目录
一、什么是core dump?
二、coredump是怎么来的?
三、怎么限制coredump文件的产生?
ulimit
半永久限制
永久限制
四、从源码分析如何对coredump文件的名字和路径管理
命名
管理
一些问题的答案
1、为什么新的ubuntu不能产生coredump了,需要手动管理?
2、systemd是什么时候出现在ubuntu中的?
3、为什么使用脚本管理coredump后ulimit就不能限制coredump文件的大小了。
4、为什么ulimit限制的大小并不准确?
5、使用脚本就没办法限制coredump的大小了嘛?
6、ubuntu现在对coredump文件的管理方式
一、什么是core dump?
core dump是Linux应用程序调试的一种有效方式,core dump又称为“核心转储”,是该进程实际使用的物理内存的“快照”。分析core dump文件可以获取应用程序崩溃时的现场信息,如程序运行时的CPU寄存器值、堆栈指针、栈数据、函数调用栈等信息。在嵌入式系统开发中是开发人员调试所需必备材料之一。每当程序异常行为产生coredump时我们就可以利用gdb工具去查看程序崩溃的原因。
二、coredump是怎么来的?
Core dump是Linux基于信号实现的。Linux中信号是一种异步事件处理机制,每种信号都对应有默认的异常处理操作,默认操作包括忽略该信号(Ignore)、暂停进程(Stop)、终止进程(Terminate)、终止并产生core dump(Core)等。
| Signal | Value | Action | Comment |
| SIGHUP | 1 | Term | Hangup detected on controlling terminal or death of controlling process |
| SIGINT | 2 | Term | Interrupt from keyboard |
| SIGQUIT | 3 | Core | Quit from keyboard |
| SIGILL | 4 | Core | Illegal Instruction |
| SIGTRAP | 5 | Core | Trace/breakpoint trap |
| SIGABRT | 6 | Core | Abort signal from abort(3) |
| SIGIOT | 6 | Core | IOT trap. A synonym for SIGABRT |
| SIGEMT | 7 | Term | |
| SIGFPE | 8 | Core | Floating point exception |
| SIGKILL | 9 | Term | Kill signal, cannot be caught, blocked or ignored. |
| SIGBUS | 10,7,10 | Core | Bus error (bad memory access) |
| SIGSEGV | 11 | Core | Invalid memory reference |
| SIGPIPE | 13 | Term | Broken pipe: write to pipe with no readers |
| SIGALRM | 14 | Term | Timer signal from alarm(2) |
| SIGTERM | 15 | Term | Termination signal |
| SIGUSR1 | 30,10,16 | Term | User-defined signal 1 |
| SIGUSR2 | 31,12,17 | Term | User-defined signal 2 |
| SIGCHLD | 20,17,18 | Ign | Child stopped or terminated |
| SIGCONT | 19,18,25 | Cont | Continue if stopped |
| SIGSTOP | 17,19,23 | Stop | Stop process, cannot be caught, blocked or ignored. |
| SIGTSTP | 18,20,24 | Stop | Stop typed at terminal |
| SIGTTIN | 21,21,26 | Stop | Terminal input for background process |
| SIGTTOU | 22,22,27 | Stop | Terminal output for background process |
| SIGIO | 23,29,22 | Term | I/O now possible (4.2BSD) |
| SIGPOLL | Term | Pollable event (Sys V). Synonym for SIGIO | |
| SIGPROF | 27,27,29 | Term | Profiling timer expired |
| SIGSYS | 12,31,12 | Core | Bad argument to routine (SVr4) |
| SIGURG | 16,23,21 | Ign | Urgent condition on socket (4.2BSD) |
| SIGVTALRM | 26,26,28 | Term | Virtual alarm clock (4.2BSD) |
| SIGXCPU | 24,24,30 | Core | CPU time limit exceeded (4.2BSD) |
| SIGXFSZ | 25,25,31 | Core | File size limit exceeded (4.2BSD) |
| SIGSTKFLT | 16 | Term | Stack fault on coprocessor (unused) |
| SIGCLD | 18 | Ign | A synonym for SIGCHLD |
| SIGPWR | 29,30,19 | Term | Power failure (System V) |
| SIGINFO | 29 | A synonym for SIGPWR, on an alpha | |
| SIGLOST | 29 | Term | File lock lost (unused), on a sparc |
| SIGWINCH | 28,28,20 | Ign | Window resize signal (4.3BSD, Sun) |
| SIGUNUSED | 31 | Core | Synonymous with SIGSYS |
以下情况会出现应用程序崩溃导致产生core dump:
- 内存访问越界 (数组越界、字符串无\n结束符、字符串读写越界)
- 多线程程序中使用了线程不安全的函数,如不可重入函数
- 多线程读写的数据未加锁保护(临界区资源需要互斥访问)
- 非法指针(如空指针异常或者非法地址访问)
- 堆栈溢出
三、怎么限制coredump文件的产生?
