大数据(四)主流大数据技术
一、写在前面的话

To 那些被折磨打击的好女孩(好男孩):
有些事情我们无法选择,也无法逃避伤害。
但请你在任何时候都记住:
你可能在一些人面前,一文不值,被伤害得体无完肤,
但一定会是另一些人心里的无价之宝,他(她)会把你看得比自己还重要。
做你自己就好,无需刻意改变任何,爱你的人,自然爱你。
谨记自己的价值所在!你活在你自己的世界,活在那些爱你的人的心中!
逆境清醒
2023.8.27

二、大数据技术
主流的大数据技术可以分为两大类。
一类面向非实时批处理业务场景,着重用于处理传统数据处理技术在有限的时空环境里无法胜任的TB级、PB级海量数据存储、加工、分析、应用等。如:用户行为分析、订单防欺诈分析、用户流失分析、数据仓库等,这类业务场景的特点,是非实时响应。通常,一些单位在晚上交易结束时,抽取各类数据进入大数据分析平台,在数小时内获得计算结果,并用于第二天的业务。比较主流的支撑技术为HDFS、MapReduce、Hive等。
另一类面向实时处理业务场景,如微博应用、实时社交、实时订单处理等,这类业务场景,特点是强实时响应,用户发出一条业务请求,在数秒钟之内要给予响应,并且确保数据完整性。比较主流的支撑技术为HBase、Kafka、Storm等。
(1)HDFS

HDFS指Hadoop分布式文件系统(Hadoop Distributed File System),是Apache Hadoop项目的核心组成部分,是一种高可用性、高可靠性、高扩展性、高容错性的分布式文件系统。它可以在一组廉价的计算机上存储和处理大规模数据集,通过在多个节点之间分布数据和计算任务,实现了大规模数据的并行处理。
HDFS是Hadoop的核心子项目,是整个Hadoop平台数据存储与访问的基础。基于Linux本地文件系统上的文件系统。在此之上,承载其他如MapReduce、HBase等子项目的运转。它是易于使用和管理的分布式文件系统。
HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。
HDFS技术有以下特点:
1.大规模存储:HDFS可以处理PB级别的大规模数据集,支持数据文件的分布式存储和管理。
2.高可靠性:HDFS是基于冗余的数据存储方式,将数据分散到不同的节点上,任意一台服务器宕机不会影响数据的完整性和可用性。
3.高可扩展性:HDFS可以在成百上千台机器上运行,支持动态扩展,方便用户随着数据量的增长进行扩容。
4.高容错性(fault-tolerent):HDFS通过数据块的多副本备份来实现数据的容错,如果某个节点宕机,其他节点可以继续提供数据服务。
5.高效性:HDFS支持数据的批量读写,提供了高效的数据传输机制,能够在集群中实现数据的快速传输和处理。6.高吞吐量(high throughput)
7.HDFS 放宽了(relax)POSIX 的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
总之,HDFS技术是实现大数据存储、管理、处理的必备技术之一,它可以为不同行业的企业提供高效可靠的数据存储解决方案。
(2)MapReduce

MapReduce是一个软件架构,在数以千计的普通硬件构成的集群中以平行计算的方式处理海量数据,该计算框架具有很高的稳定性和容错能力。MapReduce对负责逻辑进行高度归约,抽象为Mapper和Reducer类,复杂逻辑通过理解,转化为符合MapReduce函数处理的模式。
MapReduce job会划分输入数据集为独立的计算块,这些分块被map任务以完全并行、独立的模式处理。MapReduce框架对maps的输出进行排序,排序后,数据作为reduce任务的输入数据。job的input和output数据都存储在HDFS文件系统中。计算框架管理作业调度、监控作业、重新执行失败任务。
MapReduce是一个用于大规模数据处理的分布式计算框架,
MapReduce软件架构可以分为以下三个层次:
♦ 应用层:MapReduce应用程序开发人员使用MapReduce API编写应用程序,将问题分解为一个个独立且可并行处理的任务。这些任务被分为两个阶段:map阶段和reduce阶段,在map阶段将数据拆分成小块并作为键值对进行处理,然后将处理好的数据按照键进行分组处理和合并,最终生成想要的结果。
♦ 计算层:MapReduce计算集群由两种类型的节点组成:一个Master节点和一组Worker节点。Master节点负责协调整个计算过程,包括任务的划分、Worker节点的监控和数据传输等。Worker节点执行分配给它们的任务,并将结果返回给Master节点。计算层中的每个节点都是一台物理计算机或虚拟机,并且都可以在系统范围内通信。
♦ 存储层:MapReduce存储层使用Hadoop Distributed File System(HDFS)存储大量数据。HDFS是一种可扩展且容错的文件系统,可以将数据复制到不同的节点上,以保证数据的可靠性。HDFS为MapReduce提供了高效的数据存储和管理方式。
以上就是MapReduce软件架构的三个层次。MapReduce通过将数据分解成小块并在计算节点之间分配任务,实现了大规模数据的高效处理。
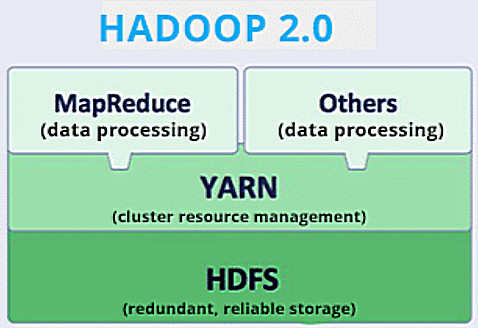
(3)YARN

