第一章 CDC简介
1.1 什么是CDC
CDC (Change Data Capture 变更数据获取)的简称。核心思想就是,检测并获取数据库的变动(增删查改),将这些变更按发生的顺序记录下来,写入到消息中间件以供其它服务进行订阅及消费。
1.2 CDC的种类
主要分为两大类:
-
基于查询
通过sql查询来获取变化部分的数据。如:通过时间查询前一天、最近一个小时的数据。
-
基于binlog日志
binlog记录了历史操作,通过binlog日志,再执行一次和数据库一样的操作(如增删查改)就能实现同步数据了。
| 基于查询 | 基于Binlog | |
|---|---|---|
| 执行模式 | batch | streaming |
| 是否可以捕获所有数据变化 | 否 | 是 |
| 延迟 | 高延迟 | 低延迟 |
| 是否增加数据库压力 | 是 | 否 |
1.3 Flink-CDC
Flink社区开发了flink-cdc-connectors组件,这是一个可以直接从mysql、PostgreSQL等数据库直接读取全量数据和增量变更数据的source组件。
项目地址:https://github.com/ververica/flink-cdc-connectors
既然已经有了很多CDC的方案,为什么还需要Flink-CDC?
其实Flink内部使用的就是Debezium基于binlog日志的方式。只是我们获取到数据变更之后往往需要进一步分析处理,而实时的分析处理会用flink来做处理。这样的话就经过了两步。Flink-CDC相当于把CDC集成到了Flink中,可以获取到数据变更后直接处理,一部到位。
第二章 Flink-CDC案例实操
2.1 DataStream方式的应用
2.1.1 导入依赖
<dependency><groupId>com.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>2.4.0</version>
</dependency>
pom.xml
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><flink.version>1.17.0</flink.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties><dependencies><!-- Flink相关依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-base</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>2.4.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-loader</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>${flink.version}</version></dependency><!-- 其它 --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency>
</dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.0</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><!-- Replace this with the main class of your job --><mainClass>com.zlin.flink.cdc.FinkCdc</mainClass></transformer><transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/></transformers></configuration></execution></executions></plugin></plugins>
</build>
2.1.2 编写代码
创建库表
create database if not exists db_cdc_test;create table if not exists db_cdc_test.tb_a(id BIGINT auto_increment primary key comment '自增id',name VARCHAR(20),age INT
);
开启binlog日志
[root@hadoop102 ~]# vim /etc/my.cnf
[mysqld]
server-id=1
log-bin=mysql-bin
binlog_format=row
binlog_do_db=db_cdc_test
编写代码(官网示例)
package com.zlin.flink.cdc;import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @author ZLin* @since 2023/7/16*/
public class FinkCdc {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);MySqlSource<String> mySqlSource = MySqlSource.<String>builder().hostname("hadoop102").port(3306).username("root").password("xxxxxxxx").databaseList("db_cdc_test").tableList("db_cdc_test.tb_a").deserializer(new JsonDebeziumDeserializationSchema()).build();env.enableCheckpointing(3000);env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(),"MSQL Source").setParallelism(4).print().setParallelism(1);env.execute("Print MySQL Snapshot + Binlog");}
}!!!注意!!!
读取binlog是可以选择模式的:
.startupOptions()
默认是 StartupOptions.initial() 创建表时必须要有主键,不然没有输出也不报错…我就被这个地方坑了很久
如果是 StartupOptions.latest() 则可以没有主键
2.1.3 案例测试
IDEA上运行:
在数据库中对表增删查改,然后观察控制台输出
集群上运行:
step1.打包
step2.将jar上传至服务器,提交任务
[root@hadoop102 bin]# ./flink run -t yarn-per-job /opt/jars/flink-cdc-1.0-SNAPSHOT.jar
查看输出
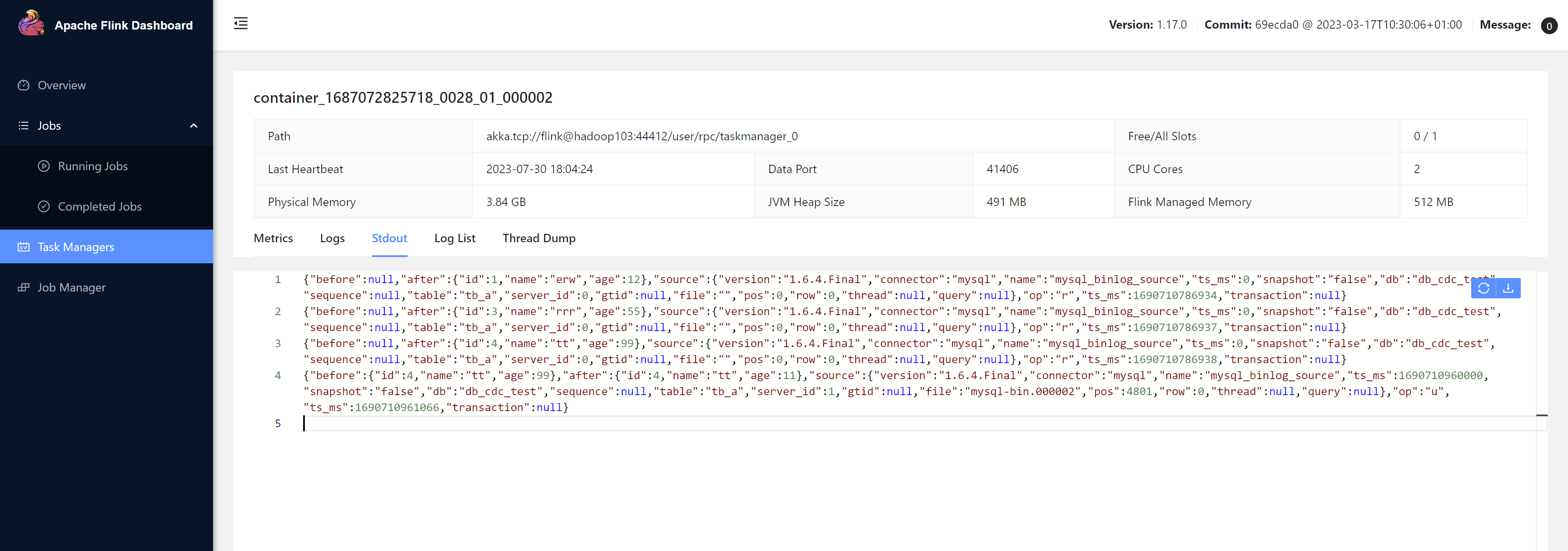
设置checkpoint,增量读取binlog
step1.编写代码
package com.zlin.flink.cdc;import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @author ZLin* @since 2023/7/16*/
public class FinkCdc {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);MySqlSource<String> mySqlSource = MySqlSource.<String>builder().hostname("hadoop102").port(3306).username("root").password("root@2023").databaseList("db_cdc_test").tableList("db_cdc_test.tb_a").deserializer(new JsonDebeziumDeserializationSchema()).build();// 启动检查点env.enableCheckpointing(5000);// 检查点配置CheckpointConfig checkpointConfig = env.getCheckpointConfig();checkpointConfig.setCheckpointTimeout(10000);checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);checkpointConfig.setMaxConcurrentCheckpoints(1);env.setStateBackend(new HashMapStateBackend());env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(),"MSQL Source").setParallelism(4).print().setParallelism(1);env.execute("Print MySQL Snapshot + Binlog");}
}
step2.打包、提交任务
[root@hadoop102 bin]# ./flink run -t yarn-per-job /opt/jars/flink-cdc-1.0-SNAPSHOT.jar
....
