Mysql的基本问题
Mysql 为什么建议使用自增id?
- 因为id(主键)是自增的话,那么在有序的保存用户数据到页中的时候,可以天然的保存,并且是在聚集索引(id)中的叶子节点可以很好的减少插入和移动操作,可以提高效率。
- int或者bigInt占用的字符不是很大,并且方便保存或者建立索引
什么是回表?
索引分为两种
- primary index,通常也是clustered index(聚集、聚簇索引),它的叶子节点会保存实际的物理数据
- secondary index,通常也是辅助索引,非聚集索引,它叶子几点保存为主键,而不是实际的物理数据,一般来说除了主键索引,一般都是这个,因为为了降低索引的成本而设计的
如果通过secondary index查出了需要的数据行,但是在secondary index中没有需要的列怎么办呢?那就只能获取id,然后在primary index中去读取全部数据了,这个过程叫做回表。
什么是索引覆盖
和回表相比,假设查询的属性列都在secondary index中呢?我们还需要回表操作吗?显然不需要,那么这个时候呢?secondary index的工作覆盖了primary index的工作,这就叫索引覆盖,Explain中的extra通常会显示using index

什么是ICP?(index condition pushdown)
Index Condition Pushdown (ICP) is an optimization for the case where MySQL retrieves rows from a table using an index. Without ICP, the storage engine traverses the index to locate rows in the base table and returns them to the MySQL server which evaluates the WHERE condition for the rows. With ICP enabled, and if parts of the WHERE condition can be evaluated by using only columns from the index, the MySQL server pushes this part of the WHERE condition down to the storage engine. The storage engine then evaluates the pushed index condition by using the index entry and only if this is satisfied is the row read from the table. ICP can reduce the number of times the storage engine must access the base table and the number of times the MySQL server must access the storage engine.
如果没有ICP,那么正常流程是这样的
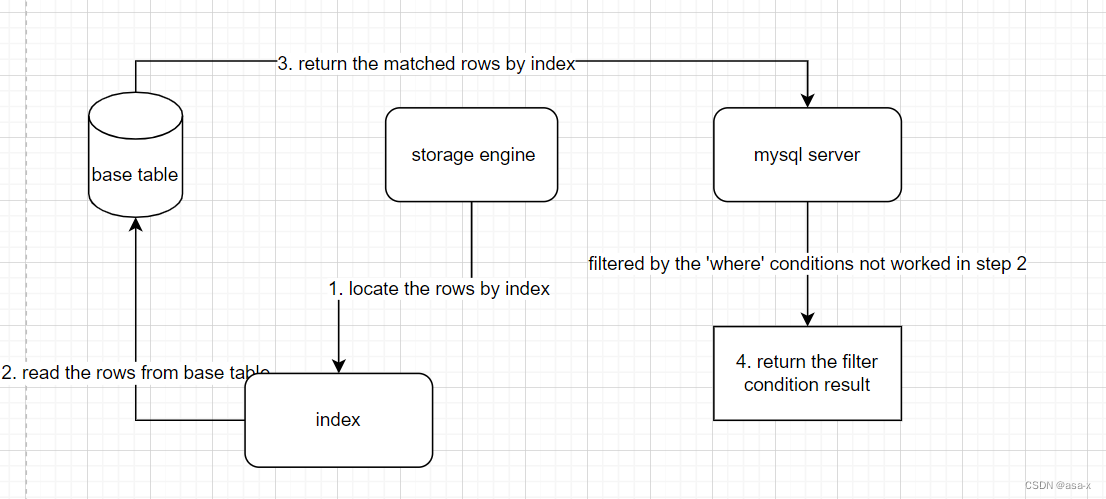
ICP优化下,流程是这样的
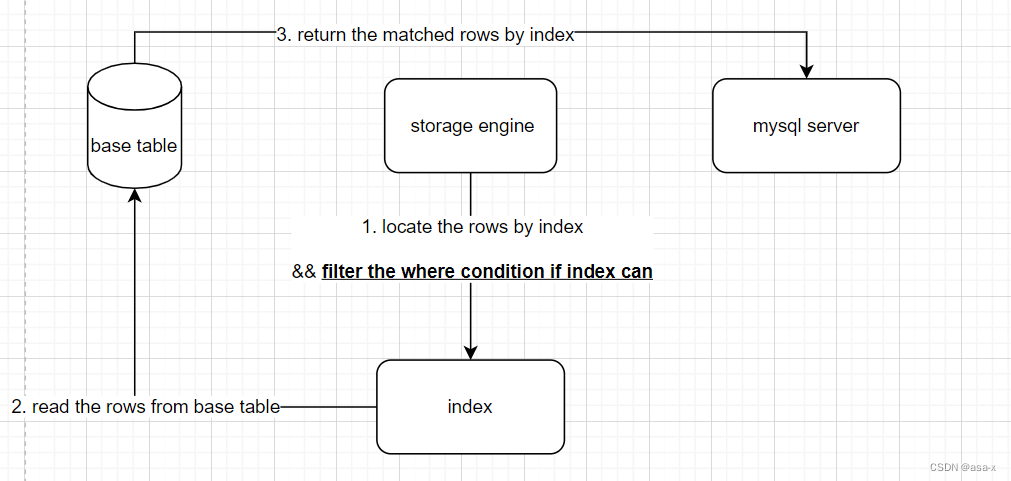
简单来说,就是如果index中存在where的过滤条件中的列但是因为最左原则或者其他的原因,导致index不能直接匹配的条件过去是先通过索引找到列,在放到缓存里过滤,现在这个过滤过程,放在index匹配的过程中了,匹配完再去表读取数据,这样就提升了读取速度。
但这个通常是有条件的:
- ICP is used for the range, ref, eq_ref, and ref_or_null access methods when there is a need to access full table rows. (需要回表操作)
- For InnoDB tables, ICP is used only for secondary indexes. The goal of ICP is to reduce the number of full-row reads and thereby reduce I/O operations. For InnoDB clustered indexes, the complete record is already read into the InnoDB buffer. Using ICP in this case does not reduce I/O. (需要辅助索引)
- Conditions that refer to subqueries cannot be pushed down.(子查询无法下沉)
有其他条件参考 ICP
Explain下type的类型
mysql explain type 访问类型解读
type显示的是访问类型,是一个较为重要的指标,值从优到劣分别为: system > const > eq_ref > ref > range > index > all
-
system
访问类型最高的,属于const类型的特例,表只有一条记录行(=系统表),一般不会出现这个,可以忽略. -
const
表示通过索引一次就能找到, const 用于比较primary或者unique(值是唯一的).因为只匹配一条数据,所以很快. 如果将主键置于where 子句中,mysql就能将该查询转为一个常量