Apache Hadoop YARN(Yet Another Resource Negotiator,另一种资源协调者)是从Hadoop 0.23进化来的一种新的资源管理和应用调度框架。基于YARN,可以运行多种类型的应用程序,例如MapReduce、Spark、Storm等。YARN不再具体管理应用,资源管理和应用管理是两个低耦合的模块。
YARN从某种意义上来说,是一个云操作系统(Cloud OS)。基于该操作系统之上,程序员可以开发多种应用程序,例如批处理MapReduce程序、Spark程序以及流式作业Storm程序等。这些应用,可以同时利用Hadoop集群的数据资源和计算资源。
YARN(Yet Another Resource Negotiator)是Hadoop生态系统中的一个资源管理器,它的主要功能是对集群资源进行统一的管理和调度,为多个应用程序分配集群资源,提高了Hadoop集群的资源利用率。YARN作为Hadoop 2.0的一个重要组件,大大扩展了Hadoop的应用场景,支持多种计算模型,包括MapReduce、Spark、Storm等。
YARN的主要功能包括:
1.资源管理:YARN可以管理集群中不同节点的资源,并为不同的应用程序分配资源,保证应用程序的正常运行。
2.调度管理:YARN可以根据不同应用程序的需求,按照指定的策略和规则对集群资源进行调度,并保证应用程序的公平共享资源。
3.应用程序管理:YARN可以自动管理应用程序的生命周期,包括应用程序启动、监控、重启和关闭等操作。
4.安全管理:YARN可以提供强大的安全管理功能,包括用户认证、授权和数据加密等,保证集群的安全性和稳定性。
总之,YARN作为Hadoop生态系统中的重要组件,为多个应用程序的运行提供了可靠的资源管理和调度功能,广泛应用于互联网、金融、医疗等各个行业。
(4)HBase

HBase是Hadoop平台中重要的非关系型数据库,它通过线性可扩展部署,可以支撑PB级数据存储与处理能力。
作为非关系型数据库,HBase适合于非结构化数据存储,它的存储模式是基于列的。
HBase是一个开源的分布式NoSQL数据库,在Hadoop生态系统中,它是Hadoop数据库、 MapReduce和HDFS的组件之一。HBase基于Google的BigTable论文而来,它是一个高可靠性、高可扩展性、高性能的数据库,设计用于在大规模数据集上运行。HBase具有以下特点:
以列簇为基本存储单位,支持动态列。
支持自动分区、自动负载均衡、自动故障转移。
支持半结构化数据和非结构化数据,没有固定的表模式。
支持高并发读写操作、多版本数据、数据压缩、数据缓存。
HBase高度可伸缩,可以支持数千亿行数据,每行可以有数万个列。
HBase通常用于存储半结构化数据,例如日志、社交媒体数据、传感器数据、网络数据、图像和音频等。它可以根据需要动态调整存储和处理容量,可以承载大规模数据集的查询和分析,是处理大数据的理想选择。
(5)Hive

