Chapter2 Amplifiers, Source followers & Cascodes
MOS单管根据输入输出, 可分为CS放大器, source follower和cascode 三种结构.
Single-transistor amplifiers
这一章学习模拟电路基本单元-单管放大器
单管运放由Common-Source加上DC电流源组成. Av=gm*Rds, gm和rds和Id有关, 增益和电流Id无关, 取决于Vgs-Vt和L. L越大, Vgs-Vt越小, Av增益越大.
为了高增益, Vgs-Vt设计为0.15V-0.2V. 小电流Ids会引入更大的噪声和小的signal-to-noise ratios (SNR)

单管增益, BJT VS MOS. BJT的Av=Ve/(kT/q), 增益至少是MOS的10倍. 可以有效减少级数.

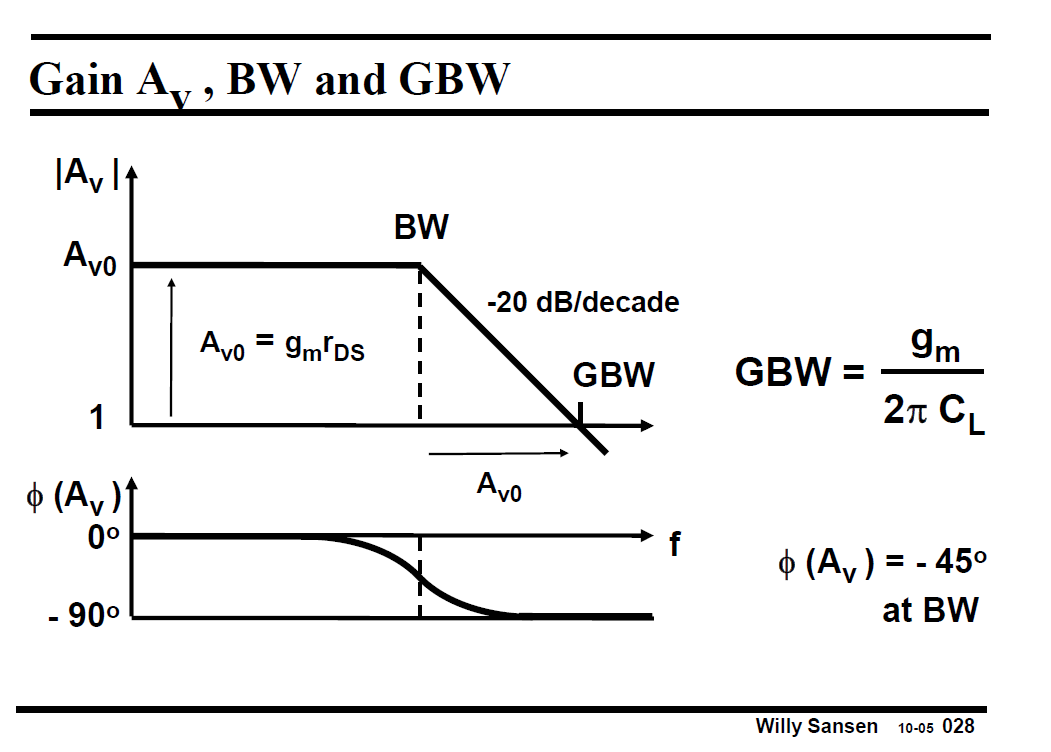
只考虑输出电容CL, 单管运放的Gain, Bandwidth (Gain开始下降点, f-3db) 和GBW (单位带宽) 如下图所示. GBW是一个运放最重要的参数之一.

在BW处, phase下降-45deg. GBW=Gain*BW
在MOS得Input (gate)和输出(Drain)之家加入CF, 即miller Cap, 会改变BW和GBW.
BW=1/(Rs* CF * AV). GBW=BW*Av, 如下图所示. BW和GBW与器件参数无关, 只取决于反馈器件参数.
Miller效应将输入电容CF放大了CF*Av倍.

另外Miller电容会引入右零点fz=gm/(2pi*CF), 在phase上相当于左极点, 即Phase 恶化-180 deg!

对于单管运放, 常在在source端串联Rs. 形成负反馈, loop gain为(1+gm*Rs).
因此等效gm变小为gmR=gm/(1+gm*Rs) ~ 1/Rs. Rout增大为RoutR=rds(1+gmRs). 另外输入电容减小为CinR=Cgs/(1+gmRs).

对于RF等需要极低噪声应用, Rs可换成电感L. 阻抗为L*s, 这样就没有噪声了.
把MOS得Gate和Drain接到一起, 可形成parallel feedback. 我们可用这个diode-connected结构将电流转换为电压信号. 或者电压转化为电流信号.

diode-connected得小信号模型为电阻1/gm.
可用diode-connected得NMOS做负载, Gain=gm1/gm2, 不高, 大概为5 ~ 10. 但好处是只用了NMOS, 无需电阻. 如下图所示


Source Follower
牢记住单管的三种应用: Gate输入, Drain输出做CS放大器, Gate输入, Source输出做source follower. Source输入, Drain输出做common gate,

对于source follower, source和body接到一起, Av=1, Rout=1/gm. 作为Voltage Buffer. 即小信号电压不变, 输出阻抗大大减小.
body直接接GND, Av=1/n, n=0.6~0.8. Av大于1.
对于BJT的source follower, 输入阻抗Rin= rπ+ rB+ (β+1)RE

source follower在高频下考虑Cgs电容, 在fT/(gm*Rs)和fT之间可作为电感.

Rs可用diode-connected MOS替代.

Cascodes
这一小结我们来看单管以source为输入, drain为输出的cascode接法.

cascode电流不变, 但输出阻抗大大增加, 输入阻抗减小, 即电流buffer.
cascode可以显著增加输出阻抗, 输出阻抗Rout= rds1 *(gm2rds2), 因此增加了Av增益

cascode增加了Av gain, BandWidth=1/(2pi * Rout*CL), BW大大减小. cascode和单管放大的GBW一致. GBW= gm1/(2pi *CL)

套筒式telescopic cascode的增益Av, 输出阻抗Rout, BW, GBW如下

cascode两个管类型不同, 称为折叠式folded cascode结构. 消耗两倍电流, 输入电压范围更广.

产生两级增益还可以用cascade, 即串联接法. 添加Miller电容后, cascade的GBW为 gm1/(2pi*Cc)

为了获得更多gain, 可以regulate cascode或者gain boosting. 利用并联-串联负反馈, 进一步提高Rout, ×gm×rds3. 如下图所示

Gain Boosting 如下图所示, 放大器一端接M1的drain, 放大器输出接M2的gate. 这样输出电阻和Av增大为Agb

我们需要保证Avgb的GBW与普通cascode的BW保持一致. 否则会产生pole-zero doublet即零极对. 影响系统settle time.
需要设计 GBW_gain_boost_amp > GBW_system, 这样doublet不会影响整体系统的set time.
最后总结MOS管和BJT管不同形态的输入,输出和增益
对于MOS的CS放大和source follower. 记住从souce看进去的阻抗为1/gm.

对于BJT, 稍微复杂一些

对于Cascode结构
AR=Vout/Iin. 从source看进去的阻抗为1/gm 或者Rb. 从drain看进去的阻抗为gm×ro×RB.