四、高并发内存池整体框架设计
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。malloc本身其实已经很优秀,那么我们项目的原型TCmalloc就是在多线程高并发的场景下更胜一筹,所以这次我们实现的内存池需要考虑以下几方面的问题。
- 性能问题。
- 多线程环境下,锁竞争问题。
- 内存碎片问题。
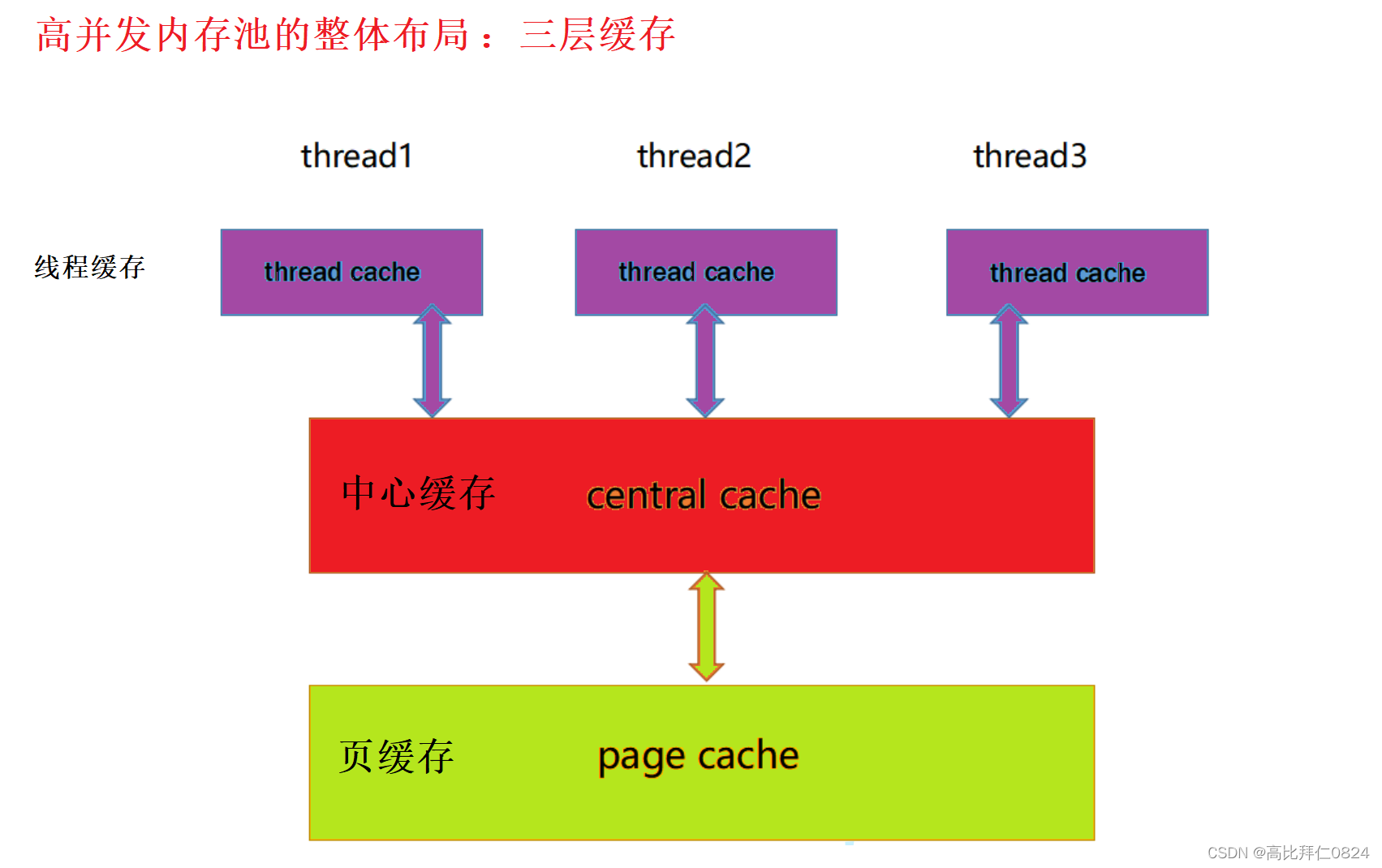
concurrent memory pool主要由以下3个部分构成:
1、thread cache:线程缓存是每个线程独有的,用于分配小于256KB的内存的,线程从这里申请内存不需要加锁,每个线程独享一个thread cache,这也就是这个并发线程池高效的地方。
2、central cache:中心缓存是所有线程所共享,thread cache是按需从central cache中获取的对象。central cache合适的时机回收thread cache中的对象,避免一个线程占用了太多的内存,而其他线程的内存不够用,达到内存分配在多个线程中更均衡的按需调度的目的。central cache是存在竞争的,所以从这里取内存对象是需要加锁,首先这里用的是桶锁,其次只有thread cache的没有内存对象时才会找central cache,所以这里竞争也就不会很激烈。
3、page cache:页缓存是在central cache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的,central cache没有内存对象时,从page cache分配出一定数量的page,并切割成定长大小的小块内存,分配给central cache。当一个span的几个跨度页的对象都回收以后,page cache会回收central cache满足条件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题,当central cache再一次向PageCache申请更大块内存的时候PageCache也能满足。
内存池三层模型中函数需要用到的公共的头文件–common.h
//能够申请的内存的最大值
static const size_t MAX_BYTES = 256 * 1024;
//thread_cache的哈希桶的数目
static const size_t NFREELIST = 208;
//PageCache中哈希桶的数量,每一个桶按照页数映射
//每一个页数对应的桶的span对象的大小就是页数,即第一页的span对象的大小是一页
static const size_t NPAGES = 129;
//页大小转换偏移, 即一页定义为2^13,也就是8KB
static const size_t PAGE_SHIFT = 13;//条件编译,为了适应不同平台
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;//页号
#endif#ifdef _WIN32
#include <windows.h>
#endif // _WIN32
//系统调用接口,直接向系统堆申请k页内存,脱离malloc函数
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage * (1 << PAGE_SHIFT),MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else// brk mmap等
#endifif (ptr == nullptr)throw std::bad_alloc();return ptr;
}
//系统调用接口,直接向系统堆释放内存,脱离free
inline static void SystemFree(void* ptr)
{
#ifdef _WIN32VirtualFree(ptr, 0, MEM_RELEASE);
#else// sbrk unmmap等
#endif
}//obj对象的前4个或者8个字节,存放的是obj的下一个对象的地址,相当于obj->next
static void*& NextObj(void* obj)
{return *(void**)obj;
}//管理切分好的小对象的自由链表
struct FreeList
{
