栈
#include <iostream>
#include <stack>int main() {std::stack<int> intStack;// 压入元素到堆栈intStack.push(5);intStack.push(10);intStack.push(15);// 查看堆栈顶部元素std::cout << "Top element: " << intStack.top() << std::endl;// 弹出堆栈顶部元素intStack.pop();// 判断堆栈是否为空if (intStack.empty()) {std::cout << "Stack is empty" << std::endl;} else {std::cout << "Stack is not empty" << std::endl;}// 打印堆栈中的元素(从栈顶到栈底)std::cout << "Stack elements: ";while (!intStack.empty()) {std::cout << intStack.top() << " ";intStack.pop();}std::cout << std::endl;return 0;
}
232. 用栈实现队列 - 力扣(LeetCode)
思路:双栈模拟队列,in2out
队列
#include <iostream>
#include <queue>int main() {// 创建一个整数队列std::queue<int> myQueue;// 向队列中添加元素myQueue.push(10);myQueue.push(20);myQueue.push(30);// 获取队列的大小std::cout << "Queue size: " << myQueue.size() << std::endl;// 访问队列的前端元素std::cout << "Front element: " << myQueue.front() << std::endl;// 访问队列的末尾元素(注意:std::queue没有直接提供访问末尾元素的接口)// 若要访问末尾元素,需要使用其他数据结构来存储队列的拷贝,然后取出拷贝的末尾元素// 弹出队列的前端元素myQueue.pop();// 检查队列是否为空if (myQueue.empty()) {std::cout << "Queue is empty." << std::endl;} else {std::cout << "Queue is not empty." << std::endl;}return 0;
}
排序
复杂度分析:

-
快速排序:
- 稳定性:快速排序不是稳定排序。由于它是通过分区操作将元素分为左右两部分,相等元素可能会在分区过程中交换位置,导致相对顺序发生改变。
- 原地性:快速排序通常是原地排序的,只需要常数级别的额外空间来保存分区点的索引。
-
堆排序:
- 稳定性:堆排序不是稳定排序。在构建堆的过程中,相等元素可能会被交换,导致相对顺序改变。
- 原地性:堆排序通常被实现为原地排序,只需要常数级别的额外空间。
-
归并排序:
- 稳定性:归并排序是稳定排序。在合并两个有序子数组时,相等元素不会改变相对顺序。
- 原地性:归并排序通常不是原地排序的,需要额外的存储空间来合并两个子数组。
C++调用:
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;int main() {std::vector<std::string> words = { "apple", "banana", "grape", "orange", "kiwi" };// 对字符串向量进行排序std::sort(words.begin(), words.end());// 打印排序后的字符串向量for (const std::string& word : words) {std::cout << word << " ";}std::cout << std::endl;std::vector<int> numbers = { 15, 6, 42, 8, 23 };// 对整数向量进行排序std::sort(numbers.begin(), numbers.end(), less<int>());// 打印排序后的整数向量for (const int& num : numbers) {std::cout << num << " ";}std::cout << std::endl;// 降序排序sort(numbers.begin(), numbers.end(), greater<int>());for (const int& num : numbers){cout << num << " ";}return 0;
}
相关题目:
56. 合并区间 - 力扣(LeetCode)
思路:先按右节点从小到大排序,再合并
215. 数组中的第K个最大元素 - 力扣(LeetCode)
思路:从大到小排序,两段数据的长度
搜索
200. 岛屿数量 - 力扣(LeetCode)
思路:找到一个1然后dfs把连起来的全赋值为0
哈希
容器对比和基础操作