-
eq_ref
唯一性索引扫描,对于每个索引建,表中只有一条记录与之对应,常见于唯一扫描或索引扫描.
与const不同的是eq_ref用于联合表的查询.读取连接表的一行,是system,const之外最好的连接类型.
SELECT * FROM bt_order left JOIN mt_user on (mt_user.id = bt_order.user_id)

It shows that one row is fetched from this table for each combination of rows of the previous table. If all the parts of the primary index or the unique not null index are used to fetch the data then the type is eq_ref
更偏重于表示一行数据通过了主键或者索引来锁定了这样的一个概念,而且这里会有个连表或者其他的组合‘combine’概念
- ref
非唯一索引扫描,返回匹配某个单独值的所有行.本质上也是一种索引访问,返回匹配单个值的所有行. 他可能会找到多个符合条件的行,所以说索引应该属于查找与扫描的混合体

The ref access method is slightly less efficient than const, but still an excellent choice if the right index is in place. Ref access is used when the query includes an indexed column that is being matched by an equality operator. If MySQL can locate the necessary rows based on the index, it can avoid scanning the entire table, speeding up the query considerably.
注意看到了吗? by an equality operator,表示用 =,如果不是话可能就会不同了

5. range
只检索给定范围的行,返回匹配指定区间的所有行,一般就是你的where子句中出现了如 between and , in , <,>等 的这种查询. 这种范围扫描的索引扫描比全表扫描要好,因为他只用开始于索引的某一点,结束与索引的某一点,不用扫描全部索引

When you use range in the where clause, MySQL knows that it will need to look through a range of values to find the right data. MySQL will use the B-Tree index to traverse from the top of the tree down to the first value of the range. From there, MySQL consults the linked list at the bottom of the tree to find the rows with values in the desired range. It’s essential to note that MySQL will examine every element in the range until a mismatch is found, so this can be slower than some of the other methods mentioned so far
上面有个概念:遍历直到不匹配,所以会性能比不过上面的几个
- index
Full index Scan ,与all 不同的是,index 为index类型只遍历索引数,这通常比all快,因为索引文件通常比数据文件小. 也就是说虽然all和index都是读全表,但是index是从index中读取的,而all是从磁盘读取的.
The index access method indicates that MySQL is scanning the entire index to locate the necessary data. Index access is the slowest access method listed so far, but it is still faster than scanning the entire table. When MySQL cannot use a primary or unique index, it will use index access if an index is available.

