目录
为什么要精通深度学习的高级内容
高级内容包含哪些武器
1. 模型资源
2. 设计思想与二次研发
3. 工业部署
4. 飞桨全流程研发工具
5. 行业应用与项目案例
飞桨开源组件使用场景概览
框架和全流程工具
1. 模型训练组件
2. 模型部署组件
3. 其他全研发流程的辅助工具
模型资源
为什么要精通深度学习的高级内容
在前面章节中,我们首先学习了神经网络模型的基本知识和使用飞桨编写深度学习模型的方法,再学习了计算机视觉、自然语言处理和推荐系统的模型实现方法。
但在人工智能的战场上取得胜利并不容易,我们还将面临如下挑战:
- 需要针对业务场景提出建模方案;
- 探索众多的复杂模型哪个更加有效;
- 探索将模型部署到各种类型的硬件上。
高级内容包含哪些武器
1. 模型资源
如今深度学习应用已经在诸多领域落地,研发人员建模的首选方案往往不是自己编写,而是使用现成的模型,或者在现成的模型上优化。这一方面会极大地减少研发人员的工作量,另一方面现成的模型一般在精度和性能上经过精进打磨,效果更好。
那么,去哪里找现成的模型资源呢?
飞桨提供了三种类型的模型资源:
- 预训练模型工具(PaddleHub);
- 特定场景的开发套件,遍布计算机视觉、自然语言处理、语音、推荐系统等领域的十几个任务(如飞桨图像分割套件PaddleSeg,飞桨语义理解套件ERNIE等);
- 开源的模型库(Paddle Models)
2. 设计思想与二次研发
当读者挑战一些最新的模型时,少数情况下会碰到模型需要的算子飞桨没有实现的情况。本章会告诉大家为飞桨框架增加自定义算子的方法,并通过讲述动态图和静态图的实现原理,让大家对飞桨框架的设计思路有一个更深入的认知。
3. 工业部署
与模型的科研和教学不同,工业应用中的模型是需要部署在非常丰富的硬件环境上的,比如将模型嵌入用C++语言写的业务系统,将模型作为单独的Web服务,或将模型放到摄像头上等等。本章会介绍Paddle Inference、Paddle Serving和Paddle Lite来满足上面这些需求场景,并介绍模型压缩工具Paddle Slim,可以让模型在有限条件的硬件上以更快的速度运行。
4. 飞桨全流程研发工具
飞桨为大家提供了这么多的模型资源和工具组件,如何串联这些组件,并研发一个适合读者所在行业的可视化建模工具? 本章会以一个官方出品的Demo为案例,向读者展示PaddleX可以为用户提供的全流程服务。
5. 行业应用与项目案例
权威的咨询机构艾瑞预测未来十年人工智能的产业规模增长率达40%,人工智能也作为国家新基建的战略重点,国务院关于AI应用发展规划也有很高的增长预期。虽然人工智能赋能各行各业在蓬勃发展,但依然有传统行业的朋友心存疑虑:
“我所在的行业太传统,人工智能没有用武之地吧?”
