文章目录
- 概要
- 初始化
- 消息发送
- 小结
概要
本文主要概括Spring Kafka生产者发送消息的主流程
代码准备:
SpringBoot项目中maven填加以下依赖
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.12.RELEASE</version><relativePath/> <!-- lookup parent from repository -->
</parent>
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>
消息发送使用KafkaTemplate
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;@GetMapping("/test/send/{msg}")
public String sendMsg(@PathVariable String msg) {kafkaTemplate.send("alai_test", msg);return "success";
}
初始化
启动类KafkaAutoConfiguration
有两个地方需要关注
@Bean
@ConditionalOnMissingBean({KafkaTemplate.class})
public KafkaTemplate<?, ?> kafkaTemplate(ProducerFactory<Object, Object> kafkaProducerFactory, ProducerListener<Object, Object> kafkaProducerListener) {KafkaTemplate<Object, Object> kafkaTemplate = new KafkaTemplate(kafkaProducerFactory);if (this.messageConverter != null) {kafkaTemplate.setMessageConverter(this.messageConverter);}kafkaTemplate.setProducerListener(kafkaProducerListener);kafkaTemplate.setDefaultTopic(this.properties.getTemplate().getDefaultTopic());return kafkaTemplate;
}@Bean
@ConditionalOnMissingBean({ProducerFactory.class})
public ProducerFactory<?, ?> kafkaProducerFactory() {DefaultKafkaProducerFactory<?, ?> factory = new DefaultKafkaProducerFactory(this.properties.buildProducerProperties());String transactionIdPrefix = this.properties.getProducer().getTransactionIdPrefix();if (transactionIdPrefix != null) {factory.setTransactionIdPrefix(transactionIdPrefix);}return factory;
}
其中的ProducerFactory使用的是DefaultKafkaProducerFactory
在发送消息之前,Spring Kafka会先创建Producer,返回的是CloseSafeProducer实现类,在该类中有一个委托类Producer<K, V> delegate,真正的发送消息处理逻辑委托给KafkaProducer,KafkaProducer实例构造如下,边幅原因,这里只展示需要说明的部分
KafkaProducer(Map<String, Object> configs,Serializer<K> keySerializer,Serializer<V> valueSerializer,ProducerMetadata metadata,KafkaClient kafkaClient,ProducerInterceptors<K, V> interceptors,Time time) {ProducerConfig config = new ProducerConfig(ProducerConfig.addSerializerToConfig(configs, keySerializer,valueSerializer));try {Map<String, Object> userProvidedConfigs = config.originals();this.producerConfig = config;this.time = time;String transactionalId = userProvidedConfigs.containsKey(ProducerConfig.TRANSACTIONAL_ID_CONFIG) ?(String) userProvidedConfigs.get(ProducerConfig.TRANSACTIONAL_ID_CONFIG) : null;this.clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);LogContext logContext;if (transactionalId == null)logContext = new LogContext(String.format("[Producer clientId=%s] ", clientId));elselogContext = new LogContext(String.format("[Producer clientId=%s, transactionalId=%s] ", clientId, transactionalId));log = logContext.logger(KafkaProducer.class);log.trace("Starting the Kafka producer");Map<String, String> metricTags = Collections.singletonMap("client-id", clientId);MetricConfig metricConfig = new MetricConfig().samples(config.getInt(ProducerConfig.METRICS_NUM_SAMPLES_CONFIG)).timeWindow(config.getLong(ProducerConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS).recordLevel(Sensor.RecordingLevel.forName(config.getString(ProducerConfig.METRICS_RECORDING_LEVEL_CONFIG))).tags(metricTags);List<MetricsReporter> reporters = config.getConfiguredInstances(ProducerConfig.METRIC_REPORTER_CLASSES_CONFIG,MetricsReporter.class,Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId));reporters.add(new JmxReporter(JMX_PREFIX));this.metrics = new Metrics(metricConfig, reporters, time);this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);if (keySerializer == null) {this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,Serializer.class);this.keySerializer.configure(config.originals(), true);} else {config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);this.keySerializer = keySerializer;}if (valueSerializer == null) {this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,Serializer.class);this.valueSerializer.configure(config.originals(), false);} else {config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);this.valueSerializer = valueSerializer;}// load interceptors and make sure they get clientIduserProvidedConfigs.put(ProducerConfig.CLIENT_ID_CONFIG, clientId);ProducerConfig configWithClientId = new ProducerConfig(userProvidedConfigs, false);List<ProducerInterceptor<K, V>> interceptorList = (List) configWithClientId.getConfiguredInstances(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, ProducerInterceptor.class);// 生产者拦截器 if (interceptors != null)this.interceptors = interceptors;elsethis.interceptors = new ProducerInterceptors<>(interceptorList);ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keySerializer,valueSerializer, interceptorList, reporters);// 生产者往服务端发送消息的时候,规定一条消息最大多大?// 如果你超过了这个规定消息的大小,你的消息就不能发送过去。// 默认是1M,这个值偏小,在生产环境中,我们需要修改这个值。// 经验值是10M。但是大家也可以根据自己公司的情况来。 this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);//指的是缓存大小//默认值是32M,这个值一般是够用,如果有特殊情况的时候,我们可以去修改这个值。