一、说明
NLTK是一个复杂的库。自 2009 年以来不断发展,它支持所有经典的 NLP 任务,从标记化、词干提取、词性标记,包括语义索引和依赖关系解析。它还具有一组丰富的附加功能,例如内置语料库,NLP任务的不同模型以及与SciKit Learn和其他Python库的集成。
本文是对NLTK的简要介绍。您将看到NLTK的实际操作,可用于各种NLP任务的简短代码片段。
这篇文章最初出现在我的博客 admantium.com。
本文的技术上下文是 和 。所有示例也应该适用于较新的版本。Python v3.11NLTK v3.8.1
二、NLTK 库安装
NLTK可以通过Python pip安装:
python3 -m pip install nltk 一些NLTK功能需要使用其他数据,例如停用词或集成语料库。为此,使用内置下载器。下面是一个示例:
import nltknltk.download('stopwords')
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('reuters')其他部分,如专用分词器或停用词,需要安装 Java 库。请参阅此 Github Gist 以开始使用。
三、自然语言处理任务
NLTK支持多个NLP任务。下面是一个简短的概述,接下来的部分将提供更多详细信息:
文本处理
- 标记化
- 堵塞
- 词形还原
文本语法
- 词性标记
文本语义
- 命名实体识别
文档语义
- 聚类
- 分类
此外,NLTK 还支持以下附加功能:
- 数据
- 语料库管理
- 机器学习聚类和分类模型
四、文本处理
4.1 标记化
标记化是文本处理中必不可少的第一步。通常,应根据项目要求和后续NLP任务来选择标记化方法。例如,当文本包含表示实体或人的多名词,但分词器只是按空格拆分时,命名实体识别变得困难。
NLTK提供了一个简单的空格标记器,几个内置的标记器,如NIST或Stanford,以及基于正则表达式的自定义标记器选项。
下面是内置句子和单词分词器的示例:
from nltk.tokenize import sent_tokenize, word_tokenize# Source: Wikipedia, Artificial Intelligence, https://en.wikipedia.org/wiki/Artificial_intelligence
paragraph = '''Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding. AI research has tried and discarded many different approaches, including simulating the brain, modeling human problem solving, formal logic, large databases of knowledge, and imitating animal behavior. In the first decades of the 21st century, highly mathematical and statistical machine learning has dominated the field, and this technique has proved highly successful, helping to solve many challenging problems throughout industry and academia.'''
sentences = []for sent in sent_tokenize(paragraph):sentences.append(word_tokenize(sent))sentences[0]
# ['Artificial', 'intelligence', 'was', 'founded', 'as', 'an', 'academic', 'discipline'4.2 词干提取和词形还原
与标记化一样,选择合适的词干提取(将屈折词替换为词干,如用厨师烹饪)和词形还原(用词干替换词组)方法取决于后续的 NLP 任务。词形还原具有特殊作用,因为它需要一些词性标记或词义消歧来正确识别单词组。
NLTK提供了几个词干模块,如Porter,Lancaster和Isri。对于词形还原,仅提供 Wordnet。
让我们比较一下维基百科文章中关于人工智能的第一句话的词干和词形还原。
from nltk.stem import LancasterStemmersent = 'Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding.'
stemmer = LancasterStemmer()
stemmed_sent = [stemmer.stem(word) for word in word_tokenize(sent)]print(stemmed_sent)
# ['art', 'intellig', 'was', 'found', 'as', 'an', 'academ', 'disciplin',用WordNet词形还原器处理的同一个句子:
from nltk.stem import WordNetLemmatizersent = 'Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding.'
