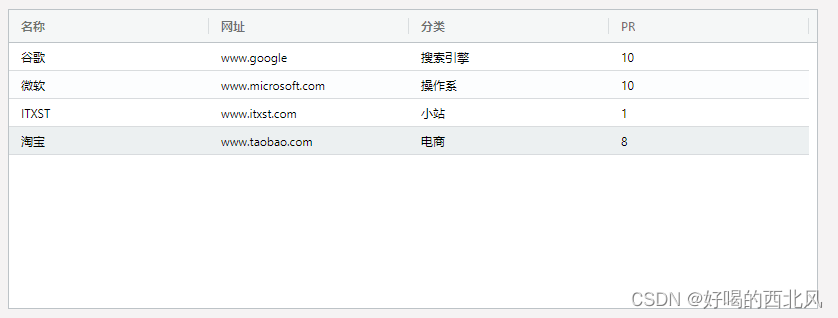
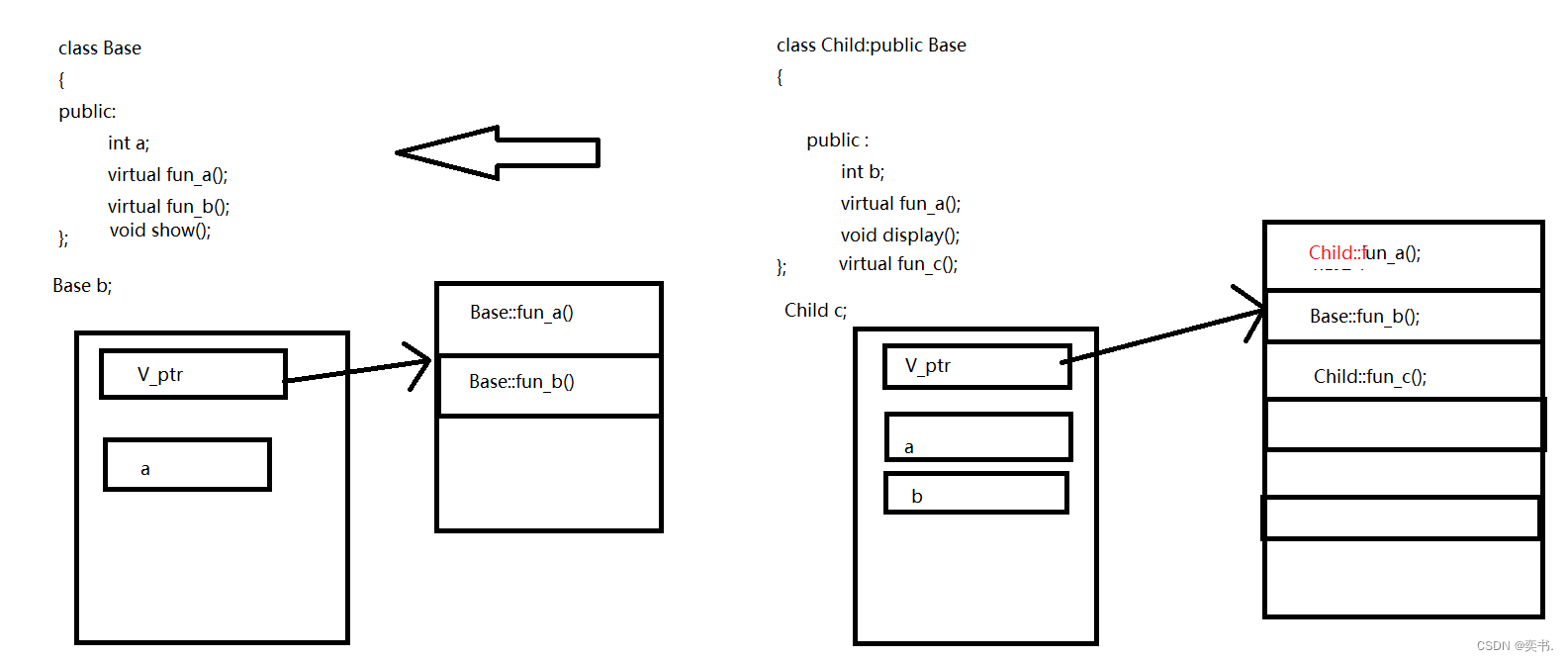
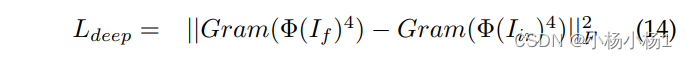马尔科夫决策过程
-
markov chain: S \mathcal{S} S
-
MRP: S , R \mathcal{S,R} S,R
-
MDP: S , A ( s ) , R , P \mathcal{S,A(s),R,P} S,A(s),R,P, P : p = P r { S t + 1 = s ′ , R t + 1 = r ∣ S t = s , A t = a } \mathcal{P}:p=Pr\{S_{t+1}=s',R_{t+1}=r|S_t = s,At = a\} P:p=Pr{St+1=s′,Rt+1=r∣St=s,At=a}
-
状态转移函数: p ( s ′ ∣ s , a ) = ∑ r ∈ R p ( s ′ , r ∣ s , a ) \mathcal{p(s'|s,a) = \sum_{r\in R}{p(s',r|s,a)}} p(s′∣s,a)=∑r∈Rp(s′,r∣s,a)
-
π \pi π(policy):
{ a = π ( s ) 确定性策略 π ( a ∣ s ) = P r { A t = a ∣ S t = s } 随机性策略 \begin{cases} {a = \pi(s)}& \text{确定性策略}\\ {\pi(a|s )= Pr\{A_t = a|S_t = s}\}& \text{随机性策略} \end{cases} {a=π(s)π(a∣s)=Pr{At=a∣St=s}确定性策略随机性策略 -
G ( R e t u r n ) G(Return) G(Return), γ ( d i s c o u n t ) \gamma(discount) γ(discount):
G t = R t + 1 + γ R t + 1 . . . + γ T − 1 R T = ∑ i = 0 ∞ γ i R t + i + 1 , γ ∈ [ 0 , 1 ] G_t = R_{t+1} + \gamma R_{t+1}...+\gamma^{T-1} R_T = \sum_{i=0}^{\infty}{\gamma_i R_{t+i+1}},\gamma \in[0,1] Gt=Rt+1+γRt+1...+γT−1RT=∑i=0∞γiRt+i+1,γ∈[0,1] -
价值函数:
{ v π ( s ) = E π { G t ∣ S t = s } 状态价值函数 q π ( s , a ) = E π { G t ∣ S t = s , A t = a } 状态动作价值函数 \begin{cases} {v_\pi(s) = E_\pi \{G_t | S_t =s\}}& \text{状态价值函数}\\ {q_\pi(s,a) = E_\pi \{G_t | S_t =s,A_t = a\}}& \text{状态动作价值函数} \end{cases} {vπ(s)=Eπ{Gt∣St=s}qπ(s,a)=Eπ{Gt∣St=s,At=a}状态价值函数状态动作价值函数