ulimit
说到限制就不得不提到ulimit工具了,这个工具其实有个坑,他并不是linux自带的工具,而是shell工具,也就是说他的级别是shell层的。
当我们新开启一个终端后之前终端的全部配置都会消失,并且他还看人下菜碟,每个linux用设置的都是自己的ulimit,比如你有两个用户,在同一个终端下对当前终端配置
一个 ulimit -c 1024
一个ulimit -c 2048
他们的限制都作用在各自的范围
即便同一个目录的同一个文件,本来这个coredump可以产生4096k个字节那么a的coredump就是1024,b的就是2048当然,不会很准确的限制,后面会从源码上给大家说明为什么。
还有就是可以通过配置文件,但是这个优先级虽然高但是可以改,这个文件只在重启时被读取一次,后面其它人再来改这个限制你之前的限制也就无效了。
半永久限制
vim /etc/profile
相当于每开一个shell时,自动执行ulimit -c unlimited(表示无限制其它具体数字通常表示多少k)

永久限制
编辑/etc/security/limits.conf,需要重新登录,或者重新打开ssh客户端连接,永久生效
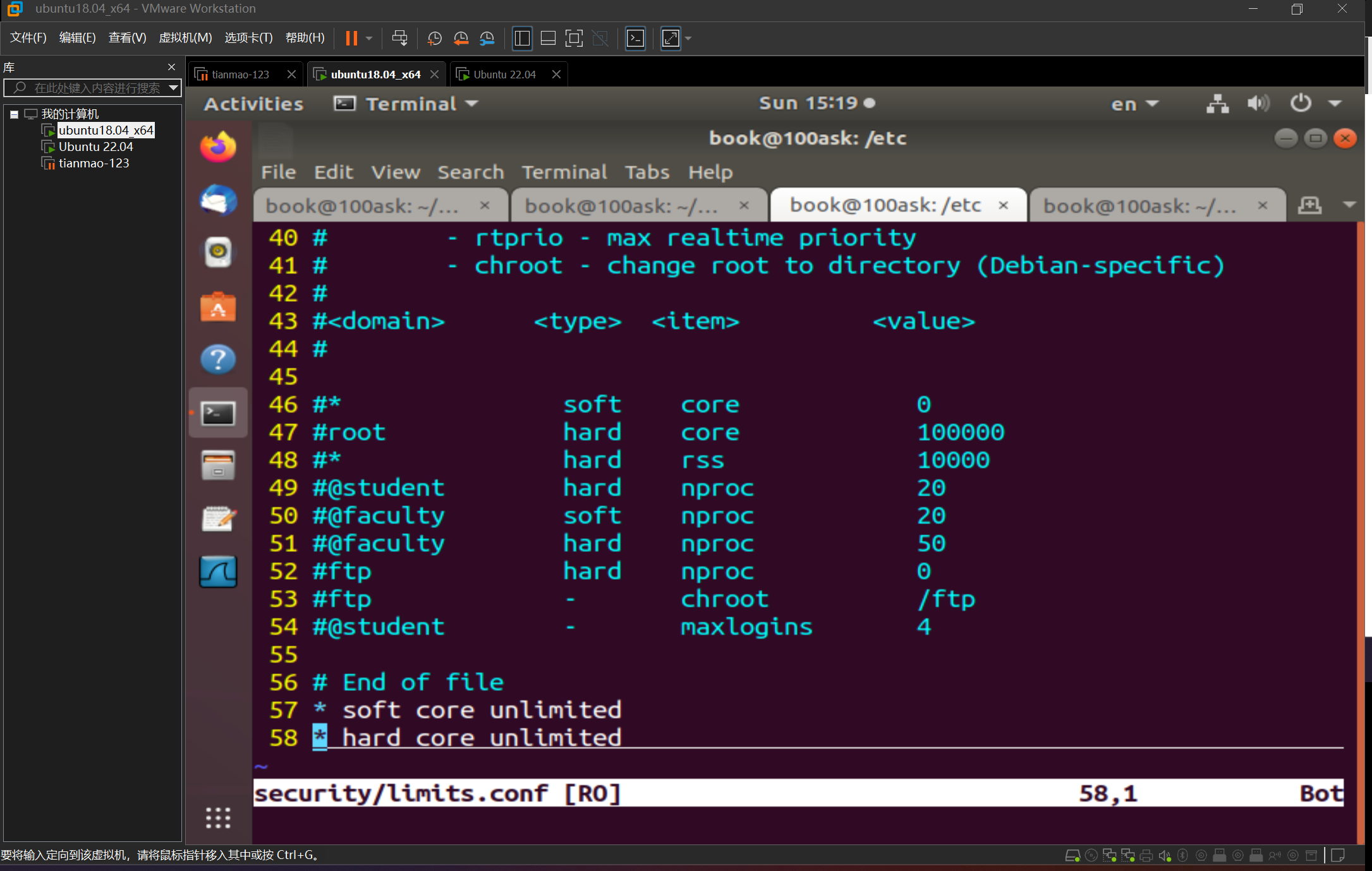
下面就是软限制和硬限制
四、从源码分析如何对coredump文件的名字和路径管理
命名

在/etc/sysctrl.conf中保存的是用户给内核传递的参数,这里有个core_pattern参数是告诉内核怎么管理coredump的。
后面直接写等号就表示这个coredump文件的命名
%% 单个%字符
%p 所dump进程的进程ID
%u 所dump进程的实际用户ID
%g 所dump进程的实际组ID
%s 导致本次core dump的信号
%t core dump的时间 (由1970年1月1日计起的秒数)
%h 主机名
%e 程序文件名
管理
kernel.core_pattern=|/usr/bin/coredump_helper.sh core_%e_%I_%p_sig_%s_time_%t.gz
像上面那样配置core_pattern后内核就可以使用我们指定的脚本去管理coredump文件了。