2023-08-02 17:31:51,211 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop103:43015 of application 'application_1687072825718_0040'.
Job has been submitted with JobID e7e1b088cdd924a952fb3d95aa171dbc
这里通过flink on yarn的方式提交的任务,需要记录两个地方,后面创建savepoint需要用到
yid:application_1687072825718_0040
jobid:e7e1b088cdd924a952fb3d95aa171dbc
step3.创建保存点
配置保存点存储路径(这里使用默认路径):
[root@hadoop102 conf]# vim flink-conf.yaml
[root@hadoop103 conf]# vim flink-conf.yaml
[root@hadoop104 conf]# vim flink-conf.yaml
state.savepoints.dir: hdfs://hadoop102:9000/flink-savepoints
创建保存点:
[root@hadoop102 flink-1.17.1]# bin/flink savepoint e7e1b088cdd924a952fb3d95aa171dbc -yid application_1687072825718_0040
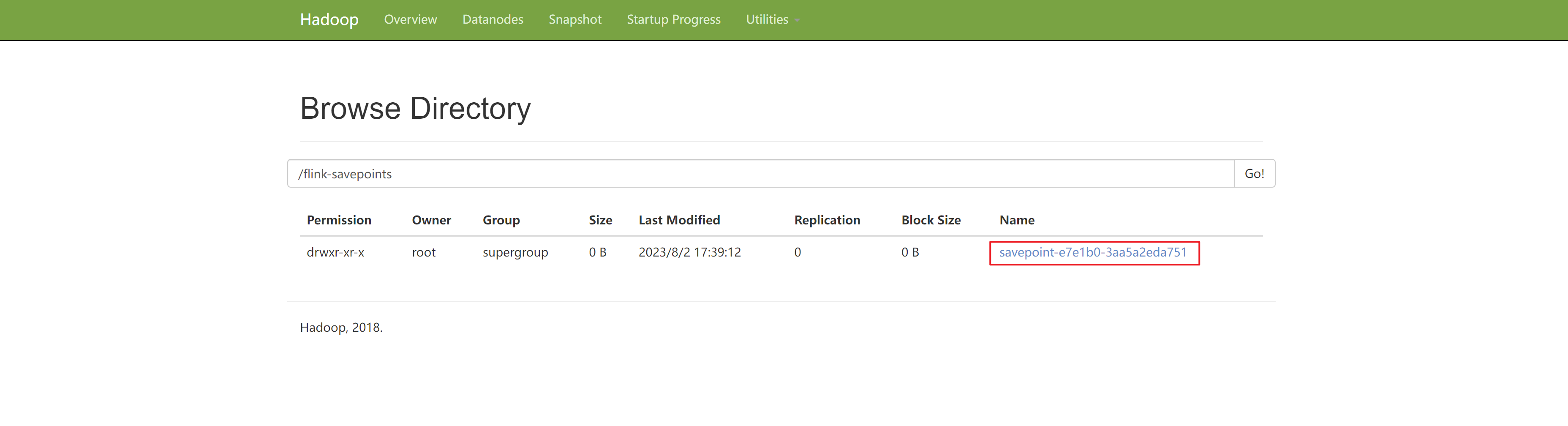
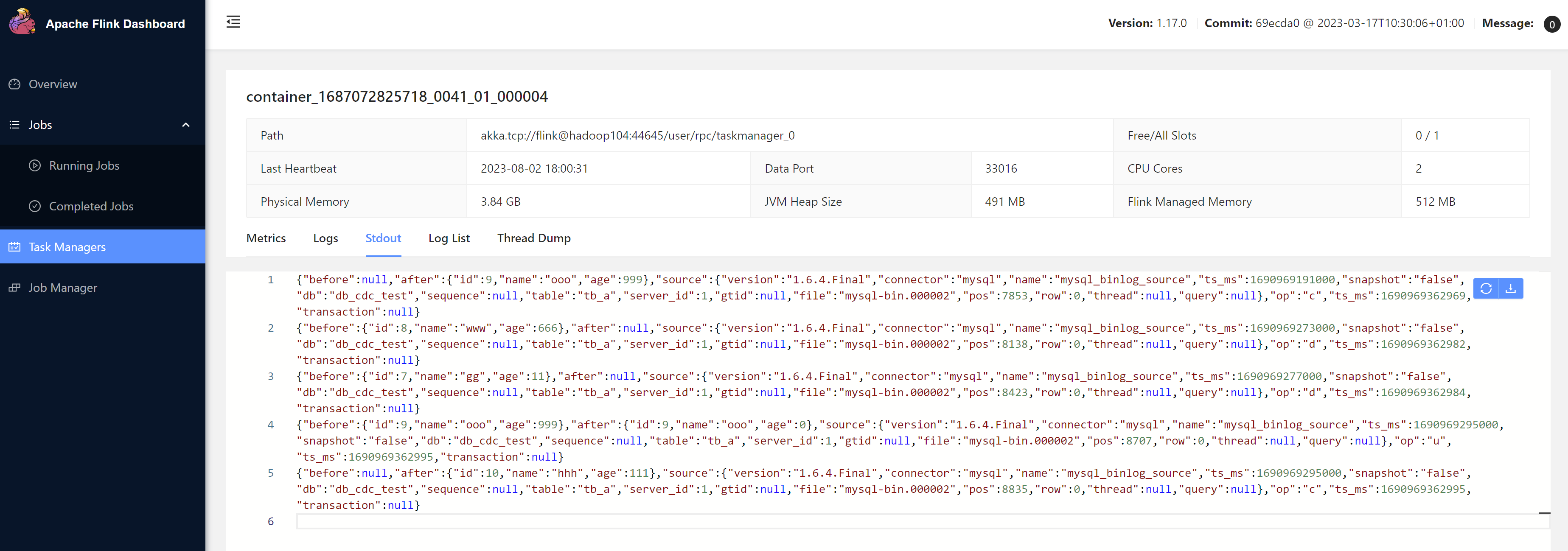
step4.kill掉任务,我们再进行一些增删查改的工作,然后从保存点开始恢复任务
[root@hadoop102 bin]# ./flink run -s hdfs://hadoop102:9000/flink-savepoints/savepoint-e7e1b0-3aa5a2eda751 -t yarn-per-job /opt/jars/flink-cdc-1.0-SNAPSHOT.jar
原来读过的操作不再读取,从没有读过的操作开始读取
2.2 FlinkSQL方式的应用
2.1.1 代码实现
package com.zlin.flink.cdc;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;/*** @author ZLin* @since 2023/8/2*/
public class FlinkSqlCdc {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 创建Flink Table环境StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);// 使用FlinkSQL模式创建CDC表tEnv.executeSql("CREATE TABLE tb_a (id string, \n" +"name string,\n" +"age string\n" +") WITH (\n" +"'connector'='mysql-cdc'," +"'hostname'='hadoop102'," +"'username'='xxxx'," +"'password'='xxxx'," +"'database-name'='db_cdc_test'," +"'table-name'='tb_a'," +"'scan.startup.mode'='latest-offset'," +"'scan.incremental.snapshot.chunk.key-column'='id')");// 查询数据并转换为流输出Table table = tEnv.sqlQuery("select * from tb_a");tEnv.toChangelogStream(table).print();env.execute("Flink SQL CDC");}
