#服务器 #部署 #云原生 #k8s
一、 前言
一、ubuntu20.04上搭建containerd版( 1.2.4 以上)k8s及kuboard V3
接上文中,我们已经部署好了单节点master的k8s集群,在生产环境中,单节点的master肯定是不行的,那么我们如何对master进行集群的拓展呢?
对master拓展,实际上就是对api-server的拓展,只要对其做个负载均衡即可。
本文选型 haproxy + keepalive 方案来实现。当然也可以选择 nginx + keepalive。
二、 haproxy 介绍
HAProxy是一款专注于负载均衡和代理的高性能软件,它的核心功能就是负载均衡,能够有效地将来自客户端的请求分发到多个后端节点。
为什么选用 haproxy 而不是 nginx?
- HAProxy主要专注于高可用性和负载均衡,将客户端请求分发到多个服务器,以实现高性能和高可用性的应用部署。
- Nginx也可以用作反向代理和负载均衡,但它更广泛地被用于作为静态内容服务器和应用服务器,同时还能提供缓存、SSL终止等功能。
- HAProxy提供了丰富的负载均衡算法,可以根据需求选择合适的算法,例如加权轮询、最少连接、源IP哈希等,以更好地适应不同的应用场景。Nginx在负载均衡算法方面的选择相对较少。
这并不是说Nginx不适合用于Kubernetes集群的Master节点,而是在这个特定的场景下,HAProxy由于其专注性、负载均衡算法和高可用性特点,更容易满足Master节点集群的需求。
三、keepalive 介绍
Keepalived 是一个用于实现高可用性和故障转移的开源工具,它通常与负载均衡器(如HAProxy)等配合使用,以确保在集群中的服务器或服务发生故障时能够实现快速的切换和恢复,从而保证服务的持续可用性。
为什么有haproxy还需要keepalive?
尽管HAProxy可以实现负载均衡,但在发生主节点故障时,单独的HAProxy实例可能需要一些时间来进行重新配置和重新分发请求。Keepalived则提供了一种快速的故障切换机制,它能够迅速检测到主节点的失效,并将虚拟IP(VIP)迁移到备用节点,实现几乎无感知的故障转移。
四、实操
假设master的机子ip为192.168.16.200,201,202
worker的机子:192.168.16.203,192.168.16.204,192.168.16.205
虚拟ip为192.168.16.210
虚拟 IP 地址应该是网络上可用的、未被分配的,并且适合你要实现的服务或应用。在配置中,你会将这个虚拟 IP 地址列入 `virtual_ipaddress` 配置项中,使 Keepalived 的 MASTER 实例能够在活动时绑定并使用它。
vim /etc/hosts
将虚拟ip加入到hosts文件中
192.168.16.200 k8s-master1
192.168.16.201 k8s-master2
192.168.16.202 k8s-master3
192.168.16.203 k8s-node1
192.168.16.204 k8s-node2
192.168.16.205 k8s-node3
#将虚拟ip加入到hosts文件中
192.168.16.210 k8s-cluster
在不同的机子上 设置各自的hostname
hostname k8s-master1
hostname k8s-master2
hostname k8s-master3
hostname k8s-node1
hostname k8s-node2
hostname k8s-node3
1、haproxy
1)安装haproxy
在所有master机子上安装haproxy
sudo apt-get update
sudo apt-get install -y haproxy
2)编辑haproxy的配置文件
sudo vim /etc/haproxy/haproxy.cfg
在配置文件最下方加入 两个监听器
#配置了一个监听器,用于提供统计信息和管理界面。
listen admin_stats
bind 0.0.0.0:1080
mode http
log 127.0.0.1 local0 err
stats refresh 30s
stats uri /status #管理界面的访问路径
stats realm welcome login\ Haproxy
stats auth admin:admin #登录认证
stats hide-version
stats admin if TRUE#配置了一个监听器,用于转发流量到Kubernetes主节点。
listen kube-master
bind 0.0.0.0:8443 #负载均衡的端口为8848
mode tcp
option tcplog
balance source
server 192.168.16.200 192.168.16.200:6443 check inter 2000 fall 2 rise 2 weight 1
server 192.168.16.201 192.168.16.201:6443 check inter 2000 fall 2 rise 2 weight 1
server 192.168.16.202 192.168.16.202:6443 check inter 2000 fall 2 rise 2 weight 1
3)设置开机启动,并进入管理界面
systemctl enable haproxy && systemctl restart haproxy
查看haproxy页面:
http://192.168.16.200:1080/status
账号/密码:
admin/admin
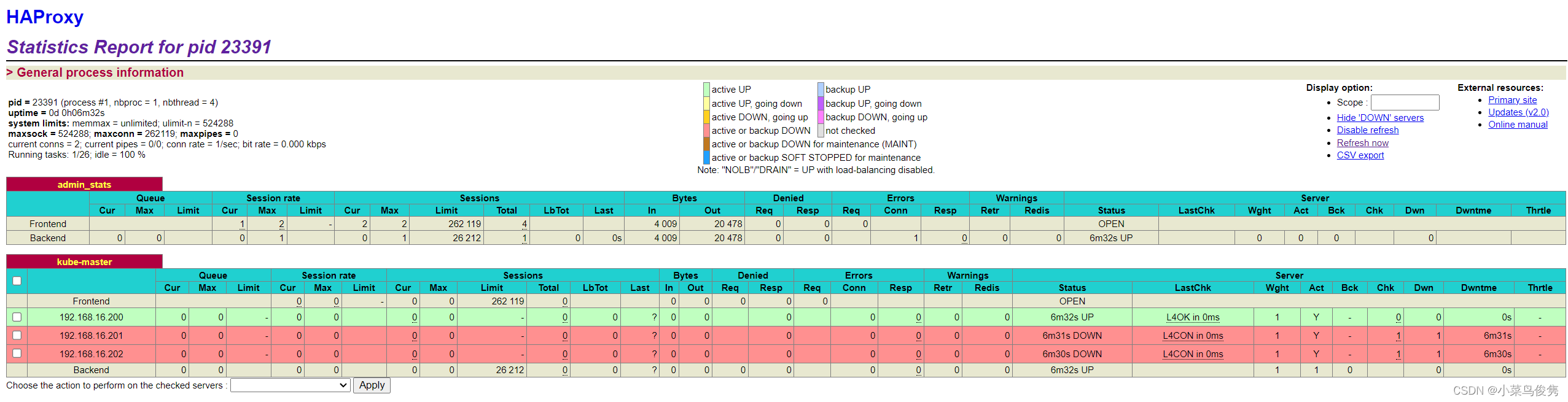
