import torch
from torch import nn
import torch.functional as F
import mathX = torch.randn(16,64,512) # B,T,Dd_model = 512 # 模型的维度
n_head = 8 # 注意力头的数量
多头注意力机制
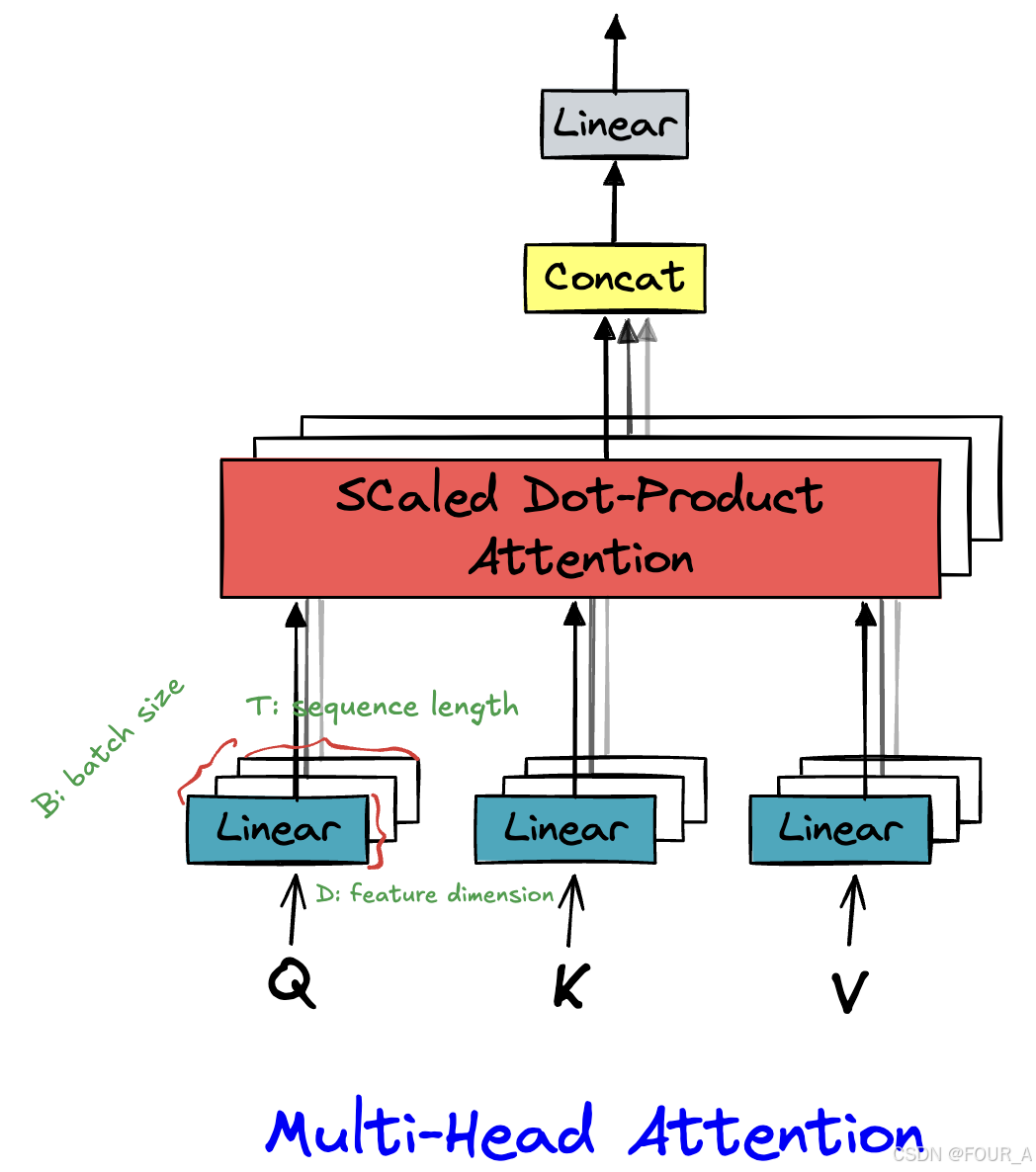
class multi_head_attention(nn.Module): def __init__(self, d_model, n_head): # 调用父类构造函数 super(multi_head_attention, self).__init__() # 保存注意力头的数量和模型的维度 self.n_head = n_head self.d_model = d_model # 定义查询(Q)、键(K)、值(V)的线性变换层 self.w_q = nn.Linear(d_model, d_model) # 输入d_model维度,输出d_model维度 self.w_k = nn.Linear(d_model, d_model) # 输入d_model维度,输出d_model维度 self.w_v = nn.Linear(d_model, d_model) # 输入d_model维度,输出d_model维度 self.w_o = nn.Linear(d_model, d_model) # 输出线性变换层,用来做一个线形缩放 # 定义softmax函数,用于计算注意力得分的归一化 self.softmax = nn.Softmax(dim=-1) # softmax会在最后一维(dim=-1)上操作 def forward(self, q, k, v): # 获取输入查询(q),键(k),值(v)的形状 B, T, D = q.shape # B: batch size, T: sequence length, D: feature dimension (d_model) # 每个注意力头的维度 n_d = self.d_model // self.n_head # 每个头的维度(d_model / n_head) # 将输入的q、k、v通过各自的线性变换层映射到新的空间 q, k, v = self.w_q(q), self.w_k(k), self.w_v(v) # 将q, k, v 按头数进行拆分(reshape),并转置使得各头的计算可以并行 # q, k, v的形状变为 (B, T, n_head, n_d),然后转置变为 (B, n_head, T, n_d) q = q.view(B, T, self.n_head, n_d).transpose(1, 2) # (B, n_head, T, n_d) k = k.view(B, T, self.n_head, n_d).transpose(1, 2) # (B, n_head, T, n_d) v = v.view(B, T, self.n_head, n_d).transpose(1, 2) # (B, n_head, T, n_d) # 计算缩放点积注意力(scaled dot-product attention) score = q @ k.transpose(2, 3) / math.sqrt(n_d) # (B, n_head, T, T) # score是查询q与键k之间的相似度矩阵,进行缩放以防止数值过大 # 生成一个下三角矩阵,用于实现自注意力中的"masking",屏蔽未来的信息 mask = torch.tril(torch.ones(T, T, dtype=bool)) # 生成一个下三角的布尔矩阵 # 使用mask进行屏蔽,mask为0的位置会被填充为一个非常大的负值(-10000) score = score.masked_fill(mask == 0, -10000) # 把mask == 0的位置置为-10000 # 对score进行softmax归一化处理,得到注意力权重 score = self.softmax(score) # (B, n_head, T, T) # 将注意力权重与值(v)相乘,得到加权后的值 score = score @ v # (B, n_head, T, n_d) # 将多个头的结果合并(concatenate),并通过线性层进行映射 # 首先将score的维度变为 (B, T, n_head * n_d),然后通过w_o进行线性变换 x_concate = score.transpose(1, 2).contiguous().view(B, T, self.d_model) # (B, T, d_model) x_output = self.w_o(x_concate) # (B, T, d_model) # 返回最终的输出 return x_output attn = multi_head_attention(d_model, n_head)
Y = attn(X,X,X)
print(Y.shape)
层归一化
# layer norm
class layer_norm(nn.Module): def __init__(self, d_model, eps = 1e-12): super(layer_norm, self).__init__() self.gamma = nn.Parameter(torch.ones(d_model)) self.beta = nn.Parameter(torch.zeros(d_model)) self.eps = eps def forward(self, x): mean = x.mean(-1, keepdim = True) var = x.var(-1, unbiased=False, keepdim = True) out = (x - mean) / torch.sqrt(var + self.eps) out = self.gamma * out + self.beta return out d_model = 512
X = torch.randn(2,5,512) # 2句话, 5个token,词向量512
ln = layer_norm(d_model)
print("d_model: ", d_model)
print(f"ln gamma: {ln.gamma.shape}")
print(f"ln beta: {ln.beta.shape}")
Y_ln = ln(X)
print(Y_ln.shape)
这段代码实现了一个多头注意力机制(Multi-Head Attention),这是Transformer模型中的核心组件之一。多头注意力机制允许模型在处理序列数据时,同时关注序列中不同位置的信息,并且可以从不同的子空间中学习到不同的特征表示。
层归一化
代码解读
1. 初始化部分 (__init__ 方法)
def __init__(self, d_model, n_head):super(multi_head_attention, self).__init__()self.n_head = n_headself.d_model = d_modelself.w_q = nn.Linear(d_model, d_model)self.w_k = nn.Linear(d_model, d_model)self.w_v = nn.Linear(d_model, d_model)self.w_o = nn.Linear(d_model, d_model)self.softmax = nn.Softmax(dim=-1)
d_model:模型的维度,即输入向量的维度。n_head:注意力头的数量。w_q,w_k,w_v:分别是对查询(Query)、键(Key)、值(Value)进行线性变换的层,将输入映射到新的空间。w_o:输出线性变换层,用于将多个头的输出合并并映射回原始维度。softmax:用于对注意力得分进行归一化。
2. 前向传播部分 (forward 方法)
