转载自:https://developer.aliyun.com/article/700370
1. 参数设置
1.1 postgresql.conf中修改
# 1、总的可开启的WORKER足够大
max_worker_processes =128# 2、所有会话同时执行并行计算的并行度足够大
max_parallel_workers=64# 3、单个QUERY中并行计算NODE开启的WORKER=24
max_parallel_workers_per_gather =24# 4、所有表和索引扫描允许并行
set min_parallel_table_scan_size =0
set min_parallel_index_scan_size =0# 5、并行计算优化器成本设置为0
set parallel_tuple_cost =0
set parallel_setup_cost =0
1.2 执行前修改
# 1、总的可开启的WORKER足够大
postgres=# show max_worker_processes ; max_worker_processes
---------------------- 128
(1 row) # 2、所有会话同时执行并行计算的并行度足够大
postgres=# set max_parallel_workers=64;
SET # 3、单个QUERY中并行计算NODE开启的WORKER=16
postgres=# set max_parallel_workers_per_gather =16;
SET # 4、所有表和索引扫描允许并行
postgres=# set min_parallel_table_scan_size =0;
SET
postgres=# set min_parallel_index_scan_size =0;
SET # 5、并行计算优化器成本设置为0
postgres=# set parallel_tuple_cost =0;
SET
postgres=# set parallel_setup_cost =0;
SET # 6、设置表级并行度为2
postgres=# alter table test set (parallel_workers =2);
ALTER TABLE # 7、执行结果
test=# explain (analyze) select count(*) from test;QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------
----Finalize Aggregate (cost=107.10..107.11 rows=1 width=8) (actual time=13.974..15.860 rows=1 loops=1)-> Gather (cost=107.08..107.09 rows=2 width=8) (actual time=9.101..15.841 rows=3 loops=1)Workers Planned: 2Workers Launched: 2-> Partial Aggregate (cost=107.08..107.09 rows=1 width=8) (actual time=2.609..2.610 rows=1 loops=3)-> Parallel Seq Scan on test (cost=0.00..96.67 rows=4167 width=0) (actual time=0.026..1.645 rows=3333 loops
=3)Planning Time: 1.899 msExecution Time: 16.046 ms
(8 rows)
max_parallel_workers_per_gather 参数控制执行节点的最大并行进程数,通过以上并行计划可知,开启并行后,会启动两个 worker 进程(即 Workers Launched: 2)并行执行
2. 建表
drop table test;
create table test(a int, b int, c int);
create index ii on test(b);
insert into test valuers(generate_series(1, 10000), generate_series(1, 10000), generate_series(1, 10000);
analyze test;
vacuum full test;
3. pg并行概述参考连接
https://developer.aliyun.com/article/684431
并行扫描的理念很朴素,即启动多个 worker 并行扫描表中的数据。以前一个进程做所有的事情,无人争抢,也无需配合,如今多个 worker 并行扫描,首先需要解决如何分工的问题。
PostgreSQL 中的并行扫描分配策略也很直观,即 block-by-block。多个进程间(leader 和 worker)维护一个全局指针 next,指向下一个需要扫描的 block,一旦某个进程需要获取一个 block,则访问该指针,获取 block 并将指针向前移动。
目前支持并行的常用扫描算子有:SeqScan,IndexScan,BitmapHeapScan 以及 IndexOnlyScan。
下图分别是并行 SeqScan(左)和 并行 IndexScan(右)的原理示意图,可见两者均维护一个 next 指针,不同的是 SeqScan 指向下一个需要扫描的 block,而 IndexScan 指向下一个索引叶子节点。
注意,目前并行 IndexScan 仅支持 B-tree 索引。
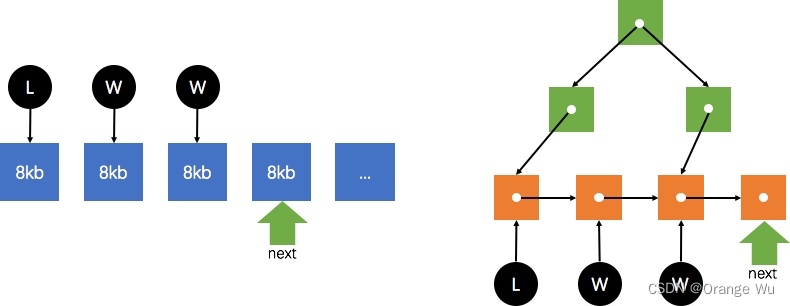
并行 IndexOnlyScan 的原理类似,只是无需根据索引页去查询数据页,从索引页中即可获取到需要的数据;并行 BitmapHeapScan 同样维护一个 next 指针,从下层 BitmapIndexScan 节点构成的位图中依次分配需要扫描的 block。
个人理解:这里实现并行的核心主要是多个线程如何处理这个全局的next指针。
后续计划对这部分的源码进行单步调试进行原理的学习。






![java八股文面试[数据库]——慢查询优化](https://img-blog.csdnimg.cn/d54656a3210248848f295102f83265f2.png)

![java八股文面试[多线程]——一个线程两次调用start()方法会出现什么情况](https://img-blog.csdnimg.cn/433801aff16c43ee896495714eeebe64.png)