简介:
本文主要是代码实现,二叉树遍历,递归和非递归(用栈)。主要为了好理解,直接在代码处,加了详细注释,方便复习和后期默写。主要了解其基本思想,为后期熟练应用打基础。
遍历的意义,就是为了实现在二叉树上,进行各种操作,给每个结点都光顾到位,到根节点时,进行当前节点的操作。
目录:
目录
一、前序遍历。
1.1前序遍历—递归
1.2前序遍历—非递归
二、中序遍历
2.1中序遍历—递归
2.2中序遍历—非递归
三、后序遍历
3.1后序遍历—递归
3.2后序遍历—非递归
五、总代码
5.1代码
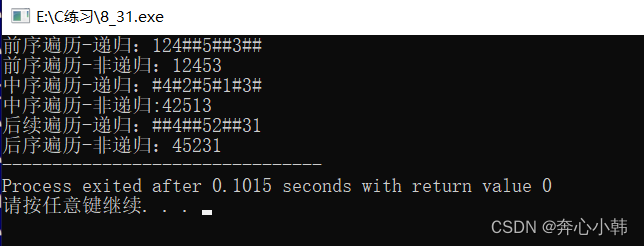
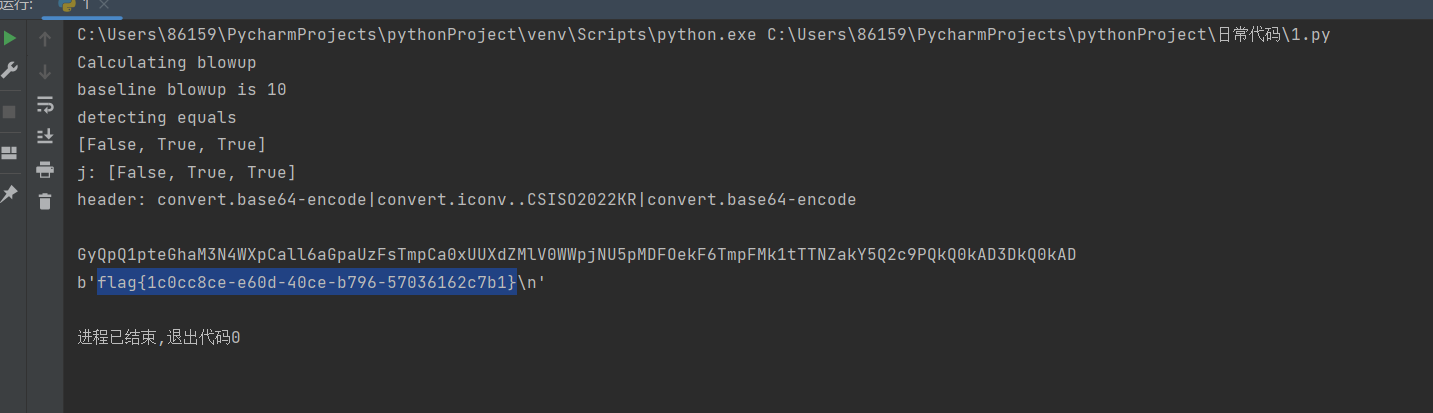
5.2运行结果图
一、前序遍历。
1.1前序遍历—递归
简介:前序为:先访问根结点,再访问其左孩子,再访问右孩子(根左右)。
//前序遍历,递归
void PreOrder(BTNode *node)
{if(node==NULL)//当前结点为空时,返回上一层递归空间 {printf("#");return;}//结点非空时 visit(node);PreOrder(node->lchild);PreOrder(node->rchild);
}1.2前序遍历—非递归
简介:非递归,就是利用栈(就是一个存放树结点指针的数组,再加一个栈顶标记top),存放树节点的指针。树不为空的时候先入栈,随后,栈不为空时,再进行出栈操作。前序遍历出栈时,先出栈后,先访问该节点信息,随后再判断该节点是否有右孩子,有则,右孩子的指针存进栈中。再判断是否有左孩子,有则左孩子指针存进栈,
//前序遍历,非递归
void Stack_PreOrder(BTNode *node)
{if(node==NULL)//树为空,不处理return;//创建一个栈,存放树结点类型的地址 BTNode* Stack[10];int top=-1;//工作指针,随着p指针,记录树的当前结点位置 BTNode *p=NULL;//当树非空时,进行操作 if(node !=NULL){//入栈 top++;Stack[top]=node;//随后进行出栈操作,只有栈非空时,才可出栈 while(top != -1){//取出此时栈顶元素 p=Stack[top];top--;//然后进行访问当前结点的相关操作 visit(p);//访问完根,在看该根的右孩子,入栈 ,因为是栈,先进后出,而前序为根左右,根出来后,右入栈,之后左入栈,最后出栈是栈顶出 if(p->rchild!=NULL){top++;Stack[top]=p->rchild;}//访问完右孩子,在看该根的左孩子,入栈 if(p->lchild!=NULL){top++;Stack[top]=p->lchild;} } }
}二、中序遍历
2.1中序遍历—递归
简介:左根右。不理解为啥的,可以画图,每进入一个新的函数,便是一个新的空间。
//中序遍历-递归
void InOrder(BTNode *node)
{if(node==NULL){printf("#");return;}InOrder(node->lchild);visit(node);InOrder(node->rchild);
}2.2中序遍历—非递归
简介:其实,栈也好,递归也罢,需要操作的,仅为两步,第一步为进入新树的一些列操作。操作完,进入第二步,进到另一方向孩子树中,该树中的操作,还是先进性第一步,再进行第二部,
思想:中序遍历非递归操作,最外圈来个do-while循环,先执行,再判断。如果栈内非空,或者该结点不为空,都进行中序遍历操作。
do-while里面的操作:先左子树操作:一直遍历,入栈元素,随后给指针地址换成该节点的左孩子,就是一直遍历到左孩子为空,才停止。至此,左根右中的左操作完毕。随后出栈元素,进行左根右中的根操作,访问根节点。至此,为第一步的操作。随后第二部,进入方向的树中,即结点指针换为右孩子地址,
//中序遍历-非递归
void StackInOrder(BTNode *node)
{if(node==NULL)//树为空,则不处理return;printf("中序遍历-非递归:");BTNode* p=node;BTNode* Stack[10];int top=-1;do{//当结点不为空时,入栈,并进入左孩子。 ——访问左孩子 while(p!=NULL){top++;Stack[top]=p;p=p->lchild;}//一直遍历左,遍历到空,此时,出栈p=Stack[top];top--;visit(p);//访问根 p=p->rchild;//根访问完,随后,访问右孩子。随后,右孩子中,又是新的树,然后再进行左根右操作,形成循环,从上面再来一圈。 }while(top!=-1 || p!=NULL);//只要树不为空,或者栈内有元素,就一直进行操作。 } 三、后序遍历
