在使用Conv1d函数时,pytorch默认你的数据是一维的,比如一句话“深度学习”可以用一个一维数组 ['深', '度', '学', '习'] 表示,这个数据就是一维的。图片是二维数据,它有长宽两个维度。
因此在使用 Conv1d 函数时,输入是一个三位数组,三个维度分别表示 (批量,通道,长度)
使用 Conv2d 函数时,输入是一个四维数组,四个维度分别是(批量,通道,行,列),这里不详细介绍Conv2d。
(批量即 batch_size)
用如下例子介绍Conv1d(input_channel=3, output_channel=4, kernel_size=1),输入的例子数据为一句话,这句话有5个单词,假设每个单词都由三个字母组成,就相当于每个单词有3个通道,假设这句话是 ['abc', 'def', 'ghi', 'jkl', 'mno'],这些数据放在图1所示的矩阵里,可见长度为5,深度方向为3。
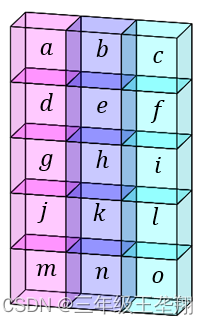
output_channel=4,即由四个卷积核,每个卷积核的通道数和输入的通道数相同,这里是3,如图2所示,第一个元素'abc'的三个通道'a', 'b', 'c'输入第一个卷积核,得到红色数字,第二个单词经过卷积核得到黄色数字,排成一列得到第一个通道,四个卷积核得到输出的四个通道。
如果一个batch里有很多句话,那么分别对每句话进行上述计算即可。

测试代码:
输入数据的 batch_size=10,通道数为3,长度为5。卷积核大小为1,卷积核通道数和输入数据的通道数一致。输出数据通道数为7,卷积核的数量和输出数据的通道数一致。
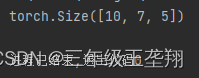
因为卷积核大小为1,所以输出长度与输入长度一致,卷积不影响批量数(batch_size),因此输出数据的(批量,通道,长度)应为(10, 7, 5)
from torch import nnconv1 = nn.Conv1d(in_channels=3, out_channels=7, kernel_size=1)input = torch.randn(10, 3, 5)out = conv1(input)print(out.size())运行后的输出如下图所示,可见分析正确。