原文链接:http://tecdat.cn/?p=24346
在今天产品高度同质化的品牌营销阶段,企业与企业之间的竞争集中地体现在对客户的争夺上(点击文末“阅读原文”获取完整代码数据)。
“用户就是上帝”促使众多的企业不惜代价去争夺尽可能多的客户。但是企业在不惜代价发展新用户的过程中,往往会忽视或无暇顾及已有客户的流失情况,结果就导致出现这样一种窘况:一边是新客户在源源不断地增加,而另一方面是辛辛苦苦找来的客户却在悄然无声地流失。因此对老用户的流失进行数据分析从而挖掘出重要信息帮助企业决策者采取措施来减少用户流失的事情至关重要,迫在眉睫。

1.2 目的:
深入了解用户画像及行为偏好,挖掘出影响用户流失的关键因素,并通过算法预测客户访问的转化结果,从而更好地完善产品设计、提升用户体验。
相关视频
1.3 数据说明:
此次数据是携程用户一周的访问数据,为保护客户隐私,已经将数据经过了脱敏,和实际商品的订单量、浏览量、转化率等有一些差距,不影响问题的可解性。
2 读取数据
# 显示全部特征
df.head()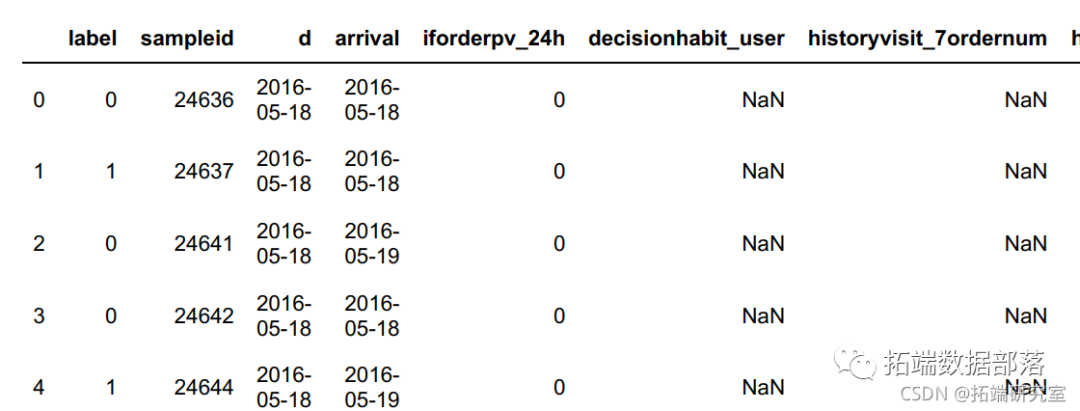
3 切分数据
# 划分训练集,测试集
X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, test\_size=0.2, random\_state=666)3.1 理解数据
可以看到变量比较的多,先进行分类,除去目标变量label,此数据集的字段可以分成三个类别:订单相关指标、客户行为相关指标、酒店相关指标。

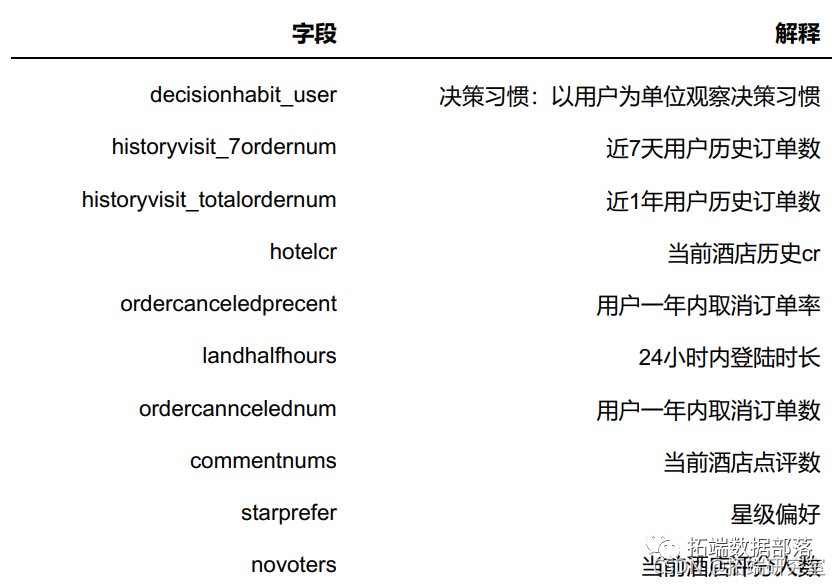
4 特征工程
# 用训练集进行数据探索
train = pd.concat(\[X\_train,y\_train\],axis=1)
4.1 数据预处理


4.1.1 删除不必要的列
X_train.pop("sampleid")
X_test.pop("sampleid")
train.pop("sampleid")
4.1.2 数据类型转换
字符串类型的特征需要处理成数值型才能建模,将arrival和d相减得到"提前预定的天数",作为新的特征
# 增加列
# 将两个日期变量由字符串转换为日期格式类型
train\["arrial"\] = pd.to_datimetain\["arrval"\])
X\_tst\["arival"\] = d.to\_daetime(X_est\["arival"\])
# 生成提前预定时间列(衍生变量)
X\_trin\["day\_adanced"\] = (X_rain\["arival"\]-Xtrain\["d"\]).dt.days## 删除列
X_tran.dro(columns="d","arrivl"\],inpace=True)4.1.3 缺失值的变量生成一个指示哑变量
zsl = tain.isnll().sum()\[tain.isnll(.sum()!=0\].inex4.1.4 根据业务经验填补空缺值