3.1后序遍历—递归
简介:左右根。
// 后序遍历-递归
void PostOrder(BTNode *node)
{if(node==NULL){printf("#");return;}PostOrder(node->lchild);PostOrder(node->rchild);visit(node);
}3.2后序遍历—非递归
简介:这个比较麻烦,不过还是利用描边法去做,根据描边法,根节点被访问两次,第一次时入栈时,第二次时判断是否出栈时,就看从那一层返回到根节点的,如果从右孩子返回的,则进行出栈操作,先记录当前结点,再出栈。否则,则进行右子树结点的出栈,
这里面,跟中序,略有不同,入栈和出栈的情况需要判断,所以需要用栈顶指针时刻对比。
先跟根结点入栈,随后当栈内不为空时,一直进行遍历操作。先进性第一步的入栈操作(当上层遍历,即不是栈顶指针的左孩子又不是右孩子时,更新工作指针为左孩子,随后进行一直左孩子入栈操作)第二步,左孩子到底了,此时需要面临出栈,因此给当前栈顶元素取出来,如果该树没有左孩子,或者pre与右孩子地址相同,则进行出栈操作,并记录出栈前的指针p,否则则给右孩子入栈。
void StackPostOrder(BTNode *node)
{printf("后序遍历-非递归:");if(node==NULL)return; BTNode *p=node;//工作指针 BTNode *pre=NULL;//表示上层结点位置 //栈 BTNode *Stack[10];int top=-1;//先跟根节点入栈,为了方便第一次判断top++;Stack[top]=p;do{//先判断上层结点是否遍历过,没有,则进行左子树都入栈,入到底if(pre!=Stack[top]->lchild && pre!=Stack[top]->rchild){p=Stack[top]->lchild;//上次没有遍历过左右孩子,那么开始栈顶元素的左孩子入栈操作。while(p!=NULL){top++;Stack[top]=p;p=p->lchild; } }//左孩子方向弄到底后,开始判断,是否需要出栈输出。p=Stack[top];//记录此时的栈顶元素if(p->rchild==NULL || pre==p->rchild)//如果右孩子为空,或者上一层和当前结点的右孩子相等,则输出 {pre=p;//记录当前结点地址 visit(p);//输出 top--;//输出了,栈内指针减少 }else{top++;Stack[top]=p->rchild;//右孩子入栈 } }while(top!=-1);
}五、总代码
5.1代码
#include <stdio.h>
#include <stdlib.h>
//创建树,孩子链表
typedef struct BTNode
{int data;struct BTNode *rchild,*lchild;}BTNode;
//创建树结点,并初始化
BTNode* BuyNode(int x)
{BTNode* node=(BTNode*)malloc(sizeof(BTNode));node->data=x;node->lchild=NULL;node->rchild=NULL;return node;
}
//手动创建树
BTNode* CreatTree()
{BTNode* node1=BuyNode(1);BTNode* node2=BuyNode(2);BTNode* node3=BuyNode(3);BTNode* node4=BuyNode(4);BTNode* node5=BuyNode(5);node1->lchild=node2;node1->rchild=node3;node2->lchild=node4;node2->rchild=node5;return node1;
}
//访问当前结点时的操作
void visit(BTNode *node)
{printf("%d",node->data);
}
//前序遍历,递归
void PreOrder(BTNode *node)
{if(node==NULL)//当前结点为空时,返回上一层递归空间 {printf("#");return;}//结点非空时 visit(node);PreOrder(node->lchild);PreOrder(node->rchild);
}
//前序遍历,非递归
void Stack_PreOrder(BTNode *node)