this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);// kafka是支持压缩数据的,可以设置压缩格式,默认是不压缩,支持gzip、snappy、lz4// 一次发送出去的消息就更多。生产者这儿会消耗更多的cpu.this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));// 配置控制了KafkaProducer.send()并将KafkaProducer.partitionsFor()被阻塞多长时间,由于缓冲区已满或元数据不可用,这些方法可// 能会被阻塞止this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);int deliveryTimeoutMs = configureDeliveryTimeout(config, log);this.apiVersions = new ApiVersions();this.transactionManager = configureTransactionState(config, logContext);// 创建核心组件:记录累加器this.accumulator = new RecordAccumulator(logContext,config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),this.compressionType,lingerMs(config),retryBackoffMs,deliveryTimeoutMs,metrics,PRODUCER_METRIC_GROUP_NAME,time,apiVersions,transactionManager,new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME));List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG),config.getString(ProducerConfig.CLIENT_DNS_LOOKUP_CONFIG));if (metadata != null) {this.metadata = metadata;} else {// 生产者每隔一段时间都要去更新一下集群的元数据,默认5分钟this.metadata = new ProducerMetadata(retryBackoffMs,config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),config.getLong(ProducerConfig.METADATA_MAX_IDLE_CONFIG),logContext,clusterResourceListeners,Time.SYSTEM);this.metadata.bootstrap(addresses);}this.errors = this.metrics.sensor("errors");// 真正执行消息发送的逻辑this.sender = newSender(logContext, kafkaClient, this.metadata);String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;this.ioThread = new KafkaThread(ioThreadName, this.sender, true);// 开启新的线程this.ioThread.start();config.logUnused();AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());log.debug("Kafka producer started");} catch (Throwable t) {// call close methods if internal objects are already constructed this is to prevent resource leak. see KAFKA-2121close(Duration.ofMillis(0), true);// now propagate the exceptionthrow new KafkaException("Failed to construct kafka producer", t);}}
创建Sender时的方法如下:
// visible for testing
Sender newSender(LogContext logContext, KafkaClient kafkaClient, ProducerMetadata metadata) {// 使用幂等性,需要将 enable.idempotence 配置项设置为true。并且它对单个分区的发送,一次性最多发送5条int maxInflightRequests = producerConfig.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION);// 控制客户端等待请求响应的最长时间。如果在超时过去之前未收到响应,客户端将// 在必要时重新发送请求,或者如果重试耗尽,请求失败int requestTimeoutMs = producerConfig.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(producerConfig, time, logContext);ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);// 初始化了一个重要的管理网路的组件
// connections.max.idle.ms: 默认值是9分钟, 一个网络连接最多空闲多久,超过这个空闲时间,就关闭这个网络连接。
// max.in.flight.requests.per.connection:默认是5, producer向broker发送数据的时候,其实是有多个网络连接。每个网络连接可以忍受 producer端发送给broker 消息然后消息没有响应的个数KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(new Selector(producerConfig.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),this.metrics, time, "producer", channelBuilder, logContext),metadata,clientId,maxInflightRequests,producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),producerConfig.getInt(ProducerConfig.SEND_BUFFER_CONFIG),producerConfig.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),requestTimeoutMs,producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),time,true,apiVersions,throttleTimeSensor,logContext);short acks = Short.parseShort(producerConfig.getString(ProducerConfig.ACKS_CONFIG));return new Sender(logContext,client,metadata,this.accumulator,maxInflightRequests == 1,producerConfig.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),acks,producerConfig.getInt(ProducerConfig.RETRIES_CONFIG), // 重试次数metricsRegistry.senderMetrics,time,requestTimeoutMs,producerConfig.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),this.transactionManager,apiVersions);
}
在创建RecordAccumulator时,其内部会维护一个ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches ,该Map的key是TopicPartition,这个类重写了equals方法,相同的topic,相同的分区,在batches中属于相同的key,就会被放入到队列Deque中。
消息发送
Spring Kafka对消息的发送,最后也是直接委托给了org.apache.kafka.clients.producer.KafkaProducer#doSend方法,下面以这个方法作为入口进行分析
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {// intercept the record, which can be potentially modified; this method does not throw exceptionsProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);return doSend(interceptedRecord, callback);
}
拦截器
onSend 方法是遍历拦截器 onSend 方法,拦截器的目的是将数据处理加工, kafka 本身并没有给出默认的拦截器的实现。如果需要使用拦截器功能,必须自己实现 ProducerInterceptor 接口
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {ProducerRecord<K, V> interceptRecord = record;for (ProducerInterceptor<K, V> interceptor : this.interceptors) {try {interceptRecord = interceptor.onSend(interceptRecord);} catch (Exception e) {// 其中一个拦截器出现处理异常时不回抛出异常,只会打印日志// do not propagate interceptor exception, log and continue calling other interceptors// be careful not to throw exception from hereif (record != null)log.warn("Error executing interceptor onSend callback for topic: {}, partition: {}", record.topic(), record.partition(), e);elselog.warn("Error executing interceptor onSend callback", e);}}return interceptRecord;
