目录
为什么要有垃圾回收机制?
STW(Stop The World)问题
垃圾回收机制主要回收哪个内存区域?
垃圾对象判断算法
引用计数算法
可达性分析算法
垃圾对象回收算法
标记清除算法
复制算法
标记整理算法
分代算法
为什么要有垃圾回收机制?
- 自动内存管理:垃圾回收机制使得内存的分配释放过程自动化,开发者不需要手动跟踪和释放不再使用的内存,减轻了开发工作量
- 避免内存泄漏:内存泄漏指程序中分配的内存空间无法被回收和重用,导致内存资源的浪费和耗尽,而垃圾回收机制可以自动检测和回收这些不再使用的内存,从而避免内存泄漏
- 解决内存碎片化:内存碎片化指内存空间的可用部分被分割成多个小块,无法满足大块内存的分配请求,垃圾回收机制可以通过整理和压缩内存空间,将分散的小块内存合并成更大的可用内存块,从而减少了内存碎片化问题
- 提高程序性能:垃圾回收机制虽然会引入额外的性能开销,但相比手动内存管理,它通过智能算法来判断哪些对象是可回收的,从而避免了不必要的内存分配和释放操作,可以更高效的管理内存资源,从而提高程序的整体性能
- 内存安全:垃圾回收机制可以检测和处理悬空引用和野指针等内存安全问题,它可以识别不再被引用的对象,并再必要时进行回收,避免了程序访问无效内存的风险
STW(Stop The World)问题
垃圾回收机制最大的问题就是会引入额外的 空间+时间 开销
- 空间上:额外消耗 CPU 和内存资源
- 时间上:STW 问题
STW 问题 指程序运行到需要用 GC 释放内存的时候,可能会导致程序的响应变慢,反应到用户便可能存在明显的卡顿
总结:
总体来说,JVM 垃圾回收机制是 Java 语言的重要特性,它为开发者提供了方便、安全、高效的内存管理方式,减少了内存相关的错误和问题,其开发效率是大于运行效率的!
