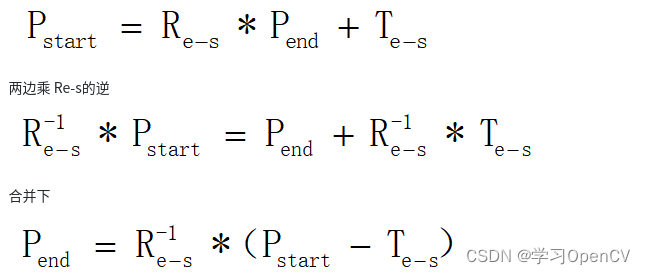全局向量的词嵌入(GloVe)
全局向量的词嵌入(Global Vectors for Word Representation),通常简称为GloVe,是一种用于将词语映射到连续向量空间的词嵌入方法。它旨在捕捉词语之间的语义关系和语法关系,以便在自然语言处理任务中能够更好地表示词语的语义信息。
GloVe的设计基于两个观察结果:共现矩阵(co-occurrence matrix)和词向量的线性关系。共现矩阵记录了词语之间在上下文中的共现频率,即它们在一定窗口大小内同时出现的次数。GloVe利用这个共现矩阵来计算词语之间的相似性,并通过优化目标函数来得到词向量。
GloVe的核心思想是将词语的向量表示表示为两个词向量的差异,这两个词向量分别表示词语在共现矩阵中的位置信息和语义信息。通过对这两个向量的点积操作,可以得到词语之间的共现概率。GloVe的优化目标是最小化预测共现概率和实际共现概率之间的误差。
与其他词嵌入方法(如Word2Vec)相比,GloVe具有一些优势。它在语义和语法任务上表现良好,并且能够更好地捕捉到词语之间的线性关系。此外,GloVe的训练过程相对简单,并且能够在大规模语料库上进行高效训练。
上下文窗口内的词共现可以携带丰富的语义信息。例如,在一个大型语料库中,“固体”比“气体”更有可能与“冰”共现,但“气体”一词与“蒸汽”的共现频率可能比与“冰”的共现频率更高。此外,可以预先计算此类共现的全局语料库统计数据:这可以提高训练效率。为了利用整个语料库中的统计信息进行词嵌入,让我们首先回顾上一节中的跳元模型,但是使用全局语料库统计(如共现计数)来解释它。
文章内容来自李沐大神的《动手学深度学习》并加以我的理解,感兴趣可以去https://zh-v2.d2l.ai/查看完整书籍
文章目录
- 全局向量的词嵌入(GloVe)
- 带全局语料统计的跳元模型
- GloVe模型
- 从条件概率比值理解GloVe模型
- GloVe和word2vec的区别
带全局语料统计的跳元模型
用 q i j q_{ij} qij表示词 w j w_j wj的条件概率P(w_j|w_i),在跳元模型中给定词 w i w_i wi,我们有:
q i j = e x p ( u j T v i ) ∑ k ∈ V e x p ( u k T v i ) q_{ij}=\frac{exp(u_j^Tv_i)}{\sum_{k\in V}exp(u_k^{T}v_i)} qij=∑k∈Vexp(ukTvi)exp(ujTvi)
其中,对于任意索引 i i i,向量 v i v_i vi和 u i u_i ui分别表示词 w i w_i wi作为中心词和上下文词,且 V = { 0 , 1 , . . . , ∣ V ∣ − 1 } V=\{0,1,...,|V|-1\} V={0,1,...,∣V∣−1}是词表的索引集。
考虑词 w i w_i wi可能在语料库中出现多次。在整个语料库中,所有以 w i w_i wi为中心词的上下文词形成一个词索引的多重集 C i C_i Ci,该索引允许同一元素的多个实例。对于任何元素,其实例数称为其重数。举例说明,假设词 w i w_i wi在语料库中出现两次,并且在两个上下文窗口中以 w i w_i wi为其中心词的上下文词索引是 k , j , m , k k,j,m,k k,j,m,k和 k , l , k . j k,l,k.j k,l,k.j。因此,多重集 C i = { j , j , k , k , k , k , l , m } C_i=\{j,j,k,k,k,k,l,m\} Ci={j,j,k,k,k,k,l,m},其中元素 j , k , l , m j,k,l,m j,k,l,m的重数分别为2、4、1、1。
现在,让我们将多重集 C i C_i Ci中的元素 j j j的重数表示为 x i j x_{ij} xij。这是词 w j w_j wj(作为上下文词)和词 w i w_i wi(作为中心词)在整个语料库的同一上下文窗口中的全局共现计数。使用这样的全局语料库统计,跳元模型的损失函数等价于:
− ∑ i ∈ V ∑ j ∈ V x i j l o g q i j -\sum_{i\in V}\sum_{j\in V}x_{ij}logq_{ij} −i∈V∑j∈V∑xijlogqij
我们用 x i x_i xi表示上下文窗口中的所有上下文词的数量,其中 w i w_i wi作为它们的中心词出现,这相当于 ∣ C i ∣ |C_i| ∣Ci∣。设 p i j p_{ij} pij为用于生成上下文词 w j w_j wj的条件概率 x i j / x i x_{ij}/x_i xij/xi。给定中心词 w i w_i wi, 上式可以重写为:
