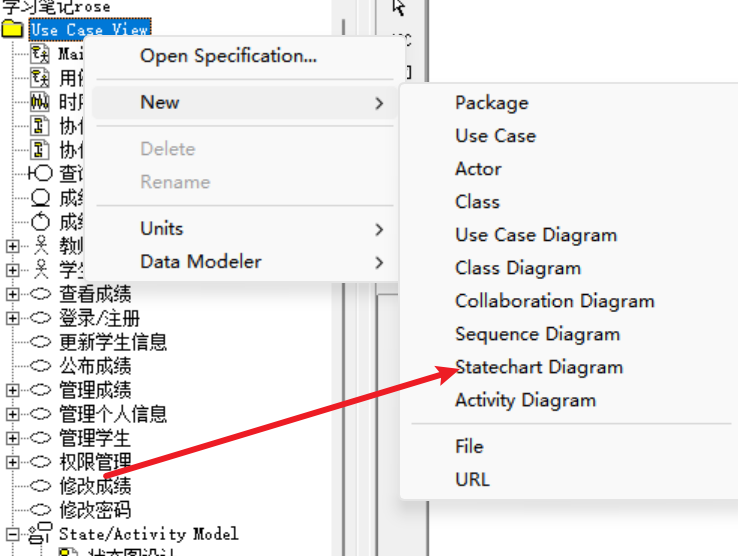
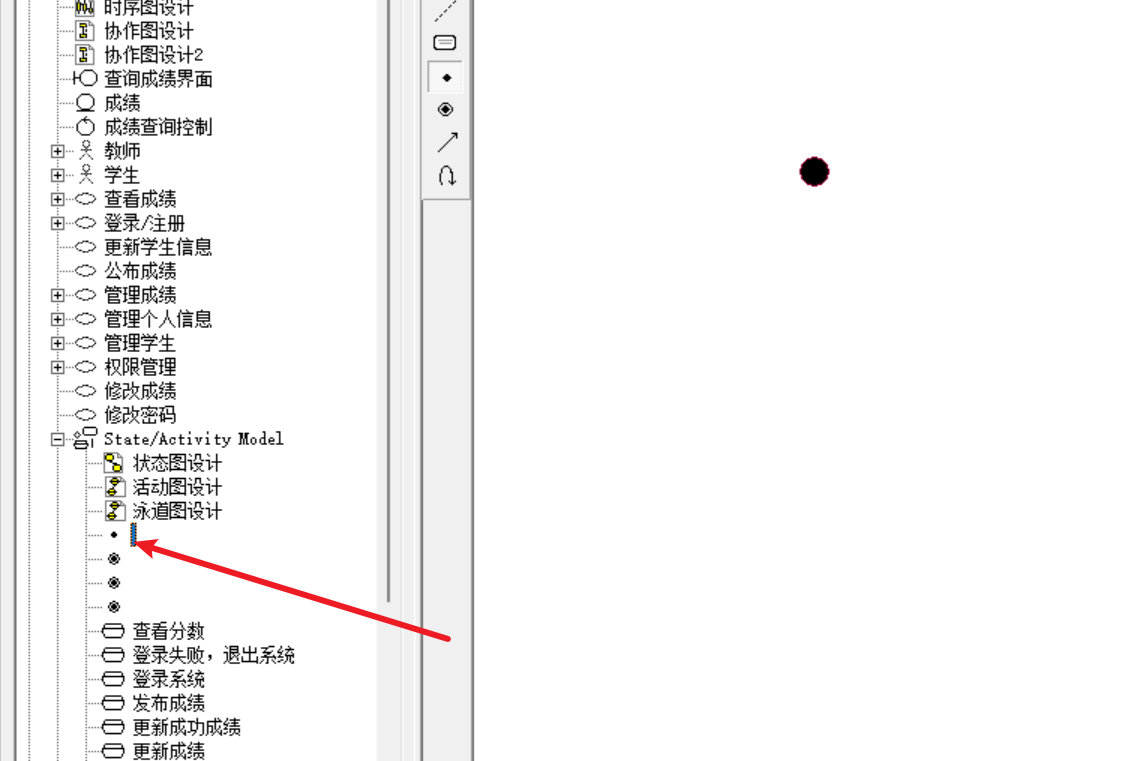
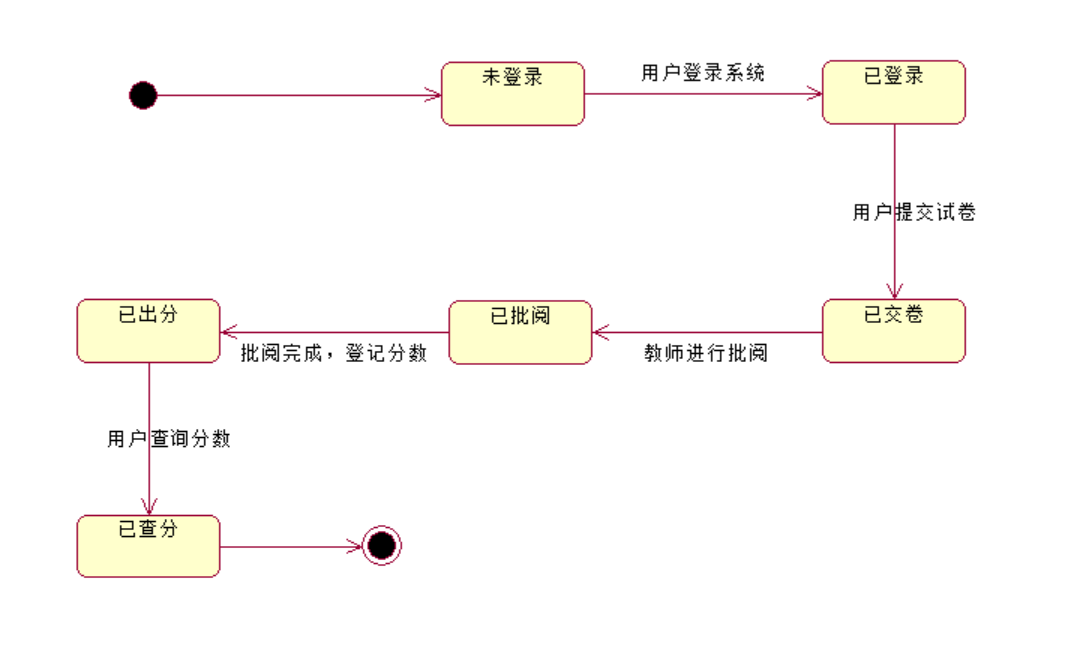
UML系列之Rational Rose笔记七:状态图



