什么是分区表
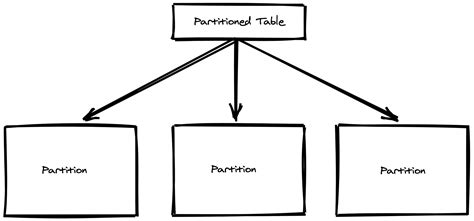
数据库分区表将表数据分成更小的物理分片,以此提高性能、可用性、易管理性。分区表是关系型数据库中比较常见的对大表的优化方式,数据库管理系统一般都提供了分区管理,而业务可以直接访问分区表而不需要调整业务架构,当然好的性能需要合理的分区访问方式。
分区表是数据库中常见的技术,而PostgreSQL中的分区表有许多专有的特性,比如分区表实现方案多、分区为普通表、分区维护方案、SQL优化还有一些分区表的问题。
分区表的实现
PostgreSQL数据库有各式各样的分区实现方式。官方支持的有声明式分区和继承式分区,而三方插件包括pathman、partman等等。在官方声明式分区实现后,基本只推荐一种分区方式:声明式分区。由于再拓展不同实现的分区表的功能、细节、历史等差别会使篇幅过长,且未来意义不大,本篇主要讨论的是声明式分区,其他方式实现的分区功能只会简单介绍。但是由于历史存量和一些功能差异,了解声明分区、继承分区、pathman还是有必要的。
声明分区表
声明分区也叫原生分区,从PG10版本开始支持,相当于“官方支持”的分区表,也是最为推荐的分区方式。虽然与继承分区不一样,但是其内部也是用继承表实现的。声明分区只支持3种分区方式:range分区、list分区、hash分区
range分区
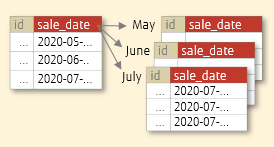
range分区表以范围进行分区,分区边界为[t1,t2)
CREATE TABLE PUBLIC.LZLPARTITION1
(id int,name varchar(50) NULL, DATE_CREATED timestamp NOT NULL DEFAULT now()
) PARTITION BY RANGE(DATE_CREATED);
alter table public.lzlpartition1 add primary key(id,DATE_CREATED)
create table LZLPARTITION1_202301 partition of LZLPARTITION1 for values from ('2023-01-01 00:00:00') to ('2023-02-01 00:00:00');create table LZLPARTITION1_202302 partition of LZLPARTITION1 for values from ('2023-02-01 00:00:00') to ('2023-03-01 00:00:00');
--往分区表添加一些数据
=> INSERT INTO lzlpartition1 SELECT random() * 10000, md5(g::text),g
FROM generate_series('2023-01-01'::date, '2023-02-28'::date, '1 minute') as g;
INSERT 0 83521
range分区的from t1 to t2,为[t1,t2)范围,下边界包含上边界不包含。
查看分区表,每个分区也是单独的表
lzldb=> \d+ lzlpartition1Partitioned table "public.lzlpartition1"Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
--------------+-----------------------------+-----------+----------+---------+----------+-------------+--------------+-------------id | integer | | not null | | plain | | | name | character varying(50) | | | | extended | | | date_created | timestamp without time zone | | not null | now() | plain | | |
Partition key: RANGE (date_created)
Indexes:"lzlpartition1_pkey" PRIMARY KEY, btree (id, date_created)
Partitions: lzlpartition1_202301 FOR VALUES FROM ('2023-01-01 00:00:00') TO ('2023-02-01 00:00:00'),lzlpartition1_202302 FOR VALUES FROM ('2023-02-01 00:00:00') TO ('2023-03-01 00:00:00')
lzldb=> \d+ lzlpartition1_202301Table "public.lzlpartition1_202301"Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
--------------+-----------------------------+-----------+----------+---------+----------+-------------+--------------+-------------id | integer | | not null | | plain | | | name | character varying(50) | | | | extended | | | date_created | timestamp without time zone | | not null | now() | plain | | |
Partition of: lzlpartition1 FOR VALUES FROM ('2023-01-01 00:00:00') TO ('2023-02-01 00:00:00')
Partition constraint: ((date_created IS NOT NULL) AND (date_created >= '2023-01-01 00:00:00'::timestamp without time zone) AND (date_created < '2023-02-01 00:00:00'::timestamp without time zone))
Indexes:"lzlpartition1_202301_pkey" PRIMARY KEY, btree (id, date_created)
Access method: heap
分区上的主键、索引、字段null/CHECK约束自动创建。由于分区也是独立的表,约束和索引也可以单独在分区上创建。(attach则不会自动创建这些,详见attach一节)
list分区
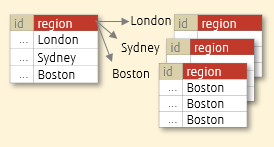
list分区以指定的分区值将数据存放到对应的分区上
CREATE TABLE cities (city_id bigserial not null,name text,population bigint
) PARTITION BY LIST (left(lower(name), 1));
CREATE TABLE cities_abPARTITION OF cities FOR VALUES IN ('a', 'b');
CREATE TABLE cities_nullPARTITION OF cities (CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN (null);
insert into cities(name,population) values('Acity',10);
insert into cities(name,population) values(null,20);
=> SELECT tableoid::regclass,* FROM cities;tableoid | city_id | name | population
-------------+---------+--------+------------cities_ab | 1 | Acity | 10cities_null | 2 | [null] | 20
list分区表可以创建null分区
hash分区
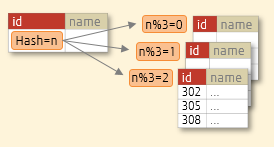
hash分区将数据散列存储在各个分区上,以打散热点数据
CREATE TABLE orders (order_id int,name varchar(10)) PARTITION BY HASH (order_id);
CREATE TABLE orders_p1 PARTITION OF ordersFOR VALUES WITH (MODULUS 3, REMAINDER 0);
CREATE TABLE orders_p2 PARTITION OF ordersFOR VALUES WITH (MODULUS 3, REMAINDER 1);
CREATE TABLE orders_p3 PARTITION OF ordersFOR VALUES WITH (MODULUS 3, REMAINDER 2);
不能创建默认分区,也不能创建超过MODULUS的分区
=> CREATE TABLE orders_p2 PARTITION OF orders
-> FOR VALUES WITH (MODULUS 3, REMAINDER 4);
ERROR: 42P16: remainder for hash partition must be less than modulus
LOCATION: transformPartitionBound, parse_utilcmd.c:3939=> CREATE TABLE orders_p4 PARTITION OF orders default;
ERROR: 42P16: a hash-partitioned table may not have a default partition
LOCATION: transformPartitionBound, parse_utilcmd.c:3909
插入数据
=>insert into orders values(generate_series(1,10000),'a');
INSERT 0 10000
=>SELECT tableoid::regclass,count(*) FROM orders group by tableoid::regclass;tableoid | count
-----------+-------orders_p1 | 3277orders_p3 | 3354orders_p2 | 3369=>select tableoid::regclass,* from orders limit 30;tableoid | order_id | name
-----------+----------+------orders_p1 | 2 | aorders_p1 | 4 | aorders_p1 | 6 | aorders_p1 | 8 | aorders_p1 | 15 | aorders_p1 | 16 | aorders_p1 | 18 | aorders_p1 | 19 | aorders_p1 | 20 | a
hash分区数据散列分布
--插入100条null数据
=> insert into orders values(null,generate_series(1,100)::text);
INSERT 0 100
=> SELECT tableoid::regclass,count(*) FROM orders where order_id is null group by tableoid::regclass;tableoid | count
-----------+-------orders_p1 | 100
--null数据全部都放在了remainder 0的分区上
=>\d+ orders_p1Table "public.orders_p1"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+-----------------------+-----------+----------+---------+----------+--------------+-------------order_id | integer | | | | plain | | name | character varying(10) | | | | extended | |
Partition of: orders FOR VALUES WITH (modulus 3, remainder 0)
Partition constraint: satisfies_hash_partition('412053'::oid, 3, 0, order_id)
hash分区表虽然没有null分区的概念,但是可以存放null数据,null数据存放在remainder 0上。
混合分区
分区下面也可以建立分区构成级联模式,子分区可以有不同的分区方式,这样的分区成为混合分区。

创建一个混合分区:
create table part_1000(id bigserial not null,name varchar(10),createddate timestamp) partition by range(createddate);
create table part_2001 partition of part_1000 for values from ('2023-01-01 00:00:00') to ('2023-02-01 00:00:00') partition by list(name) ;
create table part_2002 partition of part_1000 for values from ('2023-02-01 00:00:00') to ('2023-03-01 00:00:00') partition by list(name) ;
create table part_2003 partition of part_1000 for values from ('2023-03-01 00:00:00') to ('2023-04-01 00:00:00') partition by list(name) ;
create table part_3001 partition of part_2001 FOR VALUES IN ('abc');
create table part_3002 partition of part_2001 FOR VALUES IN ('def');
create table part_3003 partition of part_2001 FOR VALUES IN ('jkl');
\d+只能看到下一级的分区
\d+ part_1000Partitioned table "dbmgr.part_1000"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
-------------+-----------------------------+-----------+----------+---------------------------------------+----------+--------------+-------------id | bigint | | not null | nextval('part_1000_id_seq'::regclass) | plain | | name | character varying(10) | | | | extended | | createddate | timestamp without time zone | | | | plain | |
Partition key: RANGE (createddate)
Partitions: part_2001 FOR VALUES FROM ('2023-01-01 00:00:00') TO ('2023-02-01 00:00:00'), PARTITIONED,part_2002 FOR VALUES FROM ('2023-02-01 00:00:00') TO ('2023-03-01 00:00:00'), PARTITIONED,part_2003 FOR VALUES FROM ('2023-03-01 00:00:00') TO ('2023-04-01 00:00:00'), PARTITIONED
=> \d+ part_2001Partitioned table "dbmgr.part_2001"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
-------------+-----------------------------+-----------+----------+---------------------------------------+----------+--------------+-------------id | bigint | | not null | nextval('part_1000_id_seq'::regclass) | plain | | name | character varying(10) | | | | extended | | createddate | timestamp without time zone | | | | plain | |
Partition of: part_1000 FOR VALUES FROM ('2023-01-01 00:00:00') TO ('2023-02-01 00:00:00')
Partition constraint: ((createddate IS NOT NULL) AND (createddate >= '2023-01-01 00:00:00'::timestamp without time zone) AND (createddate < '2023-02-01 00:00:00'::timestamp without time zone))
Partition key: LIST (name)
Partitions: part_3001 FOR VALUES IN ('abc'),part_3002 FOR VALUES IN ('def'),part_3003 FOR VALUES IN ('jkl')
此时插入一条数据
=> insert into part_1000 values(random() * 10000,'abc','2023-01-01 08:00:00');
INSERT 0 1
=> SELECT tableoid::regclass,* FROM part_1000;tableoid | id | name | createddate
-----------+------+------+---------------------part_3001 | 6385 | abc | 2023-01-01 08:00:00
数据存放在最底层的子分区中
声明分区特性小结
- 没有interval分区。没有自带的自动新增分区功能,对于维护来说比较麻烦
- 分区表的分区本身也是表,这个特性比较特殊。这不仅仅造成pg可以灵活的操作子分区,更重要的是功能和特性上的影响。
- truncate,vacuum,analyze分区表会执行所有分区。truncate only不能在父表上执行,但可以在存数据的子表上执行,仅清除这个子分区。
- range,hash分区的分区键可以有多个列,list分区的分区键只能是单个列或表达式。
- 分区父表本身是空的,最底层子分区可以存储数据
- default分区表会接收不在声明的范围中的数据;如果没有default分区,插入范围外的数据会直接报错
- 如果要新增分区,需要注意default分区中是否有这个新增分区的数据
- partition of创建的分区会自动创建分区表上的索引、约束、行级触发器
- attach不会处理任何索引、约束等等对象
继承分区表
继承分区也是官方支持的,它利用了PGSQL的继承表特性来实现分区表的功能。继承分区表会比声明分区表更灵活。
继承分区表的实现需要到了PGSQL中的2个功能:继承表和写入重定向。写入重定向可以通过rule或者trigger来实现。
创建继承分区表
创建继承分区表示例:
1.创建父表
CREATE TABLE measurement (city_id int not null,logdate date not null,peaktemp int,unitsales int
);
2.创建继承表,指定约束范围
CREATE TABLE measurement_202308 (CHECK ( logdate >= DATE '2023-08-01' AND logdate < DATE '2023-09-01' )
) INHERITS (measurement);
CREATE TABLE measurement_202309 (CHECK ( logdate >= DATE '2023-09-01' AND logdate < DATE '2023-10-01' )
) INHERITS (measurement);
3.创建规则或触发器,将插入数据重定向到对应的继承表中
CREATE OR REPLACE FUNCTION measurement_insert_trigger()
RETURNS TRIGGER AS $$
BEGINIF ( NEW.logdate >= DATE '2023-08-01' ANDNEW.logdate < DATE '2023-09-01' ) THENINSERT INTO measurement_202308 VALUES (NEW.*);ELSIF ( NEW.logdate >= DATE '2023-09-01' ANDNEW.logdate < DATE '2023-10-01' ) THENINSERT INTO measurement_202309 VALUES (NEW.*);ELSERAISE EXCEPTION 'Date out of range. Fix the measurement_insert_trigger() function!';END IF;RETURN NULL;
END;
$$
LANGUAGE plpgsql;
CREATE TRIGGER insert_measurement_triggerBEFORE INSERT ON measurementFOR EACH ROW EXECUTE FUNCTION measurement_insert_trigger();
一个最基本的继承分区表就创建好了。
=>\d+ measurementTable "public.measurement"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
-----------+---------+-----------+----------+---------+---------+--------------+-------------city_id | integer | | not null | | plain | | logdate | date | | not null | | plain | | peaktemp | integer | | | | plain | | unitsales | integer | | | | plain | |
Triggers:insert_measurement_trigger BEFORE INSERT ON measurement FOR EACH ROW EXECUTE FUNCTION measurement_insert_trigger()
Child tables: measurement_202308,measurement_202309
Access method: heap
测试一下插入和查询数据
--插入范围外的数据会报错
=> insert into measurement values(1001, now() - interval '31' day ,1,1);
ERROR: P0001: Date out of range. Fix the measurement_insert_trigger() function!