ordernum_oneyear 用户年订单数为0 ,lasthtlordergap 11%用600000填充 88%用600000填充 一年内距离上次下单时长,ordercanncelednum 用0填充 用户一年内取消订单数,ordercanceledprecent 用0t填充 用户一年内取消订
单率 242114 242114 -为空 有2种情况 1:新用户未下订单的空-88.42% 214097 2.老用户1年以上未消费的空 增加编码列未下订单新用户和 1年未下订单的老用户
price\_sensitive -0 ,中位数填充 价格敏感指数,consuming\_capacity -0 中位数填充 消费能力指数 226108 -为空情况 1.从未下过单的新用户214097 2.12011个人为空原因暂不明确
uv\_pre -24小时历史浏览次数最多酒店历史uv. cr\_pre -0,中位数填充 -24小时历史浏览次数最多酒店历史cr -0,中位数填充 29397 -为空 1.用户当天未登录APP 28633 2.刚上线的新酒店178 586 无uv,cr记录 编码添加 该APP刚上线的新酒店 764 29397
customereval_pre2 用0填充-24小时历史浏览酒店客户评分均值, landhalfhours -24小时内登陆时长 -用0填充28633 -为空:用户当天未登录APP 28633
hotelcr ,hoteluv -中位数填充 797
刚上新酒店 60 #未登录APP 118
avgprice 0 填充一部分价格填充为0 近一年未下过订单的人数,cr 用0填充,
tkq = \["hstoryvsit\_7ordernm","historyviit\_visit\_detaipagenum","frstorder\_b","historyvi
# tbkq = \["hitoryvsit\_7dernum","hisryvisit\_isit_detailagenum"\]X_train\[i\].fillna(0,inplace=True)## 一部分用0填充,一部分用中位數填充
# 新用戶影響的相關屬性:ic\_sniti,cosuing\_cacity
n\_l = picesensitive","onsmng\_cpacty"\]
fori in n_l
X\_trini\]\[Xra\[X\_trinnew_ser==1\].idex\]=0
X\_est\[i\]\[X\_test\[X\_test.nw\_user==1\].inex\]=04.1.5 异常值处理
将customer\_value\_profit、ctrip_profits中的负值按0处理
将delta\_price1、delta\_price2、lowestprice中的负值按中位数处理
for f in flter_two:
a = X_trin\[\].median()
X\_tran\[f\]\[X\_train\[f\]<0\]=a
X\_test\[f\]\[X\_est\[\]<0\]=a
tran\[f\]\[train\[f\]<0\]=a4.1.6 缺失值填充
趋于正态分布的字段,使用均值填充:businessrate\_pre2、cancelrate\_pre、businessrate_pre;偏态分布的字段,使用中位数填充.