⇒ \Rightarrow ⇒ v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) v_\pi(s) = \sum_{a \in A}{\pi (a|s) q_{\pi}(s,a)} vπ(s)=∑a∈Aπ(a∣s)qπ(s,a)
⇒ \Rightarrow ⇒ q π ( s ) = ∑ s ′ , r { p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] } q_\pi(s) = \sum_{s',r}\{p(s',r|s,a) [r+\gamma v_\pi(s')]\} qπ(s)=∑s′,r{p(s′,r∣s,a)[r+γvπ(s′)]} -
B e l l m a n E x p e c t a t i o n E q u a t i o n Bellman\ Expectation\ Equation Bellman Expectation Equation
{ v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] q π ( s , a ) = ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ ∑ a ∈ A π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) ] \begin{cases} {v_\pi(s) = \sum_{a \in A}{\pi(a|s) \sum_{s',r}{p(s',r|s,a)[r+\gamma v_\pi(s')]}}}\\ {q_\pi(s,a) = \sum_{s',r}{p(s',r|s,a)[r+\gamma \sum_{a \in A}{\pi (a'|s') q_{\pi}(s',a')]}}} \end{cases} {vπ(s)=∑a∈Aπ(a∣s)∑s′,rp(s′,r∣s,a)[r+γvπ(s′)]qπ(s,a)=∑s′,rp(s′,r∣s,a)[r+γ∑a∈Aπ(a′∣s′)qπ(s′,a′)] -
最优价值函数
{ v ∗ ( s ) = m a x a v π ( s ) 最优状态价值函数 q ∗ ( s , a ) = m a x a q π ( s , a ) 最优状态动作价值函数 \begin{cases} {v_*(s) = \underset{a}{max}v_\pi(s)}& \text{最优状态价值函数}\\ {q_*(s,a) = \underset{a}{max}q_\pi(s,a)}& \text{最优状态动作价值函数} \end{cases} ⎩ ⎨ ⎧v∗(s)=amaxvπ(s)q∗(s,a)=amaxqπ(s,a)最优状态价值函数最优状态动作价值函数 -
B e l l m a n O p t i m a l i t y E q u a t i o n Bellman\ Optimality\ Equation Bellman Optimality Equation