CONTEXT: PL/pgSQL function measurement_insert_trigger() line 10 at RAISE
LOCATION: exec_stmt_raise, pl_exec.c:3889
--插入数据会重定向到子表上
=> insert into measurement values(1001,now(),1,1);
INSERT 0 0
--查询父表会查到子表数据
=> select tableoid::regclass,* from measurement;tableoid | city_id | logdate | peaktemp | unitsales
--------------------+---------+------------+----------+-----------measurement_202308 | 1001 | 2023-08-03 | 1 | 1
RULE和trigger
除了触发器,PGSQL还可以用rule来重定向插入。
rule语句参考:
CREATE RULE measurement_insert_202308 AS
ON INSERT TO measurement WHERE( logdate >= DATE '2023-08-01' AND logdate < DATE '2023-08-01' )
DO INSTEADINSERT INTO measurement_202308 VALUES (NEW.*);
CREATE RULE measurement_insert_202309 AS
ON INSERT TO measurement WHERE( logdate >= DATE '2023-09-01' AND logdate < DATE '2023-09-01' )
DO INSTEADINSERT INTO measurement_202309 VALUES (NEW.*);
规则和触发器的差异:
- rule性能相较trigger更差,但在批量插入时,由于rule只有一次检查,性能会比trigger更好,但其他情况下trigger更好
- COPY不会触发rule,但会触发trigger。rule时可以将数据直接COPY到子表中
- 当插入范围外数据时,rule会将数据插入到父表中,trigger则会直接报错
索引
为了提升性能,还需要创建索引和开启constrain_exclusion。分区的索引一般都是必不可少,继承表的索引需要手动在子表上创建。
创建索引示例:
CREATE INDEX idx_measurement_202308_logdate ON measurement_202308 (logdate);
CREATE INDEX idx_measurement_202309_logdate ON measurement_202309 (logdate);
插入一些数据查看执行计划:
--'2023-08-04'只有1条数据,让其可以走到索引
=> insert into measurement values(1001,now()+interval '1' day,1,1);
INSERT 0 0insert into orders values(generate_series(1,10000),'a');
=> insert into measurement values(generate_series(1,1000),now(),1,1);
INSERT 0 0=> explain select * from measurement where logdate='2023-08-04';QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------Append (cost=0.00..5.17 rows=2 width=16)-> Seq Scan on measurement measurement_1 (cost=0.00..0.00 rows=1 width=16)Filter: (logdate = '2023-08-04'::date)-> Index Scan using idx_measurement_202308_logdate on measurement_202308 measurement_2 (cost=0.14..5.16 rows=1 width=16)Index Cond: (logdate = '2023-08-04'::date)
上面的执行计划8月的分区走到了分区上的索引。constraint_exclusion默认打开了继承表的约束排除,上面的查询排除了9月分区,只扫描了8月。然而由于父表没有约束(也加不了)所以父表一定在执行计划里面,但是父表一般都是空的所以影响不大。
constraint_exclusion
constraint_exclusion拥有控制优化器是否使用约束来减少非必要的访问表,该参数在继承分区表优化上常见,通过减少子表的访问,提升SQL的性能(该功能跟enable_partition_pruning参数类似,enable_partition_pruning用于控制声明式分区表的分区裁剪)。constraint_exclusion有3个值:
on:所有表都会检查约束
partition:继承表和UNION ALL子查询检查约束(默认值)
off:不会检查约束
约束排除只能发生在生成执行计划时,不会发生在真正执行时(分区裁剪是可以的)。这意味着当使用绑定变量、变量值时不会发生约束排除。
例如在使用now()等优化器不知道具体值的函数时,优化器无法排除根本不需要访问的分区:
=> select now();now
-------------------------------2023-08-03 17:12:04.772658+08
--优化器没有排除9月的分区
=> explain select * from measurement where logdate<=now();QUERY PLAN
-----------------------------------------------------------------------------------------------------Append (cost=0.00..55.98 rows=1628 width=16)-> Seq Scan on measurement measurement_1 (cost=0.00..0.00 rows=1 width=16)Filter: (logdate <= now())-> Seq Scan on measurement_202308 measurement_2 (cost=0.00..21.15 rows=1010 width=16)Filter: (logdate <= now())-> Bitmap Heap Scan on measurement_202309 measurement_3 (cost=7.44..26.69 rows=617 width=16)Recheck Cond: (logdate <= now())-> Bitmap Index Scan on idx_measurement_202309_logdate (cost=0.00..7.28 rows=617 width=0)Index Cond: (logdate <= now())
另外,约束排除本身需要检查所有子表的约束,如果子表约束过多生成执行计划的效率会受到影响,所以继承分区不建议创建过多的子分区。
添加/删除继承分区表的分区
将一个继承分区做成普通表
ALTER TABLE measurement_202308 NO INHERIT measurement;
将一个含有数据的普通表当成子表加入到继承分区表中
CREATE TABLE measurement_202310
(LIKE measurement INCLUDING DEFAULTS INCLUDING CONSTRAINTS);
ALTER TABLE measurement_202310 ADD CONSTRAINT measurement_202310_logdate_check
CHECK ( logdate >= DATE '2023-10-01' AND logdate < DATE '2023-11-01' );
--insert into measurement_202310 values(2001,'20231010',3,3);
ALTER TABLE measurement_202310 INHERIT measurement;
继承分区表特性小结
- 继承分区要比声明分区更灵活,但一些声明分区的特性也无法使用
- 子表会继承父表上的约束,所以如果不是全局约束不要在父表上设置
- 索引不会继承,索引只能在子表上一个个地创建
- 声明分区只能有range、list、hash分区,继承分区可以更多,也可以是自定义的分区方式。
- 删除一个子表不会导致触发器失效。PGSQL没有像ORACLE那样失效对象的概念(索引有失效的概念)
- 一般来说使用trigger的插入重定向比rule效率更好
- 新增分区时,如果触发器函数中没有该分区的规则,则需要更新触发器函数。
- 继承分区可以多重继承
- 约束排除不能在执行时进行排除,所以建议使用固定值进行查询
- 使用继承分区表时,同样不要创建太多的子分区
pg_pathman
pg_pathman是三方插件实现的分区表功能。github上的pathman readme和使用pg_pathman插件的文章对pathman描述和使用已经非常详细,这里仅摘几个重点汇总和做一些简单的测试。
pg_pathman基本知识
不再更新
NOTE: this project is not under development anymore
pg_pathman支持postgres9.5到15,PostgreSQL后续版本不会再支持,已有版本也只做BUG修复,不会再新增功能。
pg_pathman的出现是因为老版本的PostgreSQL分区表功能不完善,而现在原生分区表(也就是声明分区表)已非常成熟,pg_pathman也建议使用原生分区表,存量的pg_pathman分区表也建议转移到原生分区表。曾经被许多用户认可的pg_pathman成为历史,即使不再更新,它的功能也比目前的原生分区表更多。
特性介绍
pg_pathman功能相当强大,一些原生分区表不支持的功能pathman也支持。 pathman虽然强大但也不是完美的,在实际使用过程中问题也很多。pg_pathman特性中比较需要关注的点包括:
- pg_pathman可以通过分区管理函数管理分区。支持replace、merge、split分区操作;支持 attach、detach操作;支持interval分区
- pg_pathman对分区表执行计划做了很多优化
- pg_pathman仅支持range和hash两种分区类型
- pathman_config表存储分区表配置信息;提供分区任务视图
- 分区信息缓存在内存中,以生成执行计划
pg_pathman基本使用
创建pathman range分区
--普通表就是父表
CREATE TABLE journal (id SERIAL,dt TIMESTAMP NOT NULL,level INTEGER,msg TEXT);-- 子分区会自动创建父表上的索引
CREATE INDEX ON journal(dt);
--创建分区
select
create_range_partitions('journal'::regclass, 'dt','2023-01-01 00:00:00'::timestamp,interval '1 month', 6, false) ;
--查看表定义
=> \d+ journalTable "public.journal"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------------+-----------+----------+-------------------------------------+----------+--------------+-------------id | integer | | not null | nextval('journal_id_seq'::regclass) | plain | | dt | timestamp without time zone | | not null | | plain | | level | integer | | | | plain | | msg | text | | | | extended | |
Indexes:"journal_dt_idx" btree (dt)
Child tables: journal_1,journal_2,journal_3,journal_4,journal_5,journal_6
Access method: heap=> \d+ journal_6Table "public.journal_6"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------------+-----------+----------+-------------------------------------+----------+--------------+-------------id | integer | | not null | nextval('journal_id_seq'::regclass) | plain | | dt | timestamp without time zone | | not null | | plain | | level | integer | | | | plain | | msg | text | | | | extended | |
Indexes:"journal_6_dt_idx" btree (dt)
Check constraints:"pathman_journal_6_check" CHECK (dt >= '2023-06-01 00:00:00'::timestamp without time zone AND dt < '2023-07-01 00:00:00'::timestamp without time zone)
Inherits: journal
Access method: heap
--插入数据
INSERT INTO journal (dt, level, msg)
SELECT g, random() * 10000, md5(g::text)
FROM generate_series('2023-01-01'::date, '2023-02-28'::date, '1 hour') as g;
--插入还未创建对应分区的数据
=> INSERT INTO journal (dt, level, msg) values('2023-07-01'::date,'11','1');
INSERT 0 1
--查看分区数据分布,已成功创建interval分区
=> SELECT tableoid::regclass AS partition, count(*) FROM journal group by partition;partition | count
-----------+-------journal_7 | 1journal_2 | 649journal_1 | 744
--查看执行计划
--已发生分区裁剪
=> explain select * from journal where dt='2023-01-01 22:00:00';QUERY PLAN
-----------------------------------------------------------------------------------------------------Append (cost=0.00..5.30 rows=2 width=48)-> Seq Scan on journal journal_1 (cost=0.00..0.00 rows=1 width=48)Filter: (dt = '2023-01-01 22:00:00'::timestamp without time zone)-> Index Scan using journal_1_dt_idx on journal_1 journal_1_1 (cost=0.28..5.29 rows=1 width=49)Index Cond: (dt = '2023-01-01 22:00:00'::timestamp without time zone)
创建pathman hash分区
--创建主表
CREATE TABLE items (id SERIAL PRIMARY KEY,name TEXT,code BIGINT);
--创建hash分区
select create_hash_partitions('items'::regclass, 'id',3, false) ;
--插入数据
INSERT INTO items (id, name, code)
SELECT g, md5(g::text), random() * 100000
FROM generate_series(1, 1000) as g;
=> SELECT tableoid::regclass AS partition, count(*) FROM items group by partition;partition | count
-----------+-------items_2 | 344items_0 | 318items_1 | 338
=> \d+ itemsTable "public.items"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+-----------------------------------+----------+--------------+-------------id | integer | | not null | nextval('items_id_seq'::regclass) | plain | | name | text | | | | extended | | code | bigint | | | | plain | |
Indexes:"items_pkey" PRIMARY KEY, btree (id)
Child tables: items_0,items_1,items_2
Access method: heap=> \d+ items_1Table "public.items_1"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+-----------------------------------+----------+--------------+-------------id | integer | | not null | nextval('items_id_seq'::regclass) | plain | | name | text | | | | extended | | code | bigint | | | | plain | |
Indexes:"items_1_pkey" PRIMARY KEY, btree (id)
Check constraints:"pathman_items_1_check" CHECK (get_hash_part_idx(hashint4(id), 3) = 1)
Inherits: items
Access method: heap
=> SELECT tableoid::regclass AS partition, count(*) FROM items group by partition;partition | count
-----------+-------items_2 | 344items_0 | 318items_1 | 338
pg分区表的优劣
分区表的优势
- SQL性能提升。在某些场景下,比如把大量的数据分成多个分区,而SQL只需要查那一个分区的数据时,SQL性能可能会极大的提升
- 分区可以和索引配合使用。比如访问一个分区上的一个索引要比访问一个未分区的大索引要更高效。
- 删除一个分区比删除多行数据更高效。这在时间范围分区中很常见,删除一个用不到的历史分区是非常快的,但是如果没有分区,delete删除数据不仅慢还需要额外的维护操作
- vacuum更快。一个大表在回收旧版本信息或收集统计信息时会非常慢,在vacuum还没执行完的时候可能SQL已经存在问题了。如果有分区的话,vacuum会快很多。
- IO分散能力。不同的分区可以放在不同的路径、不同的磁盘上。极少使用数据可以放在便宜的磁盘上。
- 更多的维护技巧。直接维护一个大表是非常困难的,比如一个极大的表做vacuum时就有很多问题,而分区表的各个分区可以单独运行vacuum。不仅如此,attach/detach、本地索引/约束等可以在很多场景中灵活使用。
分区表的劣势
- 在pgsql中,每个分区表的分区都可以当成普通表来对待。分区表过多会导致SQL解析时间较长和更多的内存负载,甚至报错。参考之前的文章较少的分区也报错too many range table entries
- 即使分区过多没有报错,且在生成执行计划的时候没有做分区剪裁(执行的时候有可能做),那么explain出来的执行计划会非常多,此时日志中也会打印长长的执行计划影响日志阅读。
- 一些奇怪的问题:不同用户查看到不同的执行计划
分区表的限制
-
没有原生的自动创建分区功能
-
只支持分区索引,不支持全局索引
-
主键必须包含分区键。postgresql目前只能在各自的分区内判断唯一性,所以有这个限制。oracle和mysql都没有这种限制。
-
唯一索引必须包含分区键。postgresql目前只能在各自的分区内判断唯一性。同理主键
-
无法创建定义在全局的约束
-
INSERT的BEFORE ROW触发器不能更新insert的那个分区
-
临时表分区和普通表分区不能在同一分区表下。
-
声明式分区的父表子表的列必须一致;继承式分区的子表可以比父表的列更多。
-
声明式分区CHECK和NOT NULL约束总是继承的,不能单独设置分区的这两种约束
-
range 不能存储NULL值;hash分区没有null分区的概念,但可以存储null值,null值存放在remainder 0分区上;list分区可以显示创建null分区存放null数据
什么时候该使用分区表?
