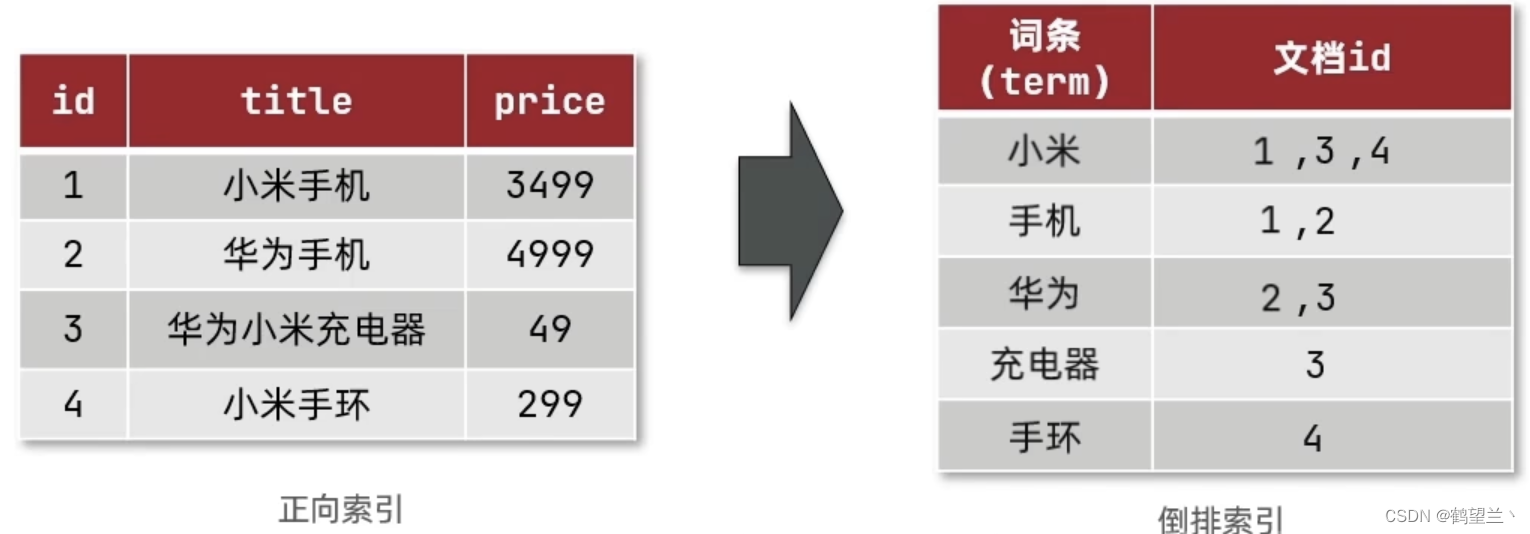
倒排索引
Mysql : 采用 正向索引 like 等内容检索 操作 会 逐行 扫描
Es采用倒排索引
查询过程 :
1 分词
2 根据词条去列表查询文档id
3 根据文档id查询文档
4 存入结果集
ES数据同步
ES 中的数据 来自于Mysql ,因为当mysql发生改变时,会涉及到数据同步问题
常见模型 : 读写分离 ,ES负责搜索和查询 ,Mysql只负责 数据写入和更新
1.同步双写数据同步