{ v ∗ ( s ) = m a x a ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] q π ( s , a ) = ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ m a x a q ∗ ( s ′ , a ′ ) ] \begin{cases} {v_*(s) = \underset{a}{max} \sum_{s',r}p(s',r|s,a) [r+\gamma v_\pi(s')]}\\ {q_\pi(s,a) = \sum_{s',r}{p(s',r|s,a) [r + \gamma \underset{a}{max} q_* (s',a')]}} \end{cases} ⎩ ⎨ ⎧v∗(s)=amax∑s′,rp(s′,r∣s,a)[r+γvπ(s′)]qπ(s,a)=∑s′,rp(s′,r∣s,a)[r+γamaxq∗(s′,a′)]
动态规划
策略迭代 { 策略评估 : 已知 p ( s ′ , a ∣ s , a ) , ∀ π , d o q π ( s , a ) 策略改进 : f i n d π ′ , s . t . π ′ ⩾ π {策略迭代}\begin{cases} {策略评估:} {已知p(s',a|s,a),\forall \pi, do\ q_\pi(s,a)} \\ {策略改进:} {find\ \pi',s.t.\ \pi'\geqslant \pi} \end{cases} 策略迭代{策略评估:已知p(s′,a∣s,a),∀π,do qπ(s,a)策略改进:find π′,s.t. π′⩾π
价值迭代:极端情况下的策略迭代
策略迭代:
- 解析解: v π ( s ) = r π ( s ) + γ ∑ s ′ P π ( s , s ′ ) v π ( s ) = ( I − γ P π ) − 1 γ π , O ( ∣ s ∣ 3 ) v_\pi(s) = r_\pi(s) +\gamma \sum_{s'}{P_\pi(s,s')v_\pi(s)} = (I - \gamma P_\pi)^{-1} \gamma_\pi,O(|s|^3) vπ(s)=rπ(s)+γ∑s′Pπ(s,s′)vπ(s)=(I−γPπ)−1γπ,O(∣s∣3)
- 数值解:迭代策略评估
构造数列 v k , s . t . lim k → ∞ v k = v π {v_k},s.t. \lim\limits_{k\rightarrow \infty}{v_k} = v_\pi vk,s.t.k→∞limvk=vπ
迭代公式: v k + 1 = ∑ a π ( a ∣ s ) ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v k ( s ′ ) ] v_{k+1} = \sum_{a}{\pi(a|s) \sum_{s',r}{p(s',r|s,a)[r+\gamma v_k(s')]}} vk+1=∑aπ(a∣s)∑s′,rp(s′,r∣s,a)[r+γvk(s′)]
v π = ∑ a π ( a ∣ s ) ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] v_{\pi} = \sum_{a}{\pi(a|s) \sum_{s',r}{p(s',r|s,a)[r+\gamma v_\pi(s')]}} vπ=∑aπ(a∣s)∑s′,rp(s′,r∣s,a)[r+γvπ(s′)] (由不动点定理 ⇒ v k → v π \Rightarrow{v_k} \rightarrow v_\pi ⇒vk→vπ)