首先使用分区表必须要了解分区表所带来的优劣势和使用限制,比如数据量很大的时候分区可以带来性能提升,冷热数据分离也更好管理分区数据等等。应该结合本身业务情况、硬件资源选择是否分区和如何分区。但是总会有开发人员会问到底多少数据量该分区等等的问题,使用分区表的建议只能给出一个笼统的回答,如果你不知道怎么分区,可以参考以下建议(如果足够了解表分区,请忽略):
- 表数据够大,而表上的sql总是或可以是带有分区键字段的时候
- 冷热数据分离明显。比如新数据都在新的当月分区插入,老的11个月分区都是只读数据的情况
- vaccum已经跑不过来了
分区表的权限
权限问题是分区表知识点中讨论的比较少的,但是它仍然值得关注。
由于PostgreSQL数据库有“分区子表也是普通表”这样的概念,这与其他几个常见的数据库(Oracle、mysql)是不同的。比如在oracle中不需要关心分区子表的权限,但是在pg中却需要关注权限问题。
partition of/attach不会将主表的权限继承给子表
--把分区去表的select授权给一个普通用户
=> grant select on lzlpartition1 to userlzl;
GRANT--查看权限,只有主表有授权,存量分区子表不会自动授权
=> select grantee,table_schema,table_name,privilege_type from information_schema.table_privileges where grantee='userlzl';grantee | table_schema | table_name | privilege_type
---------+--------------+---------------+----------------userlzl | public | lzlpartition1 | SELECT--partition of方式创建一个分区=> create table LZLPARTITION1_202303 partition of LZLPARTITION1 for values from ('2023-03-01 00:00:00') to ('2023-04-01 00:00:00');
CREATE TABLE--attach方式创建一个分区
=> CREATE TABLE lzlpartition1_202304
-> (LIKE lzlpartition1 INCLUDING DEFAULTS INCLUDING CONSTRAINTS);
CREATE TABLE
=> alter table lzlpartition1 attach partition lzlpartition1_202304 for values from ('2023-04-01 00:00:00') to ('2023-05-01 00:00:00');
ALTER TABLE--再次查看权限,新增的子分区不会自动授权给其他用户(但是新增子分区权限会自动授权给owner)
=> select grantee,table_schema,table_name,privilege_type from information_schema.table_privileges where grantee='userlzl';grantee | table_schema | table_name | privilege_type
---------+--------------+---------------+----------------userlzl | public | lzlpartition1 | SELECT
目前来看userlzl 这个用户对所有子表都没有访问权限,但是有主表的权限
此时userlzl可以通过主表访问分区数据,但不能通过直接访问子表访问数据
=> \c - userlzl;
You are now connected to database "dbmgr" as user "userlzl".
=> select * from LZLPARTITION1 where date_created='2023-01-02 10:00:00';id | name | date_created
------+----------------------------------+---------------------2159 | d05d716da126ff4b44d934344cc4dd7a | 2023-01-02 10:00:00=> select * from LZLPARTITION1_202301 where date_created='2023-01-02 10:00:00';
ERROR: 42501: permission denied for table lzlpartition1_202301
LOCATION: aclcheck_error, aclchk.c:3466
因为attach/detach不会处理权限,此时如果我们把分区detach出来,这个分区同样不能被userlzl访问
=> alter table lzlpartition1 detach partition lzlpartition1_202303;
ALTER TABLE
=> \dp+ lzlpartition1_202303;Access privilegesSchema | Name | Type | Access privileges | Column privileges | Policies
--------+----------------------+-------+-------------------+-------------------+----------dbmgr | lzlpartition1_202303 | table | | |
=> select * from LZLPARTITION1_202301 where date_created='2023-01-02 10:00:00';
ERROR: 42501: permission denied for table lzlpartition1_202301
由此可知
- 分区子表和主表PostgreSQL在数据库中都是以普通表的形式存在,他们都有各自的权限体系
- 如果没有子表权限而主表有权限同样可以访问子表数据
- partition of、attach/detach都不会处理权限问题
但是,分区表权限并不是仅仅控制是否能够访问,没有分区子表权限可能导致执行计划异常,参考文章:不同用户查看到不同的执行计划
这个问题是一个偶发现象,导致超级用户和一般用户看到的sql执行计划不一致,实际上业务SQL执行计划异常却看不出来,比较难定位。分区子表有各自的统计信息,子表权限与父表不一致(即便是partition of创建的分区),导致用户可以通过主表访问子表的数据,却不能查看子表的统计信息。权限问题导致了执行计划产生差异。
这与“权限只控制是否能访问表,不控制如何访问表”的一般概念是违背的,所以需要注意这个权限问题。
为了提供子表统计信息权限,建议显示对用户授权所有子表查询权限,就可以避免以上问题
grant select on table_partition_allname to username;
分区表的维护
分区表ATTACH/DETACH基本操作
attach/detach可以将一个已存在的表作为分区添加/分离分区表。attach/detach在维护工作中很有用。
先来看看"create table…partition of"方式添加分区和"drop table"删除分区的锁情况
锁矩阵:https://www.postgresql.org/docs/current/explicit-locking.html
申请的锁:https://postgres-locks.husseinnasser.com
- partition of新增分区
--session1 开启一个事务,只读数据
=> select * from lzlpartition1 where date_created='2023-01-01 00:00:00';id | name | date_created
------+----------------------------------+---------------------8249 | 256ac66bb53d31bc6124294238d6410c | 2023-01-01 00:00:00--session3 查看锁情况。读取一个分区数据时,要在子分区和主表上同时获得锁
=> select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+----------------------+------------+---------------+--------+-----------------+---------relation | dbmgr | lzlpartition1_202301 | [null] | [null] | 311449 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 311449 | AccessShareLock | t--session2 partition of方式添加分区
=> create table LZLPARTITION1_202305 partition of LZLPARTITION1 for values from ('2023-05-01 00:00:00') to ('2023-06-01 00:00:00');
--等待--session3 再次查看锁
=> select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+----------------------+------------+---------------+--------+---------------------+---------relation | dbmgr | lzlpartition1_202301 | [null] | [null] | 311449 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 311449 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 308525 | AccessExclusiveLock | f --此为partition of会话--session4 再随便来一个查询
=> select * from lzlpartition1 where date_created='2023-01-01 00:00:00';
--等待--session4再次查看锁
=> select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+----------------------+------------+---------------+--------+---------------------+---------relation | dbmgr | lzlpartition1_202301 | [null] | [null] | 311449 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 311449 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 308525 | AccessExclusiveLock | frelation | dbmgr | lzlpartition1 | [null] | [null] | 84774 | AccessShareLock | f --查询阻塞
partition of方式新增分区时,会申请主表的 AccessExclusiveLock,等待主表一切事务的同时也会阻塞主表的一切事务。
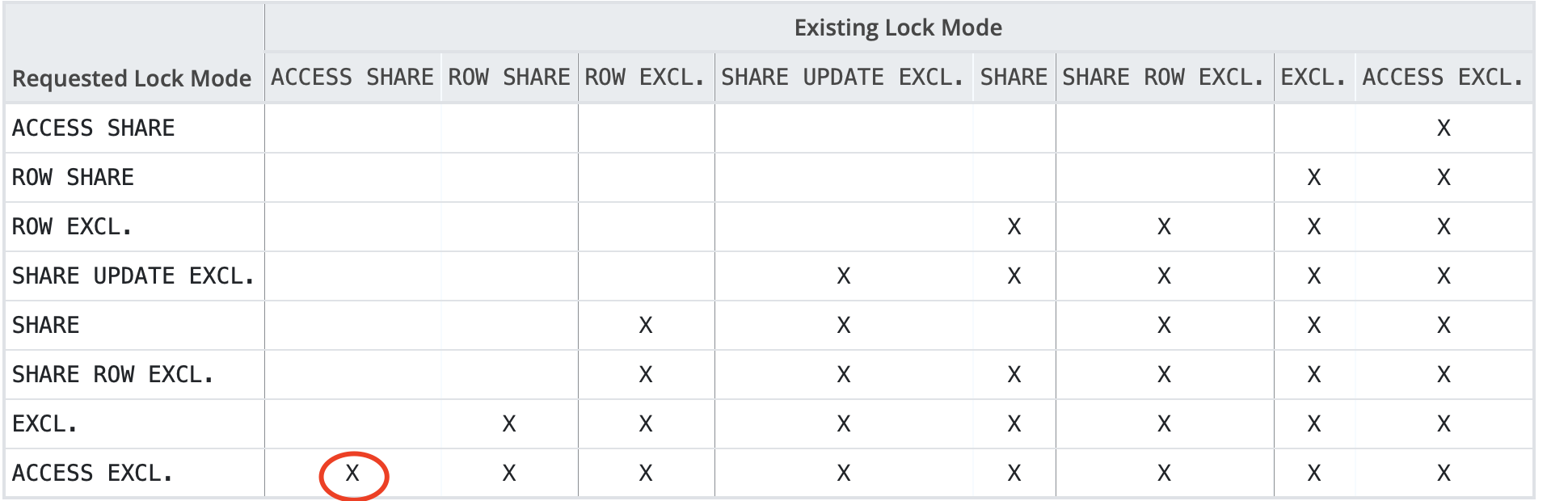
虽然partition of语句本身执行很快,但是如果遇到主表上有长事务,那么分区表上的所有操作都会长时间停滞。如果没有停机窗口,直接使用partition of方式新增分区是不推荐的。
- drop table删除分区
--session1 再次开启只读事务
--session2 删除分区表的子分区
=> drop table lzlpartition1_202305;
--等待--session3 查看锁情况
=>
select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+----------------------+------------+---------------+--------+---------------------+---------relation | dbmgr | lzlpartition1_202301 | [null] | [null] | 311449 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 311449 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 308525 | AccessExclusiveLock | f
drop table删除子分区时,会申请主表上的AccessExclusiveLock,等待一切和阻塞一切。同样的在生产环境需要谨慎使用。
- attach添加分区
attach将一个已存在的普通表附加到分区表上
虽然attach跟partition of都可以添加分区,但是需要注意ATTACH不会自动创建索引、约束、默认值、行级触发器,这点跟partition of是不同的。
先创建一个表
--减少繁琐的ddl,like方式创建表
CREATE TABLE lzlpartition1_202305(LIKE lzlpartition1 INCLUDING DEFAULTS INCLUDING CONSTRAINTS);
再观察attach的是否被阻塞
--session1 开启读写事务
=>begin;
BEGIN
=> insert into lzlpartition1 values('1234','abcd','2023-01-01 01:00:00');
INSERT 0 1
--session3 查看锁情况
=>
select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+----------------------+------------+---------------+--------+------------------+---------relation | dbmgr | lzlpartition1_202301 | [null] | [null] | 311449 | RowExclusiveLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 311449 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 311449 | RowExclusiveLock | t
--dml语句会获得分区主表和对应分区子表的RowExclusiveLock--session2 attach新建的表到分区主表上
=> alter table lzlpartition1 attach partition lzlpartition1_202305 for values from ('2023-05-01 00:00:00') to ('2023-06-01 00:00:00');
ALTER TABLE
attach只会申请SHARE UPDATE EXCLUSIVE锁,比ACCESS EXCLUSIVE低很多。
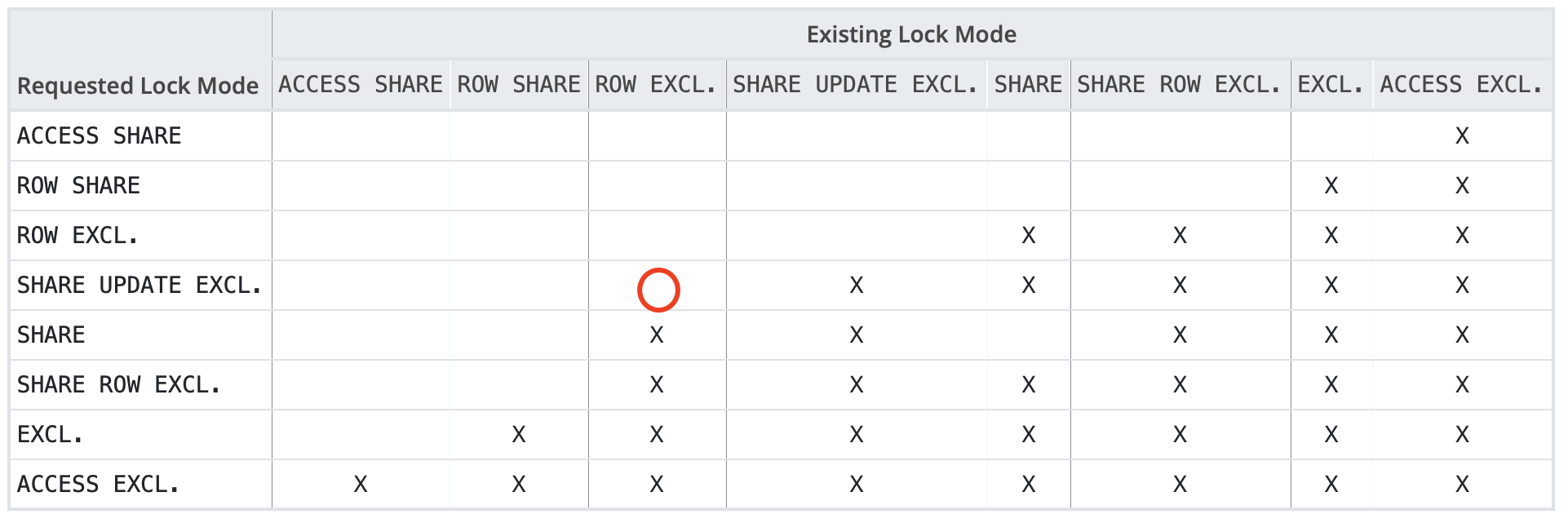
attach与读写都互不阻塞,所以推荐以attach方式添加分区,不影响业务,可在线执行。
- detach删除分区
detach将一个分区脱离分区表,成为一个普通表
--session1 保持dml事务不提交
--session2 detach一个分区alter table lzlpartition1 detach partition lzlpartition1_202305;--等待--session3 查看锁情况=> select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+----------------------+------------+---------------+--------+---------------------+---------relation | dbmgr | lzlpartition1_202301 | [null] | [null] | 311449 | RowExclusiveLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 311449 | RowExclusiveLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 308525 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 308525 | AccessExclusiveLock | fdetach跟attach不同,detach申请了主表的AccessExclusiveLock,等待一切和阻塞一切。
-
detach concurrently
PostgreSQL 14开始,detach新增了两种语法CONCURRENTLY 和FINALIZE
ALTER TABLE [ IF EXISTS ]
name
DETACH PARTITIONpartition_name[ CONCURRENTLY | FINALIZE ]
detach concurrently内部会开启两次事务,第一次事务会在主表和子表上都申请SHARE UPDATE EXCLUSIVE锁,分区会标记为正在detach的状态,此时会等待分区表上的所有事务提交。一旦这些事务全部都提交了,第二次事务会申请主表上的 SHARE UPDATE EXCLUSIVE锁和那个子表上ACCESS EXCLUSIVE锁,随后detach concurrently完成。
另外,detach concurrently后的子分区,会保留约束,由分区约束转化为check约束保留在detach后的表上
DETACH CONCURRENTLY的限制:
- DETACH CONCURRENTLY不能放在事务块中
- 分区表不能有default分区
concurrently的阻塞情况:
--session1
lzldb=> begin;
BEGIN
lzldb=*> insert into lzlpartition1 values('1234','abcd','2023-01-01 01:00:00');