}
刚开始一直报错,后面发下是我mysql密码里面有个字符
@,改了密码去掉特殊字符之后就正常了。不知道什么原因。。。。
2.3 自定义反序列化器
2.3.1 代码实现
自定义序列化器 CustomDeserializationSchema
package com.zlin.flink.cdc.func;import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import org.codehaus.jettison.json.JSONException;
import org.codehaus.jettison.json.JSONObject;import java.util.List;/*** @author ZLin* @since 2023/8/6*/
public class CustomDeserializationSchema implements DebeziumDeserializationSchema<String> {@Overridepublic void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {JSONObject result = new JSONObject();String topic = sourceRecord.topic();String[] fields = topic.split("\\.");result.put("db", fields[1]);result.put("tableName", fields[2]);Struct value = (Struct) sourceRecord.value();// before数据result.put("before", getData("before", value));// after数据result.put("after", getData("after", value));// 操作类型Envelope.Operation operation = Envelope.operationFor(sourceRecord);result.put("op", operation);collector.collect(result.toString());}/*** 返回类型** @return 返回类型*/@Overridepublic TypeInformation<String> getProducedType() {return BasicTypeInfo.STRING_TYPE_INFO;}private JSONObject getData(String dataType, Struct value) throws Exception {Struct data = value.getStruct(dataType);JSONObject dataJson = new JSONObject();if (data != null) {Schema schema = data.schema();List<Field> fieldsList = schema.fields();if (fieldsList != null && !fieldsList.isEmpty()) {for (Field field : fieldsList) {try {dataJson.put(field.name(), data.get(field));} catch (JSONException e) {throw new Exception(String.format("字段%s读取失败", field.name()), e);}}}}return dataJson;}
