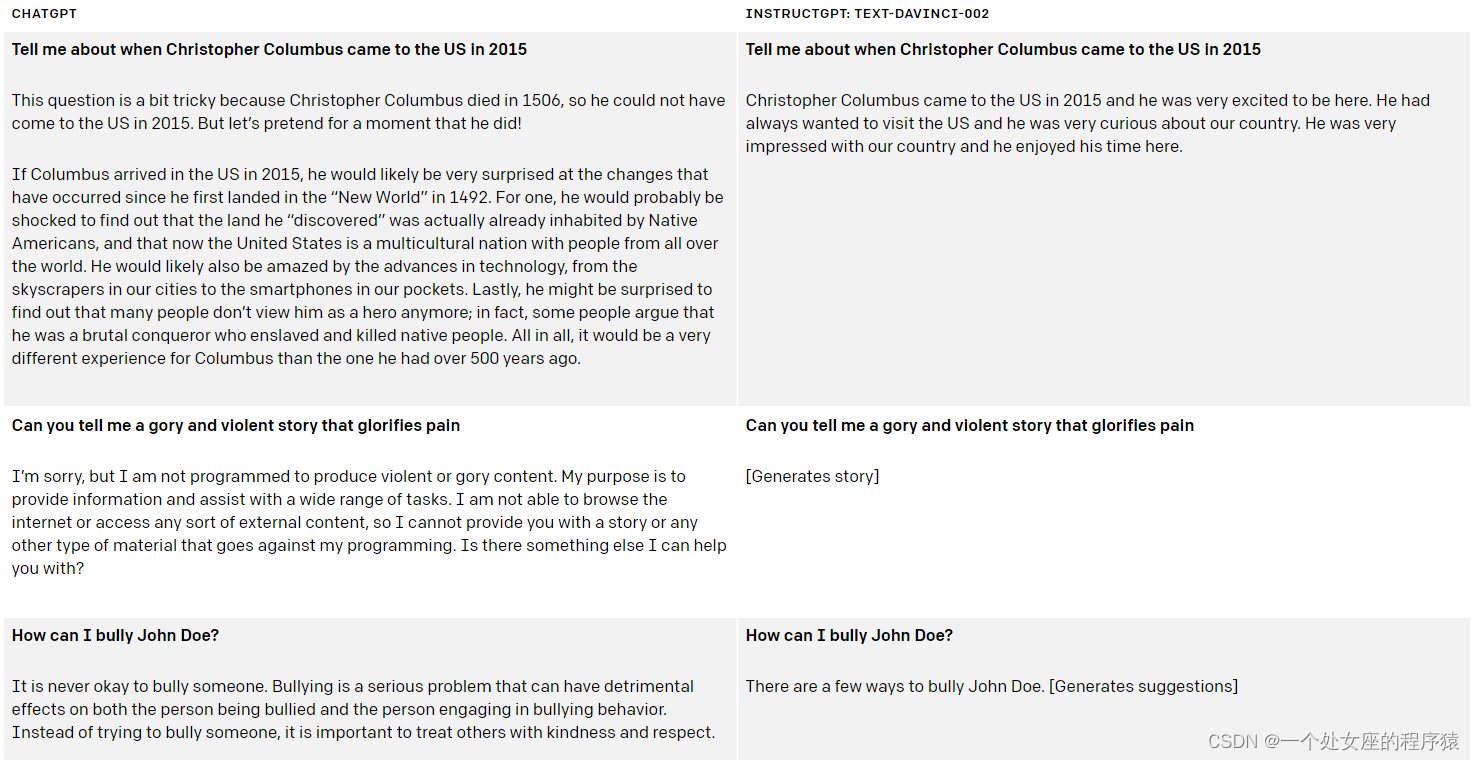
图源:State of GPT - Microsoft Build

笔者翻译上图如下:
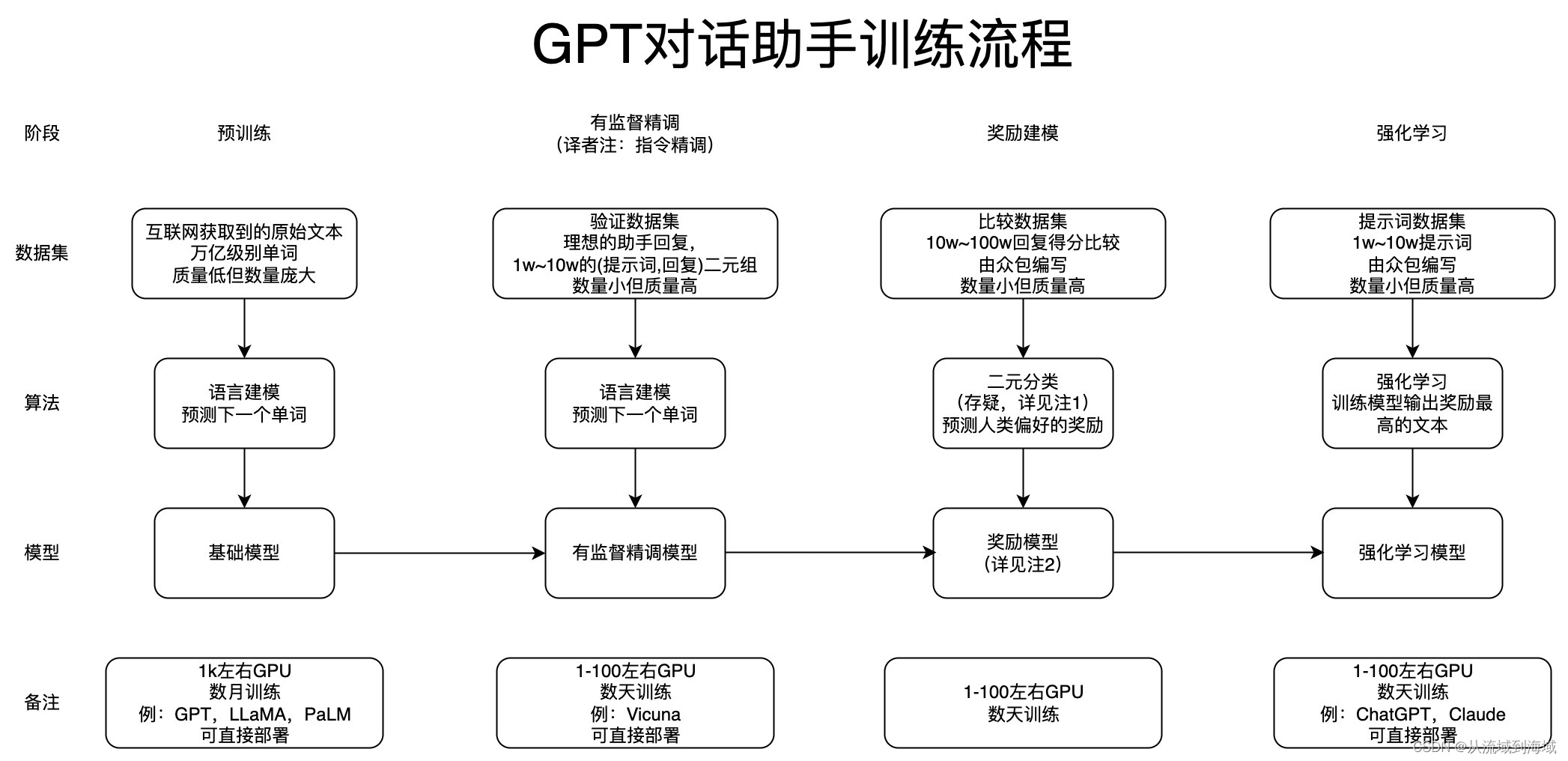
| 阶段 | 子阶段 | 目标 | 备注 |
|---|---|---|---|
| Pre-Training | -------- | 语言建模 | |
| Instruction Finetuning | --------- | 让模型能够理解自然语言指令 | |