💡 由于还没初始化k8s的master, 这里其余两台都还不可用。
2、keepalive
1)安装keepalive
在所有master机子上安装keepalive
apt-get install -y keepalived
2)编辑keepalive的配置文件
- 查看可用的网卡
ip addr
我的是ens33
![[Pasted image 20230823231343.png]]
vim /etc/keepalived/keepalived.conf
- master1 (192.168.16.200)
global_defs {script_user root
router_id k8s-lb
enable_script_security
}vrrp_script check-haproxy {
script "/usr/bin/killall -0 haproxy"
interval 5
weight -30
}vrrp_instance VI-kube-master {
state MASTER #200为主节点
priority 120 #主节点权重要大点
dont_track_primary
interface ens33 #上面的网卡
virtual_router_id 80
advert_int 3
track_script {
check-haproxy
}
virtual_ipaddress {
192.168.16.210
}
}
- master2 (192.168.16.201) ,master3 (192.168.16.202)
global_defs {script_user root
router_id k8s-lb
enable_script_security
}vrrp_script check-haproxy {
script "/usr/bin/killall -0 haproxy"
interval 5
weight -30
}vrrp_instance VI-kube-master {
state BACKUP #设置为从节点
priority 110
dont_track_primary
interface ens33 #上面的网卡
virtual_router_id 68
advert_int 3
track_script {
check-haproxy
}
virtual_ipaddress {
192.168.16.210
}
}
3)依次在master1 master2 master3 上启动
systemctl enable keepalived && systemctl start keepalived && systemctl status keepalived
keepalived启动成功之后,在master1上通过ip addr可以看到vip(192.168.16.210)已经绑定到ens33这个网卡上了
![[Pasted image 20230823231446.png]]
3、k8s master集群拓展
1)以下操作在master1执行
备份一下之前k8s master的配置文件
mv init-default.yaml init-default.yaml.bak
vim init-default.yaml
将配置文件修改为以下的样子:
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:- system:bootstrappers:kubeadm:default-node-tokentoken: abcdef.0123456789abcdefttl: 24h0m0susages:- signing- authentication
kind: InitConfiguration
localAPIEndpoint:advertiseAddress: 192.168.16.200bindPort: 6443
nodeRegistration:criSocket: unix:///var/run/containerd/containerd.sockimagePullPolicy: IfNotPresentname: k8s-master1 #这里是机子的hosttaints: null
---
apiServer:timeoutForControlPlane: 4m0scertSANs:- k8s-cluster- k8s-master1- k8s-master2- k8s-master3- k8s-node1- k8s-node2- k8s-node3
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:local:dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.27.4 #根据实际版本修改
networking:dnsDomain: cluster.localserviceSubnet: 10.96.0.0/12podSubnet: 10.244.0.0/16
scheduler: {}
controlPlaneEndpoint: k8s-cluster:8443
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
- 主要修改的部分:
controlPlaneEndpoint为控制面设置一个稳定的 IP 地址或 DNS 名称。
controlPlaneEndpoint: k8s-cluster:8443
- 设置 API 服务器签署证书所用的额外主题替代名
certSANs:- k8s-master1- k8s-master2- k8s-master3- k8s-node1- k8s-node2