cannot use a primary or unique index, it will use index access if an index is available 这是指主键或者唯一键不可以使用+读取的属性列(necessary data)在索引中,不需要回表,否则会变成all

7. all
Full table Scan , 全表扫描,将遍历全表以找到匹配的行

性能最低的,没什么好说的。
附录:
Explain的各个字段的意义
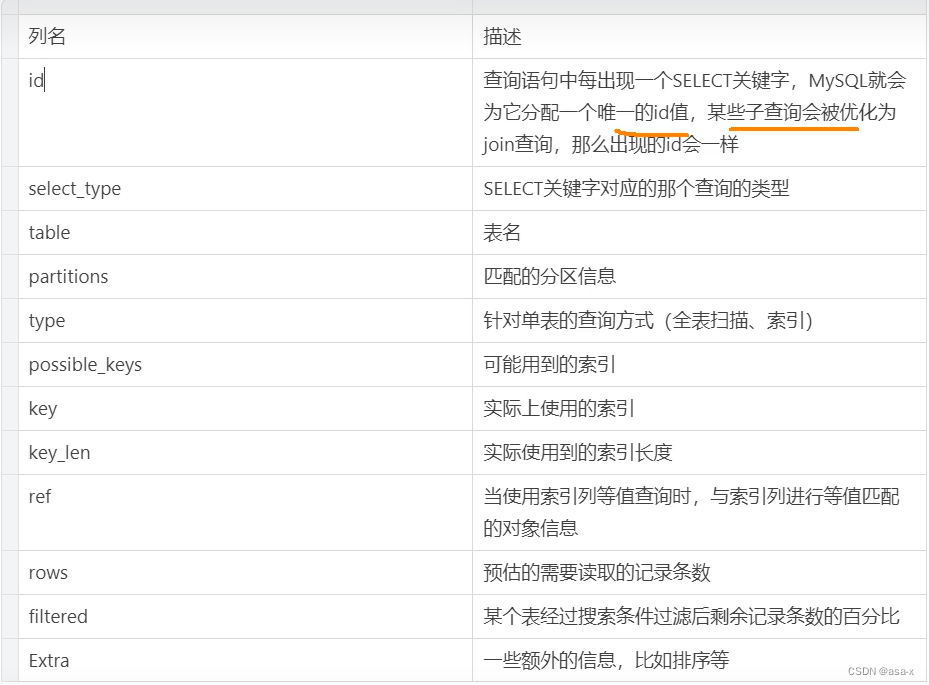
Extra的一些可能存在的信息
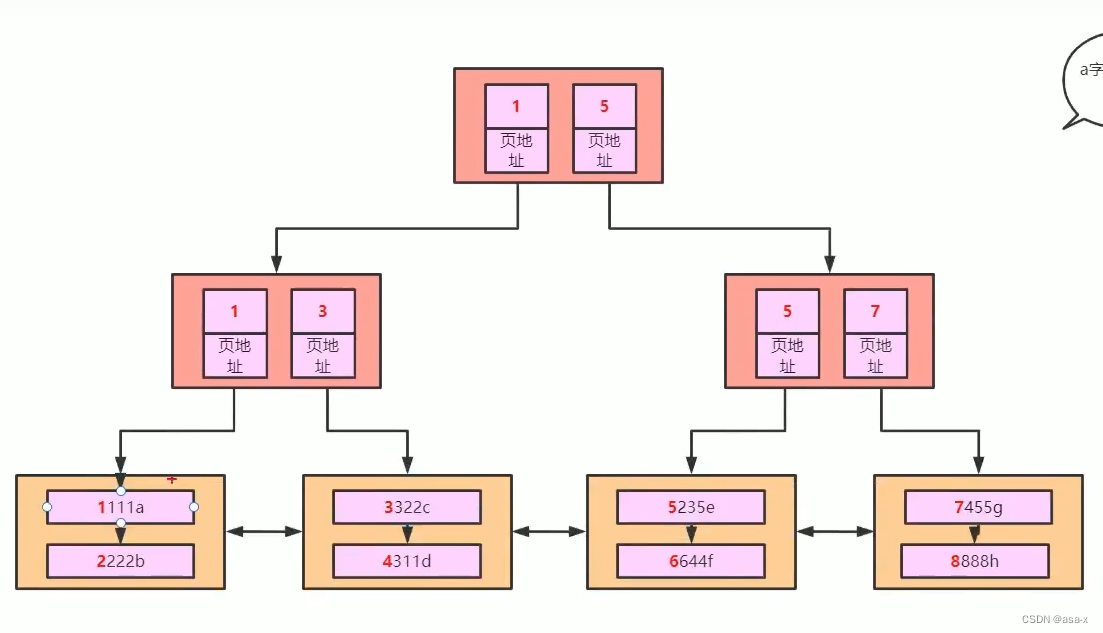
Mysql的基本结构
Page
