摘要
Apache ShardingSphere 关注于全链路压测场景下,数据库层面的解决方案。 将压测数据自动路由至用户指定的数据库,是 Apache ShardingSphere 影子库模块的主要设计目标。
一、压测背景
在基于微服务的分布式应用架构下,业务需要多个服务是通过一系列的服务、中间件的调用来完成,所以单个服务的压力测试已无法代表真实场景。 在测试环境中,如果重新搭建一整套与生产环境类似的压测环境,成本过高,并且往往无法模拟线上环境的复杂度以及流量。 因此,业内通常选择全链路压测的方式,即在生产环境进行压测,这样所获得的测试结果能够准确地反应系统真实容量和性能水平。
全链路压测是一项复杂而庞大的工作。 需要各个微服务、中间件之间配合与调整,以应对不同流量以及压测标识的透传。 通常会搭建一整套压测平台以适用不同测试计划。 在数据库层面需要做好数据隔离,为了保证生产数据的可靠性与完整性,需要将压测产生的数据路由到压测环境数据库,防止压测数据对生产数据库中真实数据造成污染。 这就要求业务应用在执行 SQL 前,能够根据透传的压测标识,做好数据分类,将相应的 SQL 路由到与之对应的数据源。
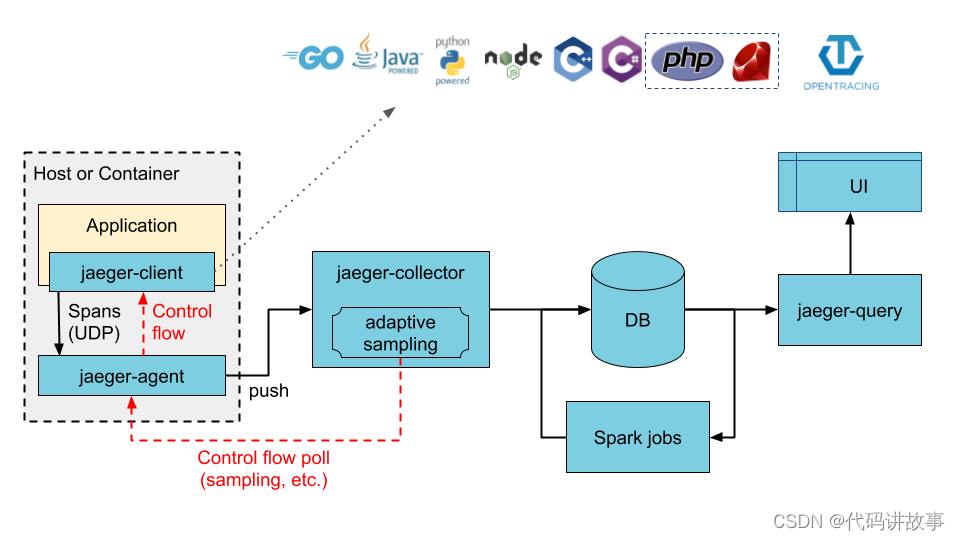
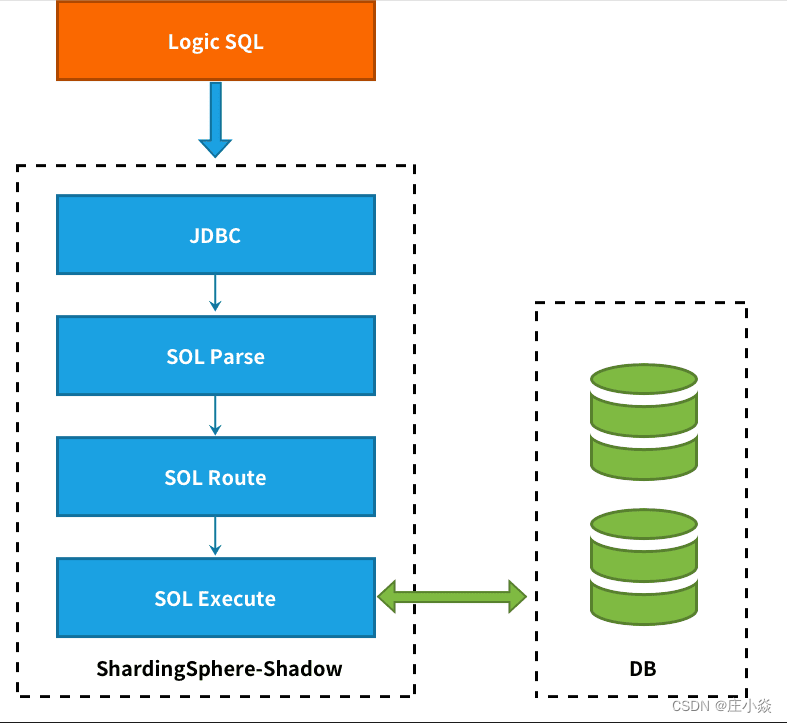
二、整体架构
博文参考
影子库 :: ShardingSphere