def forward(self, q, k, v):B, T, D = q.shapen_d = self.d_model // self.n_headq, k, v = self.w_q(q), self.w_k(k), self.w_v(v)q = q.view(B, T, self.n_head, n_d).transpose(1, 2)k = k.view(B, T, self.n_head, n_d).transpose(1, 2)v = v.view(B, T, self.n_head, n_d).transpose(1, 2)
B:批量大小(batch size)。T:序列长度(sequence length)。D:特征维度(feature dimension),即d_model。n_d:每个注意力头的维度,等于d_model / n_head。q,k,v:通过线性变换层映射到新的空间后,再按头数进行拆分和转置,以便并行计算。- [[q = q.view(B, T, self.n_head, n_d).transpose(1, 2)]]
score = q @ k.transpose(2, 3) / math.sqrt(n_d)mask = torch.tril(torch.ones(T, T, dtype=bool))score = score.masked_fill(mask == 0, -10000)score = self.softmax(score)
score:计算查询q和键k之间的相似度矩阵,并进行缩放(防止数值过大)。mask:生成一个下三角矩阵,用于屏蔽未来的信息(在自注意力机制中,当前时间步只能看到之前的时间步)。score:通过mask屏蔽未来的信息,并对得分进行softmax归一化,得到注意力权重。- [[mask = torch.tril(torch.ones(T, T, dtype=bool))]]
score = score @ vx_concate = score.transpose(1, 2).contiguous().view(B, T, self.d_model)x_output = self.w_o(x_concate)return x_output
score @ v:将注意力权重与值v相乘,得到加权后的值。x_concate:将多个头的输出合并(concatenate),并通过w_o进行线性变换,得到最终的输出。- [[x_concate = score.transpose(1, 2).contiguous().view(B, T, self.d_model)]]
3. 使用示例
attn = multi_head_attention(d_model, n_head)
Y = attn(X, X, X)
print(Y.shape)
attn:创建一个多头注意力机制的实例。Y = attn(X, X, X):将输入X分别作为查询、键、值传入多头注意力机制,得到输出Y。print(Y.shape):输出Y的形状,通常与输入X的形状相同,即(B, T, d_model)。
总结
这段代码实现了一个完整的多头注意力机制,包括线性变换、缩放点积注意力、掩码处理、softmax归一化、多头结果的合并和最终的线性变换。多头注意力机制是Transformer模型的核心组件,广泛应用于自然语言处理、计算机视觉等领域。
这段代码实现了一个层归一化(Layer Normalization)模块
层归一化是深度学习中常用的一种归一化技术,用于稳定训练过程并加速收敛。
1. 初始化部分 (__init__ 方法)
def __init__(self, d_model, eps=1e-12):super(layer_norm, self).__init__()self.gamma = nn.Parameter(torch.ones(d_model))self.beta = nn.Parameter(torch.zeros(d_model))self.eps = eps
d_model:输入特征的维度(即词向量的维度)。gamma和beta:gamma是可学习的缩放参数,初始值为全1,形状为(d_model,)。beta是可学习的偏移参数,初始值为全0,形状为(d_model,)。- 这两个参数用于对归一化后的数据进行缩放和偏移,以增强模型的表达能力。