def na_ill(df):
for col in df.clumns:
mean = X_trai\[col\].mean()dfcol\]=df\[col\].fillna(median)
return## 衍生变量年成交率
X\_train\["onear\_dalate"\]=\_tain\["odernum\_onyear"\]/X\_tran"visinum\_onyar"\]
X\_st\["onyardealae"\]=X\_st\["orernum_neyear"\]/Xtest\[visitumonyear"\]
X_al =pd.nca(\[Xtin,Xtes)#决策树检验dt = Decsionr(random_state=666)pre= dt.prdict(X_test)
pre\_rob = dt.preicproa(X\_test)\[:,1\]
pre_ob
4.2 数据标准化
scaler = MinMacaer()#决策树检验
dt = DeonTreasifi(random_state=666)5 特征筛选
5.1 特征选择-删除30%列
X\_test = X\_test.iloc\[:,sp.get_spport()\]
#决策树检验
dt = DecisonreeClssifie(random_state=666)
dt.fit(X\_trin,y\_tain)
dt.score(X\_tst,y\_est)
pre = dt.pdict(X_test)
pe\_rob = dt.redicproba(X\_test)\[:,1\]
pr_robuc(pr,tpr)
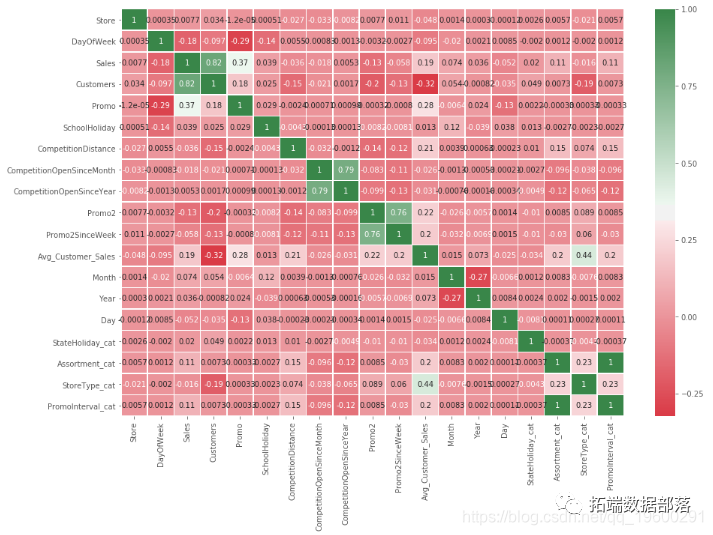
5.2 共线性/数据相关性
#共线性--严重共线性0.9以上,合并或删除
d = Xtrai.crr()
d\[d<0.9\]=0 #赋值显示高相关的变量
pl.fufsiz=15,15,dpi200)
ssheatp(d)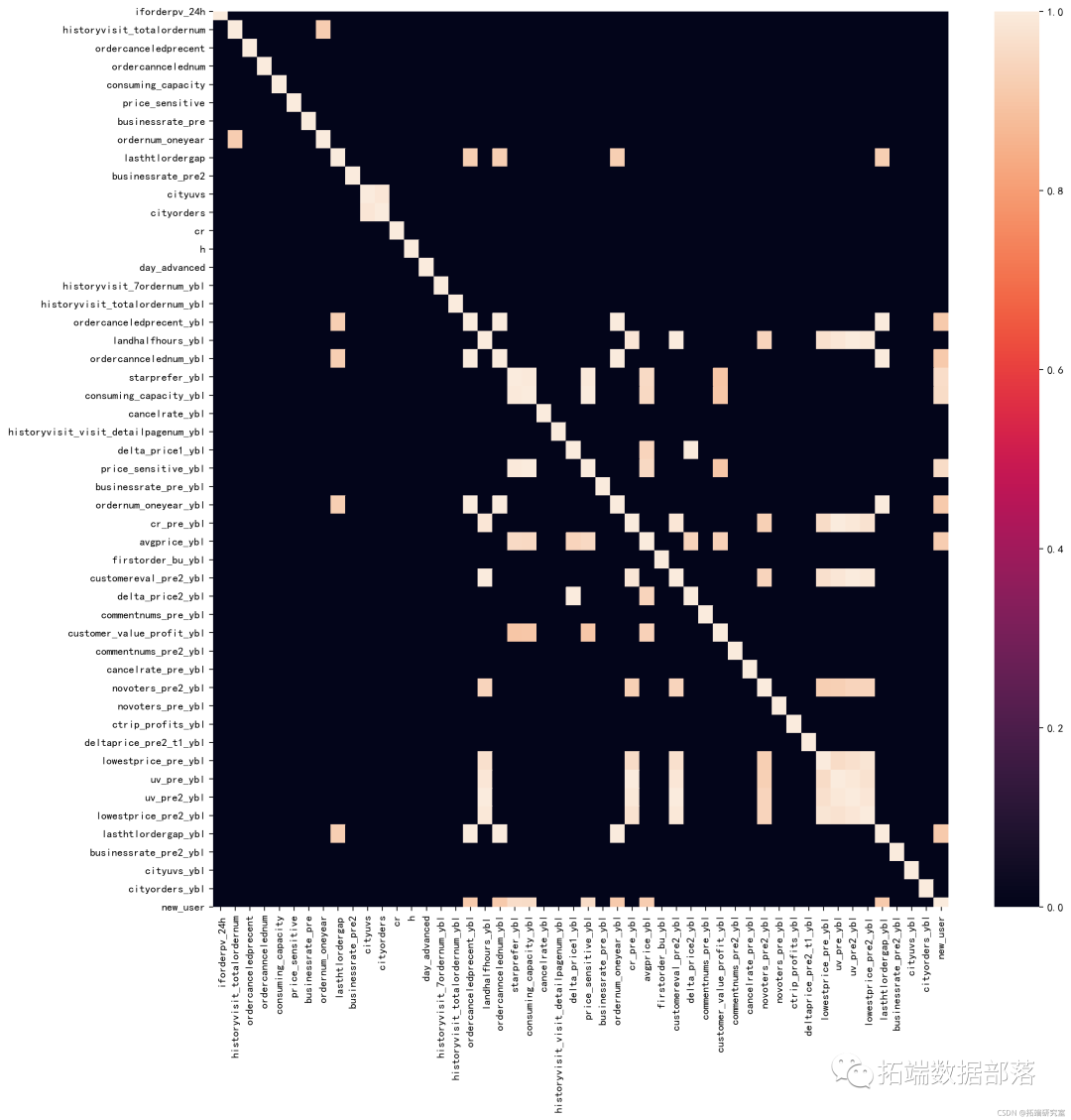
6 建模与模型评估
6.1 逻辑回归
y\_prob = lr.preictproba(X\_test)\[:,1\]
y\_pred = lr.predict(X\_test
fpr\_lr,pr\_lr,teshold\_lr = metris.roc\_curve(y\_test,y\_prob)