效率较低 ,业务耦合,不推荐
2.异步双写
使用 消息队列(mq)来异步实现数据同步,缺点:依赖mq的可靠性
3.监听binlog
使用中间件来监听 mysql 的binlog (如:canal)来完成数同步
可完全解除服务间耦合 。需要开启binlog
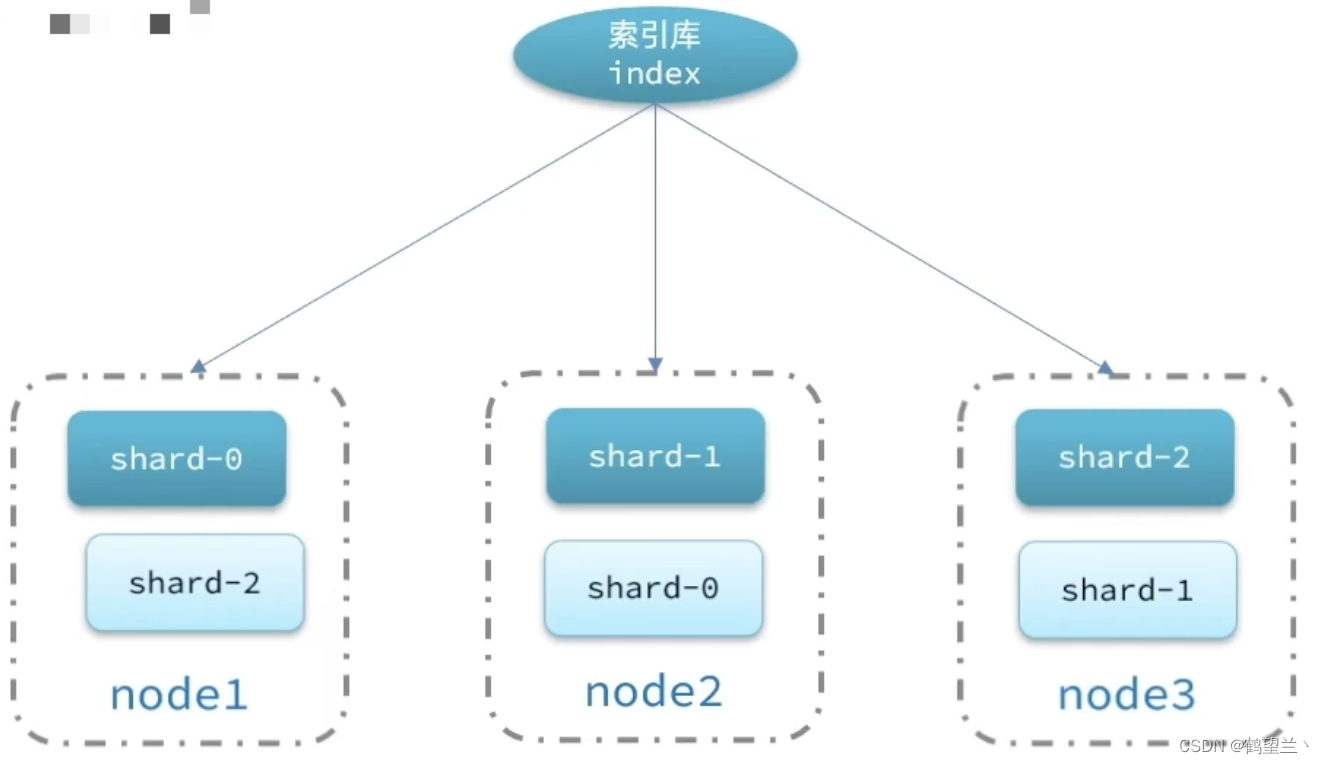
ES集群
海量数据存储问题 :将索引库 从逻辑上拆分为多个分片(shard),存储到多个节点
单点故障问题:将分片数据再不同节点备份
节点角色