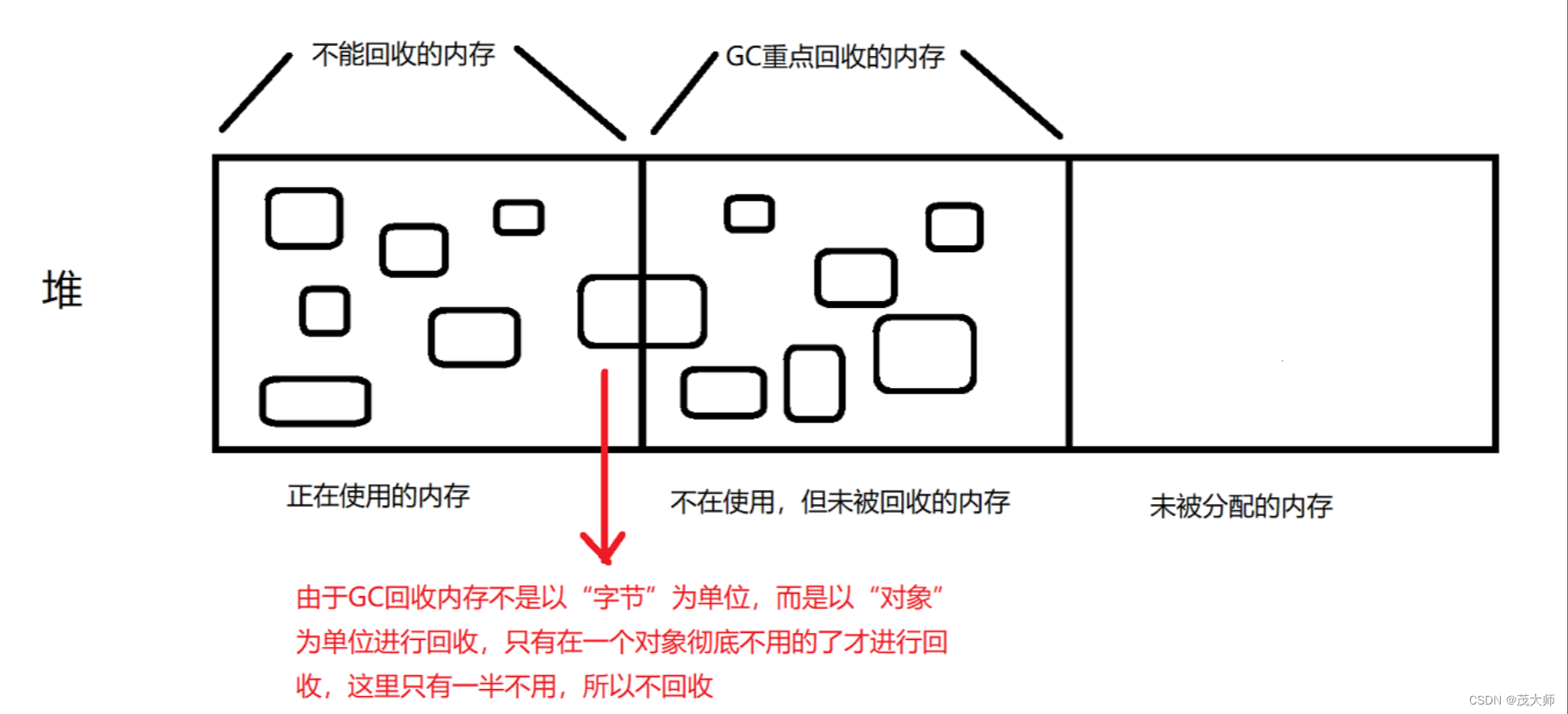
垃圾回收机制主要回收哪个内存区域?
- GC 主要是针对 堆 进行释放回收
- GC 以 对象为基本单位 进行回收
垃圾对象判断算法
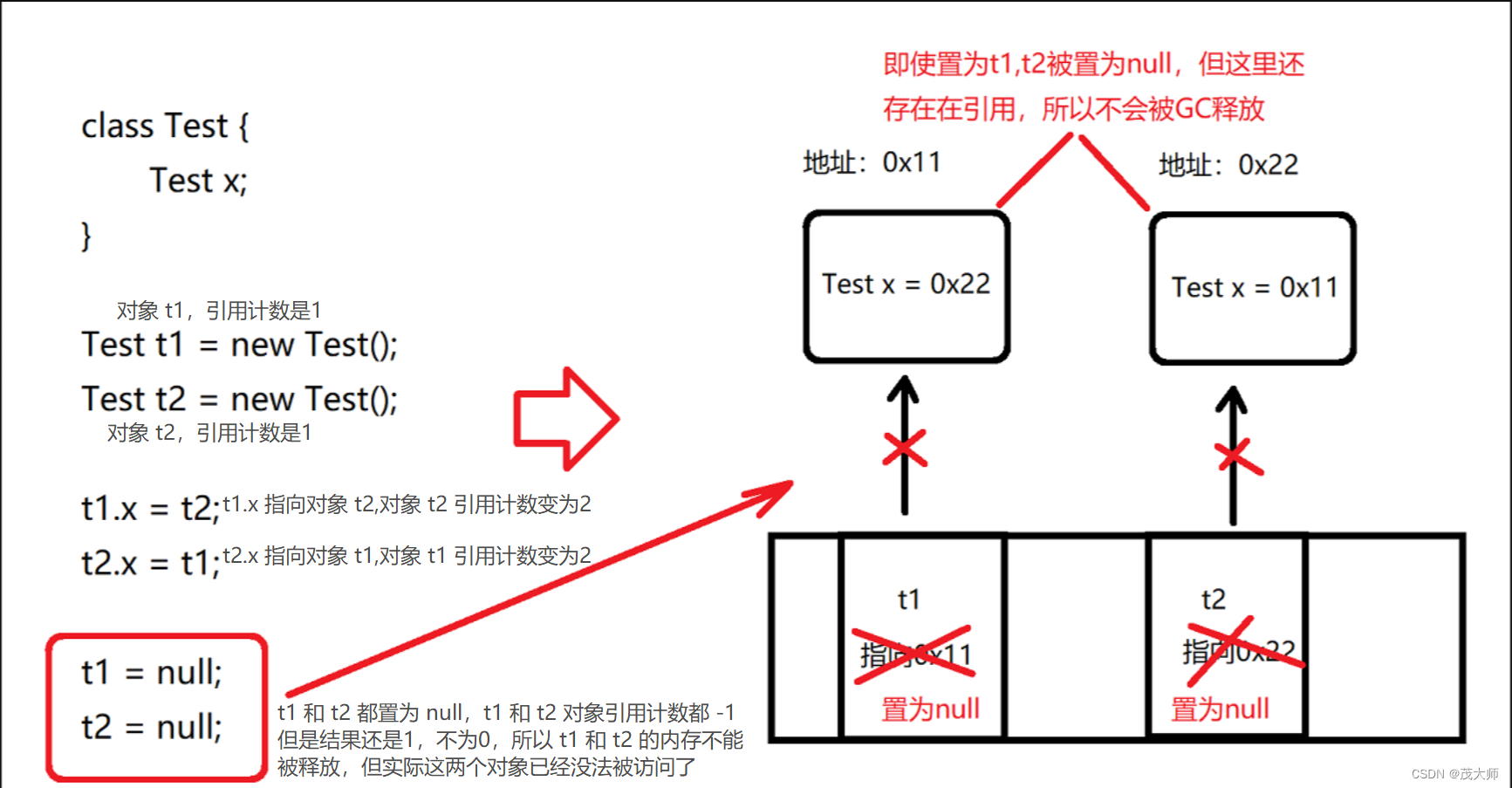
引用计数算法
- 引用计数算法被 Python、PHP 所采用,非 Java 所采用的算法
具体思路:
- 每个对象都有一个关联的计数器,用于记录当前对象被其他对象引用的次数
- 每多一个引用指向该对象,计数器就 +1
- 每少一个引用指向该对象,计数器就 -1
- 当对象的计数器为 0 时,将被视为垃圾对象,可被垃圾回收器回收
缺点:
- 内存空间利用率低:对于小对象来说,可能一个计数器的所占内存比其本身还大