(1)vector: vector支持随机访问(通过下标),时间复杂度是O(1);无序vector查找的时间复杂度是O(n),有序vector采用二分查找则是O(log n);对于插入操作,在尾部插入最快,中部次之,头部最慢;删除操作同理。由于二倍扩容机制可能会导致内存浪费,内存不足时扩容的拷贝也会造成性能开销。
(2)list: list底层是链表,不支持随机访问,只能通过扫描方式查找,时间复杂度为O(n);插入和删除速度较快,只需要调整指针指向,不会造成内存浪费。然而,频繁的内存分配和释放可能导致性能下降。
(3)deque: deque支持随机访问,但性能相对于vector较低;双端扩容机制使得头部和尾部的插入和删除元素速度很快,为O(1),但中间插入和删除较慢。
(4)set和map: 底层基于红黑树实现,增删查改的时间复杂度近似O(log n),红黑树是基于链表实现的,因此占用内存较小。
(5)unordered_set和unordered_map: 底层基于哈希表实现,是无序的。理论上增删查改的时间复杂度是O(1),但实际性能受数据分布影响较大。哈希函数的选择和解决哈希冲突的方法会影响容器的性能。
std::set:
- 性能:
std::set是基于红黑树实现的有序集合,插入、删除和查找操作的平均时间复杂度为O(log n)。 - 底层实现: 使用红黑树实现,维护元素的有序性。
- 适用场景: 适用于需要有序存储和快速查找元素的场景。对于数据量较小或需要保持有序性的情况,使用
std::set是一个不错的选择。
#include <iostream>
#include <set>int main() {// 创建一个set容器std::set<int> mySet;// 插入元素mySet.insert(3);mySet.insert(1);mySet.insert(2);// 查找元素if (mySet.find(2) != mySet.end()) {std::cout << "Element 2 found in set" << std::endl;} else {std::cout << "Element 2 not found in set" << std::endl;}// 删除元素mySet.erase(1);// 遍历打印所有元素std::cout << "Set contents:" << std::endl;for (const auto& element : mySet) {std::cout << element << " ";}std::cout << std::endl;return 0;
}
std::unordered_set:
- 性能:
std::unordered_set是基于哈希表实现的无序集合,插入、删除和查找操作的平均时间复杂度为O(1)。 - 底层实现: 使用哈希表实现,元素的存储位置由哈希函数决定。
- 适用场景: 适用于对元素顺序没有要求,但需要高效地进行插入、删除和查找操作的情况。当数据量较大且没有顺序要求时,使用
std::unordered_set可以获得更好的性能。
#include <iostream>
#include <unordered_set>
#include <unordered_map>
using namespace std;int main() {// unordered_set 常用操作示例std::unordered_set<int> intSet;// 插入元素intSet.insert(5);intSet.insert(10);intSet.insert(15);// 使用 emplace 插入元素intSet.emplace(20);// 查找元素if (intSet.find(10) != intSet.end()) {std::cout << "10 存在于集合中" << std::endl;}// 删除元素intSet.erase(5);// 遍历集合for (const int& num : intSet) {std::cout << num << " ";}std::cout << std::endl;// unordered_map 常用操作示例std::unordered_map<std::string, int> scoreMap;// 插入键值对scoreMap.emplace("Alice", 100);scoreMap.emplace("Bob", 85);scoreMap.emplace("Charlie", 92);// 查找键if (scoreMap.find("Alice") != scoreMap.end()) {std::cout << "Alice 的分数是 " << scoreMap["Alice"] << std::endl;}// 删除键值对scoreMap.erase("Bob");// 遍历键值对for (const auto& pair : scoreMap) {std::cout << pair.first << ": " << pair.second << std::endl;}unordered_map<string, vector<string>> mp;mp["Alice"].emplace_back("tall");mp["Alice"].emplace_back("thin");for (auto it = mp.begin(); it != mp.end(); ++it){cout << "key: " << it->first << ", Values: ";for (const string& value : it->second){cout << value << " ";}cout << endl;}return 0;