INSERT 0 1--session2 detach concurrently
lzldb=> alter table lzlpartition1 detach partition lzlpartition1_202301 concurrently;
--等待--session3 查看锁3691 | insert into lzlpartition1 values('1234','abcd','2023-01-01 01:00:00'); | Client | ClientRead3940 | alter table lzlpartition1 detach partition lzlpartition1_202301 concurrently; | Lock | virtualxid3947 | select pid,query,wait_event_type,wait_event from pg_stat_activity; | |
--detach会话是3940,非常奇怪,detach的等待事件是virtualxid,等待事件类型是Lock--查看锁的情况
lzldb=> select locktype,database,relation,virtualtransaction,pid,mode,granted from pg_locks where pid in (3691,3940);locktype | database | relation | virtualtransaction | pid | mode | granted
---------------+----------+----------+--------------------+------+------------------+---------virtualxid | | | 6/9 | 3940 | ExclusiveLock | trelation | 16387 | 40969 | 5/179 | 3691 | RowExclusiveLock | trelation | 16387 | 40963 | 5/179 | 3691 | RowExclusiveLock | tvirtualxid | | | 5/179 | 3691 | ExclusiveLock | tvirtualxid | | | 6/9 | 3940 | ShareLock | ftransactionid | | | 5/179 | 3691 | ExclusiveLock | t
--此时的detach还没有等待表上的锁,而是在等待virtualxid的ShareLock--session4 做个插入
lzldb=> insert into lzlpartition1 values('12345','abcd','2023-01-01 01:00:00');
ERROR: no partition of relation "lzlpartition1" found for row
DETAIL: Partition key of the failing row contains (date_created) = (2023-01-01 01:00:00).
lzldb=> insert into lzlpartition1 values('12345','abcd','2023-02-01 01:00:00');
INSERT 0 1
--此时detach的分区已经不能插入,其他分区可以插入
--如果通过分区插入会怎样呢?可以正常插入
lzldb=> insert into lzlpartition1_202301 values('12345','abcd','2023-01-01 01:00:00');
INSERT 0 1
--注意此时它还是个分区表的分区,还不是一个普通表,不过它已经被标记为不可用了--\d+查看分区处于DETACH PENDING状态
Partitions: lzlpartition1_202301 FOR VALUES FROM ('2023-01-01 00:00:00') TO ('2023-02-01 00:00:00') (DETACH PENDING),lzlpartition1_202302 FOR VALUES FROM ('2023-02-01 00:00:00') TO ('2023-03-01 00:00:00')--把insert的session1提交/回滚
lzldb=> rollback;
ROLLBACK--session2立即完成
lzldb=> alter table lzlpartition1 detach partition lzlpartition1_202301 concurrently;
ALTER TABLEFINALIZE:
--session1
lzldb=> begin;
BEGIN
lzldb=*> insert into lzlpartition1 values('1234','abcd','2023-01-01 01:00:00');
INSERT 0 1--session2 detach concurrently,手动cancel
lzldb=> alter table lzlpartition1 detach partition lzlpartition1_202301 concurrently;
^CCancel request sent
ERROR: canceling statement due to user request--\d+查看分区表,分区处于DETACH PENDING状态
Partitions: lzlpartition1_202301 FOR VALUES FROM ('2023-01-01 00:00:00') TO ('2023-02-01 00:00:00') (DETACH PENDING),lzlpartition1_202302 FOR VALUES FROM ('2023-02-01 00:00:00') TO ('2023-03-01 00:00:00')--DETACH PENDING的分区,SQL已经不会去访问了
lzldb=> explain select * from lzlpartition1;QUERY PLAN
-----------------------------------------------------------------------------------------Seq Scan on lzlpartition1_202302 lzlpartition1 (cost=0.00..752.81 rows=38881 width=45)--finalize使之完成
lzldb=> alter table lzlpartition1 detach partition lzlpartition1_202301 finalize;
--等待--查看锁情况
lzldb=> select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';lzldb-# locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+----------------------+------------+---------------+------+--------------------------+---------relation | lzldb | lzlpartition1 | | | 3691 | RowExclusiveLock | trelation | lzldb | lzlpartition1_202301 | | | 3940 | AccessExclusiveLock | frelation | lzldb | lzlpartition1 | | | 3940 | ShareUpdateExclusiveLock | trelation | lzldb | lzlpartition1_202301 | | | 3691 | RowExclusiveLock | t
--3940,finalize申请了分区主表的ShareUpdateExclusiveLock和子表的AccessExclusiveLock
--由于是插入的是数据的分区刚好是detach的分区,所以发生等待--session1结束
lzldb=!> rollback;
ROLLBACK
--session2立即完成
lzldb=> alter table lzlpartition1 detach partition lzlpartition1_202301 finalize;
ALTER TABLE虽然detach的分区会申请8级锁,但是一般业务也没有直接通过子分区写数据的,所以只需要关注分区表的长事务尽快完成就行,一般不需要担心造成该分区子表上的后续阻塞。
在线detach小结:
- detach concurrently的阻塞情况跟CIC有点类似,不会阻塞其他事务,但是其本身会等待已有的事务完成,这点在lock上不太容易看出来
- 在detach concurrently期间分区会处于DETACH PENDING中间状态,该状态有点类似invisible,sql不会找到这个分区
- 如果是长事务导致的DETACH PENDING,应及时结束长事务;如果是中断导致的DETACH PENDING,可以使用FINALIZE使其完成detach。
利用约束减少attach时间
- 分区数据情况,准备操作一个较大分区的attach操作
=> SELECT tableoid::regclass AS partition, count(*) FROM lzlpartition1 group by partition;partition | count
----------------------+---------lzlpartition1_202301 | 2592001lzlpartition1_202302 | 38881
注意这个202301的分区有一个partition constraint
=> \d+ lzlpartition1_202301Table "public.lzlpartition1_202301"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------------+-----------------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | not null | | plain | |
name | character varying(50) | | | | extended | |
date_created | timestamp without time zone | | not null | now() | plain | |
Partition of: lzlpartition1 FOR VALUES FROM ('2023-01-01 00:00:00') TO ('2023-02-01 00:00:00')
Partition constraint: ((date_created IS NOT NULL) AND (date_created >= '2023-01-01 00:00:00'::timestamp without time zone) AND (date_created < '2023-02-01 00:00:00'::timestamp without t
Indexes:"lzlpartition1_202301_pkey" PRIMARY KEY, btree (id, date_created)
Access method: heap
- detach分区
alter table lzlpartition1 detach partition lzlpartition1_202301;
--detach后,partition constraint就没有了
=> \d+ lzlpartition1_202301Table "public.lzlpartition1_202301"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------------+-----------------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | not null | | plain | |
name | character varying(50) | | | | extended | |
date_created | timestamp without time zone | | not null | now() | plain | |
Indexes:"lzlpartition1_202301_pkey" PRIMARY KEY, btree (id, date_created)
Access method: heap
- 不添加check约束,attach
=> alter table lzlpartition1 attach partition lzlpartition1_202301 for values from ('2023-01-01 00:00:00') to ('2023-02-01 00:00:00');
ALTER TABLE
Time: 343.498 ms
由于要扫描分区数据是否满足分区范围,attach耗时300+ms
- 添加check约束,attach
=> alter table lzlpartition1 detach partition lzlpartition1_202301;
=> alter table lzlpartition1_202301 add constraint chk_202301 CHECK
-> ((date_created IS NOT NULL) AND (date_created >= '2023-01-01 00:00:00'::timestamp without time zone) AND (date_created < '2023-02-01 00:00:00'::timestamp without time zone));
ALTER TABLE
Time: 355.458 ms
上面添加check约束的耗时跟没有check时的attach操作耗时差不多,因为添加check约束同样也要扫描检查所有数据。
check约束添加完后再attach,此时的attach操作非常快就能完成
=> alter table lzlpartition1 attach partition lzlpartition1_202301 for values from ('2023-01-01 00:00:00') to ('2023-02-01 00:00:00');
ALTER TABLE
Time: 1.480 ms
- 删除check约束
=> \d+ lzlpartition1_202301;Table "public.lzlpartition1_202301"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------------+-----------------------------+-----------+----------+---------+----------+--------------+-------------id | integer | | not null | | plain | | name | character varying(50) | | | | extended | | date_created | timestamp without time zone | | not null | now() | plain | |
Partition of: lzlpartition1 FOR VALUES FROM ('2023-01-01 00:00:00') TO ('2023-02-01 00:00:00')
Partition constraint: ((date_created IS NOT NULL) AND (date_created >= '2023-01-01 00:00:00'::timestamp without time zone) AND (date_created < '2023-02-01 00:00:00'::timestamp without t
Indexes:"lzlpartition1_202301_pkey" PRIMARY KEY, btree (id, date_created)
Check constraints:"chk_202301" CHECK (date_created IS NOT NULL AND date_created >= '2023-01-01 00:00:00'::timestamp without time zone AND date_created < '2023-02-01 00:00:00'::timestamp without time
Access method: heap
注意,check constraint和partition constraint是不一样的概念,虽然他俩的约束内容可以是一致的。attach使用了check约束但是不会进行合并,可以显式删除这个多余的check。
=> alter table lzlpartition1_202301 drop constraint chk_202301;
ALTER TABLE
另外,需要关注drop constraint申请了当前子分区上AccessExclusiveLock,这是最高级别的锁,会阻塞任何操作。所以当前子分区上有事务,谨慎执行drop constraint。
=> select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+----------------------+------------+---------------+--------+---------------------+---------relation | dbmgr | lzlpartition1 | [null] | [null] | 448243 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 448243 | RowExclusiveLock | trelation | dbmgr | lzlpartition1_202301 | [null] | [null] | 444399 | AccessShareLock | trelation | dbmgr | lzlpartition1_202301 | [null] | [null] | 444399 | AccessExclusiveLock | f --这个就是drop constraint会话relation | dbmgr | lzlpartition1_202301 | [null] | [null] | 448243 | RowExclusiveLock | t
so,