通常为了提高列表的查询速度,我们会简历目录来分组,同时指定对应的地址坐标
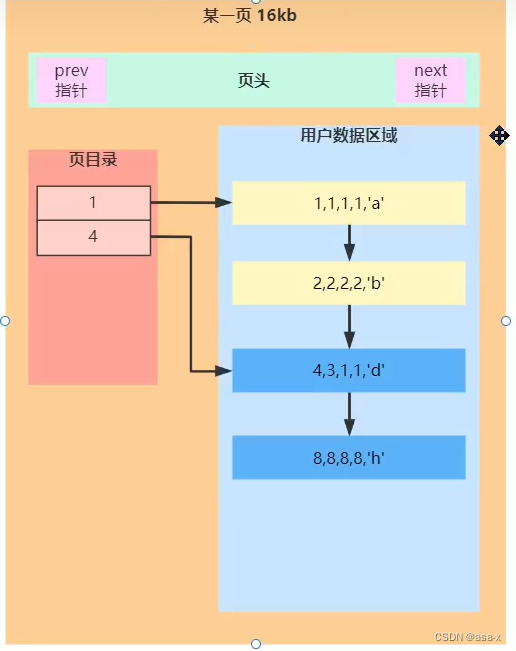
建立页目录的思想和文章目录,redis zset中的skipList的逻辑大差不差,只是不是树结构而已,但本质上依然是分治思想。
- 用户数据区,会通过主键来排序,所以,自增id会是很好的,效率比较高的主键选择方案
- 每页保存的数据条数是有限的,可以粗略的计算,假设为每条数据大小为1k,那么一页大概能保存16/1 = 16条数据
- 每页都有指向下一页和上一页的地址指针。
如何基于page来建立索引?
我们都知道叶子节点是数据(对于聚集索引来说),那么我们该如何建立索引呢?假设当前的实际数据页如下:
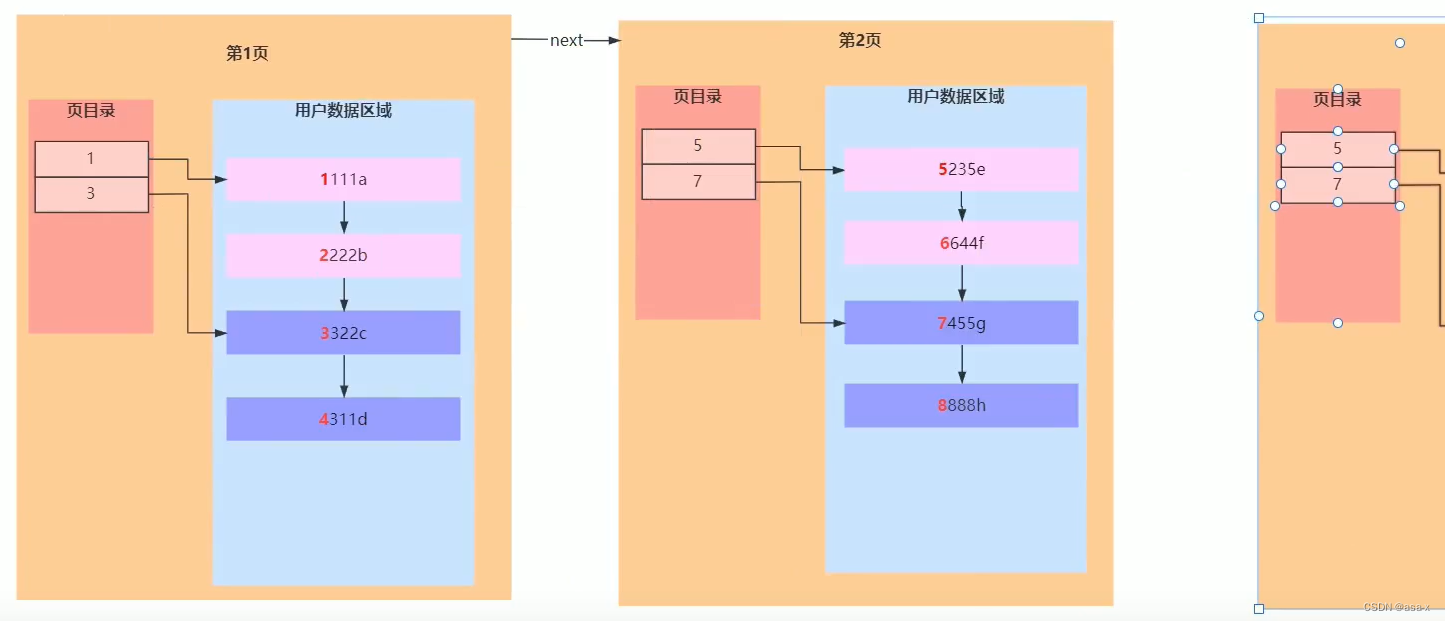