Apache Hive是一个建立在Hadoop架构之上的数据仓库。它能够提供数据的精炼,查询和分析。Apache Hive起初由Facebook开发,目前也有其他公司使用和开发Apache Hive,例如Netflix等。
Hive是Apache基金会下面的开源框架,是基于Hadoop的数据仓库工具,它可以把结构化的数据文件映射为一张数据仓库表,并提供简单的SQL(Structured Query Language)查询功能,后台将SQL语句转换为MapReduce任务来运行。
使用Hive,可以满足一些不懂MapReduce但懂SQL的数据库管理员的需求,让他们能够平滑地使用大数据分析平台。
Hive是基于Hadoop的数据仓库工具,是一个数据仓库基础设施,能够将结构化的数据文件映射为一张数据库表,并提供了一套类SQL查询语言HiveQL来查询数据。Hive是为了方便SQL开发人员来处理大型数据集而设计的,它可以通过HQL将类SQL的语法转换成MapReduce任务来执行,从而利用Hadoop集群处理海量数据。
Hive支持多种数据源,包括HDFS、HBase、本地文件系统等。它可以通过内置的数据存储格式,如文本、序列化、ORC等,存储海量数据,并提供了数据压缩、数据分区、数据桶等特性来优化性能。
Hive拥有良好的扩展性和生态系统,可以通过UDF(用户自定义函数)、UDAF(用户自定义聚合函数)等方式扩展功能,并且支持很多第三方工具的集成,如JDBC、ODBC、Tableau等。
总之,Hive是一个强大的数据仓库工具,对于需要处理大量数据的场景具有很大的实用价值。
(6)Kafka

Apache Kafka是分布式“发布-订阅”消息系统,最初,它由LinkedIn公司开发,而后成为Apache项目。Kafka是一种快速、可扩展的、设计时内在地就是分布式的、分区的和可复制的提交日志服务。
Kafka是一个分布式系统,易于向外扩展,可为发布和订阅提供高吞吐量,并且支持多订阅者,当失败时,能自动平衡消费者;Kafka可将消息持久化存储,既可面向非实时业务,也可以面向实时业务。
Apache Kafka是由Apache软件基金会开发的一种分布式流处理平台,它具有高可靠性、高扩展性和高吞吐量的特点。Kafka基于发布/订阅模式,主要用于记录流式数据,例如日志、事件和指标等。
Kafka的架构包括以下几个组件:
Broker:Kafka集群中的每个节点都称为Broker,负责存储和处理数据。
Topic:数据记录存储在一个或多个Topic中。每个Topic分为多个Partition,每个Partition都可以在不同的Broker上分布。
Producer:Producer负责将数据发送到Kafka集群中的Topic,可以指定数据发送到哪个Partition。
Consumer:Consumer从Kafka集群中Topic订阅数据,并处理这些数据。Consumer可以组成Consumer Group,每个Group中的Consumer共同消费一个或多个Partition中的数据。
Kafka被广泛应用于各种场景,例如日志收集、实时数据流处理、事件驱动架构等。它与Hadoop、Spark等开源技术紧密结合,成为了大数据生态系统中不可或缺的一部分。
(7)Storm
Storm是一个免费开源、分布式、高容错的实时计算系统。它能够处理持续不断的流计算任务,目前,比较多地被应用到实时分析、在线机器学习、ETL等领域。
Storm是一个开源的分布式实时计算系统,主要用于处理大量的流式数据。它可以实时地获取数据、处理数据、并将处理过的数据发送到其他系统。Storm具有高可扩展性、容错性和可靠性,能够在分布式集群中运行。
Storm的核心概念是Topology(拓扑),一个Topology是一种数据流处理的方式,它由Spout和Bolt组成。Spout是用于数据源输入的组件,负责将数据输入到Topology中,Bolt则是用于数据处理和数据传递的组件,将接收Spout发送过来的数据,处理后再将处理过的数据传递给下一个Bolt或者Sink。Topology中的每个Bolt都可以并行运行,让数据处理更加高效。
Storm还拥有内置的容错机制,能够在集群节点出现故障时自动重启或者切换到其他节点上运行,实现了高可靠性的分布式计算。同时,Storm还支持多种数据源(如Kafka、RabbitMQ等)和数据存储(如HDFS、Cassandra、Redis等),可以处理不同类型的数据,并将结果存储到不同的数据存储中。
总之,Storm 是一个功能强大的实时计算框架,被广泛应用于各行各业的实时数据处理领域。
Storm与Hadoop的对比
| 结构 | Hadoop | Storm |
|---|---|---|
| 主节点 | JobTracker | Nimbus |
| 从节点 | TaskTracker | Supervisor |
| 应用程序 | Job | Topology |
| 工作进程名称 | Child | Worker |
| 计算模型 | Map / Reduce | Spout / Bolt |
大数据文章:
- 大数据(一)定义、特性
- 大数据(二)大数据行业相关统计数据
- 大数据(三)大数据相关的职位
- 基于Echarts构建大数据可视化大屏
- 大数据(四)主流大数据技术
推荐阅读:
| [你找到牵手一辈子的人了吗?] 七夕情人节特辑 |
| 数字技术能让古籍“活过来”吗? |
| 心情不好时,帮自己训练个AI情绪鼓励师吧(基于PALM 2.0 finetune) |
| 深度学习框架TensorFlow |
| 人工智能开发人员工作流程、看法、工具统计数据 |
| 2023 年6月开发者调查统计结果——最流行的技术(2) |
| 2023 年6月开发者调查统计结果——最流行的技术(1) |
| 让Ai帮我们画个粽子,它会画成什么样呢? |
|
|
|
|
| 给照片换底色(python+opencv) | 猫十二分类 | 基于大模型的虚拟数字人__虚拟主播实例 |
|
|
|
|
| 计算机视觉__基本图像操作(显示、读取、保存) | 直方图(颜色直方图、灰度直方图) | 直方图均衡化(调节图像亮度、对比度) |
|
|
|
|
| 语音识别实战(python代码)(一) | 人工智能基础篇 | 计算机视觉基础__图像特征 |