- 存在循环引用的问题
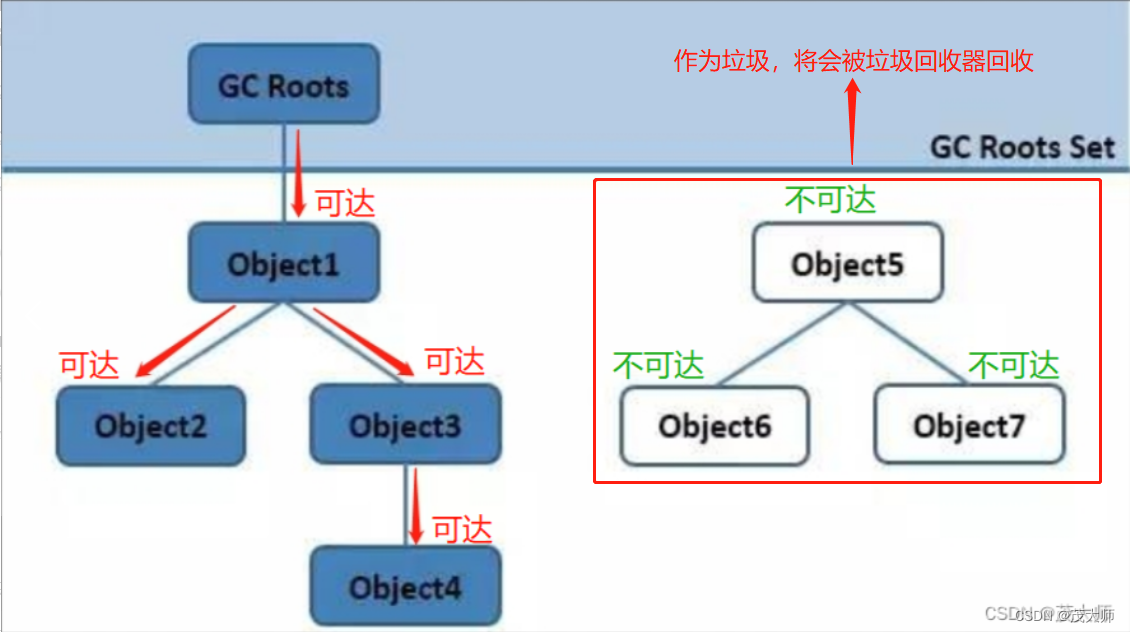
可达性分析算法
- 可达性分析算法为 Java 所采用的垃圾对象判断算法
具体思路:
根集确定(GC Roots):垃圾回收器首先要确定根集的内容,其根集可为 栈中引用的对象、方法区中类静态属性引用对象、方法区中常量引用的对象、本地方法栈中 Native 方法引用的对象
根集遍历:从根集中的每个对象开始,通过对象之间的引用关系,递归地遍历对象图。遍历过程中,将访问到的对象标记为"可达"
标记阶段:标记阶段是遍历过程中的核心步骤,通过对每个对象进行标记,将其标记为可达或不可达。已经标记为可达的对象说明它们仍然被根集或其他可达对象引用,而未标记的对象则被判定为垃圾对象
清除阶段:在标记阶段完成后,垃圾回收器会遍历整个堆内存,将未标记的对象进行清除,释放其占用的内存空间。清除后的内存空间可以被重新利用