ac\_lr = metrcs.aucfpr\_lr,tpr_lr)
score\_lr = metrics.accuracy\_score(y\_est,y\_pred)
prnt("模准确率为:{0},AUC得分为{1}".fomat(score\_lr,auc\_lr))
prit("="*30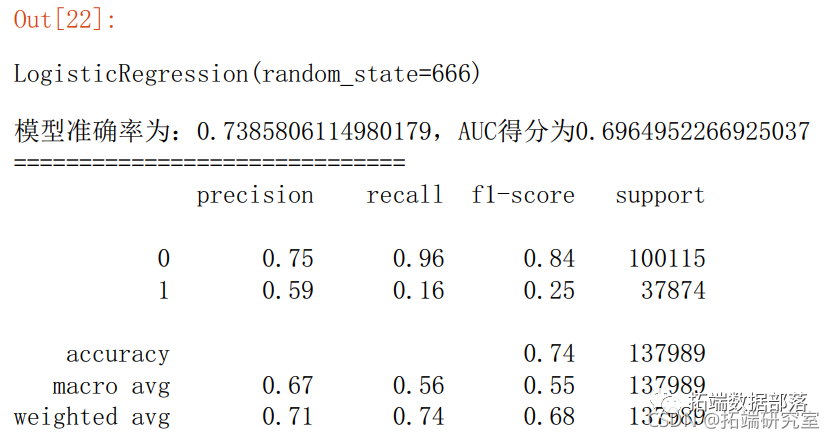
6.2 朴素贝叶斯
gnb = GasinNB() # 实例化一个LR模型
gnb.fi(trai,ytran) # 训练模型
y\_prob = gn.pic\_proba(X_test)\[:,1\] # 预测1类的概率
y\_pred = gnb.preict(X\_est) # 模型对测试集的预测结果
fpr\_gnb,tprgnbtreshold\_gb = metrics.roc\_crve(ytesty\_pob) # 获取真阳率、伪阳率、阈值
aucgnb = meic.aucf\_gnb,tr\_gnb) # AUC得分
scoe\_gnb = merics.acuray\_score(y\_tes,y\_pred) # 模型准确率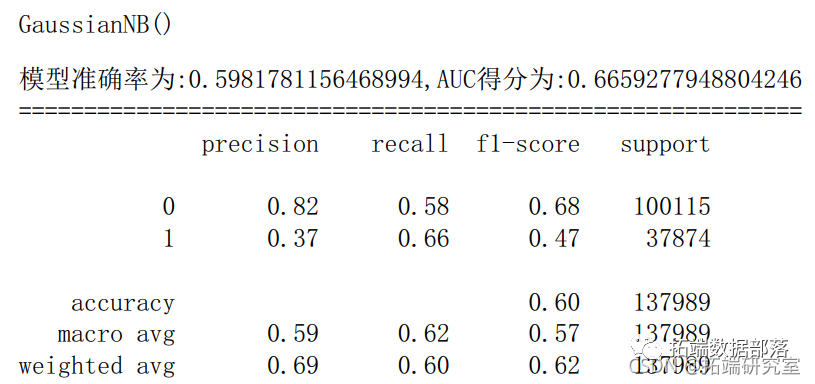
6.3 支持向量机
s =SVkernel='f',C=,max_ter=10,randomstate=66).fit(Xtrain,ytrain)
y\_rob = sc.decsion\_untio(X_st) # 决策边界距离
y\_ed =vc.redit(X\_test) # 模型对测试集的预测结果
fpr\_sv,tpr\_vc,theshld\_sv = mtris.rc\_urv(y\_esty\_pob) # 获取真阳率、伪阳率、阈值
au\_vc = etics.ac(fpr\_sc,tpr_sv) # 模型准确率
scre\_sv = metrics.ccuracy\_sore(_tst,ypre)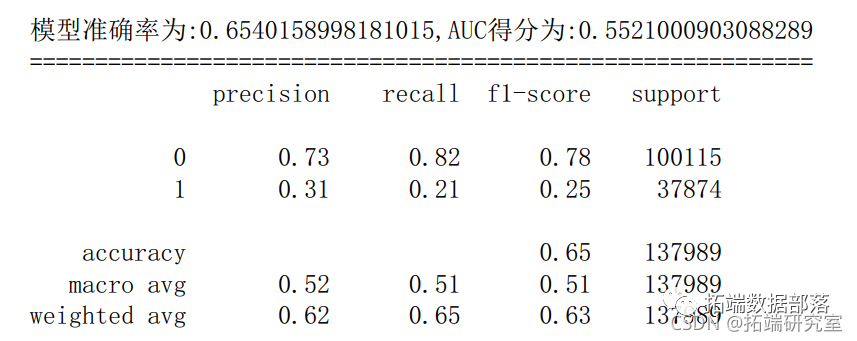
6.4 决策树
dtc.fit(X\_tran,\_raiproba(X_test)\[:,1\] # 预测1类的概率
y\_pred = dtc.predct(X\_test # 模型对测试集的预测结果