lemmatizer = WordNetLemmatizer()
lemmas = [lemmatizer.lemmatize(word) for word in word_tokenize(sent)]print(lemmas)
# ['Artificial', 'intelligence', 'wa', 'founded', 'a', 'an', 'academic', 'discipline'五、文本语法
词性标记
NLTK还提供不同的词性标记器(pos)。使用内置标记器,将生成以下注释:
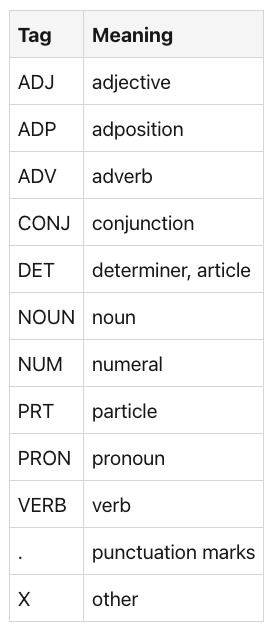
标签含义 ADJ 形容词 ADP 附加置词 ADV 副词 CONJ 连词 DET 决定符,文章名词名词 NUM 数字 PRT 助词 PRON 代词 动词 动词 .标点符号 X 其他
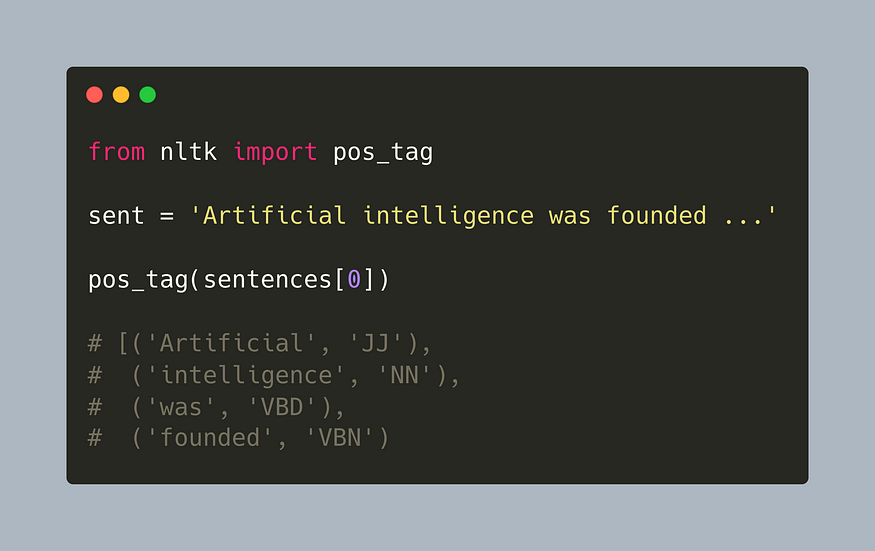
取维基百科关于人工智能的文章的第一句话,词性标记产生以下结果。
from nltk import pos_tagsent = 'Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding.'
pos_tag(sentences[0])
# [('Artificial', 'JJ'),
# ('intelligence', 'NN'),
# ('was', 'VBD'),
# ('founded', 'VBN'),
# ('as', 'IN'),
# ('an', 'DT'),
# ('academic', 'JJ'),
# ('discipline', 'NN'),要使用其他NLTK pos标记器,例如Stanford或Brill,需要下载外部Java库。
六、文本语义
命名实体识别
NLTK包括预先训练的NER标记器,但需要先下载几个额外的包。
import nltk nltk.download('maxent_ne_chunker')nltk.download('punkt')nltk.download('averaged_perceptron_tagger')nltk.download
('words')NER 标记器使用 POS 标记的句子,并将分类标签添加到表示形式中。在示例段落上使用它不会产生任何结果,因此以下示例从维基百科文章中引用了另一个句子,其中提到了人物。
from nltk.tokenize import sent_tokenize# Source: Wikipedia, Artificial Intelligence, https://en.wikipedia.org/wiki/Artificial_intelligence
sentence= '''
In 2011, in a Jeopardy! quiz show exhibition match, IBM's question answering system, Watson, defeated the two greatest Jeopardy! champions, Brad Rutter and Ken Jennings, by a significant margin.