}
std::map:
- 性能:
std::map是基于红黑树实现的有序映射,插入、删除和查找操作的平均时间复杂度为O(log n)。 - 底层实现: 使用红黑树实现,维护键的有序性。
- 适用场景: 适用于需要根据键进行有序存储和查找操作的情况。当需要对键值对进行排序和查找时,使用
std::map是一个合适的选择。
#include <iostream>
#include <map>int main() {// 创建一个map容器,键是整数,值是字符串std::map<int, std::string> myMap;// 插入元素myMap[1] = "One";myMap[2] = "Two";myMap[3] = "Three";// 查找元素std::map<int, std::string>::iterator it = myMap.find(2);if (it != myMap.end()) {std::cout << "Key 2 found, Value: " << it->second << std::endl;} else {std::cout << "Key 2 not found" << std::endl;}// 删除元素myMap.erase(1);// 遍历打印所有元素std::cout << "Map contents:" << std::endl;for (const auto& pair : myMap) {std::cout << "Key: " << pair.first << ", Value: " << pair.second << std::endl;}return 0;
}
std::unordered_map:
- 性能:
std::unordered_map是基于哈希表实现的无序映射,插入、删除和查找操作的平均时间复杂度为O(1)。 - 底层实现: 使用哈希表实现,键的存储位置由哈希函数决定。
- 适用场景: 适用于对键值对顺序没有要求,但需要高效地进行插入、删除和查找操作的情况。当需要在键值对间进行快速查找时,使用
std::unordered_map可以获得更好的性能。
#include <iostream>
#include <unordered_map>
#include <string>int main() {// 创建一个unordered_map容器,键是整数,值是字符串std::unordered_map<int, std::string> myUnorderedMap;// 插入元素myUnorderedMap[1] = "One";myUnorderedMap[2] = "Two";myUnorderedMap[3] = "Three";// 查找元素auto it = myUnorderedMap.find(2);if (it != myUnorderedMap.end()) {std::cout << "Key 2 found, Value: " << it->second << std::endl;} else {std::cout << "Key 2 not found" << std::endl;}// 删除元素myUnorderedMap.erase(1);// 遍历打印所有元素std::cout << "Unordered Map contents:" << std::endl;for (const auto& pair : myUnorderedMap) {std::cout << "Key: " << pair.first << ", Value: " << pair.second << std::endl;}return 0;
}
哈希表
在 C++ 中,std::unordered_set 使用哈希表(Hash Table)作为底层数据结构来存储元素,处理冲突的主要原理是链地址法(Separate Chaining)。下面我会详细介绍冲突处理的原理以及元素删除的原理。
处理冲突的原理(链地址法):
- 哈希表将元素通过哈希函数映射到特定的桶(bucket)。
- 每个桶内部维护一个链表,如果多个元素映射到了同一个桶,它们将被添加到该桶对应的链表中。
- 当插入元素时,哈希表会计算元素的哈希值,找到对应的桶,然后将元素添加到桶的链表中。
- 当查找元素时,哈希表会根据元素的哈希值找到对应的桶,然后在桶的链表中查找。
删除元素的原理:
- 当要删除元素时,哈希表会计算元素的哈希值,找到对应的桶。
- 在桶的链表中查找要删除的元素,如果找到了,将该元素从链表中移除。
红黑树
树(Tree):
- 树是一种层次结构,由节点和边组成,每个节点可以有零个或多个子节点,一个节点称为另一个节点的父节点,它们之间的连接称为边。
