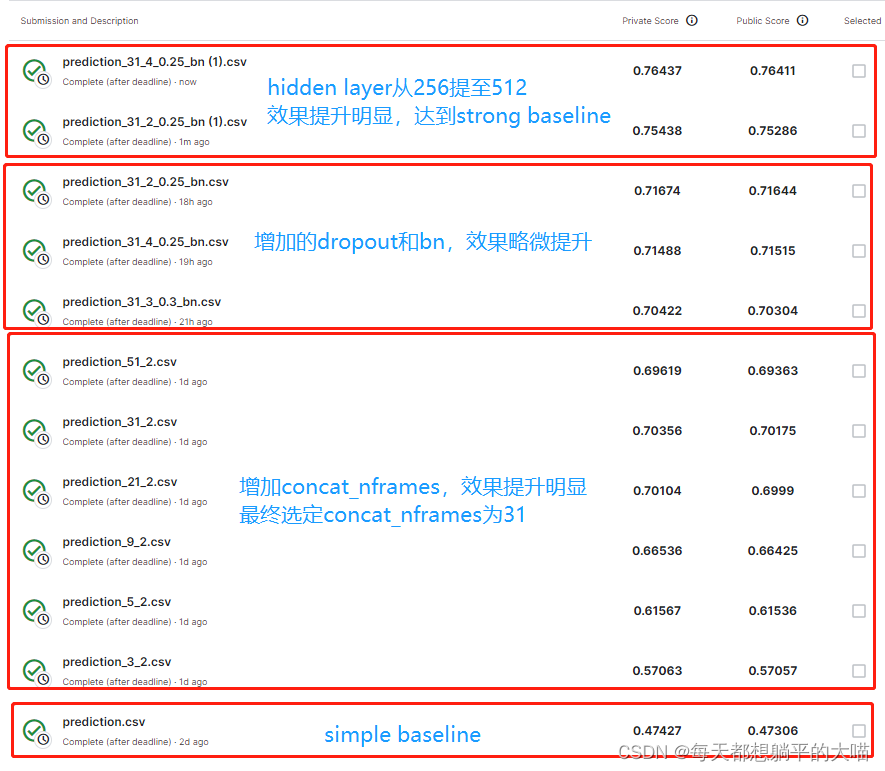
strong baseline上分路线
- baseline
- 增加concat_nframes (提升明显)
- 增加batchnormalization 和 dropout
- 增加hidden layer宽度至512 (提升明显)
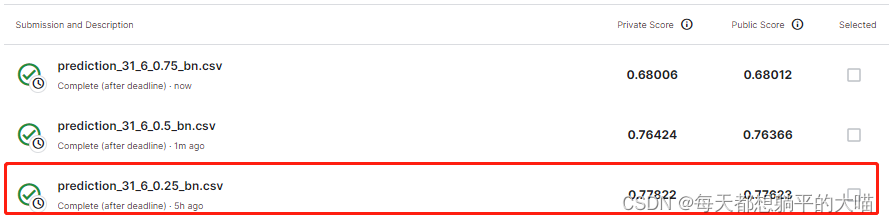
提交文件命名规则为 prediction_{concat_nframes}[{n_hidden_layers}{dropout}_bn].csv
report
-
(2%) Implement 2 models with approximately the same number of parameters, (A) one narrower and deeper (e.g. hidden_layers=6, hidden_dim=1024) and (B) the other wider and shallower (e.g. hidden_layers=2, hidden_dim=1700). Report training/validation accuracies for both models.
A: hidden_layers=6, hidden_dim=1024 (每一层加了dropout 0.25 和bn)
[200/200] Train Acc: 0.843977 Loss: 0.454965 | Val Acc: 0.775733 loss: 0.789337B: hidden_layers=2, hidden_dim=1700 (每一层加了dropout 0.25 和bn)
[200/200] Train Acc: 0.919308 Loss: 0.229898 | Val Acc: 0.750871 loss: 0.995369看下来,在这里,同样参数量下,更深的模型效果更好。另外对比一下B和之前上分路线中的 prediction_31_2_0.25_bn.csv,可以看出来,在2层模型结构中,hidden layer从512增加到1700后,效果就没有提升了(之前从256增加到512时,提升效果显著)。

-
(2%) Add dropout layers, and report training/validation accuracies with dropout rates equal to (A) 0.25/(B) 0.5/© 0.75 respectively.
这里就用1里面的A模型结构吧,只是改一下dropout大小
A: 0.25[200/200] Train Acc: 0.919308 Loss: 0.229898 | Val Acc: 0.750871 loss: 0.995369B:0.5
[200/200] Train Acc: 0.724419 Loss: 0.884636 | Val Acc: 0.761631 loss: 0.752881C:0.75
[200/200] Train Acc: 0.604394 Loss: 1.355784 | Val Acc: 0.675998 loss: 1.072153对比A和B,dropout增大后,train Acc降低了很多,而Val Acc略微提升,原本以为B会在Kaggle上表现更好,但实际上还是A的Kaggle表现最好。再看B中的train和Val Acc,会注意到train 的Acc 是低于val 的Acc的,有可能B在val上过拟合了。