脑裂问题
默认情况 :每个节点都是 master eligible (备选主节点)一旦 msater 宕机 ,当值 master 和某些节点连接不上
其他节点会选举一 个新的主节点 ,网络恢复会出现两个master节点 。 称为 :脑裂问题
ES处理: 选票超过 eligible节点数+1 / 2 ,才能当主, eligible 数量配置为 奇数
配置:discovery.zen.minimum_master_nodes es7.0之后,默认开启此配置
ES分布式存储
新增文档时:通过hash 算法来计算 文档应该存储到那个分片
对文档ID 进行哈希 ,对分片数量取余
索引库一旦创建,分片数量不能修改
ES分布式查询
Es查询分为两个阶段 :
- Scatter phase 分散阶段 ,协调节点把请求分发到每个分片
- Gather phase 聚集阶段 , 协调节点将 查询结果汇总 请返回给用户
故障转移
主节点故障 : eligible master 重新选举为主节点
数据节点故障 :主节点监控分片 :, 将故障节点的分片 转移到 其他健康的节点
索引库操作
ES的操作语法 称为 DSL :类似于sql
mapping映射属性
Mapping是对索引库中 文档的约束 ,常见的 mapping属性包括 :
Type :字符 类型 :字符串text(可分词)、keyword(不可分割)
数值 :long、int、short、byte、double float
布尔 :boolean
日期 :date
对象 :object
Index :是否创建 索引 默认 true
analyzer:使用哪种分词器
properties :该字段的子字段
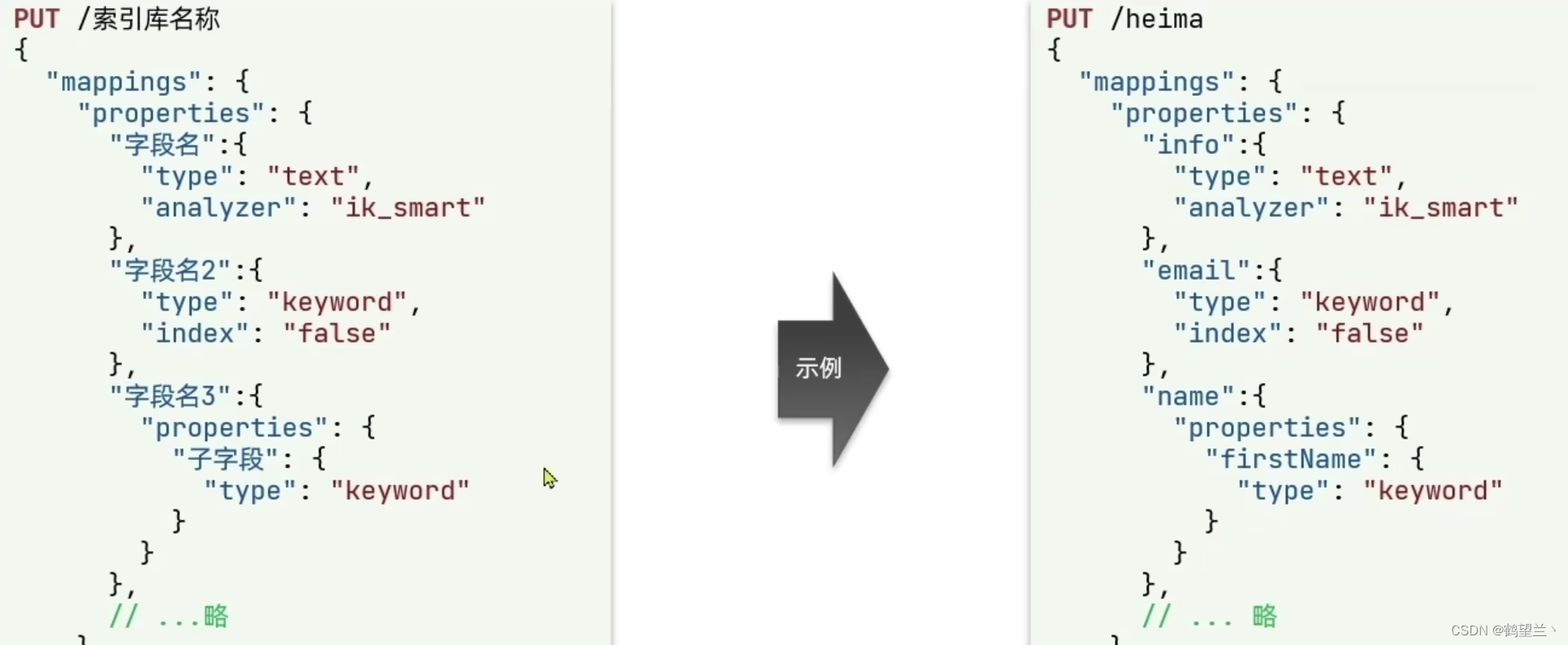
创建索引库
ES 创建索引库和mapping的 DSL语法如下
查询、删除索引库
查看 : GET /索引库名称
删除: DELETE/索引库名称
修改索引库 :索引库和mapping禁止修改,因为修改会影响到 倒排索引和分词
但是可以 添加新的字段:
Put /索引库名称/_mapping
{
Xxx
}
文档操作
文档类似于 mysql中的 行
新增文档
post操作