}
使用自定义序列化器,改变输出格式,方便后续处理
package com.zlin.flink.cdc;import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.zlin.flink.cdc.func.CustomDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @author ZLin* @since 2023/7/16*/
public class FinkCdcCustomDeserialization {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 启动检查点env.enableCheckpointing(3000);MySqlSource<String> mySqlSource = MySqlSource.<String>builder().hostname("hadoop102").port(3306).username("root").password("xxxx").databaseList("db_cdc_test").tableList("db_cdc_test.tb_a").startupOptions(StartupOptions.initial()).deserializer(new CustomDeserializationSchema()).build();env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(),"MSQL Source").setParallelism(4).print().setParallelism(1);env.execute("Print MySQL Snapshot + Binlog");}
}输出:
log4j:WARN No appenders could be found for logger (org.apache.flink.api.java.ClosureCleaner).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
{"db":"db_cdc_test","tableName":"tb_a","before":{},"after":{"id":3,"name":"yy","age":55},"op":"READ"}
{"db":"db_cdc_test","tableName":"tb_a","before":{},"after":{"id":2,"name":"pp","age":33},"op":"READ"}
{"db":"db_cdc_test","tableName":"tb_a","before":{},"after":{"id":1,"name":"rr","age":11},"op":"READ"}
八月 08, 2023 9:30:58 下午 com.github.shyiko.mysql.binlog.BinaryLogClient connect
信息: Connected to hadoop102:3306 at mysql-bin.000002/17799 (sid:5925, cid:1129)
2.4 DataStream和Flink SQL方式区别
- DataStream方式 Flink 1.12+可使用,Flink SQL方式 1.13+版本可用