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/1178.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

快速上手 INFINI Console 的 TopN 指标功能
背景
在分布式搜索引擎系统(如 Easysearch、Elasticsearch 和 OpenSearch)中,性能监控至关重要。为了确保系统的高效运行和资源的合理分配,我们通常需要关注一段时间内关键资源的使用情况,特别是索引、节点和分片的内…

springboot vue uniapp 仿小红书 1:1 还原 (含源码演示)
线上预览: 移动端 http://8.146.211.120:8081/ 管理端 http://8.146.211.120:8088/ 小红书凭借优秀的产品体验 和超高人气 目前成为笔记类产品佼佼者 此项目将详细介绍如何使用Vue.js和Spring Boot 集合uniapp 开发一个仿小红书应用,凭借uniapp 可以在h5 小程序 app…

面向对象分析与设计Python版 分析与设计概述
文章目录 一、软件工程概述二、分析与设计概述三、领域模型 一、软件工程概述
高质量软件系统的基本要求
架构性内聚可重用性可维护性可扩展性灵活性
软件开发过程模型:是指根据软件开发项目从开始到结束的一系列步骤和方法,建模为不同的模型。常见的…

3D目标检测数据集——Waymo数据集
Waymo数据集簡介 发布首页:https://waymo.com/open/ 论文:https://openaccess.thecvf.com/content_CVPR_2020/papers/Sun_Scalability_in_Perception_for_Autonomous_Driving_Waymo_Open_Dataset_CVPR_2020_paper.pdf github:https://github.…
![[笔记] 使用 Jenkins 实现 CI/CD :从 GitLab 拉取 Java 项目并部署至 Windows Server](https://i-blog.csdnimg.cn/direct/80690f955e024be69ee1d43474992041.png)
[笔记] 使用 Jenkins 实现 CI/CD :从 GitLab 拉取 Java 项目并部署至 Windows Server
随着软件开发节奏的加快,持续集成(CI)和持续部署(CD)已经成为确保软件质量和加速产品发布的不可或缺的部分。Jenkins作为一款广泛使用的开源自动化服务器,为开发者提供了一个强大的平台来实施这些实践。然而…

基于“大型园区”网络设计
基于“大型园区”网络设计
目 录
第1章 项目概述1
1.1 项目背景1
1.2 公司概况1
1.3 网络现状2
第2章 需求分析4
2.1 部门需求4
2.2 配置需求4
2.3 网络功能需求5
第3章 网络设计6
3.1 建设原则6
3.2 网络拓扑结构6
3.3 IP地址和VLAN划分8
3.4 核心层设计9
3.5 …