fpr\_dtc,pr\_dtc,thresod\_dtc= metrcs.roc\_curvey_test,yprob) # 获取真阳率、伪阳率、阈值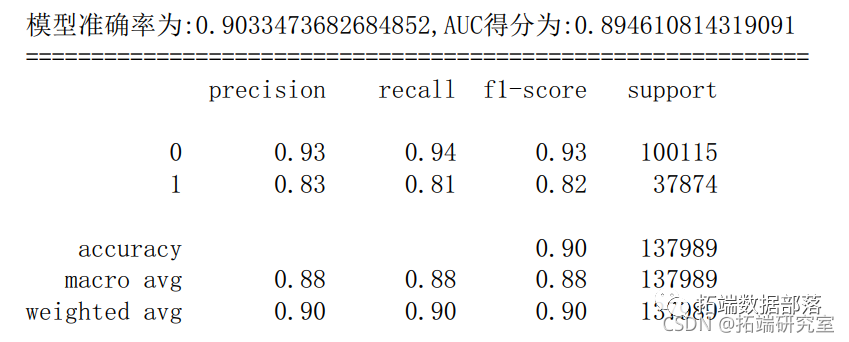
6.5 随机森林
c = RndoForetlassiir(rand_stat=666) # 建立随机森
rfc.it(X_tain,ytrain) # 训练随机森林模型
y\_rob = rfc.redict\_poa(X_test)\[:,1\] # 预测1类的概率
y\_pedf.pedic(\_test) # 模型对测试集的预测结果
fpr\_rfc,tp\_rfc,hreshol\_rfc = metrcs.roc\_curve(y\_test,\_prob) # 获取真阳率、伪阳率、阈值
au\_fc = meris.auc(pr\_rfctpr_fc) # AUC得分
scre\_rf = metrcs.accurac\_scor(y\_tes,y\_ped) # 模型准确率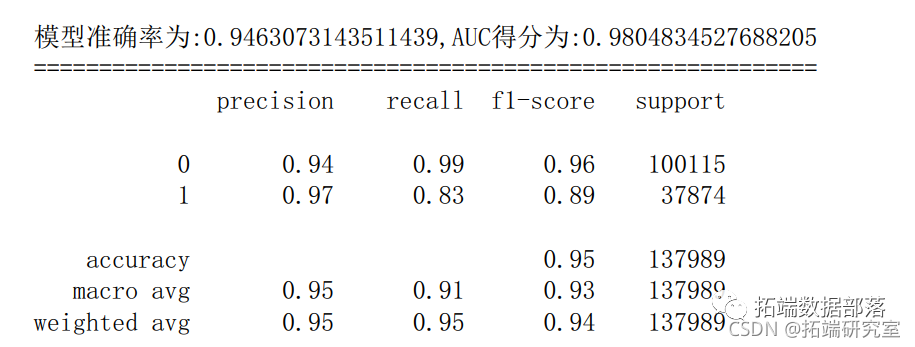
6.6 XGboost
# 读训练数据集和测试集
dtainxgbatrx(X_rai,yrain)
dtest=g.DMrx(Xtest
# 设置xgboost建模参数
paras{'booser':'gbtee','objective': 'binay:ogistic','evlmetric': 'auc'# 训练模型
watchlst = (dtain,'trai)
bs=xgb.ran(arams,dtain,n\_boost\_round=500eva=watchlst)
# 输入预测为正类的概率值
y_prob=bst.redict(dtet)
# 设置阈值为0.5,得到测试集的预测结果
y\_pred = (y\_prob >= 0.5)*1
# 获取真阳率、伪阳率、阈值
fpr\_xg,tpr\_xgb,heshold\_xgb = metricsroc\_curv(test,y_prob)
aucxgb= metics.uc(fpr\_gb,tpr\_xgb # AUC得分
score\_gb = metricsaccurac\_sore(y\_test,y\_pred) # 模型准确率
print('模型准确率为:{0},AUC得分为:{1}'.format(score\_xgb,auc\_xgb))