在attach分区时,先添加check约束是比较有用,它可以减少attach的执行时间,数据检查在attach前完成就可以了
分区表新增分区的正确姿势
我们现在知道,attach可以在线执行,而partition of/drop table/detach都会申请等待和阻塞一切的AccessExclusiveLock
so,
建议用attach新建分区。partition of/detach都会等待和阻塞一切事务,而attach不会被只读/DML事务阻塞
所以添加分区应该使用attach,并提前创建check约束,删除约束时需要关注长事务问题。
分区表添加分区的正确姿势:
--减少繁琐的ddl,like方式创建表
CREATE TABLE lzlpartition1_202303(LIKE lzlpartition1 INCLUDING DEFAULTS INCLUDING CONSTRAINTS);
--参考其他分区的Partition constraint,添加表的check约束,减少attach检查约束的时间
alter table lzlpartition1_202303 add constraint chk_202303 CHECK ((date_created IS NOT NULL) AND (date_created >= '2023-03-01 00:00:00'::timestamp without time zone) AND (date_created < '2023-04-01 00:00:00'::timestamp without time zone));
--attach方式添加分区
alter table LZLPARTITION1 attach partition LZLPARTITION1_202303 for values from ('2023-03-01 00:00:00') to ('2023-04-01 00:00:00');
--可选。在新分区有事务之前,删除多余的check约束
alter table lzlpartition1_202303 drop constraint chk_202303;
分区索引的锁
- 只读事务时创建/删除分区索引
当分区上有共享锁时AccessShareLock,也就是分区表上有查询事务的情况下
CREATE INDEX ON lzlpartition1创建成功(注意没有加concurrently);DROP INDEX lzlpartition1失败
--session1 开启事务,读取分区表数据
=> begin;
BEGIN
=> select count(*) from lzlpartition1 where date_created>='2023-01-01 00:00:00' and date_created<='2023-01-02 00:00:00';count
-------86401
(1 row)
--session2 创建索引,成功
=> create index idx_datecreated on lzlpartition1(date_created);;
CREATE INDEX
--session2 删除索引,等待
=> drop index idx_datecreated;--session3 查看锁
=> select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+---------------------------+------------+---------------+--------+---------------------+---------relation | dbmgr | lzlpartition1_202301_pkey | [null] | [null] | 300371 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 99598 | AccessExclusiveLock | frelation | dbmgr | lzlpartition1_202301 | [null] | [null] | 300371 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 300371 | AccessShareLock | t
create index没有申请表上的AccessExclusiveLock,但是drop index申请了表上的AccessExclusiveLock。
从这个的例子可以得出:
只读事务不会阻塞创建索引,但会阻塞删除索引
- 更新事务时创建/删除分区索引
--session1 开启更新事务
=> begin;
BEGIN
=> update lzlpartition1 set name='abc' where date_created='2023-01-01 10:00:00';
UPDATE 1
--session2 创建分区索引,等待
=> create index idx_datecreated on lzlpartition1(date_created);--session3 查看锁情况
=>select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
-> where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+---------------------------+------------+---------------+--------+------------------+---------relation | dbmgr | lzlpartition1_202301_pkey | [null] | [null] | 300371 | RowExclusiveLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 99598 | ShareLock | frelation | dbmgr | lzlpartition1_202301 | [null] | [null] | 300371 | RowExclusiveLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 300371 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 300371 | RowExclusiveLock | t
create index会话(99598)申请分区主表的ShareLock锁,DML事务会话(300371 )持有该子分区和主表的RowExclusiveLock

create index(无concurrently)会话申请主表ShareLock;
只读事务会话申请主表和子表的AccessShareLock;
更新事务会话申请主表和子表的RowExclusiveLock;
==>
AccessShareLock不阻塞ShareLock,所以查询不阻塞create index(无concurrently);
RowExclusiveLock阻塞ShareLock,所以DML阻塞create index(无concurrently);
- concurrently创建分区索引
注意:在分区表上不能用concurrently创建索引
=> create index concurrently idx_datecreated on lzlpartition1(date_created);
ERROR: 0A000: cannot create index on partitioned table "lzlpartition1" concurrently
LOCATION: DefineIndex, indexcmds.c:665
有个patch https://commitfest.postgresql.org/35/2815/在解决这个问题。
目前可以在分区子表上concurrently创建索引。
--session1 仍然使用之前的DML事务
--session2 concurrently方式在子表上创建索引,等待
=> create index concurrently idx_datecreated_202301 on lzlpartition1_202301(date_created);--session3 查询锁情况
=> select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+---------------------------+------------+---------------+--------+--------------------------+---------relation | dbmgr | lzlpartition1_202301_pkey | [null] | [null] | 300371 | RowExclusiveLock | trelation | dbmgr | lzlpartition1_202301 | [null] | [null] | 99598 | ShareUpdateExclusiveLock | trelation | dbmgr | lzlpartition1_202301 | [null] | [null] | 300371 | RowExclusiveLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 300371 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 300371 | RowExclusiveLock | t
concurrently申请的锁降低了一级,跟ROW EXCL不冲突了。锁都不冲突了,但是为什么concurrently本身还是被阻塞了呢?
it must wait for all existing transactions that could potentially modify or use the index to terminate.
官方文档解释concurrently需要等待潜在修改/使用索引的事务完成,我们这里的update语句更新了索引字段,所以concurrently需要等待它完成。
虽然concurrently本身因为之前的DML语句没有完成,但是这也有一个好处:concurrently不会阻塞后续的DML语句。
--concurrently没有完成的情况下
--session4 更新一条记录
=> update lzlpartition1 set name='abc' where date_created='2023-01-01 12:00:00';
UPDATE 1
汇总分区索引的锁问题:
- 分区表上只读/读写/创建索引时的锁跟普通表是差不多的,只需要注意事务会在分区主表和子表上都会加锁,所以后续阻塞链的锁更重时,会影响所有分区
- 只读事务不会阻塞create index,但是会阻塞drop index
- DML会阻塞create index,也会阻塞create index concurrently,但是concurrently不会阻塞DML
- 虽然在分区表上create index可以自动在各个分区和未来分区上创建索引,但是由于阻塞问题不建议在生产直接使用
- 不能在分区主表上直接使用concurrently,所以需要在各个分区子表上concurrently创建索引
- concurrently不会阻塞后续的事务,但本身会被之前的长事务阻塞,也可能导致创建的索引失效,所以需要关注长事务问题
创建分区索引的正确姿势
虽然不能以concurrently方式在分区表上创建索引,但可以在分区子表用concurrently创建索引,需要用到语法:
CREATE INDEX ON ONLY :在主表上创建一个无效索引,不会在子分区自动创建索引
CREATE INDEX CONCURRENTLY :concurrently方式在子分区上创建索引
ALTER INDEX .. ATTACH PARTITION:将分区索引ATTACH到主索引上,所有子分区索引ATTACH后,分区主表索引自动标记为有效。
不过在执行这些命令时仍然需要关注锁的情况
下面观察上面两个语句申请锁和阻塞的情况:
(过程中全程开启session1的DML显示事务)
- ONLY创建索引的阻塞情况
=> CREATE INDEX IDX_DATECREATED ON ONLY lzlpartition1(date_created);
--等待--查看锁情况locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+----------------------+------------+---------------+--------+------------------+---------relation | dbmgr | lzlpartition1_202301 | [null] | [null] | 448243 | RowExclusiveLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 448243 | RowExclusiveLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 444399 | ShareLock | f
ONLY创建索引会申请ShareLock锁,ShareLock跟RowExclusiveLock是相互阻塞的。所以,虽然ONLY本身执行会很快,但是ONLY创建索引也不是无脑使用。
--将DML事务结束后,ONLY创建索引完成"idx_datecreated" btree (date_created) INVALID
CREATE INDEX ON ONLY在分区主表上创建了一个失效索引,且不会在子分区创建索引。
- ATTACH索引的阻塞情况
--将ONLY索引创建完成后,再开启session1的DML显示事务
=> begin;
BEGIN
=> insert into lzlpartition1 values('1111','abc','2023-01-01 00:00:00');
INSERT 0 1--session2 concurrently创建子分区的索引
=> create index concurrently idx_datecreated_202302 on lzlpartition1_202302(date_created);
CREATE INDEX --202302分区索引创建完成
=> create index concurrently idx_datecreated_202304 on lzlpartition1_202304(date_created);
CREATE INDEX --202302分区索引创建完成
=> create index concurrently idx_datecreated_202301 on lzlpartition1_202301(date_created);
----创建202302分区索引等待
concurrently会等待潜在使用索引的事务完成,我们这里的显示事务只插入了202301分区,也只有这个分区的concurrently创建索引没有完成。
--完成session1的DML显示事务,等待索引完成后,然后再次开启事务
=> commit;
COMMIT
=> begin;
BEGIN
=> insert into lzlpartition1 values('1111','abc','2023-01-01 00:00:01');
INSERT 0 1
--session2 attach索引=> ALTER INDEX idx_datecreated ATTACH PARTITION idx_datecreated_202302;
ALTER INDEX --成功ATTACH
=> \d+ idx_datecreatedPartitioned index "public.idx_datecreated"Column | Type | Key? | Definition | Storage | Stats target
--------------+-----------------------------+------+--------------+---------+--------------date_created | timestamp without time zone | yes | date_created | plain |
btree, for table "public.lzlpartition1", invalid
Partitions: idx_datecreated_202302 --202302子分区索引已经attach,索引仍为invalid
Access method: btree
--将剩余的子分区索引全部attach
=> ALTER INDEX idx_datecreated ATTACH PARTITION idx_datecreated_202301;
ALTER INDEX --成功ATTACH
=> ALTER INDEX idx_datecreated ATTACH PARTITION idx_datecreated_202304;
ALTER INDEX --成功ATTACH
--完成所有子分区索引attach后,主表索引自动有效
=> \d+ idx_datecreatedPartitioned index "public.idx_datecreated"Column | Type | Key? | Definition | Storage | Stats target
--------------+-----------------------------+------+--------------+---------+--------------date_created | timestamp without time zone | yes | date_created | plain |
btree, for table "public.lzlpartition1"
Partitions: idx_datecreated_202301,idx_datecreated_202302,idx_datecreated_202304
Access method: btree
attach不会被DML阻塞,直接完成。此时用partition of创建的新分区也会自动创建子分区索引。
综上所述,
CREATE INDEX ON ONLY会申请ShareLock锁,跟DML申请的RowExclusiveLock是相互阻塞的CREATE INDEX CONCURRENTLY会申请ShareUpdateExclusiveLock锁,不会阻塞DML申请的RowExclusiveLock,但是CREATE INDEX CONCURRENTLY需要等待DML事务完成才能完成(concurrently可以获得锁,但不能完成)ALTER INDEX .. ATTACH PARTITION会申请AccessShareLock,这是最轻的锁,跟DML申请的RowExclusiveLock相互不阻塞。- 查询申请的是