查看、删除 文档
GET /索引库名/_doc/文档id
DELETE/索引库名/_doc/文档id
修改文档
**1.全量修改 :**删除旧文档,添加新文档
blog.csdnimg.cn/0d9a8da616aa4321918da2be370b4e8e.png)

2.局部修改。修改指定得字段值

DLS查询语法
查询类型 :
查询所有 :例 :match_all
全文检索 :利用分词器,去倒排索引查询匹配 例: match_query multi_match_query
精确查询 :根据keyword等完整词条查询,不需要查询分词内容 例: ids range term
地理查询 : geo_distanch geo_bounding_box
符合查询 :将以上方式组合使用 并且可以使用 与或非
DSL Query 基本语法

全文检索查询
利用分词器,去倒排索引查询匹配 例: match_query multi_match_query
常用于:搜索框
Match查询 :根据 关键字 分词,去倒排索引库中检索

multi_match :可以同时查询多个字段

精确查询
精确查询一般用于查找 keyword 数值、日期、bool 等 不可分词字段 、
Term 查询 :根据词条精确值 查询
Range 查询 :根据值的范围查询 gt 大于 gte大于等于 lt 小于 lte 小于等于

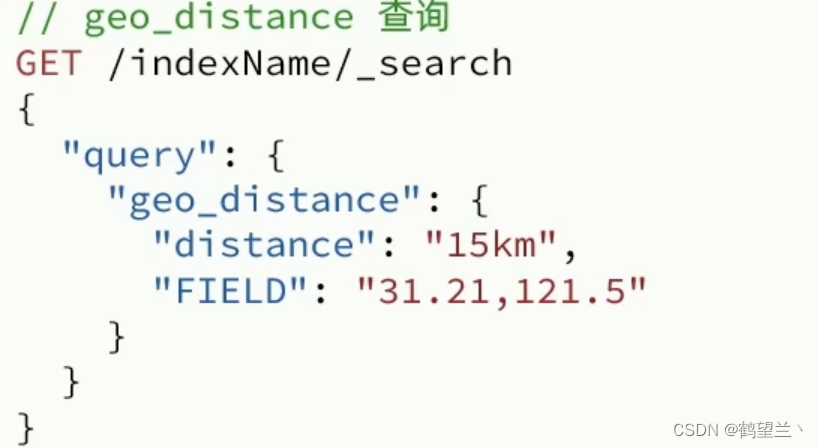
地理查询
根据经纬度查询
geo_bounding_box :查询 geo_point值落在某个矩形范围的所有文档
查询 Top_left 和bottom_right之间 的文档

geo_distance :查询到指定点为中心 距离小于某个值(distance)的所有文档
复合查询
在将其他简单查询结合起来,实现更复杂的搜索逻辑
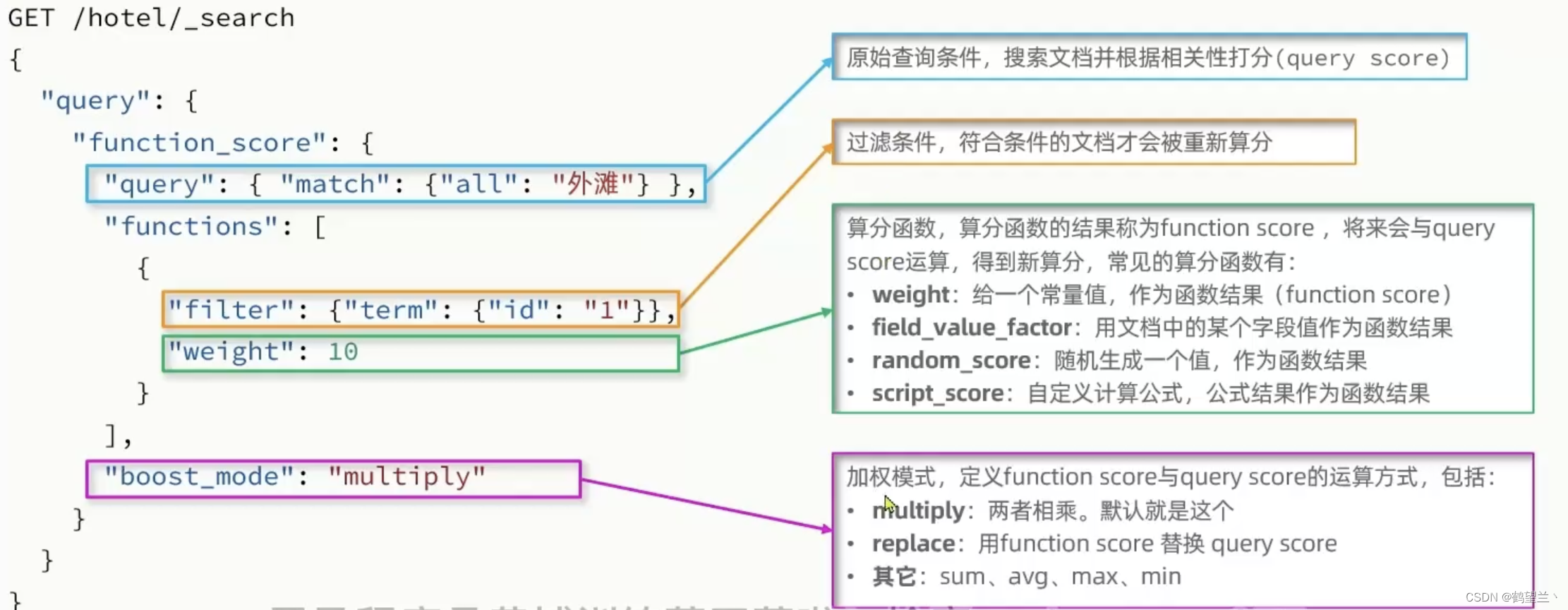
Function score :算法函数查询,可以控制 文档 相关性算分 ,控制 文档排名
相关性算分 :搜索结果 与搜索词条关联打分(_score)
TF-IDF算法 : 频率 * 权重