这个路径必须是绝对路径,前面必须是|前后都不能有空格,coredump文件会作为参数传入脚本。
这里我直接将文件以压缩格式传递给了脚本
#!/bin/shif [ ! -d "/var/coredump" ];thenmkdir -p /var/coredump
fi
gzip > "/var/coredump/$1"上面的代码就是一个简单的示例可以把coredump都放到var下的coredump目录中,我们还可以添加一些遍历判断操作限制产生coredump的数量的单个coredump的大小。
#!/bin/bash # Set the maximum number of files allowed in /var/coredump
max_files=1000 # Check if /var/coredump directory exists
if [ ! -d "/var/coredump" ]; then mkdir -p /var/coredump
fi # Get the current number of files in /var/coredump
current_files=$(ls -1 /var/coredump | wc -l) # Check if the number of files exceeds the maximum limit
if [ $current_files -ge $max_files ]; then # Sort the files based on creation time (oldest first) sorted_files=$(ls -1t /var/coredump | head -n 1) # Remove the oldest files to reduce the number of files to below the limit rm $sorted_files
fi # Compress the file and store it in /var/coredump using gzip
gzip > "/var/coredump/$1"代码很简陋正常还要有出错管理,异常情况打印到日志备份等等。
一些问题的答案
1、为什么新的ubuntu不能产生coredump了,需要手动管理?