|
| ||
| matplotlib 自带绘图样式效果展示速查(28种,全) | ||
|
| ||
| Three.js实例详解___旋转的精灵女孩(附完整代码和资源)(一) | ||
|
|
|
|
| 立体多层玫瑰绘图源码__玫瑰花python 绘图源码集锦 | Python 3D可视化(一) | 让你的作品更出色——词云Word Cloud的制作方法(基于python,WordCloud,stylecloud) |
|
|
|
|
| python Format()函数的用法___实例详解(一)(全,例多)___各种格式化替换,format对齐打印 | 用代码写出浪漫__合集(python、matplotlib、Matlab、java绘制爱心、玫瑰花、前端特效玫瑰、爱心) | python爱心源代码集锦(18款) |
|
|
|
|
| Python中Print()函数的用法___实例详解(全,例多) | Python函数方法实例详解全集(更新中...) | 《 Python List 列表全实例详解系列(一)》__系列总目录、列表概念 |
|
|
| |
| 用代码过中秋,python海龟月饼你要不要尝一口? | python练习题目录 | |
|
|
|
|
| 草莓熊python turtle绘图(风车版)附源代码 | 草莓熊python turtle绘图代码(玫瑰花版)附源代码 | 草莓熊python绘图(春节版,圣诞倒数雪花版)附源代码 |
|
|
| |
| 巴斯光年python turtle绘图__附源代码 | 皮卡丘python turtle海龟绘图(电力球版)附源代码 | |


















|
|
|
|
| Node.js (v19.1.0npm 8.19.3) vue.js安装配置教程(超详细) | 色彩颜色对照表(一)(16进制、RGB、CMYK、HSV、中英文名) | 2023年4月多家权威机构____编程语言排行榜__薪酬状况 |
|
|
|
|
| 手机屏幕坏了____怎么把里面的资料导出(18种方法) | 【CSDN云IDE】个人使用体验和建议(含超详细操作教程)(python、webGL方向) | 查看jdk安装路径,在windows上实现多个java jdk的共存解决办法,安装java19后终端乱码的解决 |






|
| ||
| vue3 项目搭建教程(基于create-vue,vite,Vite + Vue) | ||
|
|
|
|
| 2023年春节祝福第二弹——送你一只守护兔,让它温暖每一个你【html5 css3】画会动的小兔子,炫酷充电,字体特 | 别具一格,原创唯美浪漫情人节表白专辑,(复制就可用)(html5,css3,svg)表白爱心代码(4套) | SVG实例详解系列(一)(svg概述、位图和矢量图区别(图解)、SVG应用实例) |
|
|
|
|
| 【程序人生】卡塔尔世界杯元素python海龟绘图(附源代码),世界杯主题前端特效5个(附源码) | HTML+CSS+svg绘制精美彩色闪灯圣诞树,HTML+CSS+Js实时新年时间倒数倒计时(附源代码) | 2023春节祝福系列第一弹(上)(放飞祈福孔明灯,祝福大家身体健康)(附完整源代码及资源免费下载) |







|
|
|
|
| tomcat11、tomcat10 安装配置(Windows环境)(详细图文) | Tomcat端口配置(详细) | Tomcat 启动闪退问题解决集(八大类详细) |