- 树中的一个节点可以有多个子节点,但每个节点最多只有一个父节点,不存在环状结构。
- 树用于表示分层结构,例如文件系统、组织架构等。
二叉树(Binary Tree):
- 二叉树是一种特殊的树,每个节点最多有两个子节点,分别称为左子节点和右子节点。
- 二叉树可以为空,或者由一个根节点和左右两个子树构成。
二叉查找树(Binary Search Tree,BST):
- 二叉查找树是一种特殊的二叉树,对于每个节点,其左子树中的所有节点的值都小于它的值,右子树中的所有节点的值都大于它的值。
- 这个性质使得在二叉查找树中进行搜索、插入和删除操作的平均时间复杂度为 O(log n),其中 n 是树中的节点数量。
红黑树(Red-Black Tree):
- 红黑树是一种自平衡的二叉查找树,保持了在最坏情况下基本的平衡性,因此其查找、插入和删除操作的平均时间复杂度都是 O(log n)。
- 每个节点都有一个颜色属性,可以是红色或黑色。
- 红黑树具有以下性质:
- 顾名思义,红黑树中的节点,一类被标记为黑色,一类被标记为红色。
- 根节点是黑色。
- 每个**叶子节点都是黑色的空节点**(NIL),也就是说,叶子节点不存储数据;
- 任何**相邻的节点都不能同时为红色**,也就是说,红色节点是被黑色节点隔开的;
- 每个节点,**从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点;**
- 这些性质保证了红黑树的平衡,避免了退化为链表的情况。
在关系上:
- 二叉查找树是特殊的二叉树。
- 红黑树是一种特殊的自平衡二叉查找树。
二叉查找树
二叉查找树(Binary Search Tree,BST)具有以下好的性质:
-
有序性: 在二叉查找树中,每个节点的值都大于其左子树中的所有节点的值,同时小于其右子树中的所有节点的值,这保证了树的有序性。
-
快速查找: 由于有序性的特点,通过比较节点值,可以快速定位目标节点,从而实现高效的查找操作。
-
高效的插入和删除: 二叉查找树的插入和删除操作平均情况下的时间复杂度为O(log n),其中n为树中节点的数量。这使得动态地维护有序数据集变得高效。
然而,二叉查找树并不是完美的数据结构,它在某些情况下可能会退化成不平衡的树,导致操作的时间复杂度恶化。为了解决这个问题,衍生出了自平衡二叉查找树,如红黑树和AVL树。
-
增加(Insertion): 在平衡的二叉查找树中,插入操作的平均时间复杂度为O(log n)。但在不平衡的情况下,可能需要O(n)的时间,因为树可能变得过于倾斜。
-
删除(Deletion): 与插入操作类似,在平衡的情况下,删除操作的平均时间复杂度为O(log n)。不过,删除操作可能会涉及到调整树的平衡,具体复杂度取决于树的结构。
#include <iostream>
#include <vector>
using namespace std;// 二叉树的节点结构体
struct node {int data; // 数据域 node* lchild; // 指针域:左孩子node* rchild; // 指针域:右孩子
};// 创建新节点
node* newNode(int v) {node* Node = new node;Node->data = v;Node->lchild = Node->rchild = nullptr;return Node;
}// 二叉查找树的查找操作
bool search(node* root, const int& val) {if (root == nullptr) return false;if (root->data == val) return true;else if (root->data > val) {return search(root->lchild, val); // 修正:返回递归结果}else {return search(root->rchild, val); // 修正:返回递归结果}
}// 二叉查找树的插入操作
// 可以使插入操作中修改指针的值能够影响到原始指针,从而在调用者函数内正确更新树的结构。
void insert(node*& root, const int& val) { // 修正:传入引用if (root == nullptr) {root = newNode(val);return;}if (root->data == val) {return; // 已经有相同的值}else if (root->data > val) {insert(root->lchild, val);}else {insert(root->rchild, val);}
}// 二叉查找树的建立
node* create(vector<int>& data) {node* root = nullptr;for (auto& iter : data) {insert(root, iter);}return root;
}// 二叉查找树的删除
/*为保证删除某一个节点之后仍然为一个二叉查找树,一种方法是,找到删除节点的左子树中的最大值,替换掉删除的节点另一种方法是,找到删除节点的右子树中的最小值,替换掉删除的节点替换的方法是进行删除节点的递归操作