因为现在的ubuntu使用的是systemd,在这里有些服务会对内核管理coredump的接口做配置,导致coredump文件被服务写到接口的脚本管理了。
2、systemd是什么时候出现在ubuntu中的?
systemd是在Ubuntu 15.04版本中首次出现的。在此之前,Ubuntu使用Upstart作为默认的init系统。然而,从Ubuntu 15.04开始,Ubuntu采用了systemd作为默认的init系统和服务管理器。systemd是一个用于启动、停止和管理系统进程的软件套件,它提供了更快的启动速度、更好的系统资源管理和更强大的服务控制能力。
而在Upstart之前用的才是SysVinit。
3、为什么使用脚本管理coredump后ulimit就不能限制coredump文件的大小了。
这个问题就要看源码了
void do_coredump(const siginfo_t *siginfo)
{struct core_state core_state;struct core_name cn;struct mm_struct *mm = current->mm;struct linux_binfmt * binfmt;const struct cred *old_cred;struct cred *cred;int retval = 0;int flag = 0;int ispipe;struct files_struct *displaced;bool need_nonrelative = false;bool core_dumped = false;static atomic_t core_dump_count = ATOMIC_INIT(0);struct coredump_params cprm = {.siginfo = siginfo,.regs = signal_pt_regs(),.limit = rlimit(RLIMIT_CORE),/** We must use the same mm->flags while dumping core to avoid* inconsistency of bit flags, since this flag is not protected* by any locks.*/.mm_flags = mm->flags,};audit_core_dumps(siginfo->si_signo);binfmt = mm->binfmt;if (!binfmt || !binfmt->core_dump)goto fail;if (!__get_dumpable(cprm.mm_flags))goto fail;cred = prepare_creds();if (!cred)goto fail;/** We cannot trust fsuid as being the "true" uid of the process* nor do we know its entire history. We only know it was tainted* so we dump it as root in mode 2, and only into a controlled* environment (pipe handler or fully qualified path).*/if (__get_dumpable(cprm.mm_flags) == SUID_DUMP_ROOT) {/* Setuid core dump mode */flag = O_EXCL; /* Stop rewrite attacks */cred->fsuid = GLOBAL_ROOT_UID; /* Dump root private */need_nonrelative = true;}retval = coredump_wait(siginfo->si_signo, &core_state);if (retval < 0)goto fail_creds;old_cred = override_creds(cred);ispipe = format_corename(&cn, &cprm);if (ispipe) {int dump_count;char **helper_argv;struct subprocess_info *sub_info;if (ispipe < 0) {printk(KERN_WARNING "format_corename failed\n");printk(KERN_WARNING "Aborting core\n");goto fail_unlock;}if (cprm.limit == 1) {/* See umh_pipe_setup() which sets RLIMIT_CORE = 1.** Normally core limits are irrelevant to pipes, since* we're not writing to the file system, but we use* cprm.limit of 1 here as a speacial value, this is a* consistent way to catch recursive crashes.* We can still crash if the core_pattern binary sets* RLIM_CORE = !1, but it runs as root, and can do* lots of stupid things.** Note that we use task_tgid_vnr here to grab the pid* of the process group leader. That way we get the* right pid if a thread in a multi-threaded* core_pattern process dies.