笔记整理:田家琛,天津大学博士,研究方向为文本分类
链接:https://ojs.aaai.org/index.php/AAAI/article/view/26599
动机
近年来,随着预训练语言模型(PLMs)在情感分类领域的广泛应用,PLMs中存在的命名实体情感偏差问题也引起了越来越多的关注。具体而言,当前的PLMs基于神经上下文编码器,倾向于将某些命名实体上下文中的情感信息应用到表示学习过程中,使得命名实体与情感之间容易形成虚假的相关性。本文提出了一种基于自适应Gumbel攻击的情感分类器Gater,在保证文本语义一致性的前提下,利用对抗攻击策略缓解情感偏差问题。首先,该分类器内置多个可生成Gumbel噪声的专家网络,通过最小化网络输出之间的互信息来增加噪声多样性。然后,在模型训练期间,利用Gumel噪声攻击分类器输出,根据攻击前后置信度的变化情况判断攻击是否有效。最后,采用多路参数优化算法将多个专家网络参数和分类器参数进行融合,使分类器对专家网络模拟的情感偏差产生免疫。实验结果表明,该方法在不破坏情感分类性能的前提下,有效地缓解了PLMs中存在的命名实体情感偏差问题。
亮点
Gater的亮点主要包括:
(1) 提出利用Gumbel噪声缓解命名实体情感偏差。Gumbel分布作为第一类型的广义极值分布,采样噪声大部分来自于分布的尾部,对分类器输出的改动幅度较小,有利于保护其原有的语义分布。
(2) 提出多路参数优化算法。根据专家网络的攻击效果,将多个专家网络的参数融合到分类模型中,有效地丰富了模型的参数更新方向。
模型简介
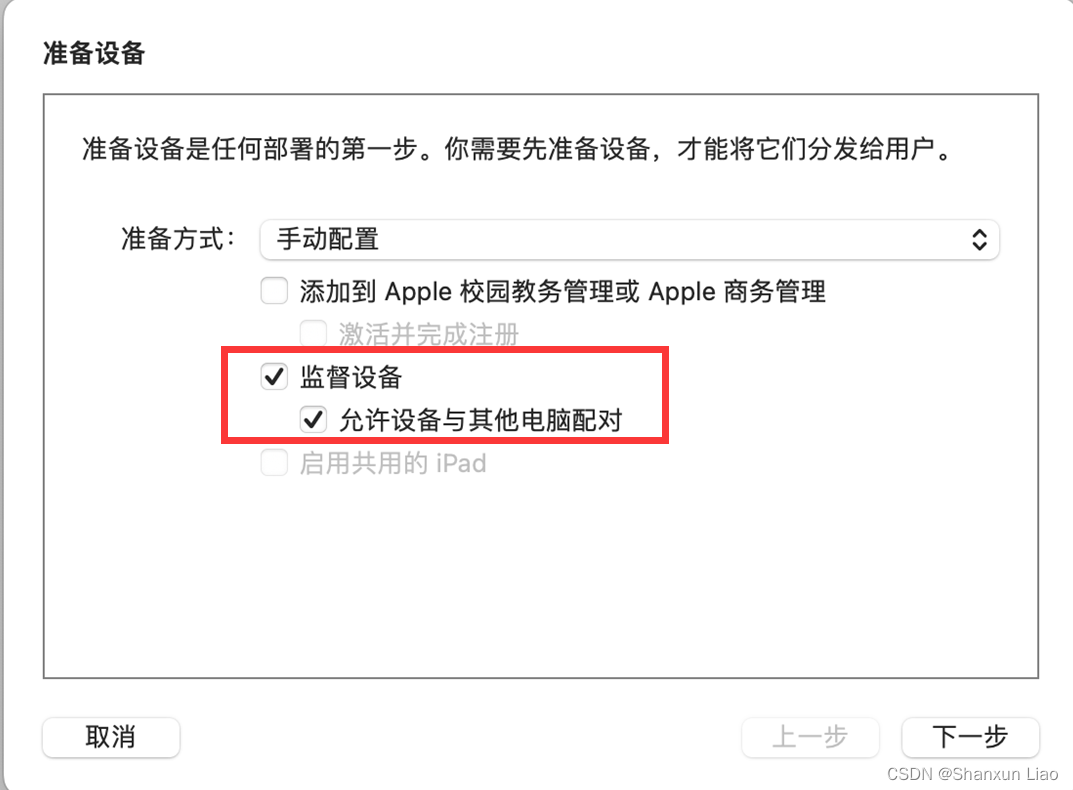