本章以能源行业为例,分析一家典型的电力企业在业务中可以用人工智能优化的环节,并展示基于飞桨建模的真实项目。
人工智能和深度学习是实践科学,如果这些武器不实际动手操练,是无法在战场上运用自如的。所以,本章精心选配了6个作业比赛,可以让大家在有趣的案例实践中,真正掌握这些武器,与最顶级的深度学习专家一拼高下。
飞桨开源组件使用场景概览
接下来我们通过一张概览图回顾下飞桨提供的全套武器。飞桨以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心框架、基础模型库、端到端开发套件、工具组件和服务平台于一体,为用户提供了多样化的配套服务产品,助力深度学习技术的应用落地。飞桨支持本地和云端两种开发和部署模式,用户可以根据业务需求灵活选择。
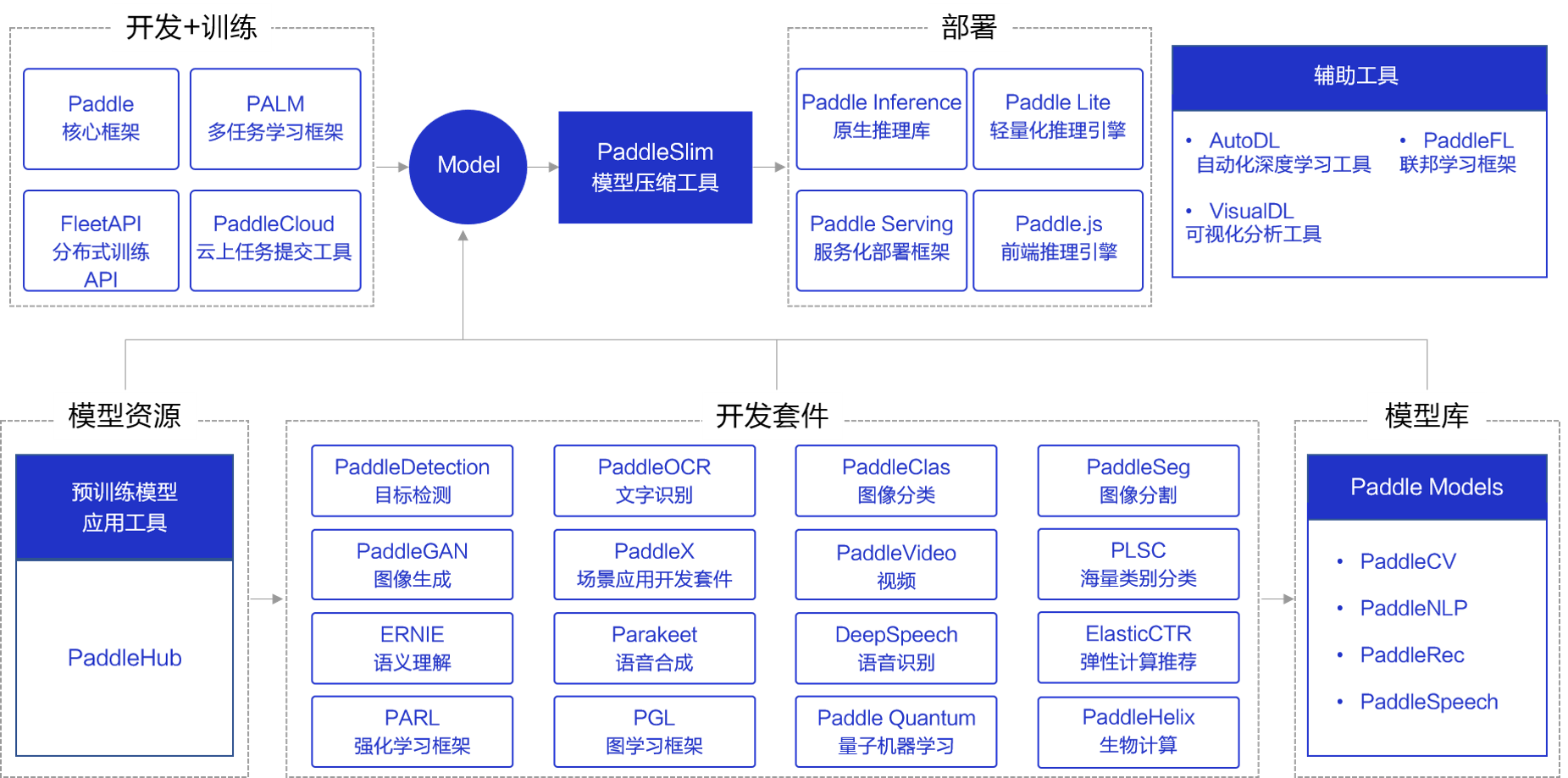
图1:飞桨PaddlePaddle组件使用场景概览
概览图上半部分是从开发、训练到部署的全流程工具,下半部分是预训练模型、各领域的开发套件和模型库等模型资源。
框架和全流程工具
飞桨在提供用于模型研发的基础框架外,还推出了一系列的工具组件,来支持深度学习模型从训练到部署的全流程。
1. 模型训练组件
飞桨提供了分布式训练框架FleetAPI,还提供了开启云上任务提交工具PaddleCloud。同时,飞桨也支持多任务训练,可使用多任务学习框架PALM。
2. 模型部署组件
飞桨针对不同硬件环境,提供了丰富的支持方案:
- Paddle Inference:飞桨原生推理库,用于服务器端模型部署,支持Python、C、C++、Go等语言,将模型融入业务系统的首选。
- Paddle Serving:飞桨服务化部署框架,用于云端服务化部署,可将模型作为单独的Web服务。
- Paddle Lite:飞桨轻量化推理引擎,用于Mobile、IoT等场景的部署,有着广泛的硬件支持。
- Paddle.js:使用JavaScript(Web)语言部署模型,用于在浏览器、小程序等环境快速部署模型。
- PaddleSlim:模型压缩工具,获得更小体积的模型和更快的执行性能。
- X2Paddle:飞桨模型转换工具,将其他框架模型转换成Paddle模型,转换格式后可以方便的使用上述5个工具。
3. 其他全研发流程的辅助工具
- AutoDL:飞桨自动化深度学习工具,旨在自动网络结构设计,开源的AutoDL设计的图像分类网络在CIFAR10数据集正确率 达到 98%,效果优于目前已公开的10类人类专家设计的网络,居于业内领先位置。
- VisualDL:飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布、精度召回曲线等模型关键信息。帮助用户清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型调优、并将算法训练过程及结果分享。
- PaddleFL:飞桨联邦学习框架,研究人员可以很轻松地用PaddleFL复制和比较不同的联邦学习算法,便捷地实现大规模分布式集群部署,并且提供丰富的横向和纵向联邦学习策略及其在计算机视觉、自然语言处理、推荐算法等领域的应用。此外,依靠着PaddlePaddle的大规模分布式训练和Kubernetes对训练任务的弹性调度能力,PaddleFL可以基于全栈开源软件轻松部署。