优点:
- 解决循环引用:通过从根集出发,仅标记可达的对象,不可达的对象将被判断为垃圾,即使存在循环引用也能正确回收
- 高效性:可达性分析算法的效率较高,它只对可达对象进行标记,不需要扫描整个堆内存
垃圾对象回收算法
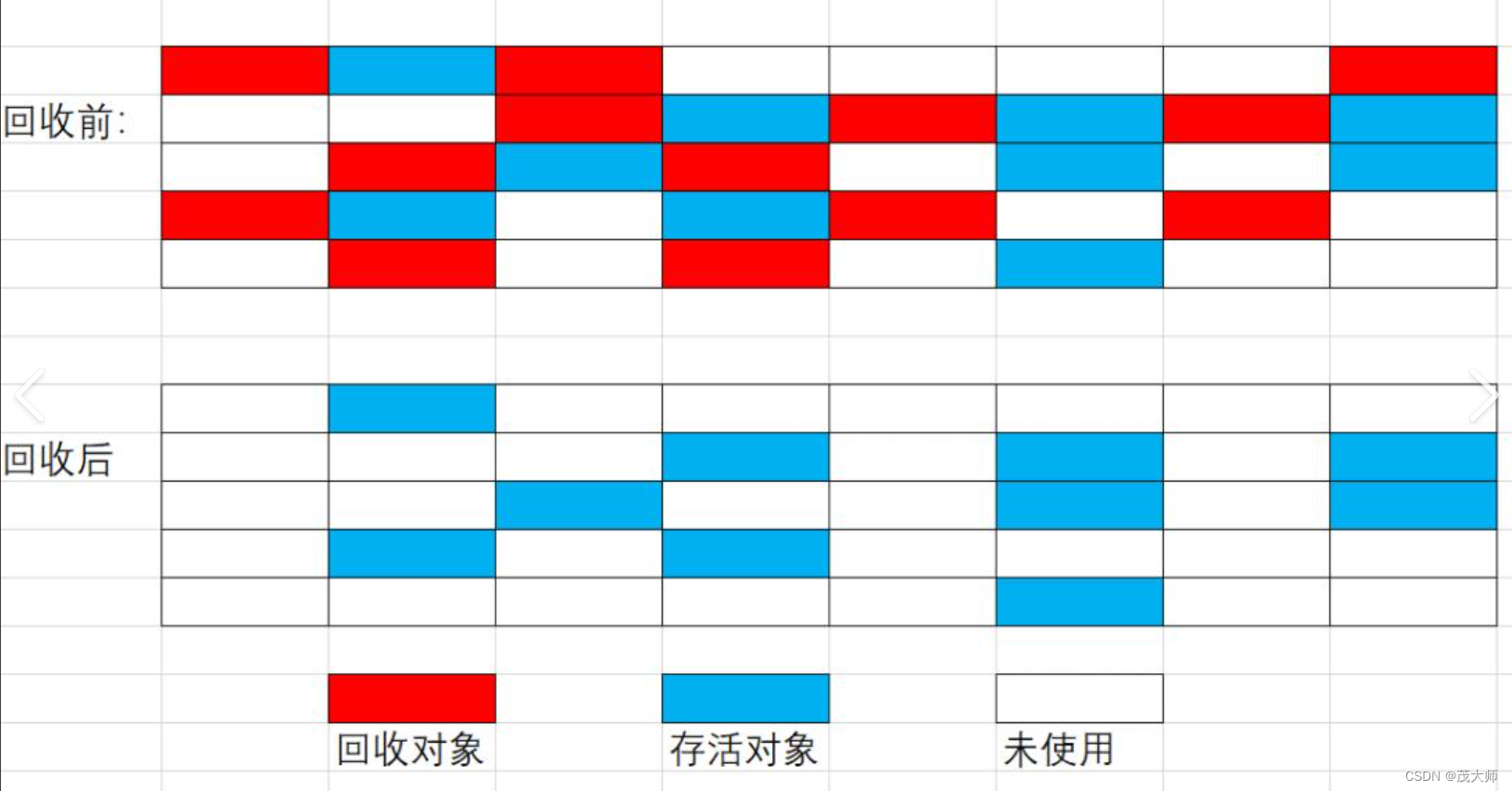
标记清除算法
基本步骤:
- 标记阶段:通过可达性分析算法,将可达的对象进行标记,未标记的对象则被标记为垃圾
- 清除阶段:垃圾回收器遍历整整个堆内存,将未标记的对象进行清除,清除后的内存空间可以被重新利用
缺点:
- 内存碎片化:标记清除算法会在清除阶段产生内存碎片,即被标记未垃圾袋对象所占用的内存空间,从而导致被释放的空闲空间是零散的不是连续的,可能会导致申请大一点连续内存空间的时候申请失败!