6.7 模型比较
plt.xlabel('伪阳率')
plt.ylabel('真阳率')
plt.title('ROC曲线')
plt.savefig('模型比较图.jpg',dpi=400, bbox_inches='tight')
plt.show()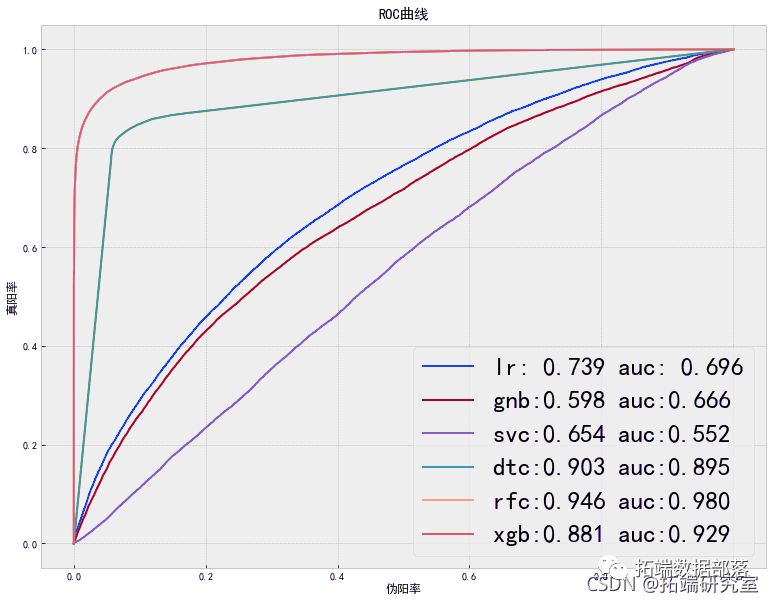
点击标题查阅往期内容

Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析

左右滑动查看更多
01
02
03
04
6.8 重要特征
ea = pd.Sries(dct(list((X\_trclumsfc.eatre\_imortancs_))))
ea.srt_vlues(acedig=False
fea\_s = (fa.srt\_vauesacnding=alse)).idex

6.9 流失原因分析
cityuvs和cityorders值较小时用户流失显著高于平均水平,说明携程平台小城市的酒店信息缺乏,用户转向使用小城市酒店信息较全的竞品导致用户流失
访问时间点在7点-19点用户流失比例高与平均水平:工作日推送应该避开这些时间点
酒店商务属性指数在0.3-0.9区间内用户流失大于平均水平,且呈现递增趋势,说明平台商务指数高的酒店和用户期望有差距(价格太高或其他原因?), 商务属性低的用户流失较少
一年内距离上次下单时长越短流失越严重,受携程2015年5月-2016年1月爆出的负面新闻影响较大,企业应该更加加强自身管理,树立良好社会形象
消费能力指数偏低(10-40)的用户流失较严重,这部分用户占比50%应该引起重视
价格敏感指数(5-25)的人群流失高于平均水平,注重酒店品质
用户转化率,用户年订单数,近1年用户历史订单数越高,24小时内否访问订单填写页的人群比例越大流失越严重,需要做好用户下单后的追踪体验, 邀请填写入住体验,整理意见作出改进
提前预定天数越短流失越严重用户一年内取消订单数越高流失越严重
6.10 建议:
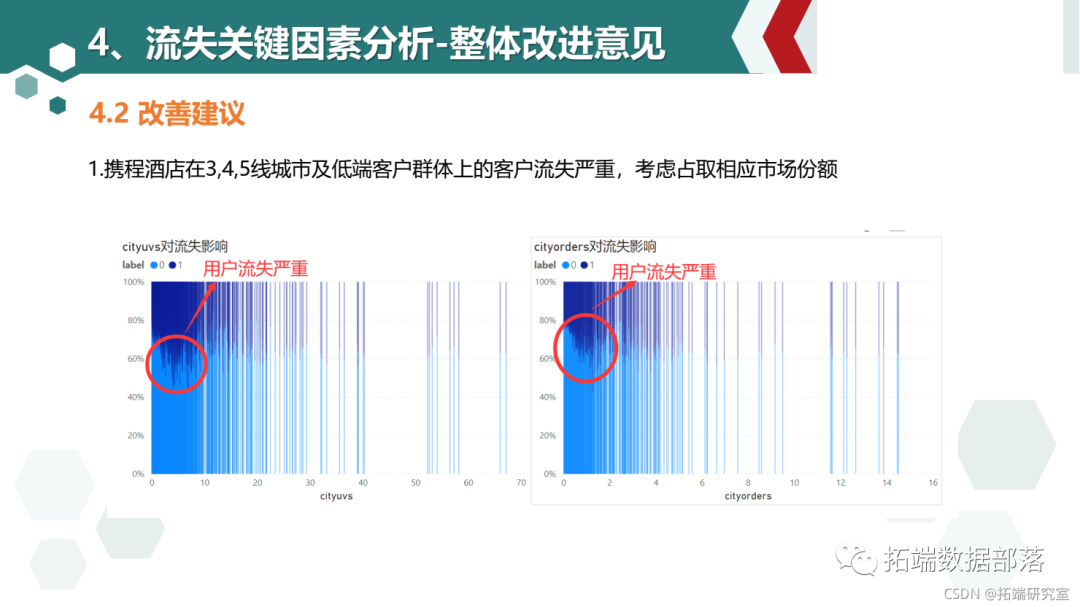
考虑占取三四线城市和低端酒店范围的市场份额
用户易受企业负面新闻影响,建议企业勇于承担社会责任,加强自身管理,提高公关新闻处理时效性,树立品牌良好形像
在节假日前2-3周开始热门景点酒店推送