- k8s-node3
将k8s集群的host都加入到certSANs中,因为我只有三台服务器,所以node1和node2其实也是master2和master3。按你实际的服务器情况修改即可。
- 当前ubuntu系统默认开启了ipvs, 后续k8s部署的kube-proxy组件将会使用ipvs模式,提高转发效率。
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
- 重新初始化master
#重置初始化
kubeadm reset -f
#配置kubetl
rm -rf /root/.kube/
mkdir -p /root/.kube/sudo kubeadm init --upload-certs --config=init-default.yaml --ignore-preflight-errors=all
跟第一章一样看到token信息,拷贝保存一下
- master的join命令
kubeadm join k8s-cluster:8443 --token abcdef.0123456789abcdef \--discovery-token-ca-cert-hash sha256:8ae4635e544e225c19a0b303a75de62169a910c6d44095903340526f0fdd2c2d \--control-plane --certificate-key 7dbedbba04cb0f5582ecb06ef78eabfe587de17f4393fe38fd772c5573e66d3d
- worker的join命令
kubeadm join k8s-cluster:8443 --token abcdef.0123456789abcdef \--discovery-token-ca-cert-hash sha256:8ae4635e544e225c19a0b303a75de62169a910c6d44095903340526f0fdd2c2d
执行以下命令
export KUBECONFIG=/etc/kubernetes/admin.conf
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
检查是否有启动成功
curl -k https://k8s-cluster:8443/api/v1/namespaces/kube-public/configmaps/cluster-info?timeout=10s
- 重新安装flannel
wget https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml#如果你修改了`podCIDR` yml中也要修改
export POD_SUBNET=10.244.0.0/16
sed -i "s#10.244.0.0/16#${POD_SUBNET}#" kube-flannel.yml
kubectl apply -f kube-flannel.yml
使用以下命令查看镜像拉取状态,pending可能是还在下载镜像
watch kubectl get pods -n kube-system -o wide
等全部镜像变成RUNNING状态后,master状态也会变成Ready
kubectl get nodes
2)master2、master3加入集群
- 安装k8s
第一章已经安装过了,这里就不重复了
- 重新初始化节点的信息
由于我之前这两台服务器上初始过worker,所以重新清除掉
#重置初始化
kubeadm reset -f
#配置kubetl
rm -rf /root/.kube/
mkdir -p /root/.kube/
- master2 master3加入集群
kubeadm join k8s-cluster:8443 --token abcdef.0123456789abcdef \--discovery-token-ca-cert-hash sha256:8ae4635e544e225c19a0b303a75de62169a910c6d44095903340526f0fdd2c2d \--control-plane --certificate-key 7dbedbba04cb0f5582ecb06ef78eabfe587de17f4393fe38fd772c5573e66d3d
赋予权限
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
检查状态,全部READY
kubectl get nodes
进入haproxy查看集群状态
http://192.168.16.210:1080/status
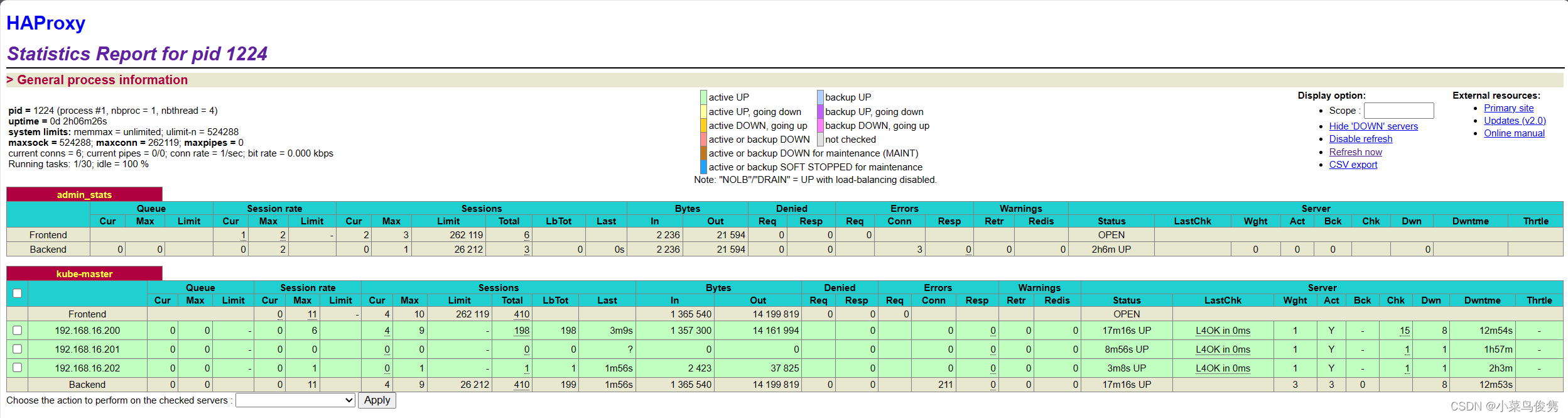
全部正常启动!
3)worker集群重新加入master
kubeadm join k8s-cluster:8443 --token abcdef.0123456789abcdef \--discovery-token-ca-cert-hash sha256:8ae4635e544e225c19a0b303a75de62169a910c6d44095903340526f0fdd2c2d
在master1上检查状态
kubectl get nodes -o wide
kubectl get pods --all-namespaces -o wide
至此整个k8s多master的环境就部署好啦!












![java八股文面试[数据库]——B树和B+树的区别](https://img-blog.csdnimg.cn/e3340931f2e1432eacc7536f91775af0.png)