*/// 传入的是左孩子节点,找到左子树中的最大值,
node * GetLeftMax(node * root) {while (root != nullptr) {root = root->rchild;}return root;
}// 传入的是右孩子节点,找到右子树中的最小值,
node* GetRightMin(node* root) {while (root != nullptr) {root = root->lchild;}return root;
}// 二叉查找树的删除操作
void deleteNode(node*& root, int& val) {if (root == nullptr) return;if (root->data > val) {deleteNode(root->lchild, val);}else if (root->data < val) {deleteNode(root->rchild, val);}else {if (root->lchild == nullptr && root->rchild == nullptr) {delete root; // 释放内存root = nullptr; // 指针置空}else if (root->lchild != nullptr) {node* pre = GetLeftMax(root->lchild);root->data = pre->data; // 使用前驱节点替换要删除的节点deleteNode(root->lchild, pre->data); // 递归删除掉替换的节点}else if (root->rchild != nullptr) {node* post = GetRightMin(root->rchild);root->data = post->data; // 使用后继节点替换要删除的节点deleteNode(root->rchild, post->data); // 递归删除掉替换的节点}}
}int main() {vector<int> data = { 5, 3, 8, 2, 4, 7, 9 };node* root = create(data);// 测试搜索操作cout << "Search 7: " << (search(root, 7) ? "Found" : "Not found") << endl;cout << "Search 6: " << (search(root, 6) ? "Found" : "Not found") << endl;// 释放树的内存//destroy(root);return 0;
}工程上为什么偏好红黑树?
在红黑树中,红色节点不能相邻,也就是说,有一个红色节点就要至少有一个黑色节点,将它跟其他红色节点隔开。红黑树中包含最多黑色节点的路径不会超过 log2n,所以加入红色节点之后,最长路径不会超过 2log2n,也就是说,红黑树的高度近似 2log2n。
在工程中使用红黑树而不是其他平衡二叉树(如AVL树、Splay树等)的原因有多个,主要与红黑树在平衡性、性能和实现复杂度等方面的优势有关。
-
平衡性和性能: 红黑树是一种相对平衡的二叉查找树,它保持了在最坏情况下基本的平衡,这意味着它的查找、插入和删除操作的平均时间复杂度都是 O(log n)。虽然在某些特定情况下,其他平衡二叉树(如AVL树)可能会更加平衡,但红黑树在大多数情况下仍然提供了很好的性能,同时在插入和删除操作上更具灵活性。
-
实现复杂度: 红黑树相对于某些其他平衡树来说,其实现相对简单一些。红黑树的平衡性质相对较弱,允许一些不完全平衡的情况出现,因此在操作过程中的平衡调整相对较少,实现也相对较简单。
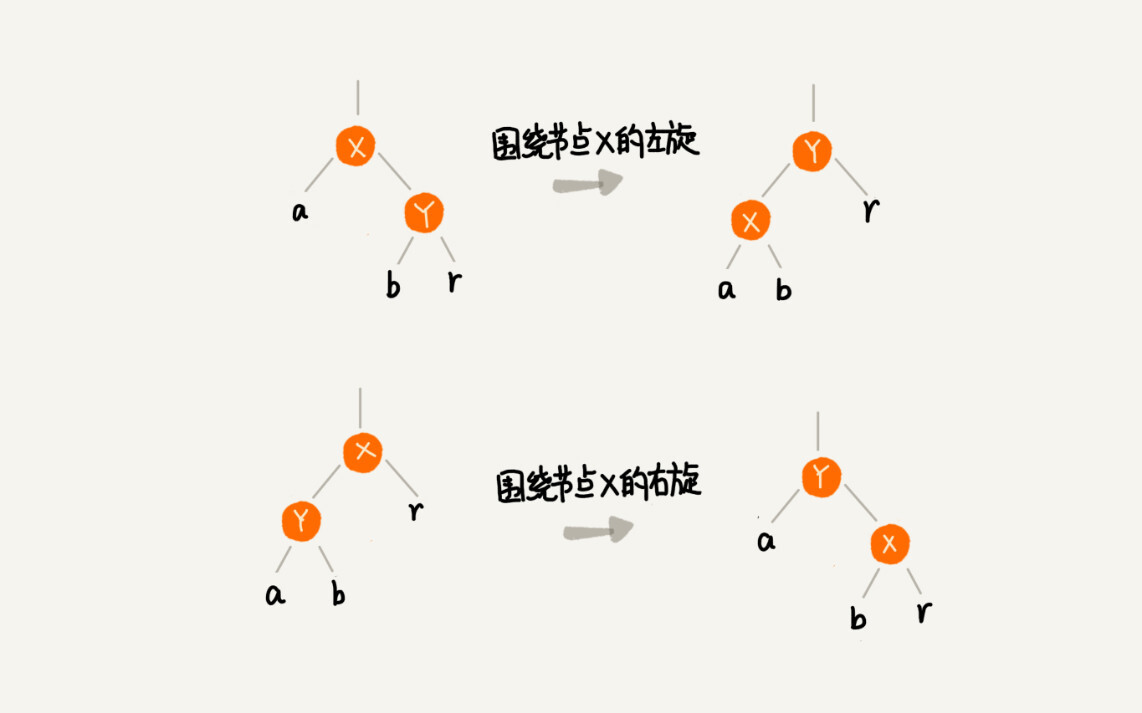
左旋与右旋
红黑树的插入
必须插入红色点
- 如果插入节点的父节点是黑色的,那我们什么都不用做,它仍然满足红黑树的定义。
- 如果插入的节点是根节点,那我们直接改变它的颜色,把它变成黑色就可以了。
如果插入的节点的父节点是红色。
核心思路:
红 -- 红 变 红 -- 黑 or 黑 -- 黑
红色在左边
如果叔叔节点是红色,那我要想办法把它变成黑色。(插入,不要相邻,染成黑色,染成红色)
如果叔叔节点是黑色,那么条件一已经满足。
将插入的红色点放置到父节点的左子树。
如果不在左子树,则以b为原点左旋。
CASE 1:如果关注节点是 a,它的叔叔节点 d 是红色,我们就依次执行下面的操作:
将关注节点 a 的父节点 b、叔叔节点 d 的颜色都设置成黑色;
将关注节点 a 的祖父节点 c 的颜色设置成红色;
关注节点变成 a 的祖父节点 c;
跳到 CASE 2 或者 CASE 3。

CASE 2:如果关注节点是 a,它的叔叔节点 d 是黑色,关注节点 a 是其父节点 b 的右子节点,我们就依次执行下面的操作:统一把红色节点调整到左侧
关注节点变成节点 a 的父节点 b;
围绕新的关注节点 b 左旋;
跳到 CASE 3。

CASE 3:如果关注节点是 a,它的叔叔节点 d 是黑色,关注节点 a 是其父节点 b 的左子节点,我们就依次执行下面的操作:
围绕关注节点 a 的祖父节点 c 右旋;