策略改进:

- 策略改进定理:给定 π , π ′ , i f ∀ s ∈ S , t h e n v π ( s ) ⩽ q π ( s , π ′ ( s ) ) , s o ∀ s ∈ S , v π ( s ) ⩽ v π ′ ( s ) \pi,\pi',if\ \forall s \in S,then\ v_\pi(s) \leqslant q_\pi(s,\pi'(s)),so\ \forall s \in S,v_\pi(s) \leqslant v_\pi'(s) π,π′,if ∀s∈S,then vπ(s)⩽qπ(s,π′(s)),so ∀s∈S,vπ(s)⩽vπ′(s)
- G r e e d y P o l i c y : ∀ s ∈ S , s . t . π ′ ( s ) = a r g m a x a q π ( s , a ) Greedy\ Policy:\forall s \in S,\ s.t.\ \pi'(s) = arg\underset{a}{max}q_\pi(s,a) Greedy Policy:∀s∈S, s.t. π′(s)=argamaxqπ(s,a)
由策略改进定理可知: ∀ s ∈ S , v π ′ ( s ) ⩾ v π ( s ) \forall s \in S,v_\pi'(s) \geqslant v_\pi(s) ∀s∈S,vπ′(s)⩾vπ(s) - 问题:迭代中套迭代, π 1 → v π 1 → π 2 → v π 2 . . . π ∗ → v ∗ \pi_1 \rightarrow v_{\pi1} \rightarrow\pi_2 \rightarrow v_{\pi2} ... \pi_*\rightarrow v_* π1→vπ1→π2→vπ2...π∗→v∗

解决:截断策略评估(策略评估只进行半步), π 1 → v 1 ( s ) \pi_1 \rightarrow v_1(s) π1→v1(s)
可简化为: v k + 1 = m a x a ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v k ( s ′ ) ] v_{k+1} =\underset{a}{max}\sum_{s',r}{p(s',r|s,a)[r+\gamma v_k(s')]} vk+1=amax∑s′,rp(s′,r∣s,a)[r+γvk(s′)]
迭代序列:
v 1 ( s 1 ) , v 1 ( s 2 ) , . . . , v 1 ( s ∣ s ∣ ) , v_1(s_1),v_1(s_2),...,v_1(s_{|s|}), v1(s1),v1(s2),...,v1(s∣s∣),
v 2 ( s 1 ) , v 2 ( s 2 ) , . . . , v 2 ( s ∣ s ∣ ) , v_2(s_1),v_2(s_2),...,v_2(s_{|s|}), v2(s1),v2(s2),...,v2(s∣s∣),
. . . ... ...