AccessShareLock最轻的锁,除非DDL申请AccessExclusiveLock最重的锁,不然不会发生阻塞
所以,直接在分区上create index会阻塞DML,是不可取的
创建分区索引的正确姿势:
--ONLY方式在分区主表上创建失效索引。快,会阻塞后续dml,会影响业务,需要关注长事务
CREATE INDEX IDX_DATECREATED ON ONLY lzlpartition1(date_created);
--CONCURRENTLY在各个分区子表上创建索引。慢,不会阻塞后续dml,不会影响业务,但需要关注DML长事务防止本身失败
create index concurrently idx_datecreated_202302 on lzlpartition1_202302(date_created);
--所有索引attach。快,不会发生业务阻塞ALTER INDEX idx_datecreated ATTACH PARTITION idx_datecreated_202302;
分区表添加主键和唯一索引
“主键索引”功能上等于“唯一索引+null约束”(但是主键只能有一个)。分区表创建唯一索引可以参考上面的索引创建最佳实践:only创建主表索引、concurrently创建子表索引、attach。
而主键虽然支持普通表using index语法,但是目前不支持分区表这样使用:
=> ALTER TABLE lzlpartition1 ADD CONSTRAINT pk_id_date_created PRIMARY KEY USING INDEX idx_uniq;
ERROR: 0A000: ALTER TABLE / ADD CONSTRAINT USING INDEX is not supported on partitioned tables
LOCATION: ATExecAddIndexConstraint, tablecmds.c:8032
也就是说可以通过提前创建not null约束+attach索引的方式创建一个非空的唯一索引,但是最后一步using index添加主键却不行。
下面看下直接添加/删除主键的阻塞情况
- 直接删除主键
--session 1
=> begin;
BEGIN
Time: 0.318 ms
=> select * from lzlpartition1 where date_created='2023-01-01 22:00:00';id | name | date_created
------+----------------------------------+---------------------7715 | beee680a86e1d12790489e9ab4a4351b | 2023-01-01 22:00:00--session2 删除主键等待=> alter table lzlpartition1 drop constraint lzlpartition1_pkey;--session3 观察=> select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+---------------------------+------------+---------------+-------+---------------------+---------relation | dbmgr | lzlpartition1_202301_pkey | [null] | [null] | 21659 | AccessShareLock | trelation | dbmgr | lzlpartition1_202301 | [null] | [null] | 21659 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 95016 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 95016 | AccessExclusiveLock | frelation | dbmgr | lzlpartition1 | [null] | [null] | 21659 | AccessShareLock | t
删除主键申请的是AccessExclusiveLock,阻塞一切
- 直接添加主键
--session1事务结束,session2的删除主键完成
--session1再次开启只读事务
--session2在分区表上添加主键,等待
=> ALTER TABLE lzlpartition1 ADD PRIMARY KEY(id, date_created);--session3 观察锁
=> select l.locktype,d.datname,r.relname,l.virtualxid,l.transactionid,l.pid,l.mode,l.granted from pg_locks l left join pg_database d on l.database=d.oid left join pg_class r on l.relation=r.oid
where relname like '%lzlpartition1%';locktype | datname | relname | virtualxid | transactionid | pid | mode | granted
----------+---------+----------------------+------------+---------------+-------+---------------------+---------relation | dbmgr | lzlpartition1_202301 | [null] | [null] | 21659 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 95016 | AccessShareLock | trelation | dbmgr | lzlpartition1 | [null] | [null] | 95016 | AccessExclusiveLock | f --添加主键的会话relation | dbmgr | lzlpartition1 | [null] | [null] | 21659 | AccessShareLock | t
添加主键在主表上申请AccessExclusiveLock,阻塞一切。
分区表上添加索引很慢,主键又会造成后续的阻塞,目前没有影响较小的在分区表上添加主键的办法。虽然没有达到目的,可以考虑用“attach唯一索引+非空约束”的办法;或者只能申请较长的停分区表业务,等待创建索引完成;或者通过第三方同步工具将数据插入一个带主键的分区表。
hash分区表添加分区
如果新增后的分区数为之前的整数倍,那么我们将会知道新分区的数据来自哪个老分区。比如将原本只有3个分区的hash分区表做成6个分区的,我们可以知道分区数据来源
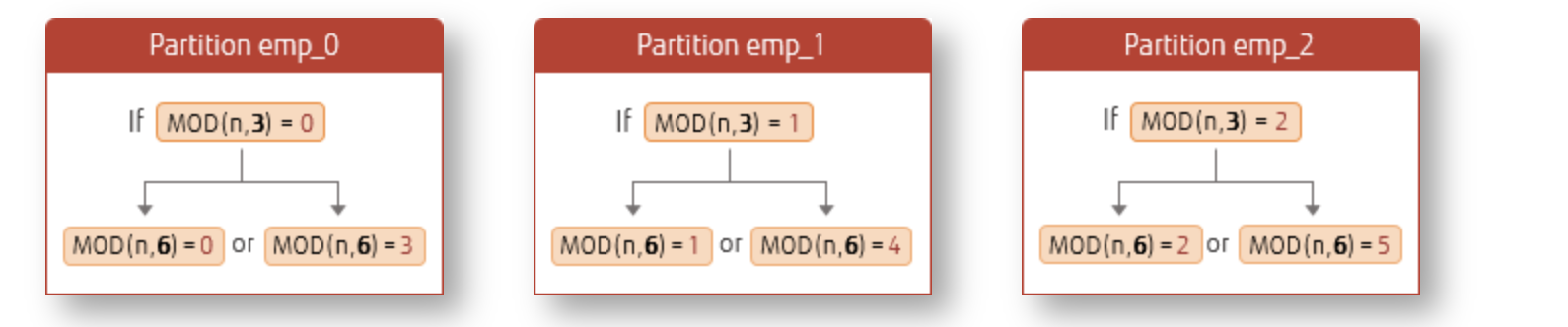
虽然了解了这种简单的数据特性,但实际情况可能没有什么用,因为新分区的hash分区总是被暴力插入的。从操作上“3->4”的新增分区操作和“3->6”的新增分区操作没有什么区别。
目前成熟的数据同步工具已经非常多了,比如使用dts把表插入到新表中然后做表切换,停机时间会很短,生产环境应优先选择这个方案。
下面是主要是测试和观察hash分区表手动新增整数倍分区时的操作:
- 分区信息
SELECT tableoid::regclass,count(*) FROM orders group by tableoid::regclass;tableoid | count
-----------+-------orders_p1 | 3377orders_p3 | 3354orders_p2 | 3369
2. detach分区3个分区的hash原生分区表再添加3个分区
ALTER TABLE orders DETACH PARTITION orders_p1;
ALTER TABLE orders DETACH PARTITION orders_p2;
ALTER TABLE orders DETACH PARTITION orders_p3;
- rename分区
ALTER TABLE orders_p1 RENAME TO bak_orders_p1;
ALTER TABLE orders_p2 RENAME TO bak_orders_p2;
ALTER TABLE orders_p3 RENAME TO bak_orders_p3;
- 在老表上创建6个hash分区
CREATE TABLE orders_p1 PARTITION OF orders FOR VALUES WITH (MODULUS 6, REMAINDER 0);
CREATE TABLE orders_p2 PARTITION OF orders FOR VALUES WITH (MODULUS 6, REMAINDER 1);
CREATE TABLE orders_p3 PARTITION OF orders FOR VALUES WITH (MODULUS 6, REMAINDER 2);
CREATE TABLE orders_p4 PARTITION OF orders FOR VALUES WITH (MODULUS 6, REMAINDER 3);
CREATE TABLE orders_p5 PARTITION OF orders FOR VALUES WITH (MODULUS 6, REMAINDER 4);
CREATE TABLE orders_p6 PARTITION OF orders FOR VALUES WITH (MODULUS 6, REMAINDER 5);
- 查看分区信息
注意分区约束使用的函数
\d+ orders_p1Table "public.orders_p1"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+-----------------------+-----------+----------+---------+----------+--------------+-------------order_id | integer | | | | plain | | name | character varying(10) | | | | extended | |
Partition of: orders FOR VALUES WITH (modulus 6, remainder 0)
Partition constraint: satisfies_hash_partition('412053'::oid, 6, 0, order_id)
Access method: heap
计算老分区数据需要插入到哪个新分区上
例如原先为modulus 3,remainder 0的分区,需要把数据分别插入到modulus 6,remainder0和3两个分区中。
select count(*) from bak_orders_p1 where satisfies_hash_partition('412053'::oid, 6, 0, order_id)=true;count
-------1776select count(*) from bak_orders_p1 where satisfies_hash_partition('412053'::oid, 6, 3, order_id)=true;count
-------1601select count(*) from bak_orders_p1;count
-------3377
6.通过分区子表插入数据
可以直接把数据插入对应的分区子表上,而不是通过分区主表插入
INSERT INTO orders_p1 SELECT * FROM bak_orders_p1 where satisfies_hash_partition('412053'::oid, 6, 0, order_id)=true;
INSERT INTO orders_p2 SELECT * FROM bak_orders_p2 where satisfies_hash_partition('412053'::oid, 6, 1, order_id)=true;
INSERT INTO orders_p3 SELECT * FROM bak_orders_p3 where satisfies_hash_partition('412053'::oid, 6, 2, order_id)=true;
INSERT INTO orders_p4 SELECT * FROM bak_orders_p1 where satisfies_hash_partition('412053'::oid, 6, 3, order_id)=true;
INSERT INTO orders_p5 SELECT * FROM bak_orders_p2 where satisfies_hash_partition('412053'::oid, 6, 4, order_id)=true;
INSERT INTO orders_p6 SELECT * FROM bak_orders_p3 where satisfies_hash_partition('412053'::oid, 6, 5, order_id)=true;
- 验证3个老分区的数据已插入到6个新分区中
SELECT tableoid::regclass,count(*) FROM orders group by tableoid::regclass;
tableoid | count
-----------+-------
orders_p3 | 1665
orders_p5 | 1678
orders_p1 | 1776
orders_p6 | 1689
orders_p4 | 1601
orders_p2 | 1691
修改分区字段长度索引会重建
修改字段需要考虑三个方面:表重写、索引重建、统计信息丢失
- 修改字段类型、字段长度减少都会重写表
- 字段长度增加仅会丢失统计信息,一个例外情况是将长度改小(或者int4改int8)会重写表
- 字段长度增加不会重建索引,一个例外情况是分区表字段长度增加会重建索引(如果这个字段有索引)
修改字段,参考PostgreSQL学徒。
这里主要测试分区表将字段改长的场景,如果存在索引的话,可能会引起分区表上的事务阻塞。
普通表,将有索引的字段改长:
--新建普通表和索引
=> create table t111(id int,name varchar(50));
CREATE TABLE
=> insert into t111 values(1001,'abc');
INSERT 0 1
=> create index idx111 on t111(name);
CREATE INDEX--索引文件relfilenode为417728select pg_relation_filepath('idx111');pg_relation_filepath
----------------------base/16398/417728
(1 row)--将字段改长
=> alter table t111 alter column name type varchar(60);
ALTER TABLE
--索引文件relfilenode为417728,未发生变化,普通表索引未重建
=> select pg_relation_filepath('idx111');pg_relation_filepath
----------------------base/16398/417728
分区表,将有索引的字段改长:
--在分区表上创建一个索引
=> create index idx_name on lzlpartition1(name);
CREATE INDEX
--查看其中一个分区上的索引
=> \d+ lzlpartition1_202301Table "dbmgr.lzlpartition1_202301"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------------+-----------------------------+-----------+----------+---------+----------+--------------+-------------id | integer | | | | plain | | name | character varying(50) | | | | extended | | date_created | timestamp without time zone | | not null | now() | plain | |
Partition of: lzlpartition1 FOR VALUES FROM ('2023-01-01 00:00:00') TO ('2023-02-01 00:00:00')
Partition constraint: ((date_created IS NOT NULL) AND (date_created >= '2023-01-01 00:00:00'::timestamp without time zone) AND (date_created < '2023-02-01 00:00:00'::timestamp without time zone))
Indexes:"lzlpartition1_202301_name_idx" btree (name)
Access method: heap=> select pg_relation_filepath('lzlpartition1_202301_name_idx') idx,pg_relation_filepath('lzlpartition1_202301') tbl;idx | tbl
-------------------+-------------------base/16398/417810 | base/16398/417800
(1 row)--将索引字段改大,分区表索引重建
=> alter table lzlpartition1 alter column name type varchar(60);
ALTER TABLE
=> select pg_relation_filepath('lzlpartition1_202301_name_idx') idx,pg_relation_filepath('lzlpartition1_202301') tbl;idx | tbl
-------------------+-------------------base/16398/417814 | base/16398/417800--将索引字段改小,分区表重写
=> alter table lzlpartition1 alter column name type varchar(40);