*/printk(KERN_WARNING"Process %d(%s) has RLIMIT_CORE set to 1\n",task_tgid_vnr(current), current->comm);printk(KERN_WARNING "Aborting core\n");goto fail_unlock;}cprm.limit = RLIM_INFINITY;dump_count = atomic_inc_return(&core_dump_count);if (core_pipe_limit && (core_pipe_limit < dump_count)) {printk(KERN_WARNING "Pid %d(%s) over core_pipe_limit\n",task_tgid_vnr(current), current->comm);printk(KERN_WARNING "Skipping core dump\n");goto fail_dropcount;}helper_argv = argv_split(GFP_KERNEL, cn.corename, NULL);if (!helper_argv) {printk(KERN_WARNING "%s failed to allocate memory\n",__func__);goto fail_dropcount;}retval = -ENOMEM;sub_info = call_usermodehelper_setup(helper_argv[0],helper_argv, NULL, GFP_KERNEL,umh_pipe_setup, NULL, &cprm);if (sub_info)retval = call_usermodehelper_exec(sub_info,UMH_WAIT_EXEC);argv_free(helper_argv);if (retval) {printk(KERN_INFO "Core dump to |%s pipe failed\n",cn.corename);goto close_fail;}} else {struct inode *inode;if (cprm.limit < binfmt->min_coredump)goto fail_unlock;if (need_nonrelative && cn.corename[0] != '/') {printk(KERN_WARNING "Pid %d(%s) can only dump core "\"to fully qualified path!\n",task_tgid_vnr(current), current->comm);printk(KERN_WARNING "Skipping core dump\n");goto fail_unlock;}cprm.file = filp_open(cn.corename,O_CREAT | 2 | O_NOFOLLOW | O_LARGEFILE | flag,0600);if (IS_ERR(cprm.file))goto fail_unlock;inode = file_inode(cprm.file);if (inode->i_nlink > 1)goto close_fail;if (d_unhashed(cprm.file->f_path.dentry))goto close_fail;/** AK: actually i see no reason to not allow this for named* pipes etc, but keep the previous behaviour for now.*/if (!S_ISREG(inode->i_mode))goto close_fail;/** Dont allow local users get cute and trick others to coredump* into their pre-created files.*/if (!uid_eq(inode->i_uid, current_fsuid()))goto close_fail;if (!cprm.file->f_op->write)goto close_fail;if (do_truncate(cprm.file->f_path.dentry, 0, 0, cprm.file))goto close_fail;}/* get us an unshared descriptor table; almost always a no-op */retval = unshare_files(&displaced);if (retval)goto close_fail;if (displaced)put_files_struct(displaced);if (!dump_interrupted()) {file_start_write(cprm.file);core_dumped = binfmt->core_dump(&cprm);file_end_write(cprm.file);}if (ispipe && core_pipe_limit)wait_for_dump_helpers(cprm.file);
close_fail:if (cprm.file)filp_close(cprm.file, NULL);
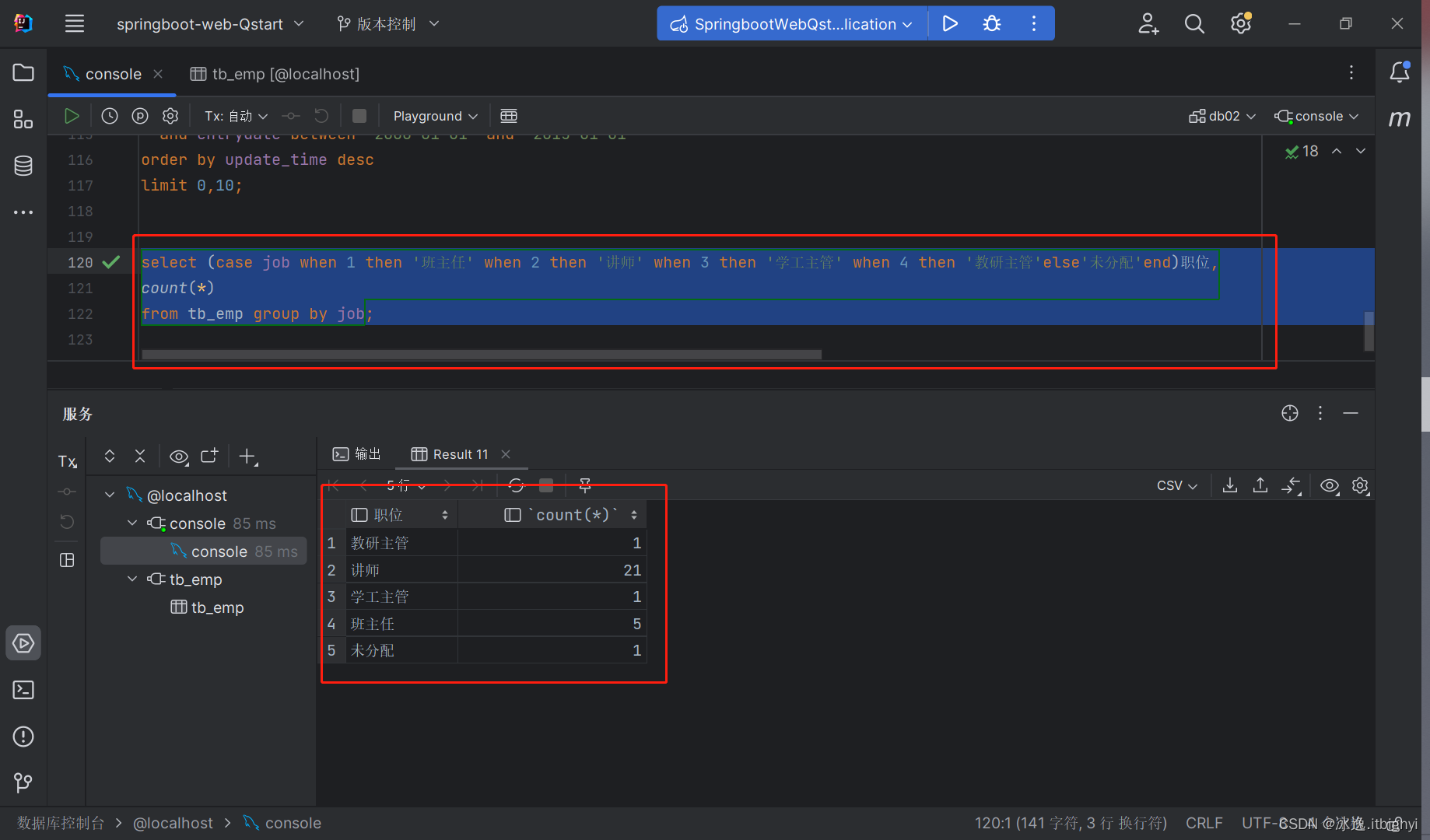
fail_dropcount:if (ispipe)atomic_dec(&core_dump_count);
fail_unlock:kfree(cn.corename);coredump_finish(mm, core_dumped);revert_creds(old_cred);
fail_creds:put_cred(cred);
fail:return;
}从源码中可以看到在产生coredump的源码中会对上面的core_pattern进行判断,如果传入了脚本就会走上面的分支,没传入走下面的分支,上面只判断了limit是不是1,1表示不产生coredump,如果不是1就赋值为0,0就是没有限制。