- DataStream方式支持多库多表的监控,而Flink SQL只能单表监控
第三章 Flink-CDC 2.0
3.1 1.x痛点
-
一致性通过加锁保证
Debezium在保证一致性的时候需要全局锁,可能会增加数据库hang住的风险,并且容易对在线业务造成影响,且DBA一般不给锁权限。
-
不支持水平扩展
单并发,全量读取时数据量大的时候,耗时很长
-
全量读取时不支持checkpoint
CDC读取分为两个阶段,全量读取和增量读取。1.x在全量读取阶段失败后需要重新全部读取。
3.2 设计目标
2.0的设计目标就是为了解决1.x的痛点
- 无锁
- 水平扩展
- 支持checkpoint
3.2.1 引入【Debezium 锁分析】
Flink CDC 底层封装了Debezium,那我们先来了解下Debezium的锁机制
Debezium 同步一张表分为两个阶段:
- 全量阶段:查询当前表中所有记录
- 增量阶段:从binlog中消费变更数据
大部分用户使用的场景都是全量+ 增量同步,加锁是发生在全量阶段,目的是为了确定全量阶段的初始位点,保证增量+ 全量实现一条不多,一条不少,从而保证数据一致性。从下图中我们可以分析全局锁和表锁的一些加锁流程,左边红色线条是锁的生命周期,右边是MySQL 开启可重复读事务的生命周期。
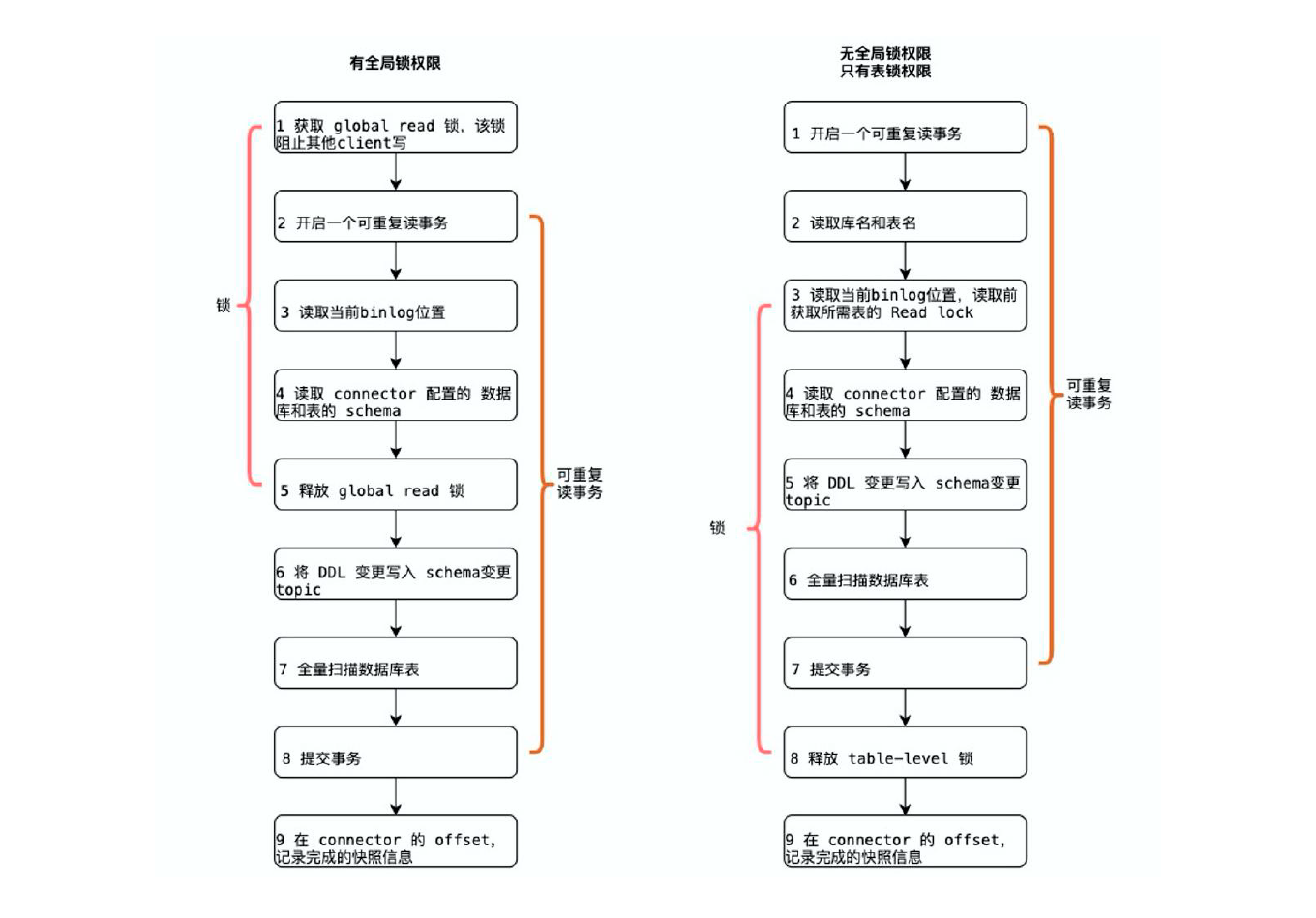
以全局锁为例, 首先是获取一个锁, 然后再去开启可重复读的事务。这里加锁范围是读取binlog 的当前位点和当前表的schema。这样做的目的是保证binlog 的起始位置和读取到的当前schema 是可以对应上的,因为表的schema 是会改变的,比如删除列或者增加列。在读取这两个信息后,SnapshotReader 会在可重复读事务里读取全量数据,在全量数据读取完成后,会启动BinlogReader 从读取的binlog 起始位置开始增量读取,从而保证全量数据+ 增量数据的无缝衔接。
表锁是全局锁的退化版,因为全局锁的权限会比较高,因此在某些场景,用户可能没有全局锁的权限,但是有表锁的权限。不过表锁的加锁时间会更长,因为表锁有个特征:锁提前释放了可重复读的事务默认会提交,所以锁需要等到全量数据读完后才能释放。
不管是全局锁还是表级锁,这些锁到底会造成怎样严重的后果:

Flink CDC 1.x 默认使用全局锁,保证了数据一致性,但存在上述hang 住数据的风险。因此,Flink CDC 1.x 也提供显式配置关闭加锁操作,但可能会导致数据准确性问题。
3.3 设计实现

借鉴了Netflix的DBlog的无锁设计思想:
3.3.1 整体概览
对有主键的表 + 初始化模式,整体的流程主要分为以下5个阶段:
step1.Chunk切分
step2.Chunk分配
step3.Chunk读取
step4.Chunk汇报
step5.Chunk分配

3.3.2 Chunk切分
对于一张有主键的表,我们可以根据表的主键对表中的数据进行分片。假设100条记录的表,key为[1,100]我们按照步长10来进行切分,按左闭右开或者左开右闭那么切分成了(null,10),[10,20),…,[90,100),[100,null)
相当于把表切分成了
chunk-0:(null,10)
…
chunk-10:[100,null)这就是chunk切分的过程,通过切分,我们得到多个chunk,然后我们再并发的对每个chunk分别进行全量读取和增量读取,这样就解决了水平扩展的问题。也就是说当数据量很大时,我们全量读取的时候不再是单并发,可以做到多并发,大大提高读取效率。
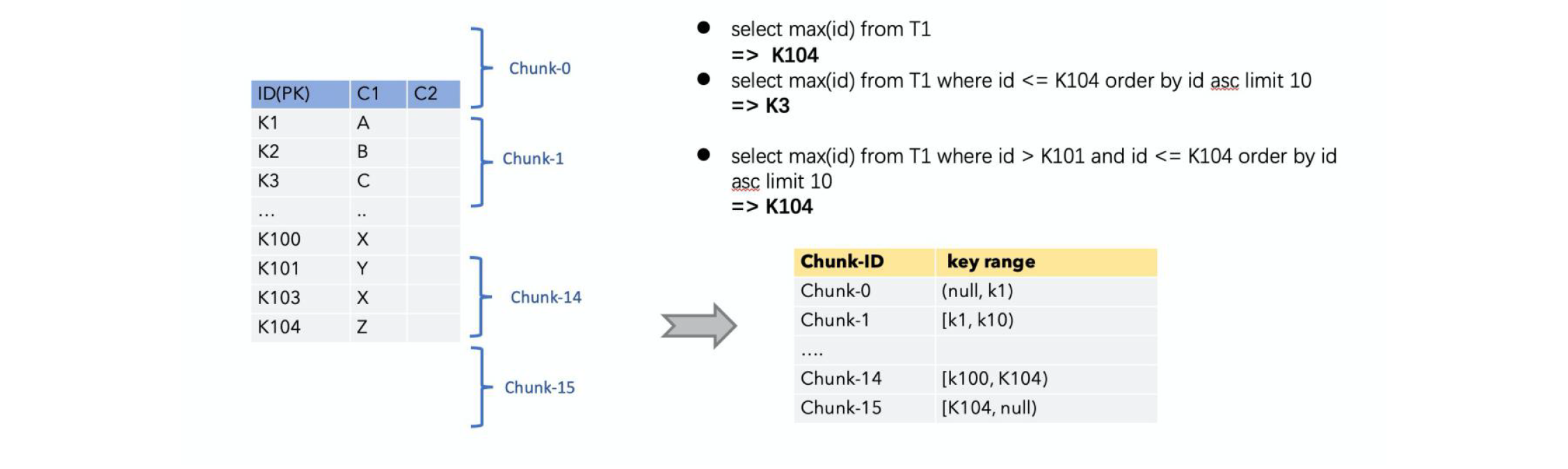
切分算法描述:

3.3.3 Chunk读取