将关注节点 a 的父节点 b、兄弟节点 c 的颜色互换。调整结束。

红黑树的删除
CASE 1:如果要删除的节点是 a,它只有一个子节点 b,那我们就依次进行下面的操作:
删除节点 a,并且把节点 b 替换到节点 a 的位置,这一部分操作跟普通的二叉查找树的删除操作一样;
节点 a 只能是黑色,节点 b 也只能是红色,其他情况均不符合红黑树的定义。
这种情况下,我们把节点 b 改为黑色;
调整结束,不需要进行二次调整。

CASE 2:如果要删除的节点 a 有两个非空子节点,并且它的后继节点就是节点 a 的右子节点 c。我们就依次进行下面的操作:
如果节点 a 的后继节点就是右子节点 c,那右子节点 c 肯定没有左子树。我们把节点 a 删除,并且将节点 c 替换到节点 a 的位置。这一部分操作跟普通的二叉查找树的删除操作无异;
然后把节点 c 的颜色设置为跟节点 a 相同的颜色;
如果节点 c 是黑色,为了不违反红黑树的最后一条定义,我们给节点 c 的右子节点 d 多加一个黑色,这个时候节点 d 就成了“红 - 黑”或者“黑 - 黑”;
这个时候,关注节点变成了节点 d,第二步的调整操作就会针对关注节点来做。

CASE 3:如果要删除的是节点 a,它有两个非空子节点,并且节点 a 的后继节点不是右子节点,我们就依次进行下面的操作:
- 找到后继节点 d,并将它删除,删除后继节点 d 的过程参照 CASE 1;
- 将节点 a 替换成后继节点 d;
- 把节点 d 的颜色设置为跟节点 a 相同的颜色;
- 如果节点 d 是黑色,为了不违反红黑树的最后一条定义,我们给节点 d 的右子节点 c 多加一个黑色,这个时候节点 c 就成了“红 - 黑”或者“黑 - 黑”;
- 这个时候,关注节点变成了节点 c,第二步的调整操作就会针对关注节点来做。
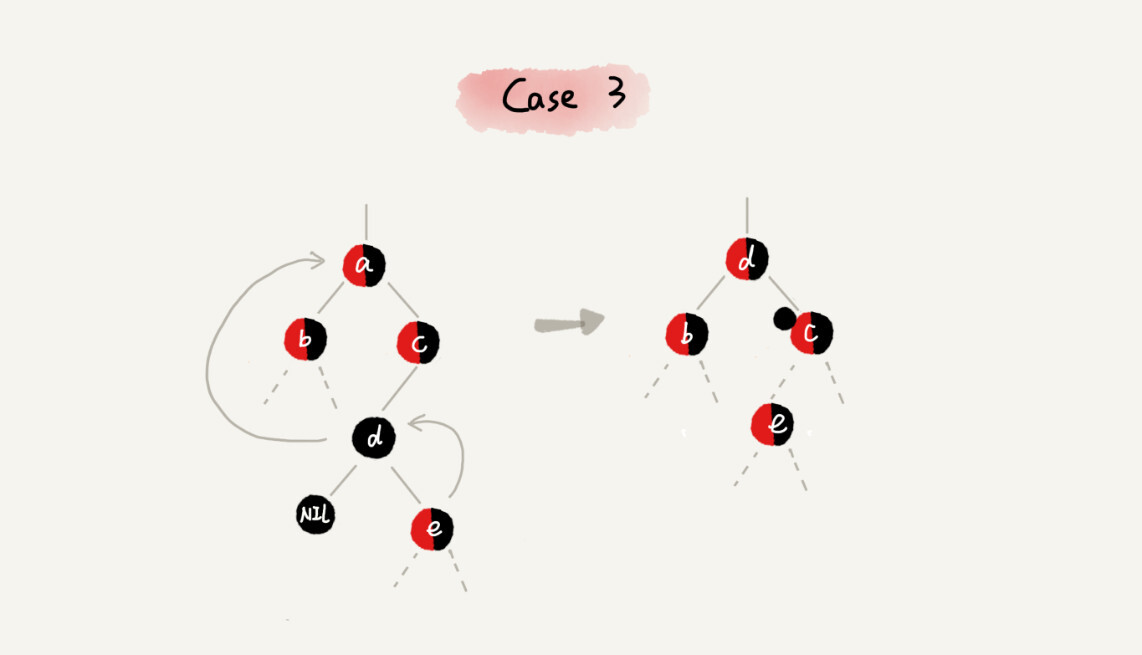
CASE 1:如果关注节点是 a,它的兄弟节点 c 是红色的,我们就依次进行下面的操作:
(红-黑-黑 左-换)
围绕关注节点 a 的父节点 b 左旋;
关注节点 a 的父节点 b 和祖父节点 c 交换颜色;
关注节点不变;
继续从四种情况中选择适合的规则来调整。

CASE 2:如果关注节点是 a,它的兄弟节点 c 是黑色的,并且节点 c 的左右子节点 d、e 都是黑色的,我们就依次进行下面的操作:
(黑-黑-黑 减一个加一个)
将关注节点 a 的兄弟节点 c 的颜色变成红色;
从关注节点 a 中去掉一个黑色,这个时候节点 a 就是单纯的红色或者黑色;
给关注节点 a 的父节点 b 添加一个黑色,这个时候节点 b 就变成了“红 - 黑”或者“黑 - 黑”;
关注节点从 a 变成其父节点 b;
继续从四种情况中选择符合的规则来调整。

CASE 3:如果关注节点是 a,它的兄弟节点 c 是黑色,c 的左子节点 d 是红色,c 的右子节点 e 是黑色,我们就依次进行下面的操作:
(黑-红-黑 右-换)
围绕关注节点 a 的兄弟节点 c 右旋;
节点 c 和节点 d 交换颜色;
关注节点不变;
跳转到 CASE 4,继续调整。

CASE 4:如果关注节点 a 的兄弟节点 c 是黑色的,并且 c 的右子节点是红色的,我们就依次进行下面的操作:
(黑-x-红 父左-去-换-染)
围绕关注节点 a 的父节点 b 左旋;
将关注节点 a 的兄弟节点 c 的颜色,跟关注节点 a 的父节点 b 设置成相同的颜色;
将关注节点 a 的父节点 b 的颜色设置为黑色;
从关注节点 a 中去掉一个黑色,节点 a 就变成了单纯的红色或者黑色;
将关注节点 a 的叔叔节点 e 设置为黑色;调整结束

1. 两数之和 - 力扣(LeetCode)
思想:空间换时间。N^-->N
49. 字母异位词分组 - 力扣(LeetCode)
思想:不同中的相同(排序后,字符串一样)。
128. 最长连续序列 - 力扣(LeetCode)
思想:暴力 -- 哈希(空间换时间)-- 裁剪
双指针
283. 移动零 - 力扣(LeetCode)
思路:拷贝非0,再补0
11. 盛最多水的容器 - 力扣(LeetCode)
思路:求容量、移动最差的那一边
15. 三数之和 - 力扣(LeetCode)
思路:当我们需要枚举两个元素,一个递增,一个递减 -- 双指针
27. 移除元素 - 力扣(LeetCode)
思路:一个指针操作要被赋值的数,一个指针遍历数组
滑动窗口
3. 无重复字符的最长子串 - 力扣(LeetCode)
数据结构:哈希集合
思路:移动右指针直到不能移动,再移动左指针
438. 找到字符串中所有字母异位词 - 力扣(LeetCode)
数据结构:哈希map
思路:窗口 + 频率表
560. 和为 K 的子数组 - 力扣(LeetCode)
数据结构:哈希map

思路:以 i 结尾 和为 k 的子问题 是 以 j - 1 结尾 和为 pre[i] - k
链表
常见考法:
1.找中点:快慢指针
2.翻转:pre cur
3.合并:
4.找环
206. 反转链表 - 力扣(LeetCode)
思路:prev储存head前的节点,next 储存head后面的节点
141. 环形链表 - 力扣(LeetCode)
思路:快慢指针。链表长度、快指针何时移动?
