MySQL 8 数据清洗三要素:
- 库表拷贝和数据备份
- 数据清洗SQL
- 数据清洗必杀技-存储过程
前提:数据库关联库表初始化和基础数据初始化:
-- usc.t_project definitionCREATE TABLE `t_project` (`id` varchar(64) NOT NULL COMMENT '主键',`tid` varchar(64) NOT NULL COMMENT 'TID',`ptid` varchar(64) NOT NULL COMMENT 'PTID',`project_no` varchar(64) DEFAULT NULL COMMENT '项目编号',`project_name` varchar(128) NOT NULL COMMENT '项目名称',`project_address` varchar(128) NOT NULL COMMENT '项目地址',`is_delete` int NOT NULL DEFAULT '0' COMMENT '删除标识:0=未删除,1=已删除',PRIMARY KEY (`id`),UNIQUE KEY `t_project_id_IDX` (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;-- usc.t_arch definitionCREATE TABLE `t_arch` (`tid` varchar(64) NOT NULL COMMENT 'TID',`ptid` varchar(64) NOT NULL COMMENT 'PTID',`id` varchar(64) NOT NULL COMMENT '主键',`project_id` varchar(64) NOT NULL COMMENT '项目ID',`project_no` varchar(100) NOT NULL COMMENT '项目编号',`arch_name` varchar(128) NOT NULL COMMENT '案卷名称',`arch_no` varchar(128) NOT NULL COMMENT '案卷编号',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;上述库表的关系:1:N = 项目 :案卷
-- 项目基础数据
INSERT INTO usc.t_project (id,tid,ptid,project_no,project_name,project_address,is_delete) VALUES('1','430100','430000','1001','长沙国金中心','长沙市芙蓉区', 0),('2','430100','430000','1001','长沙国金中心','长沙市芙蓉区', 0);
-- 案卷基础数据
INSERT INTO usc.t_arch (tid,ptid,id,project_id,project_no,arch_name,arch_no) VALUES('430100','430000','1','1','1001','案卷一','案卷一'),('430100','430000','2','2','1002','案卷二','案卷二'),('430100','430000','3','2','1002','案卷三','案卷三');
库表拷贝和数据备份
在MySQL 8 客户端 执行如下命令:
-- 复制t_project 表结构
create table t_project_2023_08_29 like t_project;-- 拷贝t_project 表的数据至t_project_2023_08_29
insert into t_project_2023_08_29 select * from t_project-- t_arch 执行如下命令, 注意替换相关表名
create table t_arch_2023_08_29 like t_arch ;insert into t_arch_2023_08_29 select * from t_arch数据清洗SQL
数据清洗的五要素:
- 确定数据清洗的筛选条件
- 确定数据清洗的数据记录
- 确定数据清洗的过滤条件
- 确定数据清洗的更新字段
- 数据清洗后的核验
实战:昨天晚上帮朋友写了一个Shell 脚本迁移******城建档案馆历史数据。今天跟我反馈迁移的历史项目信息存在重复情况,导致项目关联的案卷出现了缺失情况。
按照数据清洗的5要素一步步的来复盘,如何编写项目关联案卷的清洗SQL:
1、确定数据清洗的筛选条件:
select tp.tid, tp.ptid, tp.project_no from t_project tp group by tp.tid, tp.ptid, tp.project_no having(count(1)) > 1 此SQL功能含义:查询项目表以Tid\Ptid\Project_no 字段分组且数量大于1 的项目信息 。

上述截图标识:项目表存在重复记录的情况.