'''tagged_sentence = nltk.pos_tag(word_tokenize(sentence))
tagged_sentence
# [('In', 'IN'),
# ('2011', 'CD'),
# (',', ','),
# ('in', 'IN'),
# ('a', 'DT'),
# ('Jeopardy', 'NN'),print(nltk.ne_chunk(tagged_sentence))
# (S
# In/IN
# 2011/CD
# ,/,
# in/IN
# a/DT
# Jeopardy/NN
# !/.
# quiz/NN
# show/NN
# exhibition/NN
# match/NN
# ,/,
# (ORGANIZATION IBM/NNP)
# 's/POS
# question/NN
# answering/NN
# system/NN
# ,/,
# (PERSON Watson/NNP)如您所见,个人和组织得到了认可。WatsonIBM
七、文档语义
7.1 聚类
支持三种聚类分析算法,请参阅完整文档。
- K 均值
- 电磁集群
- 组平均集聚聚类器 (GAAC)
7.2 分类
以下分类器在 NLTK 中实现,另请参阅完整文档。
- 决策树
- 最大熵建模
- 兆米最大优化
- 朴素贝叶斯(及其变体)
支持外部包,如用于语言识别的TextCat,Java库Weka或SciKitLearn分类器。
八、附加功能
8.1 数据
NLTK提供了100多个内置语料库,请参阅完整列表。一些例子:路透社新闻文章,Treebank 2华尔街日报校园,Twitter新闻或WordNet词汇数据库。
以下是如何访问路透社语料库的示例。
from nltk.corpus import reutersprint(reuters.categories()[:10])
#['acq', 'alum', 'barley', 'bop', 'carcass', 'castor-oil', 'cocoa', 'coconut', 'coconut-oil', 'coffee']print(reuters.fileids()[:10])
# ['test/14826', 'test/14828', 'test/14829', 'test/14832', 'test/14833', 'test/14839', 'test/14840', 'test/14841', 'test/14842', 'test/14843']sample = 'test/14829'
categories = reuters.categories(sample)print(categories)
# ['acq', 'alum', 'barley', 'bop', 'carcass', 'castor-oil', 'cocoa', 'coconut', 'coconut-oil', 'coffee']content = ""
with reuters.open(sample) as stream:content = stream.read()print(f"Categories #{categories} / file #{sample}")
# Categories #['crude', 'nat-gas'] / file #test/14829print(f"Content:\#{content}")
# Content:\#JAPAN TO REVISE LONG-TERM ENERGY DEMAND DOWNWARDS
# The Ministry of International Trade and
# Industry (MITI) will revise its long-term energy supply/demand
# outlook by August to meet a forecast downtrend in Japanese
# energy demand, ministry officials said.
# MITI is expected to lower the projection for primary energy
# supplies in the year 2000 to 550 mln kilolitres (kl) from 600
# mln, they said.
# The decision follows the emergence of structural changes in
# Japanese industry following the rise in the value of the yen
# and a decline in domestic electric power demand.
# MITI is planning to work out a revised energy supply/demand
# outlook through deliberations of committee meetings of the
# Agency of Natural Resources and Energy, the officials said.
# They said MITI will also review the breakdown of energy
# supply sources, including oil, nuclear, coal and natural gas.
# Nuclear energy provided the bulk of Japan's electric power
# in the fiscal year ended March 31, supplying an estimated 27
# pct on a kilowatt/hour basis, followed by oil (23 pct) and
# liquefied natural gas (21 pct), they noted.8.2 语料库管理
语料库阅读器
NLTK 文档集读取器对象提供读取、筛选、解码和预处理结构化文件列表或 zip 文件。
存在许多不同的语料库读取器对象,请参阅完整列表。最常见的读者是:
- PlaintextCorpusReader:阅读段落拆分为空白行的文本文档。
- Markdown:处理 Markdown 文件,其中其类别在文件名中表示
- 已标记:需要已标记语料库的特殊语料库读取器对象,例如 Conl。请注意,对于多个内置语料库对象,标记的版本已经存在。
- 推特:处理 JSON 格式的推文
- XML:处理 XML 文件
作为一个简短的例子,下面是一个将读取文件。PlaintextCorpusReader*.txt
from nltk.corpus.reader.plaintext import PlaintextCorpusReadercorpus = PlaintextCorpusReader('wikipedia_articles', r'.*\.txt')print(corpus.fileids())