142. 环形链表 II - 力扣(LeetCode)
思路:哈希表统计是否遍历过
23. 合并 K 个升序链表 - 力扣(LeetCode)
思路:归并
876. 链表的中间结点 - 力扣(LeetCode)
143. 重排链表 - 力扣(LeetCode)lls
146. LRU 缓存 - 力扣(LeetCode)
// 定义双向链表节点结构
struct DLinkedNode {int value;int key;DLinkedNode* prev; // 指向前一个节点DLinkedNode* next; // 指向后一个节点DLinkedNode(): key(0), value(0), prev(nullptr), next(nullptr) {};DLinkedNode(int _key, int _value): key(_key), value(_value), prev(nullptr), next(nullptr) {};
};// 实现LRU缓存类
class LRUCache {
private:unordered_map<int, DLinkedNode*> cache; // 存储键值对和对应的双向链表节点int capacity; // 缓存容量int size; // 当前缓存大小DLinkedNode* head; // 链表头节点,不存储实际数据DLinkedNode* tail; // 链表尾节点,不存储实际数据public:// 构造函数LRUCache(int _capacity): capacity(_capacity), size(0) {head = new DLinkedNode(); // 初始化链表头tail = new DLinkedNode(); // 初始化链表尾head->next = tail; // 头节点指向尾节点tail->prev = head; // 尾节点指向头节点}// 获取缓存中键对应的值int get(int key) {if (!cache.count(key)) { // 若缓存中没有该键,返回 -1return -1;}DLinkedNode* node = cache[key]; // 获取对应的链表节点moveToHead(node); // 将该节点移动到链表头部,表示最近使用return node->value; // 返回节点值}// 向缓存中插入键值对void put(int key, int value) {if (!cache.count(key)) { // 如果缓存中没有该键DLinkedNode* node = new DLinkedNode(key, value); // 创建新的链表节点cache[key] = node; // 在缓存中存储该节点addToHead(node); // 将节点插入到链表头部size++; // 增加缓存大小if (size > capacity) { // 若缓存大小超过容量DLinkedNode* removed = removeTail(); // 移除链表尾部的节点,即最久未使用的cache.erase(removed->key); // 从缓存中移除对应的键delete removed; // 释放被移除的节点内存size--; // 减少缓存大小}} else { // 如果缓存中已经有该键DLinkedNode* node = cache[key]; // 获取对应的链表节点node->value = value; // 更新节点值moveToHead(node); // 将节点移动到链表头部,表示最近使用}}// 将节点插入到链表头部void addToHead(DLinkedNode* node) {node->prev = head; // 新节点的前一个节点是头节点node->next = head->next; // 新节点的后一个节点是原头节点的后一个节点head->next->prev = node; // 原头节点的前一个节点是新节点head->next = node; // 头节点的后一个节点是新节点}// 移除链表中的某个节点void removeNode(DLinkedNode* node) {node->prev->next = node->next; // 调整前一个节点的 next 指针node->next->prev = node->prev; // 调整后一个节点的 prev 指针}// 将节点移动到链表头部void moveToHead(DLinkedNode* node) {removeNode(node); // 先移除节点addToHead(node); // 然后将节点插入到链表头部}// 移除链表尾部的节点,并返回该节点DLinkedNode* removeTail() {DLinkedNode* node = tail->prev; // 获取尾节点的前一个节点removeNode(node); // 移除该节点return node; // 返回被移除的节点}};
动态规划
1049. 最后一块石头的重量 II - 力扣(LeetCode)lls
70. 爬楼梯 - 力扣(LeetCode)
二叉树
二叉搜索树
二叉查找树最大的特点就是,支持动态数据集合的快速插入、删除、查找操作。
散列表也是支持这些操作的,并且散列表的这些操作比二叉查找树更高效,时间复杂度是 O(1)。
既然有了这么高效的散列表,**使用二叉树的地方是不是都可以替换成散列表呢?有没有哪些地方是散列表做不了,必须要用二叉树来做的呢?**
Def:
二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值。
如果需要支持重复数据,则统一存储在右节点。
平衡二叉查找树的高度接近 logn,所以插入、删除、查找操作的时间复杂度也比较稳定,是 O(logn)。
#include <iostream>
#include <vector>
using namespace std;// 二叉树的节点结构体
struct node {int data; // 数据域 node* lchild; // 指针域:左孩子node* rchild; // 指针域:右孩子
};// 创建新节点
node* newNode(int v) {node* Node = new node;Node->data = v;Node->lchild = Node->rchild = nullptr;return Node;
}// 二叉查找树的查找操作
bool search(node* root, const int& val) {if (root == nullptr) return false;if (root->data == val) return true;else if (root->data > val) {return search(root->lchild, val); // 修正:返回递归结果}else {return search(root->rchild, val); // 修正:返回递归结果}
}// 二叉查找树的插入操作
void insert(node*& root, const int& val) { // 修正:传入引用if (root == nullptr) {root = newNode(val);return;}if (root->data == val) {return; // 已经有相同的值}else if (root->data > val) {insert(root->lchild, val);}else {insert(root->rchild, val);}