做好酒店下单后的追踪体验,邀请填写入住体验,并整理用户意见作出改进
7 客户画像
7.1 建模用户分类
# 用户画像特征
user\_feature = \["decisiohabit\_user,'starprefer','lastpvgap','sid',
'lernum",'historyvisit\_visit\_detaipagenum',
"onyear_dealrat
\]
# 流失影响特征
fea_lis = \["cityuvs",
"cityorders",
"h",
"businessrate_pre2"# 数据标准化 Kmeans方法对正态分布数据处理效果更好
scaler = StanardScalr()
lo\_atribues = pdDatarame(scr.fittransfrm(all\_cte),columns=all_ce.coluns)# 建模分类
Kmens=Means(n\_cluste=2,rndom\_state=0) #333
Keans.fi(lot_attributes # 训练模型
k\_char=Kmenscluster\_centers_ # 得到每个分类
plt.figure(figsize=(5,10))

7.2 用户类型占比
types=\['高价值用户','潜力用户'\]
ax.pie\[1\], raius=0.,colors='w')
plt.savefig(用户画像.jpg'dpi=400, box_inchs='tigh')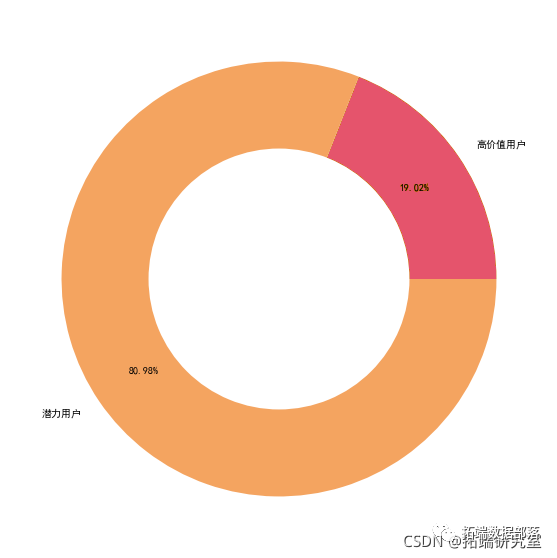
7.3 高价值用户分析
占比19.02,访问频率和预定频率都较高,消费水平高,客户价值大,追求高品质,对酒店星级要求高,客户群体多集中在老客户中,
建议:
多推荐口碑好、性价比高的商务酒店连锁酒店房源吸引用户;
在非工作日的11点、17点等日间流量小高峰时段进行消息推送。
为客户提供更多差旅地酒店信息;
增加客户流失成本:会员积分制,推出会员打折卡
7.4 潜力用户分析
占比:80.98% 访问频率和预定频率都较低,消费水平较低,对酒店星级要求不高,客户群体多集中在新客户中,客户价值待挖掘 建议:
因为新用户居多,属于潜在客户,建议把握用户初期体验(如初期消费有优惠、打卡活动等),还可以定期推送实惠的酒店给此类用户,以培养用户消费惯性为主;
推送的内容应多为大减价、大酬宾、跳楼价之类的;