基于页的目录来说,我们可以提取一层索引(当前是基于聚集索引),建立索引的过程为,我们会在索引页中保存每个叶子结点的开始id(int=4b)和地址指针(6b)
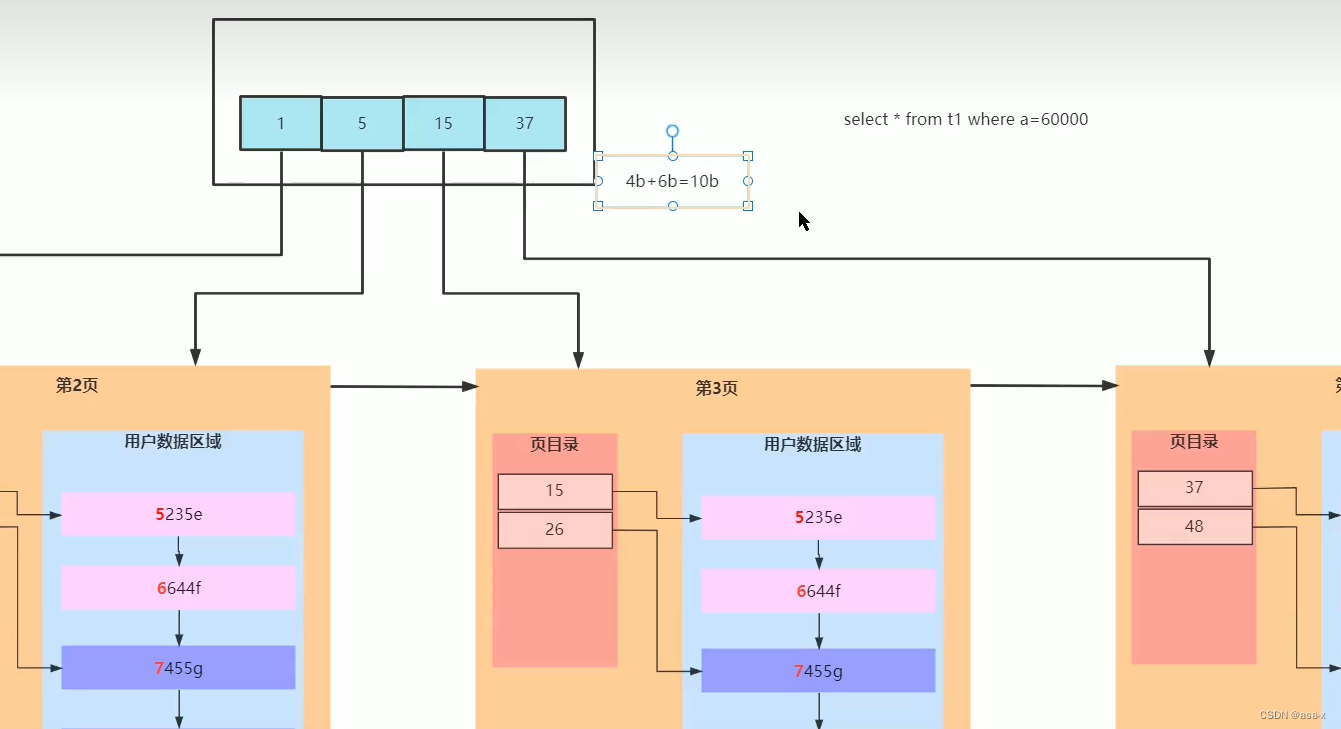
那么 一页的索引可以保存多少条索引数据呢?
16k/10b = 161024/10 = 1638
所以,如果是只有两层的索引的话,那么只能保存1638 * 16条数据,这显然是不够的,为了提升索引支持的数据,我们再加 一层,也就是三层,因为加的索引页结构是不变的,那么root的索引页可以保存 16k/10 = 1638个索引数据,总结起来就是
16381638*16 = 42928704,约4kw条数据,但是这是理想状态下,正常来说是约为2kw条数据左右。