而下面有这个判断,当已经产生的coredump文件超过ulimit -c的限制时就会停止产生。有一个点需要注意,ulimit-c和这里的limit不是完全对应的,是在shell源码中有转化的,不过大体上还是对应的。
4、为什么ulimit限制的大小并不准确?
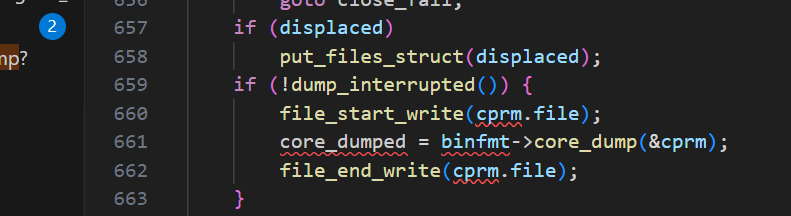
还是要看这张图,它每次写入的都是内核设计好的,就写这些。
在外面有个for循环调用do_coredump文件.
int get_signal_to_deliver(siginfo_t *info, struct k_sigaction *return_ka,struct pt_regs *regs, void *cookie)
{struct sighand_struct *sighand = current->sighand;struct signal_struct *signal = current->signal;int signr;if (unlikely(current->task_works))task_work_run();if (unlikely(uprobe_deny_signal()))return 0;/** Do this once, we can't return to user-mode if freezing() == T.* do_signal_stop() and ptrace_stop() do freezable_schedule() and* thus do not need another check after return.*/try_to_freeze();relock:spin_lock_irq(&sighand->siglock);/** Every stopped thread goes here after wakeup. Check to see if* we should notify the parent, prepare_signal(SIGCONT) encodes* the CLD_ si_code into SIGNAL_CLD_MASK bits.*/if (unlikely(signal->flags & SIGNAL_CLD_MASK)) {int why;if (signal->flags & SIGNAL_CLD_CONTINUED)why = CLD_CONTINUED;elsewhy = CLD_STOPPED;signal->flags &= ~SIGNAL_CLD_MASK;spin_unlock_irq(&sighand->siglock);/** Notify the parent that we're continuing. This event is* always per-process and doesn't make whole lot of sense* for ptracers, who shouldn't consume the state via* wait(2) either, but, for backward compatibility, notify* the ptracer of the group leader too unless it's gonna be* a duplicate.*/read_lock(&tasklist_lock);do_notify_parent_cldstop(current, false, why);if (ptrace_reparented(current->group_leader))do_notify_parent_cldstop(current->group_leader,true, why);read_unlock(&tasklist_lock);goto relock;}for (;;) {struct k_sigaction *ka;if (unlikely(current->jobctl & JOBCTL_STOP_PENDING) &&do_signal_stop(0))goto relock;if (unlikely(current->jobctl & JOBCTL_TRAP_MASK)) {do_jobctl_trap();spin_unlock_irq(&sighand->siglock);goto relock;}signr = dequeue_signal(current, ¤t->blocked, info);if (!signr)break; /* will return 0 */if (unlikely(current->ptrace) && signr != SIGKILL) {signr = ptrace_signal(signr, info);if (!signr)continue;}ka = &sighand->action[signr-1];/* Trace actually delivered signals. */trace_signal_deliver(signr, info, ka);if (ka->sa.sa_handler == SIG_IGN) /* Do nothing. */continue;if (ka->sa.sa_handler != SIG_DFL) {/* Run the handler. */*return_ka = *ka;if (ka->sa.sa_flags & SA_ONESHOT)ka->sa.sa_handler = SIG_DFL;break; /* will return non-zero "signr" value */}/** Now we are doing the default action for this signal.