v k ( s 1 ) , v k ( s 2 ) , . . . , v k ( s ∣ s ∣ ) , v_k(s_1),v_k(s_2),...,v_k(s_{|s|}), vk(s1),vk(s2),...,vk(s∣s∣),
当状态空间 S S S维度较高时,价值迭代人计算量巨大
- 就地策略迭代:随机选取 ∀ s \forall s ∀s,对其 v k ( s ) v_k(s) vk(s)更新,完成策略评估
- 广义策略迭代(GPI)
蒙特卡洛方法
用采样的方法解决动态特性未知的问题
用MC做策略评估
v π ( s ) = E π [ G t ∣ S t = s ] ≈ 1 N ∑ i = 1 G t i v_\pi(s) = E_\pi[G_t|S_t = s] \approx \frac{1}{N}\sum_{i=1}{G_t^i} vπ(s)=Eπ[Gt∣St=s]≈N1∑i=1Gti(大数定律)
- 首次访问型MC预测
初始化: v ( s ) , R e t u r n ( s ) , f o r ∀ s ∈ S v(s),Return(s),for\ \forall s \in S v(s),Return(s),for ∀s∈S
循环(每幕):
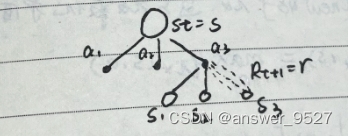
\qquad 由 π \pi π生成一幕序列: S 0 , A 0 , R 1 , S 1 , A 1 , R 3 , . . . , S T − 1 , A T − 1 , R T , S T S_0,A_0,R_1,S_1,A_1,R_3,...,S_{T-1},A_{T-1},R_T,S_T S0,A0,R1,S1,A1,R3,...,ST−1,AT−1,RT,ST
\qquad 循环每幕, t = T − 1 , T − 2 , . . . , 0 t = T-1,T-2,...,0 t=T−1,T−2,...,0
\qquad 若 S t S_t St未曾出现在 S 0 : t − 1 S_{0:t-1} S0:t−1:
\qquad \qquad 将 G G G加入到 R e t u r n ( S t ) Return(S_t) Return(St)
\qquad \qquad v s ( t ) ← a v e r a g e ( R e t u r n ( S t ) ) v_s(t) \leftarrow average(Return(S_t)) vs(t)←average(Return(St))
对 q π ( s , a ) q_\pi(s,a) qπ(s,a)而言,若要用MC做策略评估。须
{ 无限多幕 试探性出发假设 ( 保证每一对 s , a 都有非零的概率被选中作为一幕的起点 ) \begin{cases} {无限多幕} \\ {试探性出发假设(保证每一对s,a都有非零的概率被选中作为一幕的起点)} \end{cases} {无限多幕试探性出发假设(保证每一对s,a都有非零的概率被选中作为一幕的起点)
基于试探性出发假设的MC控制(策略迭代)
{ 策略评估: I . 无限幕, I I . 试探性出发假设 策略改进: π k + 1 ( s ) = a r g m a x a q π k ( s , a ) \begin{cases} 策略评估:I.无限幕,II.试探性出发假设\\ 策略改进:\pi_{k+1}(s) = arg\underset{a}{max}q_{\pi_{k}}(s,a) \end{cases} {策略评估:I.无限幕,II.试探性出发假设策略改进:πk+1(s)=argamaxqπk(s,a)
π 0 → q 0 → π 1 → q 1 . . . \pi_0 \rightarrow q_0 \rightarrow \pi_1 \rightarrow q_1... π0→q0→π1→q1...(只选一幕做评估)
q π k ( s , π k + 1 ( s ) ) = q π k ( s , a r g m a x a q π k ( s , a ) ) = m a x a q π ( s , a ) ⩾ ∑ a π k ( a ∣ s ) q π k ( s , a ) = v π k ( s , a ) q_{\pi_k}(s,\pi_{k+1}(s)) = q_{\pi_k}(s,arg\underset{a}{max}q_{\pi_k}(s,a)) =\underset{a}{max}q_\pi(s,a) \geqslant \sum_{a}{\pi_k(a|s)q_{\pi_k}(s,a)}=v_{\pi_k(s,a)} qπk(s,πk+1(s))=qπk(s,argamaxqπk(s,a))=amaxqπ(s,a)⩾∑aπk(a∣s)qπk(s,a)=vπk(s,a)