2、确定数据清洗的数据记录:
select * from t_arch ta
inner join (select tp.tid, tp.ptid, tp.project_no from t_project tp group by tp.tid, tp.ptid, tp.project_no having(count(1)) > 1) temp
on ta.tid = temp.tid and ta.ptid = temp.ptid and ta.project_no = temp.project_no此SQL功能含义:使用内联模式查询案卷表和项目表【条件添加:数据清洗的筛选条件】 。
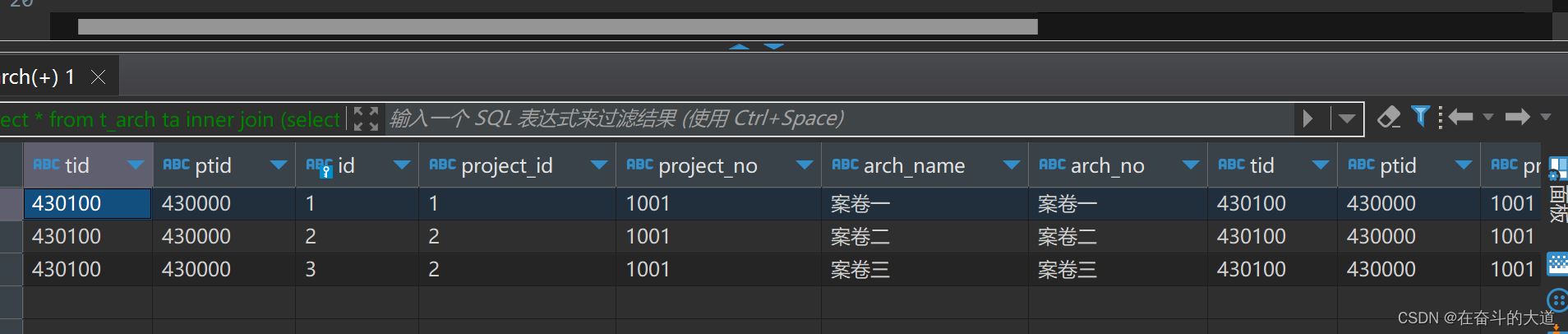 上述截图标识:案卷表需要进行数据清洗的记录数.
上述截图标识:案卷表需要进行数据清洗的记录数.
3、确定数据清洗的过滤条件
一般情况下过滤条件为:查询记录字段与关联从表关联字段。
select * from t_arch ta
inner join (select tp.tid, tp.ptid, tp.project_no from t_project tp group by tp.tid, tp.ptid, tp.project_no having(count(1)) > 1) temp
on ta.tid = temp.tid and ta.ptid = temp.ptid and ta.project_no = temp.project_no
where ta.project_id in (select tp.id from t_project tp where tp.tid = temp.tid and tp.ptid = temp.ptid and tp.project_no = temp.project_no
)此SQL功能含义:使用查询字段temp.tid\temp.ptid\temp.project_no 关联从表t_project,查询满足主表t_arch 关联的project_id。

上述截图标识:案卷表需要进行数据清洗的记录数并添加了相关条件进行筛选。
4、 确定数据清洗的更新字段
案卷表需要更新project_id 字段,同时将Select 语句修改为Update 语句。
update t_arch ta
inner join (select tp.tid, tp.ptid, tp.project_no from t_project tp group by tp.tid, tp.ptid, tp.project_no having(count(1)) > 1) temp
on ta.tid = temp.tid and ta.ptid = temp.ptid and ta.project_no = temp.project_no
set ta.project_id = (select min(tp.id) from t_project tp where tp.tid = temp.tid and tp.temp.ptid and tp.project_no = temp.project_no group by tp.tid, tp.ptid, tp.project_no limit 1)
where ta.project_id in (select tp.id from t_project tp where tp.tid = temp.tid and tp.ptid = temp.ptid and tp.project_no = temp.project_no
)重点:从表存在重复的情况,一般推荐使用:min/max函数 + group by +limit +筛选主表关联字段,查询出满足条件的从表字段进行Set。
(select min(tp.id) from t_project tp where tp.tid = temp.tid and tp.temp.ptid and tp.project_no = temp.project_no group by tp.tid, tp.ptid, tp.project_no limit 1)5、数据清洗后的核验
select * from t_arch ta
inner join (select tp.tid, tp.ptid, tp.project_no from t_project tp group by tp.tid, tp.ptid, tp.project_no having(count(1)) > 1) temp
此SQL功能含义:核查数据的清洗记录情况。

上述截图标识:与数据清洗筛选记录截图,我们明显发现project_id 字段已经全部替换为 1,但是数据核查的清洗记录SQL 还能查询出相关数据,但是t_arch 表管理的project_id 字段又是正确的因为t_project 表的数据还没有进行清洗。
数据清洗拓展
以下SQL 主要涉及T_Project 表数据的清洗
update t_project tainner join (select tp.tid, tp.ptid, tp.project_no from t_project tp group by tp.tid, tp.ptid, tp.project_no having(count(1)) > 1) tempon ta.tid = temp.tid and ta.ptid = temp.ptid and ta.project_no = temp.project_noset ta.is_delete = 1where ta.id not in (select min_id from (select min(tp.id) as min_id from t_project tp where tp.is_delete = 0 group by tp.tid, tp.ptid, tp.project_no having(count(1)) > 1) temp)重点:主表级联主表基于筛选条件构建的临时表。添加Where 条件为筛选主表重复记录的条件,并设置is_delete = 1.