public:void Push(void* obj){assert(obj);//头插NextObj(obj) = _freeList;_freeList = obj;_size++;}void PushRange(void* start,void* end,size_t n){assert(start);assert(end);NextObj(end) = _freeList;_freeList = start;调试技巧:1、条件断点2、调用堆栈3、中断程序//int i = 0;//while (start)//{// start = NextObj(start);// i++;//}//if (i != n)//{// int x = 0;//}_size += n;}//n表示删除了多少个,这里的删除并不是真的把空间释放了,而是把小对象从自由链表中解掉//即可,删除掉的这些小对象本质也是被外面调用方函数拿到了的,注意这里start和end是引用//输出型参数void PopRange(void*& start, void*& end, size_t n){assert(n <= _size);start = _freeList;end = start;//end走n-1步是为了修改end的next和更新_freeListfor (size_t i = 0; i < n - 1; i++){end = NextObj(end);}_freeList = NextObj(end);NextObj(end) = nullptr;//一定要注意置空_size -= n;}//这里的删除需要同时返回这个小对象void* Pop(){assert(_freeList);//头删void* obj = _freeList;_freeList = NextObj(obj);_size--;return obj;}size_t& MaxSize(){return _maxSize;}size_t Size(){return _size;}bool Empty(){return _freeList == nullptr;}public:void* _freeList = nullptr;//自由链表
private:size_t _maxSize = 1;size_t _size = 0;
};计算对象大小的对齐映射规则
class SizeClass
{
public:// 整体控制在最多10%左右的内碎片浪费// [1,128] 8byte对齐 freelist[0,16)// [128+1,1024] 16byte对齐 freelist[16,72)// [1024+1,8*1024] 128byte对齐 freelist[72,128)// [8*1024+1,64*1024] 1024byte对齐 freelist[128,184)// [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)//向上对齐计算对象大小//由于这里是按照一定规则对齐的,所以其实是会有内存碎片的(内碎片),即申请1字节也是给8字节,申请2字节//也是给8字节的,但是根据以上计算可以控制最多10%左右的内碎片浪费。static inline size_t RoundUp(size_t bytes){if (bytes <= 128){return _RoundUp(bytes, 8);}else if (bytes <= 1024){return _RoundUp(bytes, 16);}else if (bytes <= 8*1024){return _RoundUp(bytes, 128);}else if (bytes <= 64*1024){return _RoundUp(bytes, 1024);}else if (bytes <= 256*1024){return _RoundUp(bytes, 8 * 1024);}else{//以页为单位对齐return _RoundUp(bytes, 1 << PAGE_SHIFT);}}//计算某一对象映射的哈希桶的下标static inline size_t Index(size_t alignSize){assert(alignSize <= MAX_BYTES);//不同的对齐数对应的区间中有多少个哈希桶static int group[] = { 16,56,56,56 };if (alignSize <= 128){return _Index(alignSize, 3);}else if (alignSize <= 1024){return _Index(alignSize - 128, 4) + group[0];}else if (alignSize <= 8 * 1024){return _Index(alignSize - 1024, 7) + group[0] + group[1];}else if (alignSize <= 64 * 1024){return _Index(alignSize - 8 * 1024, 10) + group[0] + group[1] + group[2];}else if (alignSize <= 256 * 1024){return _Index(alignSize - 64 * 1024, 13) + group[0] + group[1] + group[2] + group[3];}else{//alignSize太大就无法映射到哈希桶中了,这时应该直接断言错误即可assert(false);return -1;}}//计算当有线程申请一个size大小的内存块时,threadcache对应哈希桶没有内存块//时一次向central cache申请多少个size大小的内存块,多的挂到threadcache//对应的哈希桶中,这个是大佬们研究之后得出来的算法static