BM25算法 : es 5.0之后
相比较 TF—IDF 得分 会更加平滑
Function score Query : 可以修改相关性算分 。根据新得到的算法排序
Boolean Query (与或非)
布尔查询是一个活多个查询子句的组合。 子查询组合方式有 :
must:必须匹配每个子查询,类似“与”
should:选择性匹配子查询,类似“或〞
must_not:必须不匹配,不参与算分,类似“非”
filter:必须匹配,不参与算分
搜索结果处理(排序、分页、高亮)
排序
对搜索结果进行排序 ,默认按照(_socre)来排序 可以排序的子字段有 :keyword 、数值、GEO、日期 等

分页
ES默认只返回TOP10的数据 。需要查询更多数据则需要修改分页参数
ES 通过 from size 来控制 分页

ES 由于 是倒排索引 所以分页需要查询出 前面所有的数据 比如 from 990 siez 10 则要 查出 1000 条数据 再截取 10条
问题 :ES是分布式的,会导致深度分页问题 ,找每个分片 的 前 1000数据 ,再合并 找出 前1000 。会对性能有很大影响
ES设定的 结果集上限是10000
深度分页解决方案
Search after : 分页时需要排序。从上一次排序位置开始查询下一页,缺点:只能向后翻页 。 官方推荐
Scroll :将排序数据形成快照 。保存在 内存 。 缺点 :耗内存,并且数据可能不是最新
高亮
将搜索结果中的关键字突出显式
原理 :
将关键字有标签标记出来 ,再页面中给标签添加css样式
highlight 高亮:

数据聚合
聚合可惜实现对文档数据的统计、分析、运算。 聚合常见有三类
桶聚合(bucket):用来对文档分组
TermAddregation:按文档字段值分组
Date histogram: 按日期阶梯分组
Size : 聚合结果数量
Order :结果排序方式
Field:指定聚合字段
Query可以先定聚合的范围(查询条件)

度量聚合(Metric):用来计算数值:最大值、最小值、平均值等
在brandAgg 内部使用 aggs 即可使用度量聚合

管道聚合(pipeline)
以其他聚合的结果再做聚合
自动补全
自定义分词器
elasticsearch中分词器 (analvzer)的组成包含三部分:
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
**tokenizer:**将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik smart
**tokenizer filter:**將tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
我们在创建索引库时,通过settings来配置自定义的 analyzer(分词器)

如何使用拼音分词器?
- 下载pinyin分词器
- 解压并放到elasticsearch的plugin目录
- 重启即可
如何自定义分词器?
创建索引库时,在settings中配置,可以包含三部分
character filter.
tokenizer
Afilter
completion suggester 自动补全
completion suggester 查询 实现了自动补全功能
此查询会匹配用户输入开头词条并返回
参与查询的字段 必须是:completion类型
字段内容一般是用来补全的多个词条形成的数组