如图1所示,在前向传播阶段,Gater自适应地为原始分类器 添加 个专家网络,每个专家网络包含一个攻击模块 和一个基础模块 ,其中 。 负责模拟有情感偏差的情况, 负责模拟没有情感偏差的情况,它们经过对比之后输出模拟的情感偏差,用来攻击 中的情感偏差。
具体而言, 和 的输入是仅包含命名实体的文本向量表示。训练每个专家网络时,Gater通过最大化 输入与输出之间的互信息(损失函数 ),保证 中的情感偏差不再变化;通过最大化 输出与加入Gumbel噪声的输入之间的互信息(损失函数 ),使 学会Gumbel攻击;通过最小化 之间的互信息(损失函数 ),保证Gumbel噪声的多样性。此外,模型使用Softmax层的输出来评估采样效果。在下一轮的训练中,效果不好的专家网络将被重置参数。
在反向传播阶段,多路参数优化算法的目标是融合 与每个 和 的参数,使 获得情感去偏的能力。例如,对于 进行参数更新,首先使用梯度下降算法更新 的参数,并进一步融合 、 和 的参数。即:
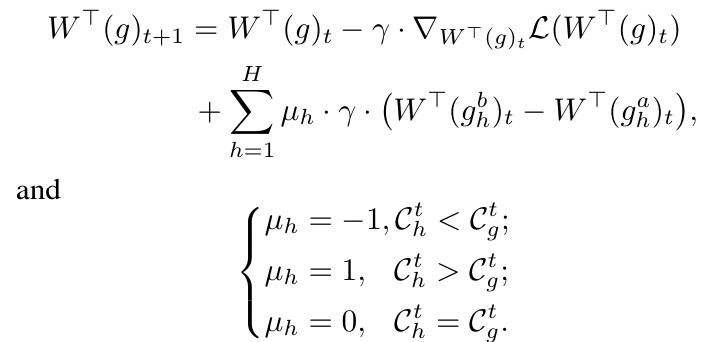
其中, 指的是 在第 个训练批次时的参数。 是选择的损失函数。 是 在第 个训练批次时的平均置信度。当 μ 时,表明第 个专家网络无法降低情感偏差,因此分类器 的参数应该远离第 个专家网络的参数。当 μ 时,表示第 个专家网络实现了情感去偏,因此分类器 的参数应该与第 个专家网络的参数接近。当 μ 时,表示第 个专家网络无效,应该保持分类器 原有的参数更新方向。
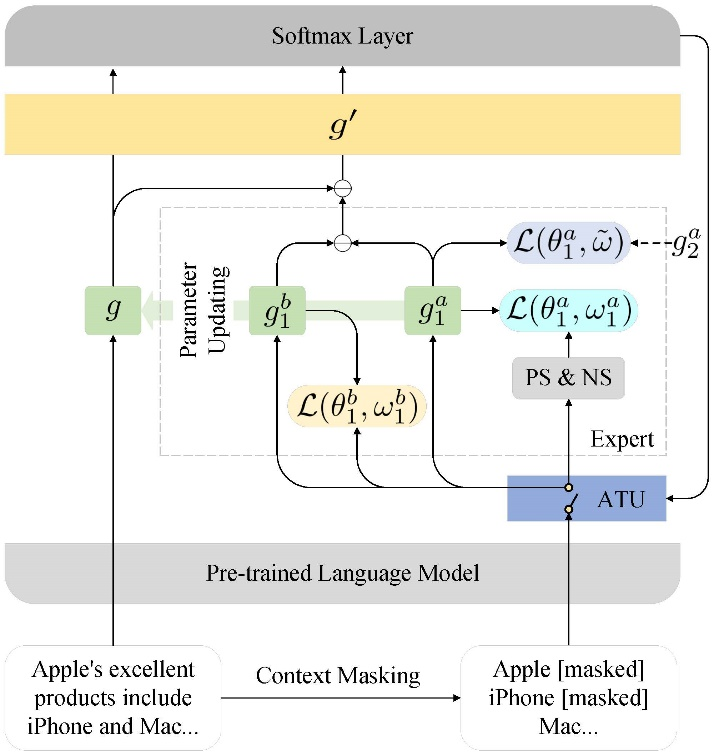
图1 Gater总体架构图
实验
