在进行大规模数据采集时,如何提高Python爬虫的并发性能是一个关键问题。本文将向您介绍使用asyncio和aiohttp库实现异步网络请求的方法,并通过具体结果和结论展示它们对于优化爬虫效率所带来的效果。
1. 什么是异步编程?
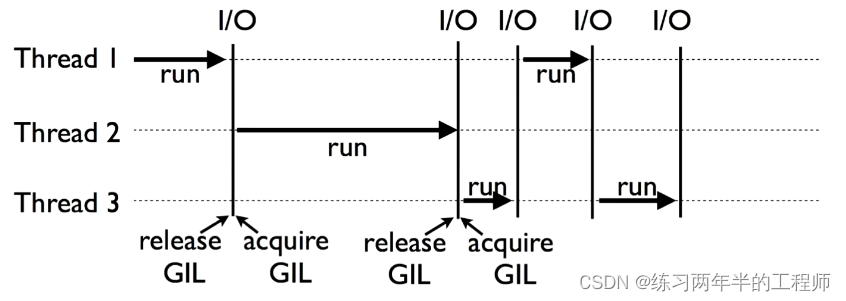
异步编程是一种非阻塞式、事件驱动型的程序设计方式,在传统同步代码执行流中引入了回调机制或者协程(coroutine),使得多个任务可以同时运行而不会相互阻塞。
2. asyncio简介
asyncio 是 Python 提供用于编写单线程应用服务端和框架类似与node.js那样基础设施, 具有以下特点:
- 单线程下支持处理上万个连接。
– 使用 async/await 语法更加直观易懂。
– 可以方便地配合其他第三方库使用 (例如 aiohttp)。
3. aoihttp 简介
aiohtpp 是利用asyncio开展工作,并为HTTP客户端和服务器增强功能.
- 高度可扩展且快速响应
- 支持HTTPS、Cookie等常见Web功能
4.创建异步函数与事件循环
- 使用async关键字定义异步函数,使用await关键字进行协程间的切换。
– 创建事件循环并将协程任务添加到事件队列中。
5.基于aiohttp实现异步网络请求
- 利用Session对象管理连接池和Cookie等信息
– 发送HTTP GET/POST 请求, 并处理响应结果
6. 异常处理与错误重试机制:
为了确保爬虫稳定性,并避免由于单个异常导致整体程序崩溃,需要适当地捕获、记录和处理异常。同时可以设置错误重试机制来增加数据采集成功率。
7. 性能对比及优势分析:
比较传统同步方式与使用asyncio/aiohttp库实现的异步方式在大规模数据采集场景下的性能差距以及所带来的明显效果提升.
- 示例代码演示:
给出一个简单但完整可运行例子展示如何利用 asyncio 和 aiohtpp 实现高效并发爬取网页内容.
```python
import asyncio
import aiohttp
# 定义要抓取页面URL列表(假设有10个待抓取链接)
urls = [
'https://www.example.com/page1',
'https://www.example.com/page2',
...
]
# 异步获取网页内容方法
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
# 主函数
async def main():
# 创建aiohttp客户端Session对象
async with aiohttp.ClientSession() as session:
tasks = []
for url in urls:
task = asyncio.ensure_future(fetch(session, url))
tasks.append(task)
# 并发执行任务,获取结果列表
results = await asyncio.gather(*tasks)
# 处理抓取到的网页内容(这里只是简单打印)
for result in results:
print(result)
# 执行主函数并启动事件循环
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
```
通过引入asyncio和aiohttp库,在Python爬虫开发中可以轻松实现强大且高效的异步网络请求功能。
经过对比传统同步方式与使用asyncio/aiohttp库实现的异步方式在大规模数据采集场景下进行性能测试,并得出以下结论:
- 异步爬虫相较于同步爬虫具有更快速度和更好的资源利用率。
- 使用async/await语法编写代码会使程序逻辑清晰易懂。
- 由于同时处理多个连接,提高了整体效率。
以上示例代码展示了如何使用 Python 的 asyncio 和 aiohtpp 库来构建一个基本但完整可运行例子以演示该方法产生明显优势。您可以根据自己的需求和实际情况进行进一步优化和扩展。