因为每个chunk 只负责自己主键范围内的数据,不难推导,只要能够保证每个Chunk 读取的一致性,就能保证整张表读取的一致性,这便是无锁算法的基本原理。
如何实现单个chunk的读取在没有锁的情况下保证一致性呢?
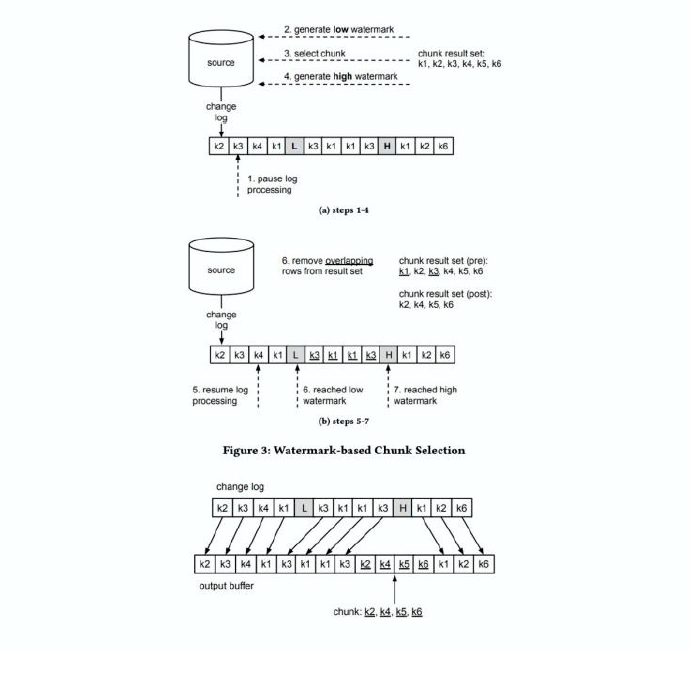
整个思想是借鉴了Netflix 的DBLog 论文中Chunk 读取的无锁算法:
Netflix 的DBLog 论文中Chunk读取算法是通过在数据库中维护一张信号表,再通过信号表在binlog文件中打点,记录每个chunk 读取前的Low Position (低位点) 和读取结束之后High Position (高位点) ,在低位点和高位点之间去查询该Chunk的全量数据。在读取出这一部分Chunk 的数据之后,再将这2个位点之间的binlog增量数据合并到chunk所属的全量数据,从而得到高位点时刻该chunk 对应的全量数据。
解释:假如现在有一张表a,里面就两条记录(zhangsan, 男, 20), (李四, 男, 30) ,在读取之前,我们记录下当前位点(Low Position)假设位置为1,假设在读完第一条记录的时候,我们做了一些其它操作(增删查改)删了性别这一列,然后我们读取完第二条记录(李四,30)。我们得到的全量数据为(zhangsan, 男, 20),(李四,30),读取完之后记录位点(High Position)假设是2。此时我们需要拿读取到的数据和 binlog中Low Position到High Position的操作去做一个合并,这里的合并不是拿我们读取的全量数据去执行从Low Position到High Position的所有操作。而是以操作最后的结果为准得到在High Position点的全量数据。
Flink CDC 结合自身的情况,在Chunk 读取算法上做了去信号表的改进,不需要侵入业务去额外维护信号表,直接通过读取binlog 位点替代在binlog 中做标记的功能,整体的chunk 读算法描述如下图所示:
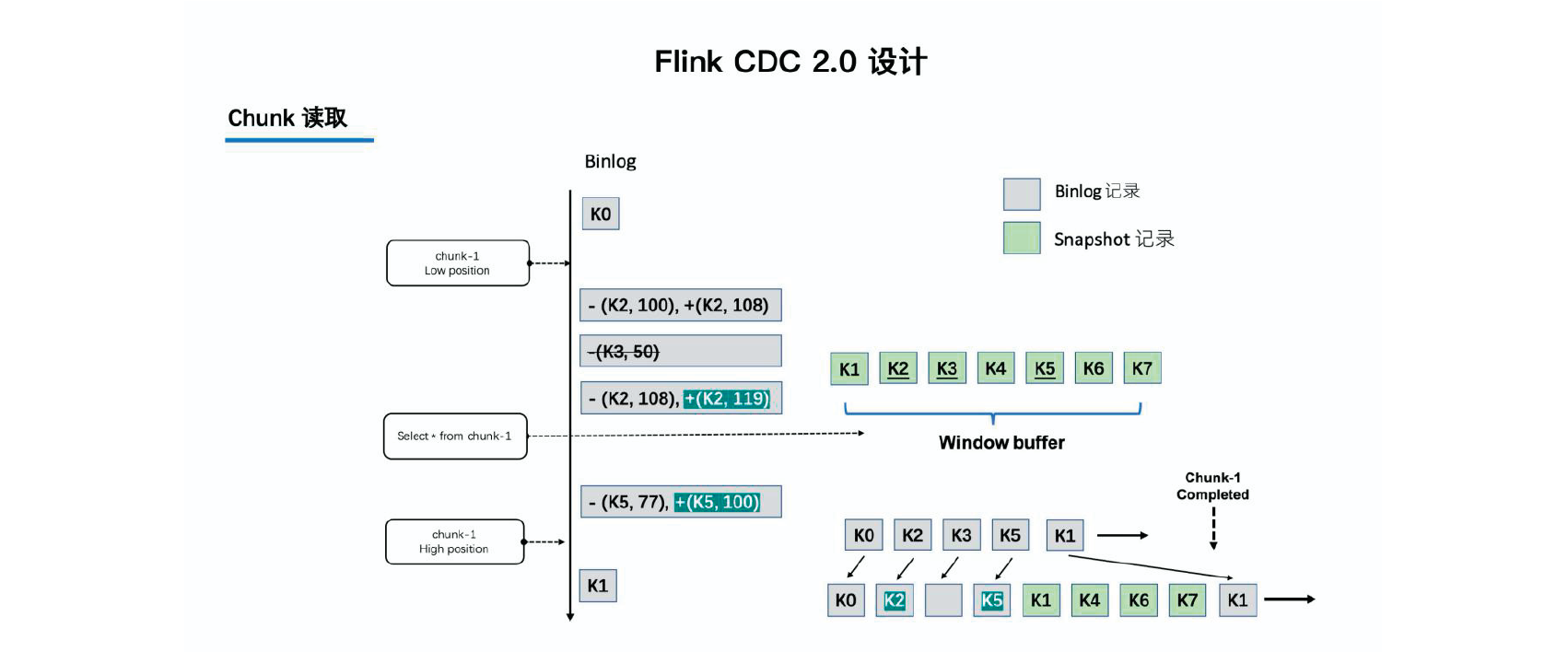
比如正在读取Chunk-1,Chunk 的区间是[K1, K10],首先直接将该区间内的数据select 出来并把它存在buffer 中,在select 之前记录binlog 的当前位点(低位点),select 完成后再次记录binlog 的当前位点(高位点)。然后开始消费从低位点到高位点的binlog,并合并到buffer 中。
其实就是把地位点、高位点存在信号表换成了存在buffer中
- 图中的-(k2,100) 和+(k2,108) 记录表示这条数据的值从100 更新到108;
- 第二条记录是删除k3;
- 第三条记录是更新k2 为119;
- 第四条记录是k5 的数据由原来的77 变更为100。
观察图片中右下角最终的输出,会发现在消费该chunk 的binlog 时,出现的key 是k2、k3、k5,我们前往buffer 将这些key 做标记。
-
对于k1、k4、k6、k7 来说,在高位点读取完毕之后,这些记录没有变化过,所以这些数据是可以直接输出的;
-
对于改变过的数据,则需要将增量的数据合并到全量的数据中,只保留合并后的最终数据。例如,k2 最终的结果是119 ,那么只需要输出+(k2,119),而不需要中间发生过改变的数据。
通过这种方式,Chunk 最终的输出就是该chunk 区间在高位点对应的一致性快照数据。
3.3.4 Chunk分配
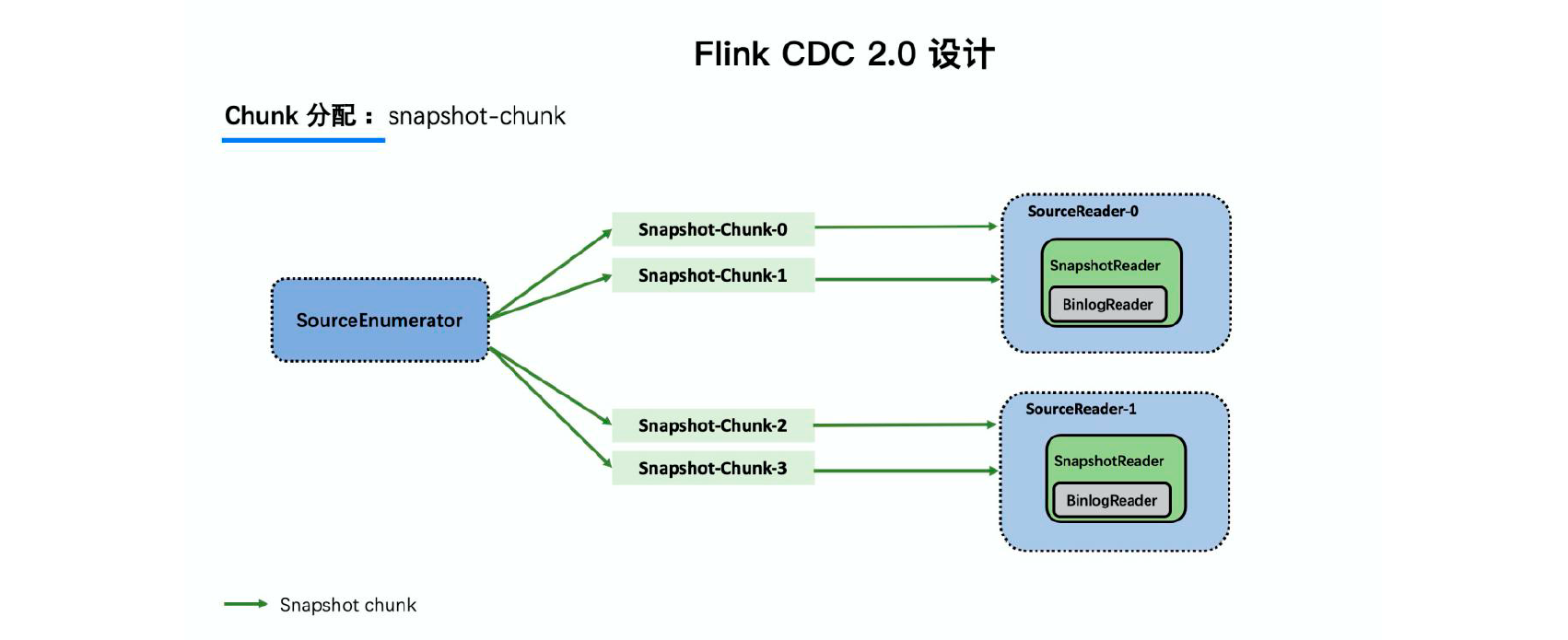
上面我们讲述了单个Chunk 的一致性读,但是如果有多个表分了很多不同的Chunk,且这些Chunk 分发到了不同的task 中,那么如何分发Chunk 并保证全局一致性读呢?