ALTER TABLE
Time: 609.585 ms
=> select pg_relation_filepath('lzlpartition1_202301_name_idx') idx,pg_relation_filepath('lzlpartition1_202301') tbl;idx | tbl
-------------------+-------------------base/16398/417828 | base/16398/417825--将索引字段保持原样,分区表索引重建
=> alter table lzlpartition1 alter column name type varchar(40);
ALTER TABLE
=> select pg_relation_filepath('lzlpartition1_202301_name_idx') idx,pg_relation_filepath('lzlpartition1_202301') tbl;idx | tbl
-------------------+-------------------base/16398/417834 | base/16398/417825
普通表改大字段长度只需要关注统计信息会丢失(int到bigint除外);但是分区表在改大字段长度时,如果这个字段上有索引,不仅会丢失统计信息,还会重建索引。由于alter修改字段是8级锁,所以重建索引期间会导致长时间阻塞。
建议:先把索引删除,修改完字段后,“父表ONLY+子表CIC+ATTACH”的方式建索引。
分区表维护小结
- partition of/drop table/DETACH需要 ACCESS EXCLUSIVE锁;推荐ATTACH/DETACH CONCURRENTLY,它们不会造成阻塞,DETACH CONCURRENTLY需关注已有长事务
- attach表分区前可以提前在分区上创建约束,这样会减去在attach时扫描分区数据的时间
- 目前不支持分区表CIC创建索引,可以通过在“主表上only+子表上concurrently+attach索引”的方式创建分区索引,减少业务阻塞时间
- 分区表不支持using index方式创建主键
- 需要关注分区表修改字段长度这个例外情况
分区表的优化
分区裁剪
分区裁剪(Partition Pruning)可以为声明式分区提升性能,是分区表优化非常重要的特性。如果没有分区裁剪,那么查询会扫描所有分区。当有分区裁剪时,优化器可以通过where条件过滤那些不需要访问的分区
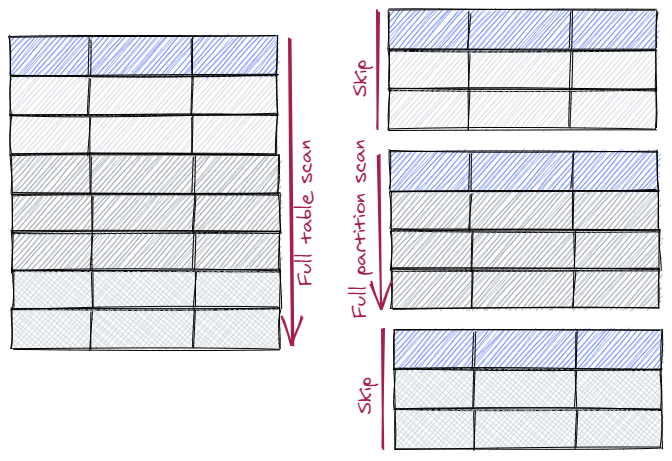
分区裁剪依赖于分区约束Partition constraint(\d+可以看到),也就是说查询必须带有分区键条件才能进行裁剪。这个约束不同于一般约束constraint,它在分区创建时自动创建。
分区裁剪由enable_partition_pruning参数控制,默认为on。
--没有分区裁剪时,会访问所有分区
=> set enable_partition_pruning=off;
SET=> explain select count(*) from lzlpartition1 where date_created='2023-01-01';QUERY PLAN
--------------------------------------------------------------------------------------------------Aggregate (cost=1872.08..1872.09 rows=1 width=8)-> Append (cost=0.00..1872.07 rows=4 width=0)-> Seq Scan on lzlpartition1_202301 lzlpartition1_1 (cost=0.00..992.30 rows=1 width=0)Filter: (date_created = '2023-01-01 00:00:00'::timestamp without time zone)-> Seq Scan on lzlpartition1_202302 lzlpartition1_2 (cost=0.00..864.12 rows=1 width=0)Filter: (date_created = '2023-01-01 00:00:00'::timestamp without time zone)-> Seq Scan on lzlpartition1_202304 lzlpartition1_3 (cost=0.00..15.62 rows=2 width=0)Filter: (date_created = '2023-01-01 00:00:00'::timestamp without time zone)--有分区裁剪时,不需要访问的分区被排除
=> set enable_partition_pruning=on;
SET=> explain select count(*) from lzlpartition1 where date_created='2023-01-01';QUERY PLAN
------------------------------------------------------------------------------------------Aggregate (cost=992.30..992.31 rows=1 width=8)-> Seq Scan on lzlpartition1_202301 lzlpartition1 (cost=0.00..992.30 rows=1 width=0)Filter: (date_created = '2023-01-01 00:00:00'::timestamp without time zone)
(3 rows)
(官方文档说生成执行计划时发生裁剪,那么explain有Subplans Removed字样,经测试有时候没有,就像上面的explain例子)
分区裁剪可能发生在两个阶段:生成执行计划时、真正执行时
为什么会发生这样的情况呢?因为有时候只有执行时才会知道那些分区可以裁剪。有两种情况:
-
Parameterized Nested Loop Joins: The parameter from the outer side of the
join can be used to determine the minimum set of inner side partitions to
scan. -
Initplans: Once an initplan has been executed we can then determine which
partitions match the value from the initplan.
模拟执行时发生裁剪:从其他表拿数据优化器肯定不知道数据是什么,就无法以此为依据在执行计划时发生分区裁剪:
--创建一个其他表
=> create table x(date_created timestamp);
CREATE TABLE=> insert into x values('2023-01-01 09:00:00');
INSERT 0 1--仅生成执行计划,不执行,没有发生裁剪
=> explain select count(*) from lzlpartition1 where date_created=(select date_created from x);QUERY PLAN
--------------------------------------------------------------------------------------------------Aggregate (cost=1904.68..1904.69 rows=1 width=8)InitPlan 1 (returns $0)-> Seq Scan on x (cost=0.00..32.60 rows=2260 width=8)-> Append (cost=0.00..1872.07 rows=4 width=0)-> Seq Scan on lzlpartition1_202301 lzlpartition1_1 (cost=0.00..992.30 rows=1 width=0)Filter: (date_created = $0)-> Seq Scan on lzlpartition1_202302 lzlpartition1_2 (cost=0.00..864.12 rows=1 width=0)Filter: (date_created = $0)-> Seq Scan on lzlpartition1_202304 lzlpartition1_3 (cost=0.00..15.62 rows=2 width=0)Filter: (date_created = $0)
(10 rows)--执行sql,发生裁剪。关键字never executed
=> explain analyze select count(*) from lzlpartition1 where date_created=(select date_created from x);QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------Aggregate (cost=1904.68..1904.69 rows=1 width=8) (actual time=5.680..5.682 rows=1 loops=1)InitPlan 1 (returns $0)-> Seq Scan on x (cost=0.00..32.60 rows=2260 width=8) (actual time=0.013..0.014 rows=1 loops=1)-> Append (cost=0.00..1872.07 rows=4 width=0) (actual time=0.029..5.676 rows=2 loops=1)-> Seq Scan on lzlpartition1_202301 lzlpartition1_1 (cost=0.00..992.30 rows=1 width=0) (actual time=0.008..5.652 rows=2 loops=1)Filter: (date_created = $0)Rows Removed by Filter: 45382-> Seq Scan on lzlpartition1_202302 lzlpartition1_2 (cost=0.00..864.12 rows=1 width=0) (never executed)Filter: (date_created = $0)-> Seq Scan on lzlpartition1_202304 lzlpartition1_3 (cost=0.00..15.62 rows=2 width=0) (never executed)Filter: (date_created = $0)Planning Time: 0.157 msExecution Time: 5.732 ms
(13 rows)
partition wise join
partition wise join可以减少分区连接的代价。
假设有两个分区表t1、t2,他们都有3个分区(p1,p2,p3)且分区定义一致,t1的每个分区10条数据,t2的每个分区20条数据:
| t1 | t2 | |
|---|---|---|
| p1 | 10 rows | 20 rows |
| p2 | 10 rows | 20 rows |
| p3 | 10 rows | 20 rows |
| 此时t1和t2表进行连接, |
- 正常情况下需要把所有两个分区数据取出进行连接,他们的行的连接比较次数为:
(10+10+10)*(20+20+20)=180次 - 有partition wise join的情况下,因为结构差不多,只需要连接对应的分区,如
t1.p1<=>t2.p1,
t1.p2<=>t2.p2,
t1.p3<=>t2.p3,
此时的连接比较次数为:
(10*20)*3=90次
在分区特别多的情况下,partition wise join的代价会小很多。
参数enable_partitionwise_join:是否开启partition wise join,默认关闭
partition wise join的前提条件非常苛刻:
- 连接条件必须包含分区键
- 分区键必须是相同的数据类型
- 分区必须一一对应
看上去条件苛刻,两个不同的用途的表能产生partition wise join的情况是也是比较少的,比较常见的应该是两个表都是range时间分区。还有一种情况,如果是分区表自我连接,也符合partition wise join的前提:
--未开启partition wise join的情况
=> explain select p1.*,p2.name from lzlpartition1 p1,lzlpartition1 p2 where p1.date_created=p2.date_created and p2.name='256ac66bb53d31bc6124294238d6410c';QUERY PLAN
----------------------------------------------------------------------------------------------------------------Hash Join (cost=546.64..9256.34 rows=182252 width=288)Hash Cond: (p1.date_created = p2.date_created)-> Append (cost=0.00..2085.46 rows=85364 width=150)-> Seq Scan on lzlpartition1_202301 p1_1 (cost=0.00..878.84 rows=45384 width=150)-> Seq Scan on lzlpartition1_202302 p1_2 (cost=0.00..765.30 rows=39530 width=150)-> Seq Scan on lzlpartition1_202304 p1_3 (cost=0.00..14.50 rows=450 width=150)-> Hash (cost=541.30..541.30 rows=427 width=146)-> Append (cost=7.17..541.30 rows=427 width=146)-> Bitmap Heap Scan on lzlpartition1_202301 p2_1 (cost=7.17..284.30 rows=227 width=146)Recheck Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)-> Bitmap Index Scan on lzlpartition1_202301_name_idx (cost=0.00..7.12 rows=227 width=0)Index Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)-> Bitmap Heap Scan on lzlpartition1_202302 p2_2 (cost=6.95..248.52 rows=198 width=146)Recheck Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)-> Bitmap Index Scan on lzlpartition1_202302_name_idx (cost=0.00..6.90 rows=198 width=0)Index Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)-> Bitmap Heap Scan on lzlpartition1_202304 p2_3 (cost=2.66..6.35 rows=2 width=146)Recheck Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)-> Bitmap Index Scan on lzlpartition1_202304_name_idx (cost=0.00..2.66 rows=2 width=0)Index Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)
(20 rows)--开启partition wise join的情况
=> set enable_partitionwise_join =on;
SETM=> explain select p1.*,p2.name from lzlpartition1 p1,lzlpartition1 p2 where p1.date_created=p2.date_created and p2.name='256ac66bb53d31bc6124294238d6410c';QUERY PLAN