{if(node==NULL)return;printf("前序遍历-非递归:");//创建一个栈,存放树结点类型的地址 BTNode* Stack[10];int top=-1;//工作指针,随着p指针,记录树的当前结点位置 BTNode *p=NULL;//当树非空时,进行操作 if(node !=NULL){//入栈 top++;Stack[top]=node;//随后进行出栈操作,只有栈非空时,才可出栈 while(top != -1){//取出此时栈顶元素 p=Stack[top];top--;//然后进行访问当前结点的相关操作 visit(p);//访问完根,在看该根的右孩子,入栈 ,因为是栈,先进后出,而前序为根左右,根出来后,右入栈,之后左入栈,最后出栈是栈顶出 if(p->rchild!=NULL){top++;Stack[top]=p->rchild;}//访问完右孩子,在看该根的左孩子,入栈 if(p->lchild!=NULL){top++;Stack[top]=p->lchild;} } }
}
//中序遍历-递归
void InOrder(BTNode *node)
{if(node==NULL){printf("#");return;}InOrder(node->lchild);visit(node);InOrder(node->rchild);
}
//中序遍历-非递归
void StackInOrder(BTNode *node)
{if(node==NULL)return;printf("中序遍历-非递归:");BTNode* p=node;BTNode* Stack[10];int top=-1;do{//当结点不为空时,入栈,并进入左孩子。 ——访问左孩子 while(p!=NULL){top++;Stack[top]=p;p=p->lchild;}//一直遍历左,遍历到空,此时,出栈p=Stack[top];top--;visit(p);//访问根 p=p->rchild;//根访问完,随后,访问右孩子。随后,右孩子中,又是新的树,然后再进行左根右操作,形成循环,从上面再来一圈。 }while(top!=-1 || p!=NULL);//只要树不为空,或者栈内有元素,就一直进行操作。 }
// 后序遍历-递归
void PostOrder(BTNode *node)
{if(node==NULL){printf("#");return;}PostOrder(node->lchild);PostOrder(node->rchild);visit(node);
}
//后序遍历-非递归
void StackPostOrder(BTNode *node)
{printf("后序遍历-非递归:");if(node==NULL)return; BTNode *p=node;//工作指针 BTNode *pre=NULL;//表示上层结点位置 //栈 BTNode *Stack[10];int top=-1;//先跟根节点入栈,为了方便第一次判断top++;Stack[top]=p;do{//先判断上层结点是否遍历过,没有,则进行左子树都入栈,入到底if(pre!=Stack[top]->lchild && pre!=Stack[top]->rchild){p=Stack[top]->lchild;//上次没有遍历过左右孩子,那么开始栈顶元素的左孩子入栈操作。while(p!=NULL){top++;Stack[top]=p;p=p->lchild; } }//左孩子方向弄到底后,开始判断,是否需要出栈输出。p=Stack[top];//记录此时的栈顶元素if(p->rchild==NULL || pre==p->rchild)//如果右孩子为空,或者上一层和当前结点的右孩子相等,则输出 {pre=p;//记录当前结点地址 visit(p);//输出 top--;//输出了,栈内指针减少 }else{top++;Stack[top]=p->rchild;//右孩子入栈 } }while(top!=-1);
}
int main()
{BTNode* root=CreatTree();//前序遍历打印printf("前序遍历-递归:"); PreOrder(root);//递归 printf("\n"); Stack_PreOrder(root);//非递归,栈来做 printf("\n"); printf("中序遍历-递归:");InOrder(root); printf("\n"); StackInOrder(root); printf("\n"); printf("后续遍历-递归:");PostOrder(root);printf("\n"); StackPostOrder(root);return 0;} 5.2运行结果图