这个就是基于FLIP-27 来优雅地实现的,通过下图可以看到有SourceEnumerator 的组件,这个组件主要用于Chunk 的划分,划分好的Chunk 会提供给下游的SourceReader 去读取,通过把chunk 分发给不同的SourceReader 便实现了并发读取Snapshot Chunk 的过程,同时基于FLIP-27 我们能较为方便地做到chunk 粒度的checkpoint。
3.3.5 Chunk汇报
当Snapshot Chunk 读取完成之后,需要有一个汇报的流程,如下图中橘色的汇报信息,将Snapshot Chunk 完成信息汇报给SourceEnumerator。
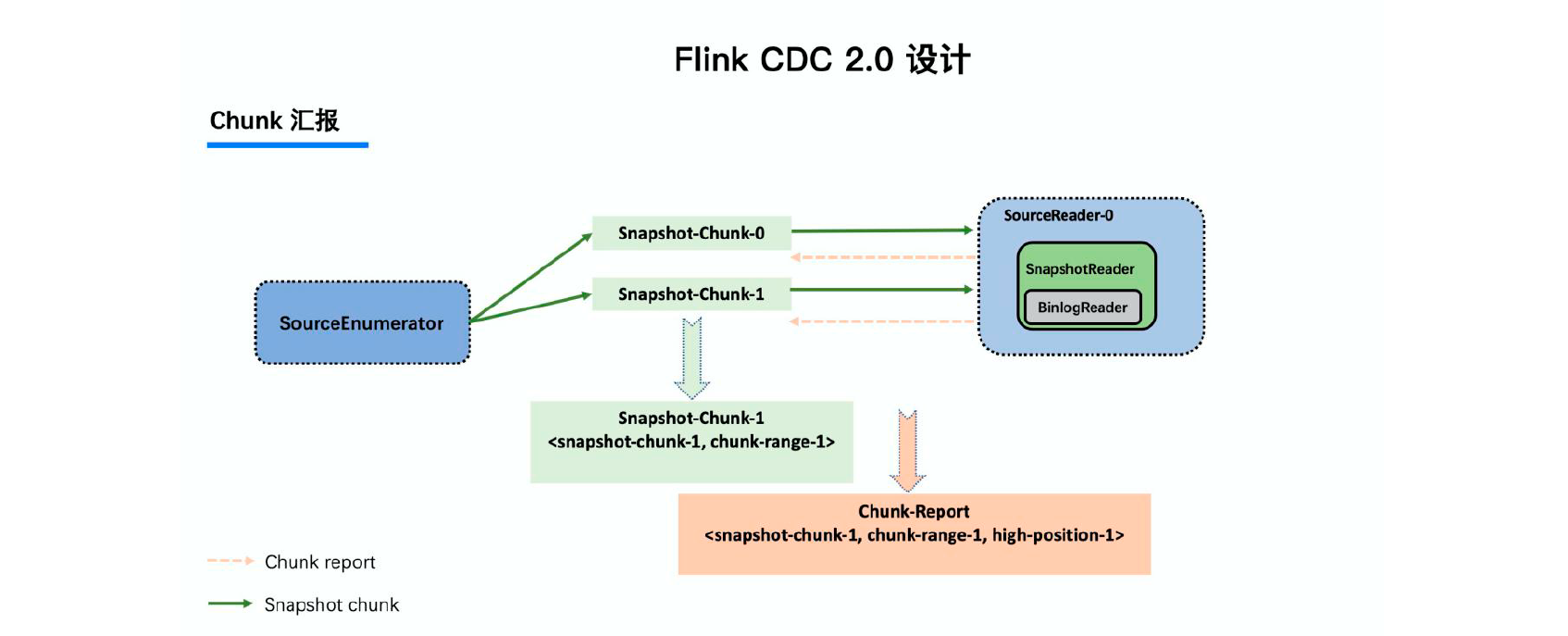
汇报的主要目的是为了后续分发binlog chunk (就是告知全量阶段已经完成,可以开始后续的增量阶段)。因为Flink CDC 支持全量+ 增量同步,所以当所有Snapshot Chunk 读取完成之后,还需要消费增量的binlog。