}// 二叉查找树的建立
node* create(vector<int>& data) {node* root = nullptr;for (auto& iter : data) {insert(root, iter);}return root;
}// 二叉查找树的删除
/*为保证删除某一个节点之后仍然为一个二叉查找树,一种方法是,找到删除节点的左子树中的最大值,替换掉删除的节点另一种方法是,找到删除节点的右子树中的最小值,替换掉删除的节点替换的方法是进行删除节点的递归操作
*/// 传入的是左孩子节点,找到左子树中的最大值,
node * GetLeftMax(node * root) {while (root != nullptr) {root = root->rchild;}return root;
}// 传入的是右孩子节点,找到右子树中的最小值,
node* GetRightMin(node* root) {while (root != nullptr) {root = root->lchild;}return root;
}// 二叉查找树的删除操作
void deleteNode(node*& root, int& val) {if (root == nullptr) return;if (root->data > val) {deleteNode(root->lchild, val);}else if (root->data < val) {deleteNode(root->rchild, val);}else {if (root->lchild == nullptr && root->rchild == nullptr) {delete root; // 释放内存root = nullptr; // 指针置空}else if (root->lchild != nullptr) {node* pre = GetLeftMax(root->lchild);root->data = pre->data; // 使用前驱节点替换要删除的节点deleteNode(root->lchild, pre->data); // 递归删除掉替换的节点}else if (root->rchild != nullptr) {node* post = GetRightMin(root->rchild);root->data = post->data; // 使用后继节点替换要删除的节点deleteNode(root->rchild, post->data); // 递归删除掉替换的节点}}
}int main() {vector<int> data = { 5, 3, 8, 2, 4, 7, 9 };node* root = create(data);// 测试搜索操作cout << "Search 7: " << (search(root, 7) ? "Found" : "Not found") << endl;cout << "Search 6: " << (search(root, 6) ? "Found" : "Not found") << endl;// 释放树的内存//destroy(root);return 0;
}堆
手写最大堆,说明插入、弹出操作

#include <iostream>
#include <vector>
#include <algorithm> // 包含算法头文件
using namespace std;class MaxHeap {
private:vector<int> heapArr;
public:// 构造函数,用传入的数组创建最大堆MaxHeap(int elements[], int number) {heapArr.push_back(0); // 在堆数组开头添加一个哑节点for (int i = 1; i < number + 1; i++) {heapArr.push_back(elements[i - 1]); // 将传入的数据存入堆数组中}// 从最后一个非叶节点开始,逐步将数组调整为最大堆for (int i = heapArr.size() / 2; i >= 1; i--) {down(i);}}// 向最大堆中添加元素void push(int p) {heapArr.push_back(p);up(heapArr.size() - 1);}// 弹出最大元素并重新调整堆int pop() {int res = heapArr[1]; // 最大元素在堆顶swap(heapArr[1], heapArr[heapArr.size() - 1]); // 将堆顶与最后一个元素交换heapArr.pop_back(); // 弹出最后一个元素down(1); // 调整堆return res;}// 向下调整,维持最大堆的性质void down(int i) {while (true) {int son1 = 2 * i, son2 = 2 * i + 1;int maxPos = i;if (son1 <= heapArr.size() - 1 && heapArr[son1] > heapArr[i]) {maxPos = son1;}if (son2 <= heapArr.size() - 1 && heapArr[son2] > heapArr[maxPos]) {maxPos = son2; // 将 heapArr[son1] 修改为 heapArr[son2]}if (maxPos == i) break; // 如果当前位置是最大位置,停止调整swap(heapArr[i], heapArr[maxPos]); // 交换当前位置与最大位置的元素i = maxPos; // 继续向下调整}}// 向上调整,维持最大堆的性质void up(int i) {int fa = i / 2;if (i > 1 && heapArr[i] > heapArr[fa]) {swap(heapArr[i], heapArr[fa]); // 如果当前位置的元素大于父节点,交换它们up(fa); // 继续向上调整}}// 显示最大堆中的元素void show() {for (int i = 1; i < heapArr.size(); i++) {cout << " " << heapArr[i];}cout << endl;}
};int main() {int a[] = { 4, 1, 3, 2, 16, 9, 10, 14, 8, 7 };MaxHeap* m = new MaxHeap(a, int(sizeof(a) / sizeof(int))); // 创建最大堆对象并初始化cout << "初始最大堆:" << endl;m->show();cout << "弹出最大元素:" << m->pop() << endl;cout << "调整后的最大堆:" << endl;m->show();m->push(90); // 向最大堆中插入元素cout << "插入元素后的最大堆:" << endl;m->show();return 0;
}
https://blog.csdn.net/weixin_42653023/article/details/123502436