*/if (sig_kernel_ignore(signr)) /* Default is nothing. */continue;/** Global init gets no signals it doesn't want.* Container-init gets no signals it doesn't want from same* container.** Note that if global/container-init sees a sig_kernel_only()* signal here, the signal must have been generated internally* or must have come from an ancestor namespace. In either* case, the signal cannot be dropped.*/if (unlikely(signal->flags & SIGNAL_UNKILLABLE) &&!sig_kernel_only(signr))continue;if (sig_kernel_stop(signr)) {/** The default action is to stop all threads in* the thread group. The job control signals* do nothing in an orphaned pgrp, but SIGSTOP* always works. Note that siglock needs to be* dropped during the call to is_orphaned_pgrp()* because of lock ordering with tasklist_lock.* This allows an intervening SIGCONT to be posted.* We need to check for that and bail out if necessary.*/if (signr != SIGSTOP) {spin_unlock_irq(&sighand->siglock);/* signals can be posted during this window */if (is_current_pgrp_orphaned())goto relock;spin_lock_irq(&sighand->siglock);}if (likely(do_signal_stop(info->si_signo))) {/* It released the siglock. */goto relock;}/** We didn't actually stop, due to a race* with SIGCONT or something like that.*/continue;}spin_unlock_irq(&sighand->siglock);/** Anything else is fatal, maybe with a core dump.*/current->flags |= PF_SIGNALED;if (sig_kernel_coredump(signr)) {if (print_fatal_signals)print_fatal_signal(info->si_signo);proc_coredump_connector(current);/** If it was able to dump core, this kills all* other threads in the group and synchronizes with* their demise. If we lost the race with another* thread getting here, it set group_exit_code* first and our do_group_exit call below will use* that value and ignore the one we pass it.*/do_coredump(info);}/** Death signals, no core dump.*/do_group_exit(info->si_signo);/* NOTREACHED */}spin_unlock_irq(&sighand->siglock);return signr;
}哪次判断超出了就会停止生成.
5、使用脚本就没办法限制coredump的大小了嘛?
可以的,但是limit这个系统调用肯定是不行了,源码中我们就看到了人家都不鸟你。但是我们可以ulimit -f,这个脚本coredump文件从内核态到用户态是通过这个传入的脚本,所以直接ulimit -f限制脚本生成的全部文件大小就ok了,但是这里要写成正常两倍大小因为是先获取在写入,我们一个字节计算两次,这次限制的大小就完全准确了,也有个坏处就是文件会损坏限制住了也没法去看这个coredump。
6、ubuntu现在对coredump文件的管理方式
由于使用systemd机制,所以现在的coredump是以服务的方式存在的,为了可以更好的保存和规范化管理,coredump内容被放到了日志中,使用coredump@和socket服务共同实现,将coredump文件从内核态转移到用户态后又用了socket机制做过滤和写入日志。完美限制大小和内容。只要日志管理的好可以想看任何时候的有用的coredump。
---------------------------------------------------------------------------------------------------------------------------------
这是我工作中遇到的第一个做了两周的问题的一部分,当时贼痛苦各种查资料翻源码,好在最后想到了还算不错的解决方案,工作的提升是真的大,不止是技术,主要是团队写作能力,做事情的条例,规范化做事才会少出错。这些很重要。还有表达能力,不然你写的永远都是垃圾。下周有时间更新另一半,日志的管理。