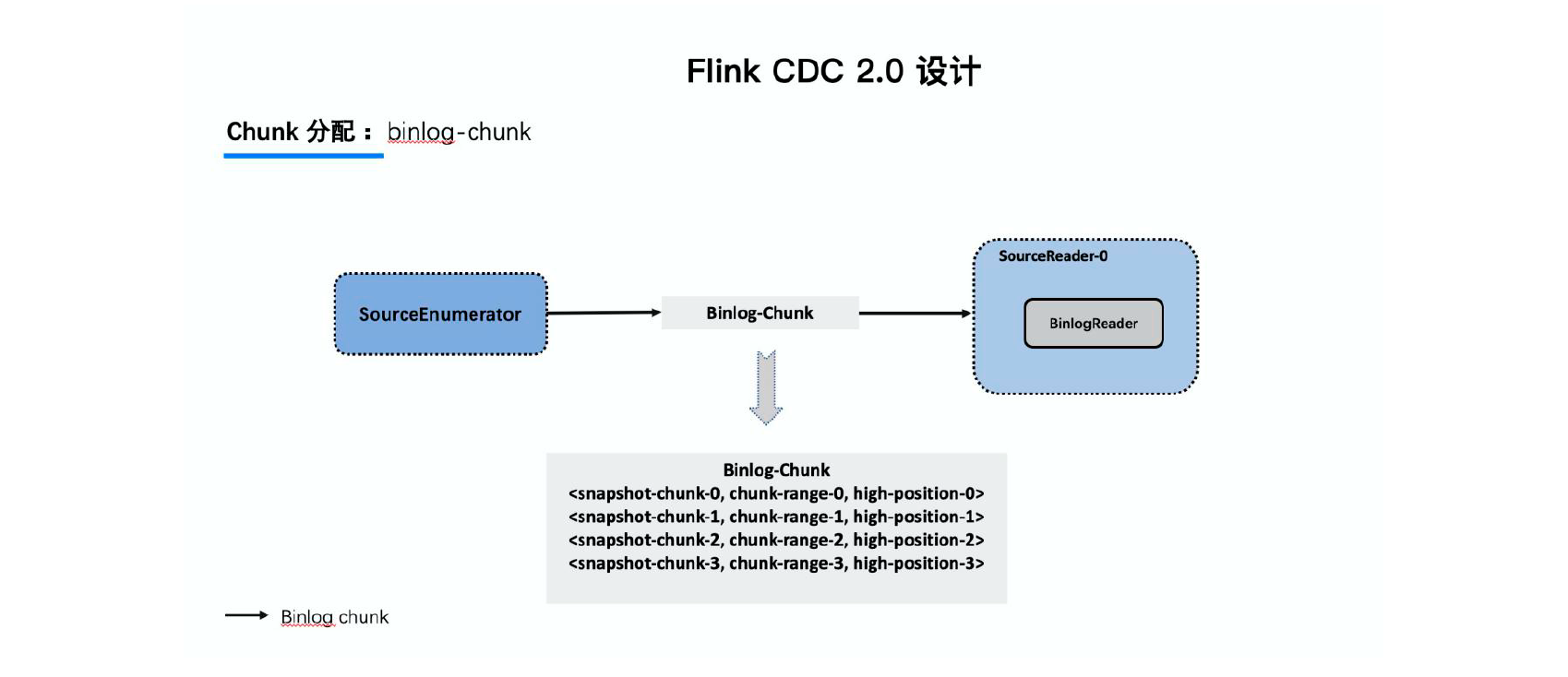
3.3.6 Chunk分配
所以当所有Snapshot Chunk 读取完成之后,还需要消费增量的binlog,这是通过下发一个binlog chunk 给任意一个Source Reader 进行单并发读取实现的。
3.3.7 总结
整体流程:
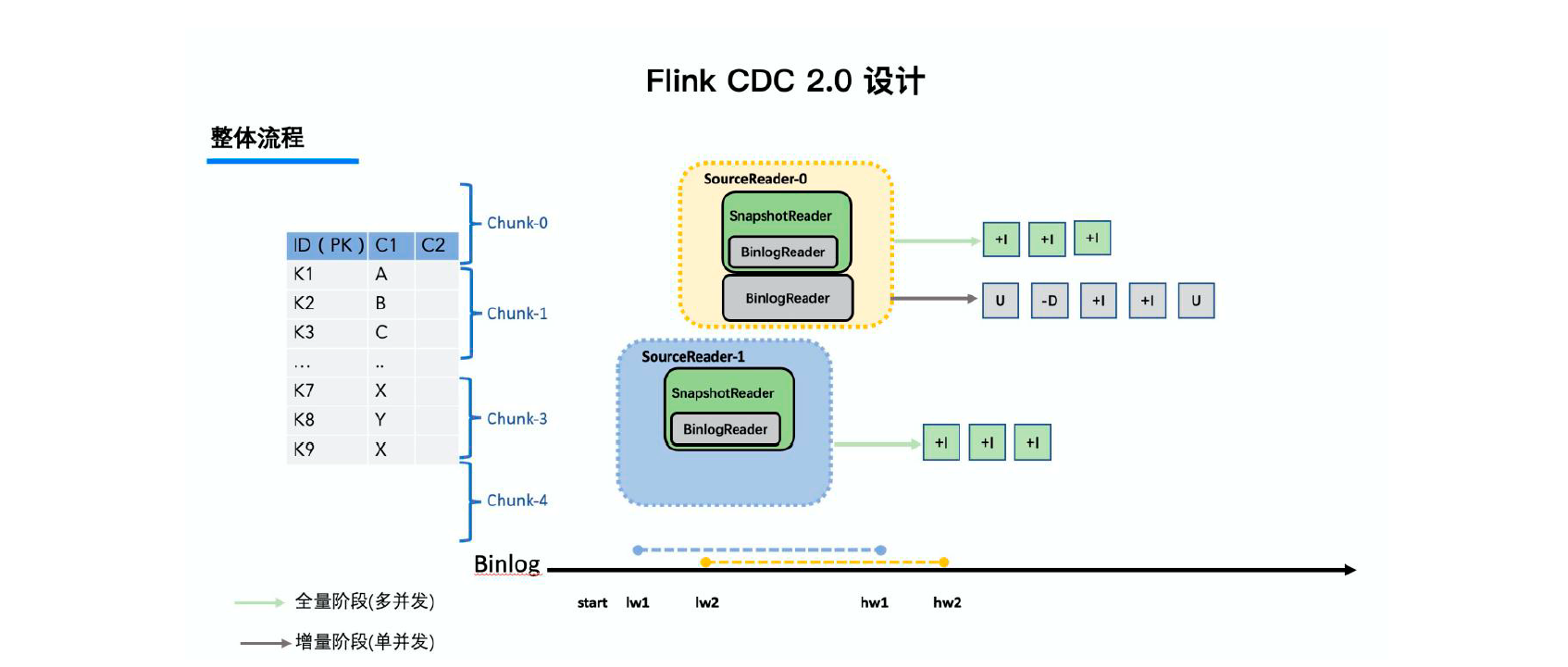
通过主键对表进行Snapshot Chunk 划分->将Snapshot Chunk 分
发给多个SourceReader,每个Snapshot Chunk 读取时通过算法实现无锁条件下的一致性读,
SourceReader 读取时支持chunk 粒度的checkpoint->所有Snapshot Chunk 读取完成后,
下发一个binlog chunk 进行增量部分的binlog 读取
提供MySQL CDC 2.0,核心feature 包括:
○ 并发读取,全量数据的读取性能可以水平扩展;
○ 全程无锁,不对线上业务产生锁的风险;
○ 断点续传,支持全量阶段的checkpoint。