温馨提示:
主表数据清理的条件为:主表重复记录条件
业务表级联主表数据清理条件为:查询满足条件记录的字段条件
主表数据清理SQL:
update t_project tainner join (select tp.tid, tp.ptid, tp.project_no from t_project tp group by tp.tid, tp.ptid, tp.project_no having(count(1)) > 1) tempon ta.tid = temp.tid and ta.ptid = temp.ptid and ta.project_no = temp.project_noset ta.is_delete = 1where ta.id not in (select min_id from (select min(tp.id) as min_id from t_project tp where tp.is_delete = 0 group by tp.tid, tp.ptid, tp.project_no having(count(1)) > 1) temp)从表级联主表数据清理SQL:
update t_arch ta
inner join (select tp.tid, tp.ptid, tp.project_no from t_project tp group by tp.tid, tp.ptid, tp.project_no having(count(1)) > 1) temp
on ta.tid = temp.tid and ta.ptid = temp.ptid and ta.project_no = temp.project_no
set ta.project_id = (select min(tp.id) from t_project tp where tp.tid = temp.tid and tp.temp.ptid and tp.project_no = temp.project_no group by tp.tid, tp.ptid, tp.project_no limit 1)
where ta.project_id in (select tp.id from t_project tp where tp.tid = temp.tid and tp.ptid = temp.ptid and tp.project_no = temp.project_no
)数据清洗必杀技-存储过程
如果数据清洗SQL 无法到达数据清洗的预期,那接下来我将使用存储过程实现数据清洗功能。
前提条件:
- 熟悉和了解MySQL 8 存储过程基本语法。
- 熟悉存储过程中的变量声明和赋值。
- 熟悉存储过程中的游标声明和遍历。
- 熟悉存储过程中的IF...ELSE 判断
- 熟悉存储过程中的运算符。
如果对于MySQL 8 存储过程的小白,建议参考学习:MySQL 8 一文读懂存储过程
项目和案卷清洗存储过程源码:
delimiter $
create procedure distanct_project()
begin-- 变量声明declare tid varchar(64);declare ptid varchar(64);declare project_no varchar(64);declare min_id varchar(64);-- 定义游标遍历标识符declare done int default 0;-- 游标定时declare project_cursor cursor for select tp.tid, tp.ptid, tp.project_no from t_project tp group by tp.tid, tp.ptid, tp.project_no having(count(1)) > 1;-- 游标全部遍历完成时,将游标遍历标识符设置为1declare continue handler for not found set done =1;-- 打开游标open project_cursor;-- 游标遍历read_project:LOOP-- 从游标中获取下一行数据FETCH project_cursor INTO tid, ptid, project_no;-- 判断是否已经遍历完所有行IF done THENLEAVE read_project;END IF;-- 查询select min(tp.id) into min_id from t_project tp where tp.tid = tid and tp.ptid = ptid and tp.project_no = project_no group by tp.tid, tp.ptid, tp.project_no limit 1;-- 从表更新update t_arch ta set ta.project_id = min_id where ta.tid =tid and ta.ptid =ptid and ta.project_no =project_no;-- 主表更新update t_project tp set tp.is_delete = 1where tp.tid =tid and tp.ptid = ptid and tp.project_no = project_no and tp.id <> min_id;END LOOP;-- 关闭游标CLOSE project_cursor;end $call distanct_project ();
温馨提示: 对于复杂的业务数据清洗,例如:商品房管理系统:项目-》楼栋-》房屋-》网签合同-》预售证 等多层级多维度的数据清洗,无非就是游标中嵌套游标,再进行select 查询插入最后执行IF...ELSE 判断执行insert/update 语句。
今天的分析就到这里结束。