回归预测 | MATLAB实RVM-Adaboost相关向量机集成学习多输入单输出回归预测
回归预测 | MATLAB实RVM-Adaboost相关向量机集成学习多输入单输出回归预测 目录 回归预测 | MATLAB实RVM-Adaboost相关向量机集成学习多输入单输出回归预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍
RVM-Adaboost相关向量机集成学习多输入单输出回归预测是一种先进…

力扣经典练习题之70.爬楼梯
今天继续给大家分享一道力扣的做题心得今天这道题目是70.爬楼梯
题目如下: 题目链接:70.爬楼梯 1,题目分析 这个题目是一个经典的动态规划问题,它帮助我们理解如何通过分解问题来找到解决方案。在现实生活中,很多复杂…

Vue学习二——创建登录页面
前言
以一个登录页面为例子,这篇文章简单介绍了vue,element-plus的一些组件使用,vue-router页面跳转,pinia及持久化存储,axios发送请求的使用。后面的页面都大差不差,也都这么实现,只是内容&am…

ZYNQ初识10(zynq_7010)UART通信实验
基于bi站正点原子讲解视频:
系统框图(基于串口的数据回环)如下: 以下,是串口接收端的波形图,系统时钟和波特率时钟不同,为异步时钟,,需要先延时两拍,将时钟同…

java小知识点总结
一、比特流的本质就是数组
二、位运算
位运算就是CPU的底层原理,半导体电路进行位运算 位运算涉及一些算法,&和^
^ 异或 两变量交换值,不依赖第三个变量
x^s k 异或知道两者就能推另一个
a a<<2就是乘以2的多少次方
相反 a…

vue3后台系统动态路由实现
动态路由的流程:用户登录之后拿到用户信息和token,再去请求后端给的动态路由表,前端处理路由格式为vue路由格式。
1)拿到用户信息里面的角色之后再去请求路由表,返回的路由为tree格式
后端返回路由如下: …


CVE-2025-22777 (CVSS 9.8):WordPress | GiveWP 插件的严重漏洞
漏洞描述
GiveWP 插件中发现了一个严重漏洞,该插件是 WordPress 最广泛使用的在线捐赠和筹款工具之一。该漏洞的编号为 CVE-2025-22777,CVSS 评分为 9.8,表明其严重性。 GiveWP 插件拥有超过 100,000 个活跃安装,为全球无数捐赠平…

ubuntu官方软件包网站 字体设置
在https://ubuntu.pkgs.org/22.04/ubuntu-universe-amd64/xl2tpd_1.3.16-1_amd64.deb.html搜索找到需要的软件后,点击,下滑,
即可在Links和Download找到相关链接,下载即可, 但是找不到ros的安装包,
字体设…

细说STM32F407单片机以DMA方式读写外部SRAM的方法
目录
一、工程配置
1、时钟、DEBUG、GPIO、CodeGenerator
2、USART3
3、NVIC
4、 FSMC
5、DMA 2
(1)创建MemToMem类型DMA流
(2)开启DMA流的中断
二、软件设计
1、KEYLED
2、fsmc.h、fsmc.c、dma.h、dma.c
3、main.h…