− ∑ i ∈ V x i ∑ j ∈ V p i j l o g q i j -\sum_{i\in V}x_{i}\sum_{j\in V}p_{ij}log\ q_{ij} −i∈V∑xij∈V∑pijlog qij
在上式中, − ∑ j ∈ V x i j l o g q i j -\sum_{j\in V}x_{ij}log\ q_{ij} −∑j∈Vxijlog qij计算全局语料统计的条件分布 p i j p_{ij} pij和模型预测的条件分布 q i j q_{ij} qij的交叉熵。如上所述,这一损失也按 x i x_i xi加权。在式中最小化损失函数将使预测的条件分布接近全局语料库统计中的条件分布。
虽然交叉熵损失函数通常用于测量概率分布之间的距离,但在这里可能不是一个好的选择。一方面,规范化 q i j q_{ij} qij的代价在于整个词表的求和,这在计算上可能非常昂贵。另一方面,来自大型语料库的大量罕见事件往往被交叉熵损失建模,从而赋予过多的权重。
GloVe模型
有鉴于此,GloVe模型基于平方损失 (Pennington et al., 2014)对跳元模型做了三个修改:
- 使用 p i j ′ = x i j p'_{ij}=x_{ij} pij′=xij和 q i j ′ = e x p ( u j T v i ) q'_{ij}=exp(u_j^Tv_i) qij′=exp(ujTvi)而非概率分布,并取两者的对数,所以平方损失项是
( l o g p i j ′ − l o g q i j ′ ) 2 = ( u j T v i + b i + c j − l o g x i j ) 2 (log\ p'_{ij}-log\ q_{ij}')^2=(u_j^Tv_i+b_i+c_j-log \ x_{ij})^2 (log pij′−log qij′)2=(ujTvi+bi+cj−log xij)2 - 为每个词 w i w_i wi添加两个标量模型参数:中心词偏置 b i b_i bi和上下文词偏置 c i c_i ci
- 用权重函数 h ( x i j ) h(x_{ij}) h(xij)替换每个损失项的权重,其中 h ( x ) h(x) h(x)在 [ 0 , 1 ] [0,1] [0,1]的间隔内递增。
整合代码,训练GloVe是为了尽量降低以下损失函数:
∑ i ∈ V ∑ j ∈ V h ( x i j ) ( u j T v i + b i + c j − l o g x i j ) 2 \sum_{i\in V}\sum_{j\in V}h(x_{ij})(u_j^Tv_i+b_i+c_j-log\ x_{ij})^2 i∈V∑j∈V∑h(xij)(ujTvi+bi+cj−log xij)2
对于权重函数,建议的选择是:当 x < c x<c x<c(例如, c = 100 c=100 c=100)时, h ( x ) = ( x / c ) α h(x)=(x/c)^\alpha h(x)=(x/c)α(例如 α = 0.75 \alpha=0.75 α=0.75);否则 h ( x ) = 1 h(x)=1 h(x)=1。在这种情况下,由于 h ( x ) = 1 h(x)=1 h(x)=1,为了提高计算效率,可以省略任意 x i j = 0 x_{ij}=0 xij=0的平方损失项。例如,当使用小批量随机梯度下降进行训练时,在每次迭代中,我们随机抽样一小批量非零的 x i j x_{ij} xij来计算梯度并更新模型参数。注意,这些非零的 x i j x_{ij} xij是预先计算的全局语料库统计数据;因此,该模型GloVe被称为全局向量。
该强调的是,当词 w i w_i wi出现在词 w j w_j wj的上下文窗口时,词 w j w_j wj也出现在词 w i w_i wi的上下文窗口。因此, x i j = x j i x_{ij}=x_{ji} xij=xji。与拟合非对称条件概率 p i j p_{ij} pij的word2vec不同,GloVe拟合对称概率 l o g x i j log\ x_{ij} log xij。因此,在GloVe模型中,任意词的中心词向量和上下文词向量在数学上是等价的。但在实际应用中,由于初始值不同,同一个词经过训练后,在这两个向量中可能得到不同的值:GloVe将它们相加作为输出向量。
从条件概率比值理解GloVe模型
我们也可以从另一个角度来理解GloVe模型。设 p i j = P ( w j ∣ w i ) p_{ij}=P(w_j|w_i) pij=P(wj∣wi)为生成上下文词 w j w_j wj的条件概率,给定
作为语料库中的中心词。 tab_glove根据大量语料库的统计数据,列出了给定单词“ice”和“steam”的共现概率及其比值。