# ['AI_alignment.txt', 'AI_safety.txt', 'Artificial_intelligence.txt', 'Machine_learning.txt']print(corpus.sents())
# [['In', 'the', 'field', 'of', 'artificial', 'intelligence', '(', 'AI', '),', 'AI', 'alignment', 'research', 'aims', 'to', 'steer', 'AI', 'systems', 'towards', 'humans', ''', 'intended', 'goals', ',', 'preferences', ',', 'or', 'ethical', 'principles', '.'], ['An', 'AI', 'system', 'is', 'considered', 'aligned', 'if', 'it', 'advances', 'the', 'intended', 'objectives', '.'], ...]8.3 文本集合
另一个从语料库访问结构化信息的实用工具是 TextCollection 类。在标记化文本上实例化,它提供以下功能:
collocations(num, window_size):返回到长度的元组,单词并置出现numwindow_sizecollocation_list(num, window_size):将并置单词输出为元组列表common_contexts(word, num):打印显示的上下文wordconcordance(word, width, lines):打印给定的索引(单个单词或句子)wordconcordance_list(word, width, lines):打印元组列表count(word):单词的绝对外观tf, , : 单词的频率idftf_idfgenerate:基于三元组语言模型创建随机文本。vocab:所有代币的频率分布plot:绘制频率分布
下面是一个示例:
from nltk.corpus.reader.plaintext import PlaintextCorpusReader
from nltk.text import TextCollectioncorpus = PlaintextCorpusReader('wikipedia_articles', r'.*\.txt')
col = TextCollection(corpus.sents())
print(col.count('the'))
# 973
print(col.common_contexts(['intelligence']))
# artificial_( general_( artificial_. artificial_is general_,
# artificial_, artificial_in artificial_". artificial_and "_"
# artificial_was general_and general_. artificial_; artificial_" of_or
# artificial_– artificial_to artificial_: and_.九、机器学习聚类和分类模型
NLTK 提供了几种聚类和分类算法。但在使用任何算法之前,需要手动设计和从文本中提取特征。
在有关分类的 API 文档页面上,步骤定义如下:
- 定义与 ML 任务相关的功能
- 实现从语料库中提取特征的方法(例如,文档中的词频)
- 创建一个包含单个元组的 Python 字典对象,并将它们传递给训练算法
(feature_name, labels)
让我们用 NLTK 手册中的一个例子来说明这一点,以构建文本分类器。
首先,我们建立一个包含所有单词的词汇表:
from nltk.corpus.reader.plaintext import PlaintextCorpusReader
corpus = PlaintextCorpusReader('wikipedia_articles', r'.*\.txt')vocab = nltk.FreqDist(w.lower() for w in corpus.words())
# FreqDist({'the': 65590, ',': 63310, '.': 52247, 'of': 39000, 'and': 30868, 'a': 30130, 'to': 27881, 'in': 24501, '-': 19867, '(': 18243, ...})
all_words = nltk.FreqDist(w.lower() for w in corpus.words())
word_features = list(all_words)
# ['the', ':']其次,我们定义一种方法,该方法返回一个热编码的单词向量,该向量表示文档中是否存在单词。生成的特征向量必须包含布尔值,才能用于分类任务。
def document_features(document):document_words = set(corpus.words(document))features = {}for word in word_features:features['contains({})'.format(word)] = (word in document_words)return featuresf = document_features('Artificial_intelligence.txt')
# {'contains(the)': True,
# 'contains(,)': True,
# 'contains(.)': True,第三,我们选择一种分类算法,并将特征化的文档传递给它。
featuresets = [(document_features(d), d) for d in corpus.fileids()]
featuresets
# featuresets = [(document_features(d), d) for d in corpus.fileids()]train_set, test_set = featuresets[100:], featuresets[:100]
classifier = nltk.NaiveBayesClassifier.train(train_set)
# <nltk.classify.naivebayes.NaiveBayesClassifier at 0x185ec5dd0>十、总结
NLTK 是一个支持多个 NLP 任务的多功能库。对于标记化、词干提取/词形还原和词性标记的核心任务,包括内置方法以及科学论文中的方法。为了管理文档语料库,NLTK处理文本,Markdown,XML和其他格式,并提供API来获取文件,类别,句子和单词。特别有用的是能够收集单词搭配和计算术语频率的类。塞巴斯蒂安 最后,NLTK还提供了聚类和分类算法,如KMeans。决策树或朴素贝叶斯。TextCollection