1.SQLAlchemy是什么?
SQLAlchemy 是 Python 著名的 ORM 工具包。通过 ORM,开发者可以用面向对象的方式来操作数据库,不再需要编写 SQL 语句。
SQLAlchemy 支持多种数据库,除 sqlite 外,其它数据库需要安装第三方驱动。
2. 使用数据库连接池说明
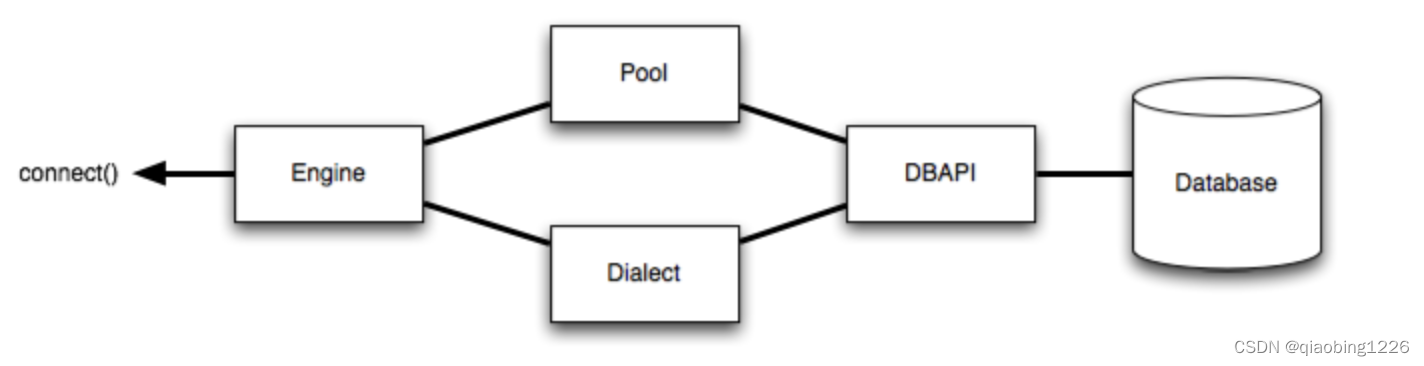
Engine 对象是使用 sqlalchemy 的起点,Engine 包括数据库连接池 (Pool) 和 方言 (Dialect,指不同数据库 sql 语句等的语法差异),两者一起把对数据库的操作,以符合 DBAPI 规范的方式与数据库交互。
3.工具类展示
3.1 数据库配置类:db_config.py
# dev环境配置
host = "dev-pg.test.xxxx.cloud"
port = 1921
user = "check"
database = "checkn"
password = "Ku2221AP123aXsNW"
# 连接池大小,默认为5,设置为0时表示连接无限制
pool_size = 10
# 连接池中最大连接数,如果访问数据库的请求数超过了pool_size,连接池将会自动创建新的连接,
# 直到创建达到max_overflow个连接为止。默认情况下,max_overflow值为10
max_overflow = 20
# 连接池中获取连接的等待时间,超过该等待时间后,获取连接方法将会超时,引发连接失败异常。默认情况下,timeout为30秒。
pool_timeout = 60
3.2 数据库类封装:database.py
# !/usr/bin/python
# -*- coding: UTF-8 -*-from sqlalchemy import *
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import Session
from sqlalchemy.ext.declarative import declarative_baseimport db_configclass dbTools(object):session = None;isClosed = True;def open(self, host=db_config.host, port=db_config.port, db=db_config.database, user=db_config.user,pwd=db_config.password, pool_size=db_config.pool_size, max_overflow=db_config.max_overflow,pool_timeout=db_config.pool_timeout):url = 'postgresql://%s:%s@%s:%d/%s' % (user, pwd, host, port, db)# echo: 设置为ture时,会将orm语句转化成sql语句并打印出来,一般debug时候使用engine = create_engine(url, poolclass=QueuePool, pool_size=pool_size, max_overflow=max_overflow,pool_timeout=pool_timeout, echo=True)DbSession = sessionmaker(bind=engine)self.session = DbSession()self.isClosed = Falsereturn self.sessiondef query(self, type):query = self.session.query(type)return querydef execute(self, sql):return self.session.execute(sql)def add(self, item):self.session.add(item)def add_all(self, items):self.session.add_all(items)def delete(self, item):self.session.delete(item)def commit(self):self.session.commit()def close(self):if self.isClosed:passself.session.close()self.isClosed = True
3.3 模型类 modeBatchInfo.py
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import String, Column, Integer, DateTime, Enum, Table, ForeignKey, Text
from sqlalchemy.orm import relationship# 创建Base类
Base = declarative_base()# 创建ORM模型类
class icsBatchInfo(Base):__tablename__ = 'ics_batch_info'batch_id = Column(Integer, primary_key=True)process_id = Column(String)task_id = Column(String)data_path = Column(Text)project_id = Column(String)user_name = Column(String)user_type = Column(String)status = Column(String)start_time = Column(DateTime)end_time = Column(DateTime)confidence_code = Column(String)repair_code = Column(String)report_count = Column(Integer)task_scope = Column(Text)adcity_code = Column(String)progress = Column(String)task_type = Column(String)job_id = Column(String)
3.4 开始使用工具类:main.py
# coding=utf-8
from database import dbTools
from modelBatchInfo import icsBatchInfo
from sqlalchemy import textif __name__ == "__main__":dbtools = dbTools()dbtools.open()# 打开一个文件with open('task.txt') as fr:# 读取文件所有行lines = fr.readlines()lines = [i.rstrip() for i in lines]list = []list.append("taskId,batchId\n")for taskId in lines:# 1. 使用对象查询# result = dbtools.query(icsBatchInfo).filter(icsBatchInfo.task_id == taskId).all()# nodes = dbtools.filter(icsBatchInfo.py.master == False).all()# 2. 使用sql查询sql = text("select * from ics_batch_info where batch_id=(select MAX(batch_id) from ics_batch_info WHERE task_id = '{taskId}')".format(taskId=taskId))result = dbtools.execute(sql)for batchInfo in result:list.append(batchInfo.task_id + "," + str(batchInfo.batch_id) + "\n")dbtools.close()list[len(list) - 1] = list[len(list) - 1].rstrip();with open("最大批次查询结果.csv", 'w') as fw:fw.writelines(list)print("☺☺☺执行完毕☺☺☺")
说明:
读取本目录下task.txt 中的任务号,去查数据库记录,并将需求查出来的内容写到本地csv文件"最大批次查询结果.csv" 文件。
上阶尽管费力,却一步比一步高。不经过琢磨,宝石也不会发光