由策略改进定理: π k + 1 ⩾ π k \pi_{k+1} \geqslant \pi_k πk+1⩾πk
同轨 VS 离轨
- 如何避免试探性出发假设(b为软性策略)
{ 行动策略 b : 用样本生成的策略,且必须为软性策略 ∀ s ∈ S , a ∈ A ( s ) , 有 b ( a ∣ s ) > 0 目标策略 π : 待改进、待评估的策略 \begin{cases} 行动策略b:用样本生成的策略,且必须为软性策略\ \forall s \in S,a \in A(s),有b(a|s) >0 \\ 目标策略\pi:待改进、待评估的策略 \end{cases} {行动策略b:用样本生成的策略,且必须为软性策略 ∀s∈S,a∈A(s),有b(a∣s)>0目标策略π:待改进、待评估的策略
{ 同轨策略方法: π = b , b 为软性策略 离轨策略方法: π ≠ b (采样困难,用重要性采样) \begin{cases} 同轨策略方法:\pi = b,b为软性策略\\ 离轨策略方法:\pi \not= b(采样困难,用重要性采样) \end{cases} {同轨策略方法:π=b,b为软性策略离轨策略方法:π=b(采样困难,用重要性采样)
- 重要性采样:
E p [ f ( x ) ] = ∫ p ( x ) f ( x ) d x = ∫ p ( x ) q ( x ) q ( x ) f ( x ) d x = ∫ [ p ( x ) q ( x ) f ( x ) ] q ( x ) d x = E q [ p ( x ) q ( x ) f ( x ) ] ≈ 1 N ∑ i = 1 N p ( x ) q ( x ) f ( x ) E_p[f(x)] = \int p(x)f(x)dx = \int \frac{p(x)}{q(x)} q(x)f(x)dx = \int [\frac{p(x)}{q(x)} f(x)]q(x)dx = E_q[\frac{p(x)}{q(x)}f(x)] \approx \frac{1}{N} \sum_{i=1}^{N}\frac{p(x)}{q(x)}f(x) Ep[f(x)]=∫p(x)f(x)dx=∫q(x)p(x)q(x)f(x)dx=∫[q(x)p(x)f(x)]q(x)dx=Eq[q(x)p(x)f(x)]≈N1∑i=1Nq(x)p(x)f(x)
同轨策略的MC控制
- ε − \varepsilon- ε−贪心策略(设计软性策略)
给定 π , q π ( s , a ) , π ′ ( a ∣ s ) = { 1 − ε + ε ∣ A ∣ , i f a = a ∗ = a r g m a x q π ( s , a ) a ε ∣ A ∣ , o t h e r w i s e \pi,q_\pi(s,a),\pi'(a|s)= \begin{cases} {1- \varepsilon + \frac{\varepsilon}{|A|},}&{if\ a= a^*=arg\underset{a}{maxq_\pi(s,a)}}\\ {\frac{\varepsilon}{|A|},}&{otherwise} \end{cases} π,qπ(s,a),π′(a∣s)=⎩ ⎨ ⎧1−ε+∣A∣ε,∣A∣ε,if a=a∗=argamaxqπ(s,a)otherwise
兼顾大部分情况选最优,小部分情况选平均

离轨策略的MC策略评估(用b分布采样)
π , b \pi,b π,b固定且已知,用行动策略 b b b做试探性采样,基于行动策略改进目标策略 π \pi π;解决同轨策略不能学习到最优策略的问题

v π ( s ) = E b [ ρ t : T − 1 G t ∣ S t = s ] v_\pi(s) = E_b[\rho_{t:T-1}G_t | S_t = s] vπ(s)=Eb[ρt:T−1Gt∣St=s]
ρ t : T − 1 = ∏ k = t T − 1 π ( A k ∣ S k ) b ( A k ∣ S k ) \rho_{t:T-1} = \prod_{k=t}^{T-1} \frac{\pi(A_k|S_k)}{b(A_k|S_k)} ρt:T−1=∏k=tT−1b(Ak∣Sk)π(Ak∣Sk),重要度比列因子,此更新方式为全量更新方式,需维护每一幕完整的 G t G_t Gt

离轨策略的MC控制
增量更新:
{ C = C + W V = V + W C ( G − V ) \begin{cases} C=C+W\\ V = V + \frac{W}{C}(G-V) \end{cases} {C=C+WV=V+CW(G−V)