二分查找算法——山脉数组的峰顶索引
一.题目描述
852. 山脉数组的峰顶索引 - 力扣(LeetCode) 二.题目解析
题目给了我们一个山脉数组,山脉数组的值分布就如下面的样子:
然后我们只需要返回数组的峰值元素的下标即可。
三.算法原理
1.暴力解法
因为题目明确说明…
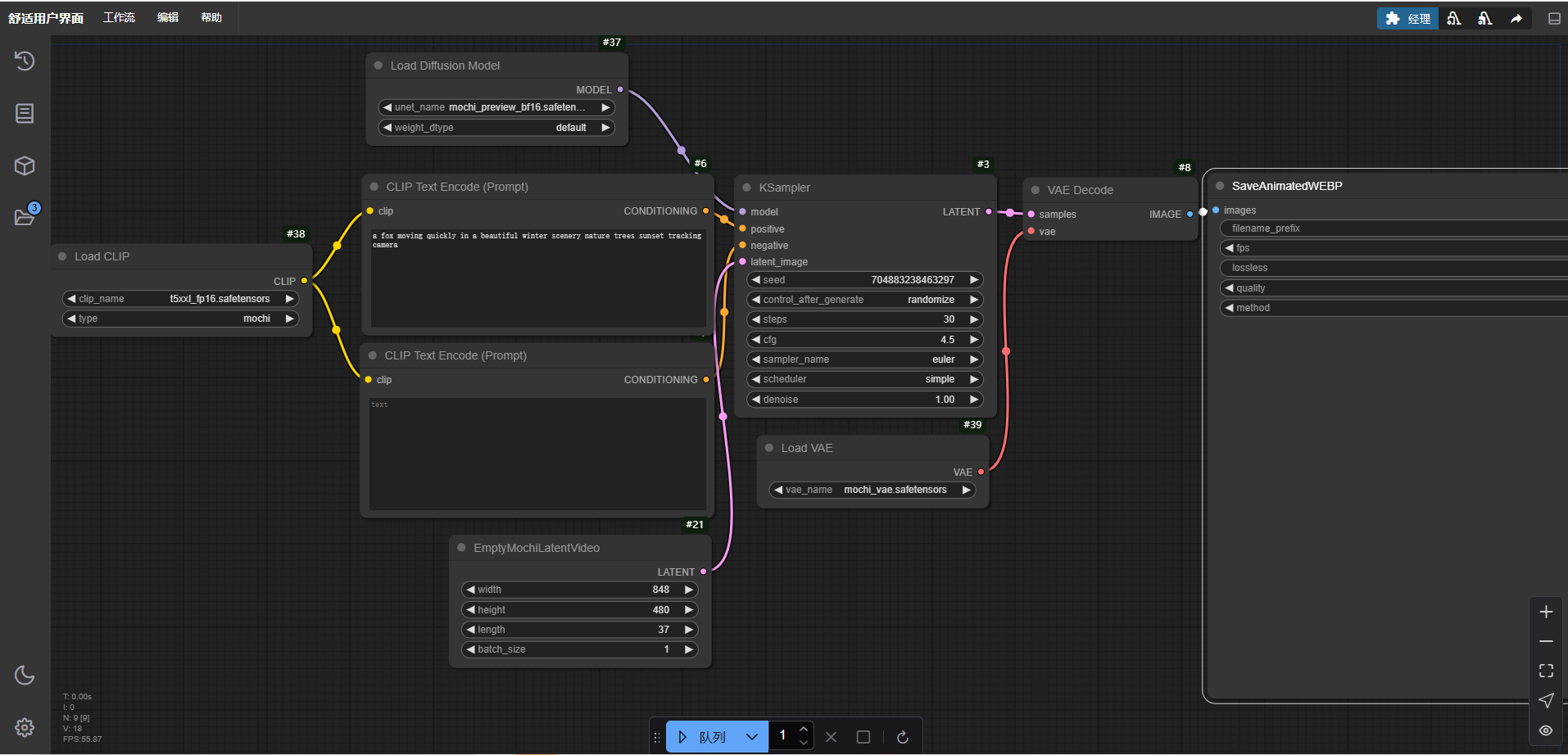
重塑视频创作的格局!ComfyUI-Mochi本地部署教程
一、介绍 mochi是近期Genmo公司开源的先进视频生成模型,具有高保真运动和强大的提示遵循性。此模型的发布极大的缩小了闭源和开源视频生成系统之间的差距。 目前,视频生成模型与现实之间存在巨大差距。其中最影响视频生成的两个关键功能也就是运动质量和…

Docker 安装开源的IT资产管理系统Snipe-IT
一、安装
1、创建docker-compose.yaml
version: 3services:snipeit:container_name: snipeitimage: snipe/snipe-it:v6.1.2restart: alwaysports:- "8000:80"volumes:- ./logs:/var/www/html/storage/logsdepends_on:- mysqlenv_file:- .env.dockernetworks:- snip…

Oracle重启后业务连接大量library cache lock
一、现象
数据库和前段应用重启后,出现大量library cache lock等待事件。 二、分析解决
本次异常原因是:原因定位3: 库缓存对象无效 Library cache object Invalidations 三、各类情况具体分析如下
原因定位1:由于文字导致的非…
推荐文章
- “百镜大战”引爆AI眼镜元年:端侧大模型+轻量化设计,2025销量或暴增230%!
- ### Java二维字符矩阵输入解析:正确读取由0和1组成的矩阵
- (动态规划 最长递增的子序列)leetcode 300
- (二)VMware:VMware虚拟机安装CentOS教程
- [AI]Mac本地部署Deepseek R1模型 — — 保姆级教程
- [C#]C# winform部署yolov12目标检测的onnx模型
- [C]基础8.详解操作符
- [C++] 智能指针 进阶
- [Easy] leetcode-500 键盘行
- [QT]深入理解Qt中的信号与槽机制
- [权限提升] Wdinwos 提权 维持 — 系统错误配置提权 - Trusted Service Paths 提权
- 《Spring日志整合与注入技术:从入门到精通》