模型资源
飞桨提供了丰富的端到端开发套件、预训练模型和模型库。
PaddleHub:飞桨预训练模型应用工具,覆盖文本、图像、视频、语音四大领域超过200个高质量预训练模型。开发者可以轻松结合实际业务场景,选用高质量预训练模型并配合Fine-tune API快速完成模型验证与应用部署工作。适用于个人开发者学习、企业POC快速验证、参加AI竞赛以及教学科研等多种业务场景。
开发套件:针对具体的应用场景提供了全套的研发工具,例如在图像检测场景不仅提供了预训练模型,还提供了数据增强等工具。开发套件也覆盖计算机视觉、自然语言处理、语音、推荐这些主流领域,甚至还包括图神经网络和增强学习。与PaddleHub不同,开发套件可以提供一个领域极致优化(State Of The Art)的实现方案,曾有国内团队使用飞桨的开发套件拿下了国际建模竞赛的大奖。一些典型的开发套件包括:
- PaddleClas:飞桨图像分类套件,目的是为工业界和学术界提供便捷易用的图像分类任务预训练模型和工具集,打通模型开发、训练、压缩、部署全流程,辅助其它高层视觉任务组网并提升模型效果,助力开发者训练更好的图像分类模型和应用落地。
- PaddleDetection:飞桨目标检测套件,旨在帮助开发者更快更好地完成检测模型的训练、精度速度优化到部署全流程。PaddleDetection以模块化的设计实现了多种主流目标检测算法,并且提供了丰富的数据增强、网络组件、损失函数等模块,集成了模型压缩和跨平台高性能部署能力。目前基于PaddleDetection已经完成落地的项目涉及工业质检、遥感图像检测、无人巡检等多个领域。
- PaddleSeg:飞桨图像分割套件,覆盖了DeepLabv3+/OCRNet/BiseNetv2/Fast-SCNN等高精度和轻量级等不同方向的大量高质量分割模型。通过模块化的设计,提供了配置化驱动和API调用等两种应用方式,帮助开发者更便捷地完成从训练到部署的全流程图像分割应用。
- PaddleOCR: 飞桨文字识别套件,旨在打造一套丰富、领先、且实用的OCR工具库,开源了基于PPOCR实用的超轻量中英文OCR模型、通用中英文OCR模型,以及德法日韩等多语言OCR模型。并提供上述模型训练方法和多种预测部署方式。同时开源文本风格数据合成工具Style-Text和半自动文本图像标注工具PPOCRLable。
- PaddleGAN:飞桨图像生成开发套件,集成风格迁移、超分辨率、动漫画生成、图片上色、人脸属性编辑、妆容迁移等SOTA算法,以及预训练模型。并且模块化设计,以便开发者进行二次研发,或是直接使用预训练模型做应用。
- PaddleX:飞桨场景应用开发套件,以低代码的形式支持开发者快速实现深度学习算法开发及产业部署。提供极简Python API和可视化界面Demo两种开发模式,可一键安装。针对CPU(OpenVINO)、GPU、树莓派等通用硬件提供完善的部署方案,并可通过RESTful API快速完成集成、再开发,开发者无需分别使用不同套件即可完成全流程模型生产部署。可视化推理界面及丰富的产业案例更为开发者提供飞桨全流程开发的最佳实践。