size_t NumMoveSize(size_t size){int n = MAX_BYTES / size;if (n < 2){return 2;}else if (n > 512){return 512;}else{return n;}}//计算当CentralCache对应位置的哈希桶中没有空闲的span的时候向PageCache//申请多少页大小的span对象,这个是别人通过测试得出来的算法static size_t NumMovePage(size_t size){size_t num = NumMoveSize(size);size_t npage = num * size;npage >>= PAGE_SHIFT;if (npage == 0){npage = 1;}return npage;}private:static inline size_t _RoundUp(size_t bytes, size_t alignNum/*对齐数*/){//对齐之后的大小//size_t alignSize;//if (bytes % alignNum == 0)//{// alignSize = bytes;//}//else//{// alignSize = (bytes / alignNum + 1) * alignNum;//}//return alignSize;return (bytes + alignNum - 1) & ~(alignNum - 1);}//static inline size_t _Index(size_t alignSize, size_t align)//{// int index;// if (alignSize % (1 << align) != 0)// {// index = alignSize / align;// }// else// {// index = alignSize / align - 1;// }// return index;//}static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}
};//以页为单位的大块内存,1页=8k=8*1024字节
struct Span
{PAGE_ID _pageId = 0;//Span大块内存的起始页号,页号相当于一个地址,描述这个大块内存的位置size_t _n = 0;//页数,代表这个Span有多少页内存,表示这个Span的大小Span* _next = nullptr;//用双向链表结构组织起来Span* _prev = nullptr;void* _freeList = nullptr;//用Span切好的小块内存的自由链表size_t _useCount = 0;//记录Span切好的小块内存被使用的数量,方便后续归还内存size_t _objSize = 0;//记录该span被切成的小块内存的大小,让释放内存时不用传大小//表示该span是否正在被使用,如果span在PageCache,则认为该span没有被使用//可以在PageCache和前后的空闲页合并,如果span被分到CentralCache,则说明//该span被使用,不能被合并bool _isUse = false;};//用带头双向链表结构把多个Span组织起来
class SpanList
{
public:SpanList(){//哨兵位的头节点_head = new Span;_head->_next = _head;_head->_prev = _head;}void PushFront(Span* newSpan){Insert(Begin(), newSpan);}bool Empty(){return _head->_next == _head;}Span* PopFront(){Span* front = Begin();Erase(Begin());return front;}Span* Begin(){return _head->_next;}Span* End(){return _head;}void Insert(Span* pos, Span* newSpan){assert(pos);assert(newSpan);Span* prev = pos->_prev;prev->_next = newSpan;newSpan->_prev = prev;newSpan->_next = pos;pos->_prev = newSpan;}void Erase(Span* pos){assert(pos != _head);Span* prev = pos->_prev;Span* next = pos->_next;prev->_next = next;next->_prev = prev;}
private:Span* _head;public://桶锁,因为全局只有一个central cache,如果有多个线程同时访问同一个桶的时候//会有线程安全的问题,所以需要加锁,但是多个线程同时访问到同一个桶的概率不大//所以锁竞争没有那么激烈std::mutex _mtx;
};