由于这部分用户占比较多,可结合该群体流失情况分析流失客户因素,进行该群体市场的开拓,进一步进行下沉分析,开拓新的时长。
关于作者
Lijie Zhang逻辑思辨能力强,考虑问题全面,熟练掌握数据清洗和数据预处理、绘图和可视化展示,熟悉机器学习 sklearn, xgboost 等库进行数据挖掘和数据建模,掌握机器学习的线性回归、逻辑回归、主成分分析、聚类、决策树、随机森林、 xgboost、 svm、神经网络算法。

本文摘选《PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像》,点击“阅读原文”获取全文完整资料。


点击标题查阅往期内容
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测
spss modeler用决策树神经网络预测ST的股票
R语言中使用线性模型、回归决策树自动组合特征因子水平
R语言中自编基尼系数的CART回归决策树的实现
R语言用rle,svm和rpart决策树进行时间序列预测
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言ISLR工资数据进行多项式回归和样条回归分析
R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
如何用R语言在机器学习中建立集成模型?
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
在python 深度学习Keras中计算神经网络集成模型
R语言ARIMA集成模型预测时间序列分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言基于Bootstrap的线性回归预测置信区间估计方法
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线
matlab使用分位数随机森林(QRF)回归树检测异常值

![]()


![[Linux]进程](https://img-blog.csdnimg.cn/42383dffcbcd44fe959424c80c447792.png)

![[笔记] 阿里云域名知识](https://img-blog.csdnimg.cn/179fc9a5d06444e3871e325656cb9b67.png)