大型语料库中的词-词共现概率及其比值(根据 (Pennington et al., 2014)中的表1改编)
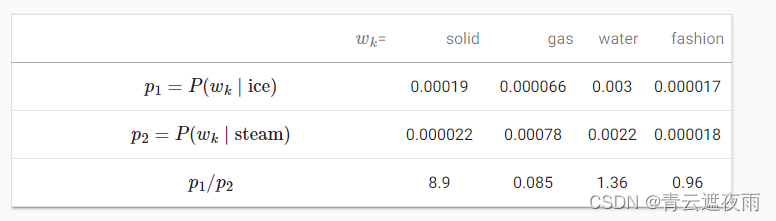
从 tab_glove中,我们可以观察到以下几点:
- 对于与“ice”相关但与“steam”无关的单词 w k w_k wk,例如 w k = s o l i d w_k=solid wk=solid,我们预计会有更大的共现概率比值,例如8.9。
- 对于与“steam”相关但与“ice”无关的单词 w k w_k wk,例如 w k = g a s w_k=gas wk=gas,我们预计较小的共现概率比值,例如0.085。
- 对于同时与“ice”和“steam”相关的单词 w k w_k wk,例如 w k = w a t e r w_k=water wk=water,我们预计其共现概率的比值接近1,例如1.36。
- 对于与“ice”和“steam”都不相关的单词,例如 w k = f a s h i o n w_k=fashion wk=fashion,我们预计共现概率的比值接近1,例如0.96.
由此可见,共现概率的比值能够直观地表达词与词之间的关系。因此,我们可以设计三个词向量的函数来拟合这个比值。对于共现概率 p i j / p i k p_{ij}/p_{ik} pij/pik的比值,其中 w i w_i wi是中心词, w j w_j wj和 w k w_k wk是上下文词,我们希望使用某个函数 f f f来拟合该比值:
f ( u j , u k , v i ) ≈ p i j p i k f(u_j,u_k,v_i)\approx \frac{p_{ij}}{p_{ik}} f(uj,uk,vi)≈pikpij
在 f f f的许多可能的设计中,我们只在以下几点中选择了一个合理的选择。因为共现概率的比值是标量,所以我们要求 f f f是标量函数,例如 f ( u j , u k , v i ) = f ( ( u j − u k ) T v i ) f(u_j,u_k,v_i)=f((u_j-u_k)^Tv_i) f(uj,uk,vi)=f((uj−uk)Tvi)。在 上述式中交换词索引 j j j和 k k k,它必须保持 f ( x ) f ( − x ) = 1 f(x)f(-x)=1 f(x)f(−x)=1,所以一种可能性是 f ( x ) = e x p ( x ) f(x)=exp(x) f(x)=exp(x),即:

现在让我们选择 e x p ( u j T v i ) ≈ α p i j exp(u_j^Tv_i)\approx\alpha p_{ij} exp(ujTvi)≈αpij,其中 α \alpha α是常数。从 p i j = x i j p_{ij}=x_{ij} pij=xij开始,取两边的对数得到 u i T v i ≈ l o g α + l o g x i j − l o g x i u_i^Tv_i\approx log\alpha+logx_{ij}-logx_{i} uiTvi≈logα+logxij−logxi。我们可以使用附加的偏置项来拟合 − l o g α + l o g x i -log\ \alpha+log x_i −log α+logxi,如中心词偏置 b i b_i bi和上下文词偏置 c j c_j cj,得到:

此时我们便得到了全局向量的词嵌入的损失函数
GloVe和word2vec的区别
GloVe(Global Vectors for Word Representation)和word2vec都是用于自然语言处理中的词向量表示方法,它们之间有一些区别:
-
构建方式:GloVe是基于全局词频统计的方法,它使用了全局的统计信息来学习词向量。而word2vec是基于局部上下文窗口的方法,它通过预测上下文词来学习词向量。
-
训练效果:GloVe在一些语义和语法任务上表现较好,尤其是在类比推理任务上。它能够捕捉到词之间的线性关系。而word2vec在一些语法任务上表现较好,尤其是在词类比和词性推断任务上。它能够捕捉到词之间的局部上下文信息。
-
算法原理:GloVe使用了共现矩阵来建模词之间的关系,通过最小化词向量之间的欧氏距离和词频之间的关系来训练词向量。word2vec使用了两种不同的算法:Skip-gram和CBOW(Continuous Bag-of-Words)。Skip-gram模型通过目标词预测上下文词,而CBOW模型通过上下文词预测目标词。
-
训练速度:一般情况下,GloVe的训练速度比word2vec要快,因为它使用了全局信息进行训练,可以并行处理。
选择使用GloVe还是word2vec取决于具体的任务和需求。它们在不同的语义和语法任务上可能表现不同,因此在应用中需要根据实际情况进行选择。