----------------------------------------------------------------------------------------------------------------Append (cost=287.14..2529.83 rows=438 width=288)-> Hash Join (cost=287.14..1338.49 rows=232 width=288)Hash Cond: (p1_1.date_created = p2_1.date_created)-> Seq Scan on lzlpartition1_202301 p1_1 (cost=0.00..878.84 rows=45384 width=150)-> Hash (cost=284.30..284.30 rows=227 width=146)-> Bitmap Heap Scan on lzlpartition1_202301 p2_1 (cost=7.17..284.30 rows=227 width=146)Recheck Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)-> Bitmap Index Scan on lzlpartition1_202301_name_idx (cost=0.00..7.12 rows=227 width=0)Index Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)-> Hash Join (cost=250.99..1166.55 rows=202 width=288)Hash Cond: (p1_2.date_created = p2_2.date_created)-> Seq Scan on lzlpartition1_202302 p1_2 (cost=0.00..765.30 rows=39530 width=150)-> Hash (cost=248.52..248.52 rows=198 width=146)-> Bitmap Heap Scan on lzlpartition1_202302 p2_2 (cost=6.95..248.52 rows=198 width=146)Recheck Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)-> Bitmap Index Scan on lzlpartition1_202302_name_idx (cost=0.00..6.90 rows=198 width=0)Index Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)-> Hash Join (cost=6.37..22.60 rows=4 width=288)Hash Cond: (p1_3.date_created = p2_3.date_created)-> Seq Scan on lzlpartition1_202304 p1_3 (cost=0.00..14.50 rows=450 width=150)-> Hash (cost=6.35..6.35 rows=2 width=146)-> Bitmap Heap Scan on lzlpartition1_202304 p2_3 (cost=2.66..6.35 rows=2 width=146)Recheck Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)-> Bitmap Index Scan on lzlpartition1_202304_name_idx (cost=0.00..2.66 rows=2 width=0)Index Cond: ((name)::text = '256ac66bb53d31bc6124294238d6410c'::text)
(25 rows)
在没有开启partition wise join的情况下,优化器需要先访问分区表p2的所有分区数据(符合条件的)放一起(append),然后与分区表p1的所有分区数据通过分区键连接(Hash Join)。
在开启partition wise join的情况下,优化器将p1、p2两个分区表(实际上是一个,访问了两次)所对应的分区相连接:
p1_1<=>p2_1 Hash Join
p1_2<=>p2_2 Hash Join
p1_3<=>p2_3 Hash Join
然后再把数据合到一起(append)。
如果数据分区足够多,再加上分区裁剪,partition wise join会有很好的优化效果。
partition wise grouping/aggregation
分区表在进行分区数据聚合计算时,分区可以各自算各自的,不需要扫描所有分区数据进行聚合计算,只需要各自分区的数据聚合计算完成后汇总返回即可。
没有partition wise grouping本质上是“先扫描所有分区,再聚合计算”;有partition wise grouping是“先分区聚合计算,再汇合数据”。
partition wise grouping的优势如下:
- 分区在foreign server时,可以将聚合算子下推到foreign server
- 聚合到hash表时,每个分区而不是所有分区去使用内存hash表的空间,可以减少内存使用
- 聚合算法下方到各自的分区可以更好的使用索引、并行等等特性
- 更少的数据对比。虽然数据扫描都是一样的,但是减少了数据对比,比如最后一个分区的数据不需要与第一个分区的数据进行对比
参数enable_partitionwise_aggregate:是否开启partition wise grouping/aggregation,默认关闭
partition wise aggregate示例:
=> vacuum (analyze) lzlpartition1;--未开启wise agg
=> set enable_partitionwise_aggregate =off;
SET
=> explain select date_created,min(id),count(*) from lzlpartition1 group by date_created order by 1,2,3;QUERY PLAN
-------------------------------------------------------------------------------------------------------------Sort (cost=10354.94..10562.89 rows=83180 width=20)Sort Key: lzlpartition1.date_created, (min(lzlpartition1.id)), (count(*))-> HashAggregate (cost=2725.69..3557.49 rows=83180 width=20)Group Key: lzlpartition1.date_created-> Append (cost=0.00..2085.46 rows=85364 width=12)-> Seq Scan on lzlpartition1_202301 lzlpartition1_1 (cost=0.00..878.84 rows=45384 width=12)-> Seq Scan on lzlpartition1_202302 lzlpartition1_2 (cost=0.00..765.30 rows=39530 width=12)-> Seq Scan on lzlpartition1_202304 lzlpartition1_3 (cost=0.00..14.50 rows=450 width=12)--开启wise agg
=> set enable_partitionwise_aggregate =on;
SET
=> explain select date_created,min(id),count(*) from lzlpartition1 group by date_created order by 1,2,3;QUERY PLAN
-------------------------------------------------------------------------------------------------------------Sort (cost=10356.08..10564.32 rows=83296 width=20)Sort Key: lzlpartition1.date_created, (min(lzlpartition1.id)), (count(*))-> Append (cost=1219.22..3548.31 rows=83296 width=20)-> HashAggregate (cost=1219.22..1663.09 rows=44387 width=20)Group Key: lzlpartition1.date_created-> Seq Scan on lzlpartition1_202301 lzlpartition1 (cost=0.00..878.84 rows=45384 width=12)-> HashAggregate (cost=1061.77..1448.86 rows=38709 width=20)Group Key: lzlpartition1_1.date_created-> Seq Scan on lzlpartition1_202302 lzlpartition1_1 (cost=0.00..765.30 rows=39530 width=12)-> HashAggregate (cost=17.88..19.88 rows=200 width=20)Group Key: lzlpartition1_2.date_created-> Seq Scan on lzlpartition1_202304 lzlpartition1_2 (cost=0.00..14.50 rows=450 width=12)
(12 rows)
无wise aggregate时,先扫描所有数据再合并(Append),合并后再聚合计算(HashAggregate);
partition wise aggregate先在分区聚合计算(HashAggregate),然后在合并结果(Append)。
partial aggregation
聚合算法可以下放到分区上进行计算,此时聚合后的数据分为两种情况:聚合数据不重复(group包含分区键),聚合数据有重复(group不包含分区键)。
当聚合数据不重复时,只需要把各自分区算出来的聚合数据简单的加到一起(append)即可(就像上面的案例);当各自分区算出来的聚合数据重复时,仍然需要再聚合计算一次(Finalize Aggregate)。不包含分区键的聚合计算就是partial aggregation。
partial aggregation示例:
--group by不是分区键时
=> show enable_partitionwise_aggregate;enable_partitionwise_aggregate
--------------------------------on
=> explain select id,count(*) from lzlpartition1 group by id ;QUERY PLAN
------------------------------------------------------------------------------------------------------------Finalize HashAggregate (cost=2474.80..2573.80 rows=9900 width=12)Group Key: lzlpartition1.id-> Append (cost=1105.76..2377.47 rows=19467 width=12)-> Partial HashAggregate (cost=1105.76..1202.28 rows=9652 width=12)Group Key: lzlpartition1.id-> Seq Scan on lzlpartition1_202301 lzlpartition1 (cost=0.00..878.84 rows=45384 width=4)-> Partial HashAggregate (cost=962.95..1059.10 rows=9615 width=12)Group Key: lzlpartition1_1.id-> Seq Scan on lzlpartition1_202302 lzlpartition1_1 (cost=0.00..765.30 rows=39530 width=4)-> Partial HashAggregate (cost=16.75..18.75 rows=200 width=12)Group Key: lzlpartition1_2.id-> Seq Scan on lzlpartition1_202304 lzlpartition1_2 (cost=0.00..14.50 rows=450 width=4)group by不包含分区键,也可以进行聚合计算,但是必须在稍后总聚合Finalize HashAggregate
即使没有group by,也可能发生Partial Aggregate:
=> show enable_partitionwise_aggregate;enable_partitionwise_aggregate
--------------------------------on
=> explain select count(*) from lzlpartition1;QUERY PLAN
------------------------------------------------------------------------------------------------------------Finalize Aggregate (cost=1872.10..1872.11 rows=1 width=8)-> Append (cost=992.30..1872.10 rows=3 width=8)-> Partial Aggregate (cost=992.30..992.31 rows=1 width=8)-> Seq Scan on lzlpartition1_202301 lzlpartition1 (cost=0.00..878.84 rows=45384 width=0)-> Partial Aggregate (cost=864.12..864.13 rows=1 width=8)-> Seq Scan on lzlpartition1_202302 lzlpartition1_1 (cost=0.00..765.30 rows=39530 width=0)-> Partial Aggregate (cost=15.62..15.63 rows=1 width=8)-> Seq Scan on lzlpartition1_202304 lzlpartition1_2 (cost=0.00..14.50 rows=450 width=0)=> explain select max(date_created) from lzlpartition1;QUERY PLAN
------------------------------------------------------------------------------------------------------------Finalize Aggregate (cost=1872.10..1872.11 rows=1 width=8)-> Append (cost=992.30..1872.10 rows=3 width=8)-> Partial Aggregate (cost=992.30..992.31 rows=1 width=8)-> Seq Scan on lzlpartition1_202301 lzlpartition1 (cost=0.00..878.84 rows=45384 width=8)-> Partial Aggregate (cost=864.12..864.13 rows=1 width=8)-> Seq Scan on lzlpartition1_202302 lzlpartition1_1 (cost=0.00..765.30 rows=39530 width=8)-> Partial Aggregate (cost=15.62..15.63 rows=1 width=8)-> Seq Scan on lzlpartition1_202304 lzlpartition1_2 (cost=0.00..14.50 rows=450 width=8)触发Partial Aggregate的前提不是group。应从Partial Aggregate的目的去考虑,它的目的是把聚合下放到分区,那么没有group的聚合其实也可以这么做,就像上面两个例子:他们都是在分区上聚合计算后(Partial Aggregate),汇总到一起再聚合计算一次( Finalize Aggregate);如果没有打开参数,这些聚合发生在扫描完所有分区后。
分区表的历史
声明式分区经过了多个版本的增强,如今已非常成熟。对于历史版本的声明式分区,功能增强如下:
PG9.6以前
- 只能继承表实现分区功能
PG10
- 支持声明式分区
- 支持range、list分区
- 支持attach/detach表分区
- 支持分区裁剪
PG11
- 增加支持HASH分区
- 支持创建主键、外键、索引、触发器
- 支持update分区键、自动创建分区上的索引
- 支持default分区
- 支持attach索引
- 支持FOR EACH ROW触发器,自动在已有/未来的子分区上创建
- 新增enable_partition_pruning参数;裁剪增强
- 支持partition wise join
- 支持partition wise aggregation
PG12
- 增强查询、插入、pruning、COPY性能
- 支持外键约束to分区表
- 支持非阻塞分区表ATTACH:
ALTER TABLE ATTACH PARTITION
PG13
- 增强pruning
- 增强partition wise join
- 支持BEFORE triggers
- 支持发布分区表;支持订阅写入分区表
PG14
- 增强update、delete性能
- 支持非阻塞分区表DETACH:
ALTER TABLE ... DETACH PARTITION ... CONCURRENTLY - 支持reindex分区表的索引
PG15
- 增强执行计划生成,减少多分区时执行计划生成时间
- 增强排序
- 支持cluster分区表
PG16
- 增强generated列的限制,主表有generated列子分区也必须包含。
- 增强查找range、list分区
参考
《PostgreSQL修炼之道》
https://mp.weixin.qq.com/s/NW8XOZNq0YlDZvx24H737Q
https://www.postgresql.org/docs/current/ddl-partitioning.html
https://www.postgresql.org/docs/current/ddl-inherit.html
https://www.postgresql.org/docs/13/sql-altertable.html
https://github.com/postgrespro/pg_pathman
https://developer.aliyun.com/article/62314
https://hevodata.com/learn/postgresql-partitions
https://www.postgresql.fastware.com/postgresql-insider-prt-ove
https://www.buckenhofer.com/2021/01/postgresql-partitioning-guide/
https://www.depesz.com/2018/05/01/waiting-for-postgresql-11-support-partition-pruning-at-execution-time/
https://blog.csdn.net/horses/article/details/86164273
http://www.pgsql.tech/article_0_10000102
https://brandur.org/fragments/postgres-partitioning-2022

![[二分查找] 旋转数组](https://img-blog.csdnimg.cn/dd9ea6066df2460192d8ad515acdc9a9.png)