eps:一个小常数,用于防止分母为零的情况,通常设置为1e-12。
2. 前向传播部分 (forward 方法)
def forward(self, x):mean = x.mean(-1, keepdim=True)var = x.var(-1, unbiased=False, keepdim=True)out = (x - mean) / torch.sqrt(var + self.eps)out = self.gamma * out + self.betareturn out
-
输入
x:假设x的形状为(B, T, d_model),其中:B是批量大小(batch size)。T是序列长度(sequence length)。d_model是特征维度(即词向量的维度)。
-
步骤 1:计算均值和方差:
mean = x.mean(-1, keepdim=True):沿着最后一个维度(d_model)计算均值,形状为(B, T, 1)。var = x.var(-1, unbiased=False, keepdim=True):沿着最后一个维度计算方差,形状为(B, T, 1)。unbiased=False表示计算方差时不使用无偏估计(即除以n而不是n-1)。
-
步骤 2:归一化:
out = (x - mean) / torch.sqrt(var + self.eps):对输入x进行归一化,减去均值并除以标准差(加上eps防止除零)。
-
步骤 3:缩放和偏移:
out = self.gamma * out + self.beta:对归一化后的数据进行缩放和偏移,gamma和beta是可学习的参数。
-
输出
out:形状与输入x相同,为(B, T, d_model)。
3. 代码运行示例
d_model = 512
X = torch.randn(2, 5, 512) # 2句话, 5个token,词向量512
ln = layer_norm(d_model)
print("d_model: ", d_model)
print(f"ln gamma: {ln.gamma.shape}")
print(f"ln beta: {ln.beta.shape}")
Y_ln = ln(X)
print(Y_ln.shape)
- 输入
X:形状为(2, 5, 512),表示 2 个句子,每个句子有 5 个 token,每个 token 的词向量维度为 512。 ln.gamma和ln.beta:ln.gamma的形状为(512,)。ln.beta的形状为(512,)。
- 输出
Y_ln:形状与输入X相同,为(2, 5, 512)。
4. 层归一化的作用
- 稳定训练:通过对每个样本的特征进行归一化,减少内部协变量偏移(Internal Covariate Shift),从而稳定训练过程。
- 加速收敛:归一化后的数据分布更加稳定,有助于加速模型的收敛。
- 增强表达能力:通过可学习的参数
gamma和beta,模型可以学习到适合当前任务的归一化方式。
5. 与批量归一化(Batch Normalization)的区别
- 批量归一化:沿着批量维度(
B)计算均值和方差,适用于批量较大的情况。 - 层归一化:沿着特征维度(
d_model)计算均值和方差,适用于序列数据(如 NLP 中的句子)或批量较小的情况。
6. 总结
- 这段代码实现了一个层归一化模块,对输入的特征进行归一化,并通过可学习的参数
gamma和beta进行缩放和偏移。 - 层归一化在 Transformer 等模型中广泛应用,用于稳定训练和加速收敛。
- 输入形状为
(B, T, d_model),输出形状与输入相同。


















![[EAI-023] FAST,机器人动作专用的Tokenizer,提高VLA模型的能力和训练效率](https://i-blog.csdnimg.cn/direct/d4deb5975c7943dbbe742e00215ecc43.png)