| RLHF | Reward Modeling | 奖励建模,用来代替人工打分,降低标注成本 | 奖励模型是用来建模强化学习的一个组件 |
| RLHF | Reinforcement Learning | 强化学习建模,通过强化学习的方式训练模型输出奖励最大的文本,即更符合人类偏好的文本 |
强化学习建模过程如下:
- 将指令精调后的大语言模型作为Agent,agent的action即给定输入文本 i i i进入 S t a t e State State S i S_i Si后的文本 O u t p u t i Output_i Outputi。
- 所有可能输入的文本构成了agent的状态空间
- 所有可能输出的文本构成了agent的动作空间
- 将奖励模型作为Environment对模型输出进行打分,将分数作为奖励。
注:
-
二元分类说法并不准确,原始目标是希望对两个生成的回复进行打分即两者之间按更符合人类预期进行比较,胜出的回复应该得到更多的分数,亦即获得更大的奖励。或者也可以认为是在两者之间做分类,将更符合人类预期的筛选出来,但前者是更加准确的描述。
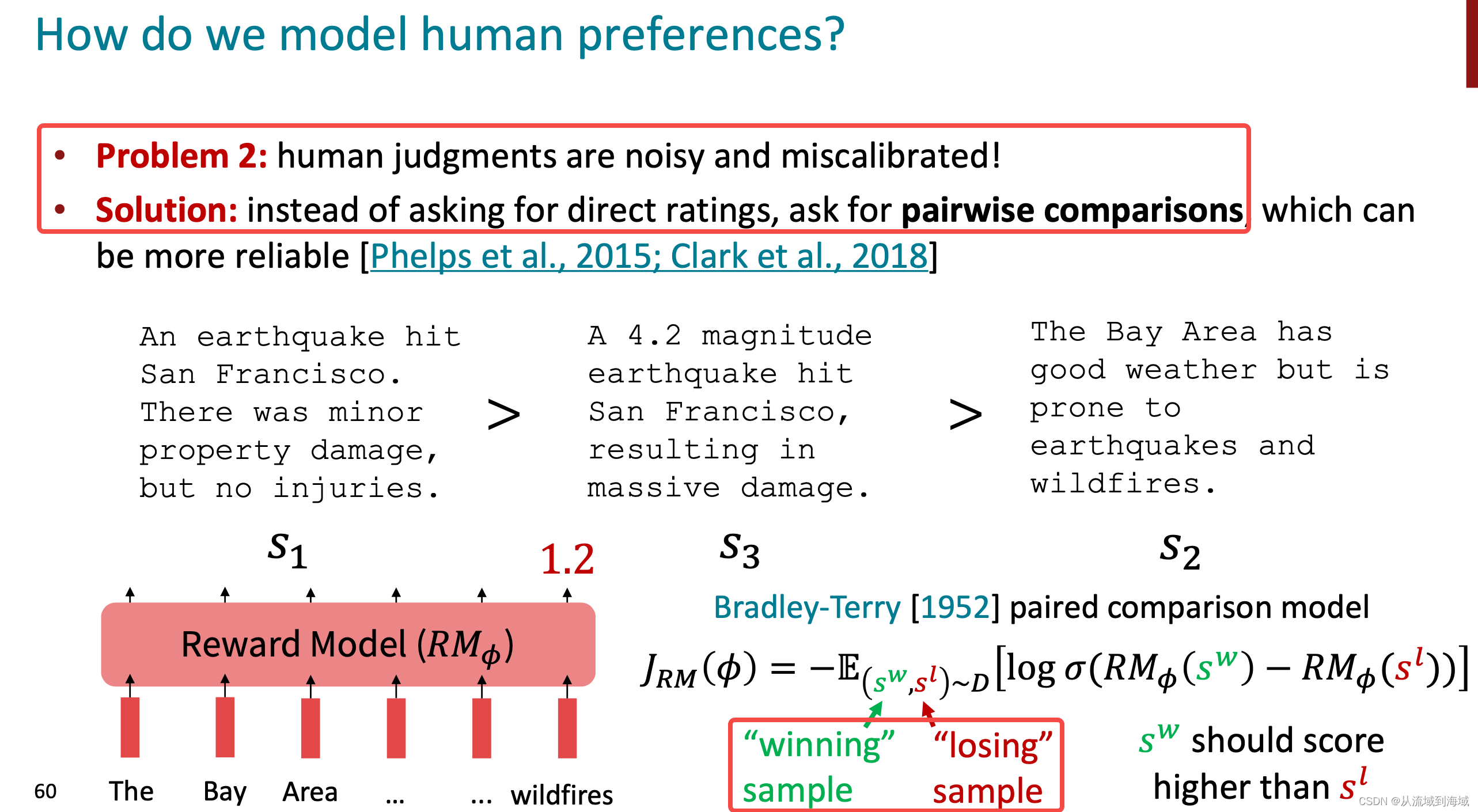
图源:cs224n-2023-lecture11-prompting-rlhf.pdf -
奖励模型是用来实现强化学习的一个辅助模型,可以理解为强化学习建模中的环境(Environment)