- PLSC:飞桨海量类别分类套件,为用户提供了大规模分类任务从训练到部署的全流程解决方案。提供简洁易用的高层API,通过数行代码即可实现千万类别分类神经网络的训练,并提供快速部署模型的能力。
- ERNIE:基于持续学习的知识增强语义理解框架实现,内置业界领先的系列ERNIE预训练模型,能够 支持各类NLP算法任务Fine-tuning, 包含保证极速推理的Fast-inference API, 灵活部署的ERNIE Service和轻量化解决方案ERNIE Slim,训练过程所见即所得,支持动态debug,同时方便二次开发。
- ElasticCTR:飞桨弹性计算推荐套件,可以实现分布式训练CTR预估任务和基于Paddle Serving的在线个性化推荐服务。Paddle Serving服务化部署框架具有良好的易用性、灵活性和高性能,可以提供端到端的CTR训练和部署解决方案。ElasticCTR具备产业实践基础、弹性调度能力、高性能和工业级部署等特点。
- Parakeet:飞桨语音合成套件,提供了灵活、高效、先进的文本到语音合成工具,帮助开发者更便捷高效地完成语音合成模型的开发和应用。
- PGL:飞桨图学习框架,业界首个提出通用消息并行传递机制, 支持百亿规模巨图的工业级图学习框架。PGL基于飞桨动态图全新升级,极大提升了易用性,原生支持异构 图,支持分布式图存储及分布式学习算法,覆盖30+图学习模型,包括图语义理解模型ERNIESage等。历经 大量真实工业应用验证,能够灵活、高效地搭建前沿的大规模图学习算法。
- PARL:飞桨深度强化学习框架,在2018, 2019, 2020夺得强化学习挑战赛三连冠。具有高灵活性、可扩展性和高性能的特点。实现了十余种主流强化学习算法的示例,覆盖了从单智能体到多智能体,离散决策到连续控制不同领域的强化学习算法支持。基于GRPC机制实现数千台CPU和GPU的高性能并行。
- Paddle Quantum:量桨,飞桨量子机器学习框架,提供量子优化、量子化学等前沿应用工具集,常用量子电路模型,以及丰富的量子机器学习案例,帮助开发者便捷地搭建量子神经网络,开发量子人工智能应用。
- PaddleHelix:飞桨螺旋桨生物计算框架,开放了赋能疫苗设计,新药研发,精准医疗的AI能力。在疫苗设计上,PaddleHelix的LinearRNA系列算法相比传统方法在RNA折叠上提升了几百上千倍的效率; 在新药研发上,PaddleHelix提供了基于大规模数据预训练的分子表示,助力分子性质预测,药物筛选,药物设计等领域;在精准医疗上,PaddleHelix提供了利用组学信息精准定位药物,提升治愈率的高性能模型。
模型库:包含了各领域丰富的开源模型代码,不仅可以直接运行模型,还可以根据应用场景的需要修改原始模型代码,得到全新的模型实现。
比较三种类型的模型资源,PaddleHub的使用最为简易,模型库的可定制性最强且覆盖领域最广泛。读者可以参考“PaddleHub->各领域的开发套件->模型库”的顺序寻找需要的模型资源,在此基础上根据业务需求进行优化,即可达到事半功倍的效果。