本文在七个真实数据集上进行实验,它们分别是IMDb、SST-2、YELP-2、YELP-5、Amazon-2、Amazon-5和SemEval。此外,本文选择的预训练模型分别是BERT、RoBERT、ALBERT和ELECTRA。
之前的研究发现,目前的去偏方法可能会过度去偏,导致下游任务的性能下降。实验结果表明(表1),Gater可以有效地避免过度去偏问题,且每个PLM的分类性能都比原始版本提升了0.0到2.0。
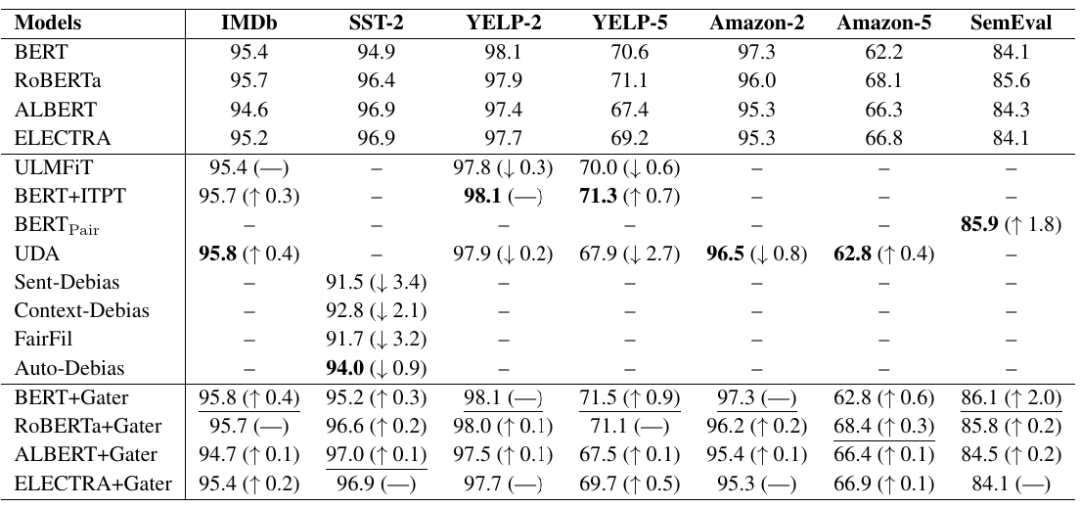 表1 分类性能
表1 分类性能
本文使用NLTK版本的词性标记工具从每个数据集中随机选择400个命名实体,然后通过情感转移测试计算这些命名实体的情感得分。得分越高,情感偏差越严重。图2反映了这些实体在使用Gater前后的情感偏差变化。对于每个数据集,Gater将情感偏差保持在较低的水平,即这些命名实体的情感得分接近于0。相比之下,在不使用Gater的情况下,这些命名实体具有较高的情感得分。这说明Gater有效地减少了情感偏差。
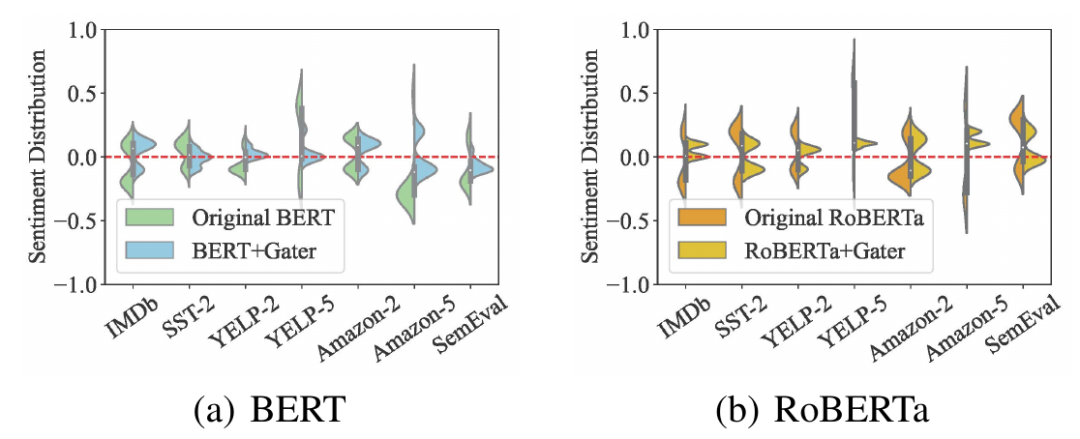
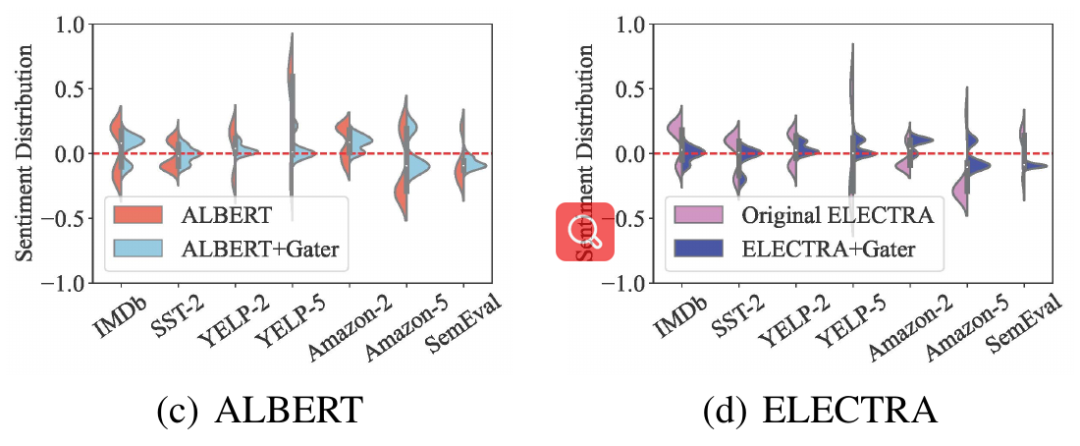
图2 情感去偏
总结
本文提出了一种基于自适应Gumbel攻击的情感分类器Gater,从对抗攻击的角度缓解了PLMs中的命名实体情感偏差。现实世界中的命名实体是复杂和多样的,它们的特征和属性会随着时间和不同的环境而变化。随着PLMs在现实场景中的广泛应用,Gater可以快速调整PLMs对命名实体的情感倾向性,从而有效地提高情感分类系统的鲁棒性。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。