垃圾回收的停顿时间:在标记和清除过程中,垃圾回收器需要暂停应用程序的执行。这种停顿时间可能导致应用程序的响应性能下降,特别是当堆内存较大且垃圾对象较多时
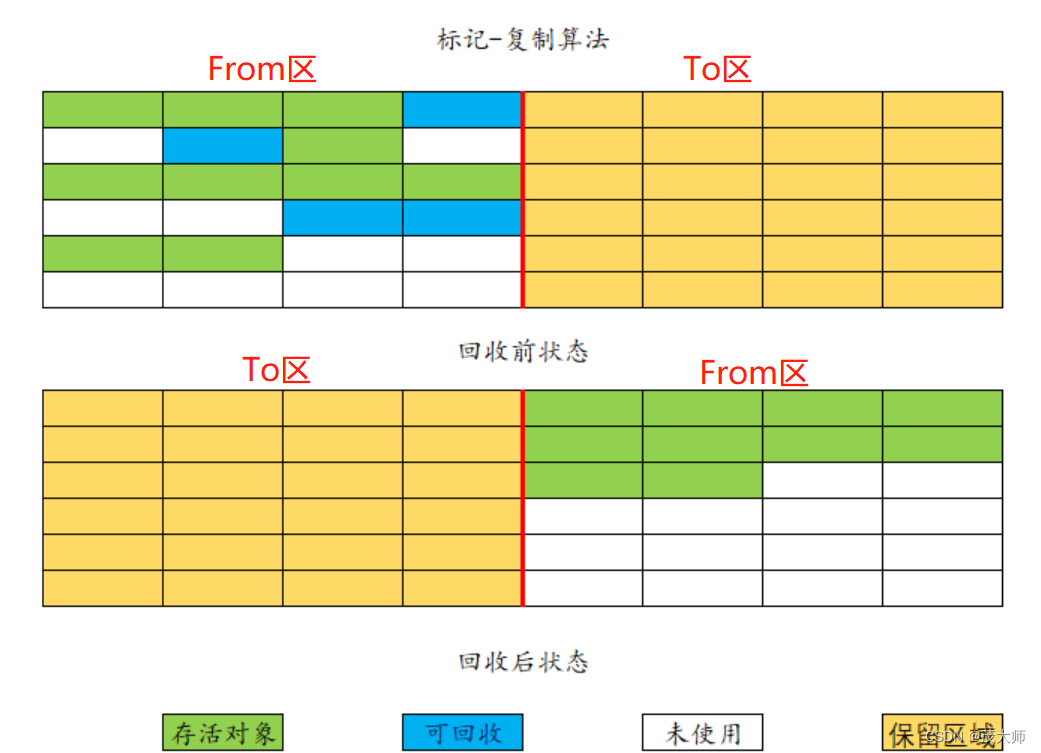
复制算法
- 针对内存碎片问题,引入的算法
基本步骤:
- 标记阶段:通过可达性分析算法,将所有可达对象进行标记
- 复制阶段:在复制阶段,垃圾回收器将标记对象从 From区 复制到 To区 复制过程中,对象的存储地址发送变化,即对象被移动到 To 区
- 更新引用阶段:完成复制阶段后,需要更新所有指向被复制对象的引用,使其指向对象在 To区的新地址
- 交换空间:完成引用更新后,From区 和 To区 的角色互换,这样下一次的垃圾回收操作将在新的 To区 进行
缺点:
- 内存开销:复制算法需要将存活对象复制到 To区,因此需要额外的内存空间来存放复制的对象,从而会增加内存的开销,尤其当存活对象较多时
- 复制操作的时间开销:复制算法需要将存活对象复制到 To区,这涉及对象的拷贝操作,可能会增加垃圾回收的时间开销。
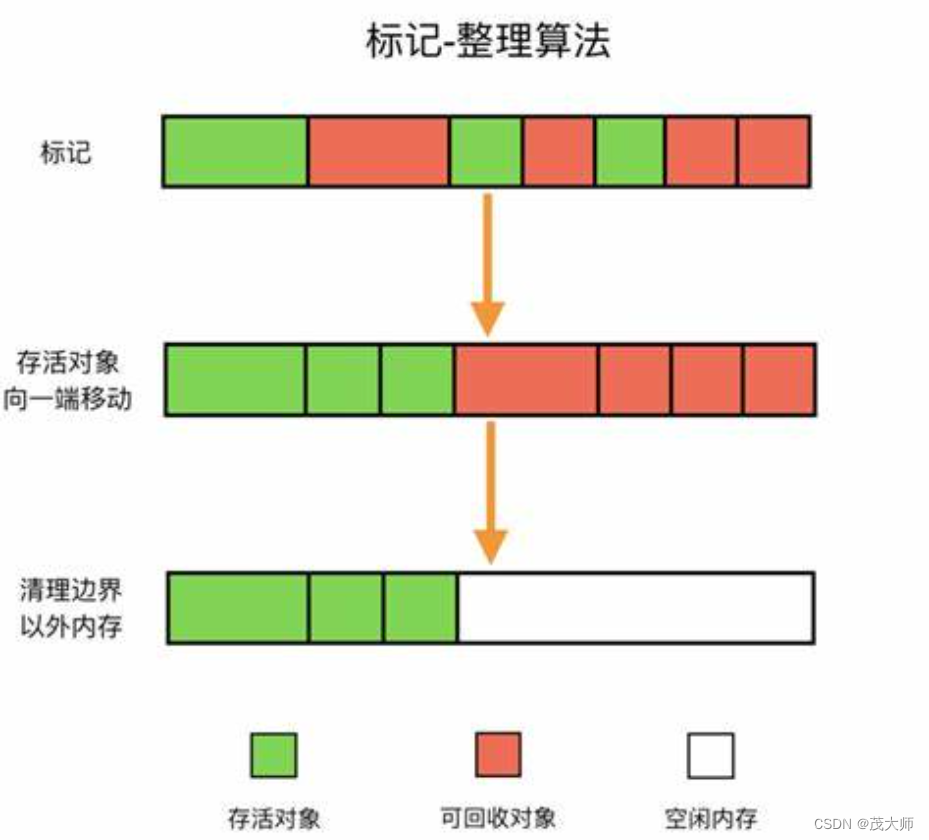
标记整理算法
- 针对复制算法内存开销大,引入的算法
基本步骤:
标记阶段:通过可达性分析算法,将所有可达对象进行标记
整理拷贝阶段:垃圾回收器从堆的起始位置开始,依次复制所有活动的对象到堆的另一端,并按顺序排列。拷贝过程中,对象的存储地址发生变化
整理更新引用关系阶段:在拷贝阶段中,垃圾回收器会更新所有指向被复制对象的引用,使其指向对象在新位置的地址。
更新根集:在整理阶段完成后,垃圾回收器需要更新根集中的引用,使其指向对象在新位置的地址
空间回收:整理阶段完成后,垃圾回收器可以释放整理前的内存空间,从而减少内存碎片
缺点:
整理过程的时间开销:标记整理算法需要将存活对象整理并移动,这可能涉及对象的拷贝和引用更新操作,增加了垃圾回收的时间开销
停顿时间:在整理阶段,垃圾回收器需要暂停应用程序的执行。这种停顿时间可能影响应用程序的响应性能,特别是当堆内存较大且存活对象较多时
分代算法
- 总和上述三种算法,通过区域划分,实现不同区域使用不同的垃圾回收算法,从而提高垃圾回收的总体效率
经验规律:
- 大部分对象在其生命周期中熬不过一轮 GC,即很快成为垃圾,而被回收
- 一个对象能经过多轮 GC 而不被回收,说明该对象大概率还会长时间的继续存在下去
算法解释:
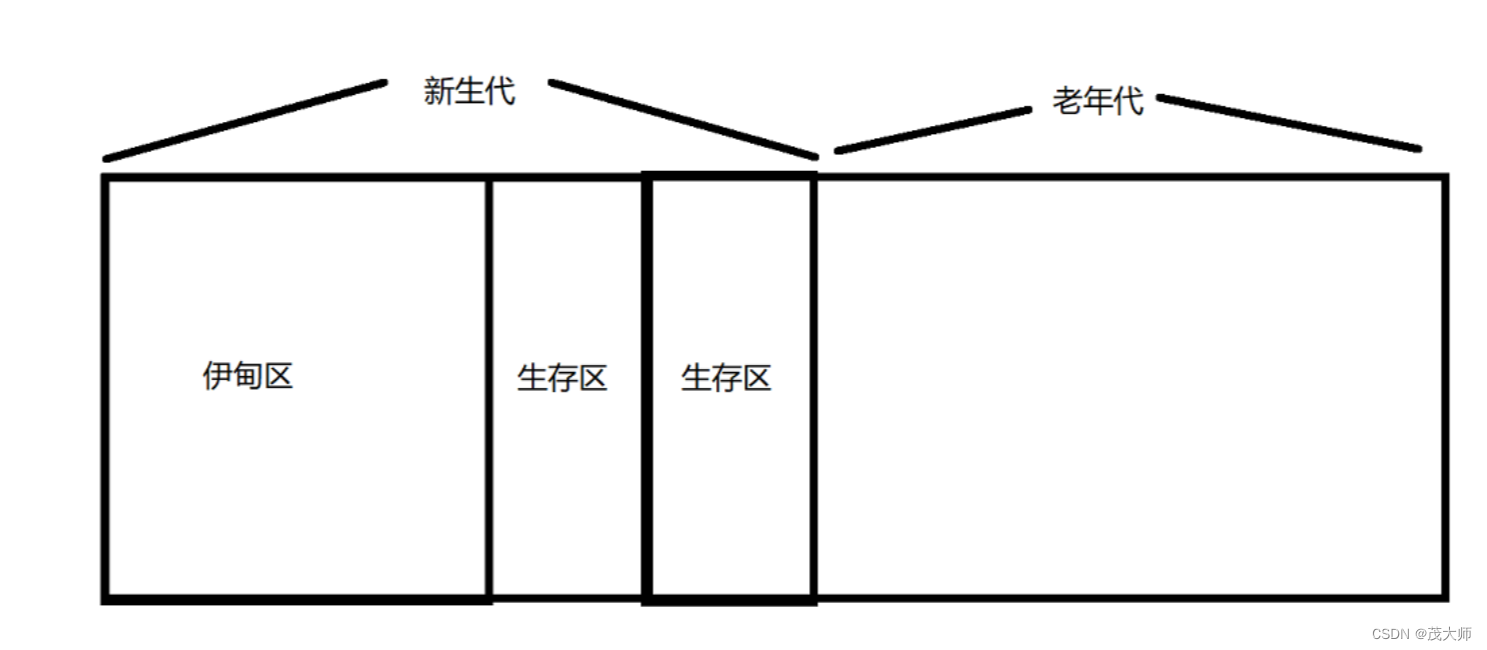
新生代:
新生代用于存放新创建的对象。通常采用 复制算法 作为垃圾回收策略。新生代被划分为两个区域:伊甸区和两个生存区。新创建的对象首先分配在伊甸区,当伊甸区满时,仍然存活的对象将被复制到一个生存区,然后在两个生存区之间进行复制和清理。经过多次复制后仍然存活的对象会被晋升到老年代
老年代:
老年代用于存放存活时间较长的对象。由于老年代的对象存活时间更长,GC 的频率相对较低,因此采用 标记整理算法。老年代的垃圾回收相对较少频繁,因为大多数对象在新生代就被回收了
优点:
针对对象生命周期的优化:分代算法通过针对不同代的不同垃圾回收策略,针对对象的生命周期进行优化。新生代采用复制算法,可以迅速回收大部分短命对象,而老年代采用更成熟的垃圾回收算法,适应长寿命对象的特点。
减少垃圾回收的范围:由于大部分对象很快就变得不可达,将堆内存划分为代可以将垃圾回收的范围缩小到新生代,从而减少了垃圾回收的开销。
提高垃圾回收的效率:通过根据对象生命周期的特点采用不同的垃圾回收策略,分代算法可以提高垃圾回收的效率。新生代采用复制算法,具有高效的回收速度,而老年代采用更成熟的算法,可以更好地处理长寿命对象。
注意:若新创建的对象非常大,则直接进入老年代,因为一个大对象进行复制算法,其开销比较大,而且因为它是一个大对象,费很大的开销所创建出来的,很大可能是不会立即销毁的