}
ProducerInterceptor的3个方法:
onSend: Producer确保在消息被序列化以计算分区前调用该方法。用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的topic和分区,否则会影响目标分区的计算onAcknowledgement: 该方法会在消息被应答之前或消息发送失败时调用,并且通常都是在producer回调逻辑触发之前。onAcknowledgement运行在producer的IO线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢producer的消息发送效率close: 关闭interceptor,主要用于执行一些资源清理工作
消息发送主流程
/*** Implementation of asynchronously send a record to a topic.*/
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {TopicPartition tp = null;try {throwIfProducerClosed();// first make sure the metadata for the topic is availablelong nowMs = time.milliseconds();ClusterAndWaitTime clusterAndWaitTime;try {// 首先确保该topic的元数据可用clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);} catch (KafkaException e) {if (metadata.isClosed())throw new KafkaException("Producer closed while send in progress", e);throw e;}nowMs += clusterAndWaitTime.waitedOnMetadataMs;long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);Cluster cluster = clusterAndWaitTime.cluster;// 序列化 record 的 key 和 valuebyte[] serializedKey;try {serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());} catch (ClassCastException cce) {throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +" specified in key.serializer", cce);}byte[] serializedValue;try {serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());} catch (ClassCastException cce) {throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +" specified in value.serializer", cce);}// 获取该 record 要发送到的 partitionint partition = partition(record, serializedKey, serializedValue, cluster);tp = new TopicPartition(record.topic(), partition);setReadOnly(record.headers());Header[] headers = record.headers().toArray();int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),compressionType, serializedKey, serializedValue, headers);ensureValidRecordSize(serializedSize);long timestamp = record.timestamp() == null ? nowMs : record.timestamp();if (log.isTraceEnabled()) {log.trace("Attempting to append record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);}// producer callback will make sure to call both 'callback' and interceptor callbackCallback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);// 向 accumulator 中追加 record 数据,数据会先进行缓存RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);if (result.abortForNewBatch) {int prevPartition = partition;partitioner.onNewBatch(record.topic(), cluster, prevPartition);partition = partition(record, serializedKey, serializedValue, cluster);tp = new TopicPartition(record.topic(), partition);if (log.isTraceEnabled()) {log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);}// producer callback will make sure to call both 'callback' and interceptor callbackinterceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);result = accumulator.append(tp, timestamp, serializedKey,serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);}if (transactionManager != null) {transactionManager.maybeAddPartition(tp);}// 如果追加完数据后,对应的 RecordBatch 已经达到了 batch.size 的大小(或者batch 的剩余空间不足以添加下一条 Record),则唤醒 sender 线程发送数据。if (result.batchIsFull || result.newBatchCreated) {log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);this.sender.wakeup();}return result.future;} catch (ApiException e) {...}...
}
-
Producer通过waitOnMetadata()方法来获取对应 topic 的 metadata 信息,需要先该topic 是可用的 -
Producer端对record的key和value值进行序列化操作,在Consumer端再进行相应的反序列化 -
获取partition值,具体分为下面三种情况:
1 指明 partition 的情况下,直接将指明的值直接作为 partiton 值
2 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值
3 既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到partition 值,也就是常说的 round-robin 算法
4Producer默认使用的 partitioner 是org.apache.kafka.clients.producer.internals.DefaultPartitioner -
向
accumulator写数据,先将 record 写入到 buffer 中,当达到一个 batch.size 的大小时,再唤起 sender线程去发送RecordBatch,这里仔细分析一下Producer是如何向buffer写入数据的
1.获取该 topic-partition 对应的 queue,没有的话会创建一个空的 queue
2.向 queue 中追加数据,先获取 queue 中最新加入的那个RecordBatch,如果不存在或者存在但剩余空余不足以添加本条 record 则返回 null,成功写入的话直接返回结果,写入成功
3.创建一个新的RecordBatch,初始化内存大小根据max(batch.size,Records.LOG_OVERHEAD + Record.recordSize(key, value))来确定(防止单条record 过大的情况)
4.向新建的RecordBatch写入 record,并将RecordBatch添加到 queue 中,返回结果,写入成功 -
发送
RecordBatch,当 record 写入成功后,如果发现RecordBatch已满足发送的条件(通常是 queue 中有多个 batch,那么最先添加的那些 batch 肯定是可以发送了),那么就会唤醒sender 线程,发送 RecordBatch 。sender 线程对 RecordBatch 的处理是在 run() 方法中进行的,该方法具体实现如下:
1.获取那些已经可以发送的RecordBatch对应的 nodes
2.如果与node 没有连接(如果可以连接,同时初始化该连接),就证明该 node 暂时不能发送数据,暂时移除该 node
3.返回该 node 对应的所有可以发送的RecordBatch组成的 batches(key 是
node.id),并将RecordBatch从对应的 queue 中移除
4.将由于元数据不可用而导致发送超时的RecordBatch移除
5.发送RecordBatch

小结
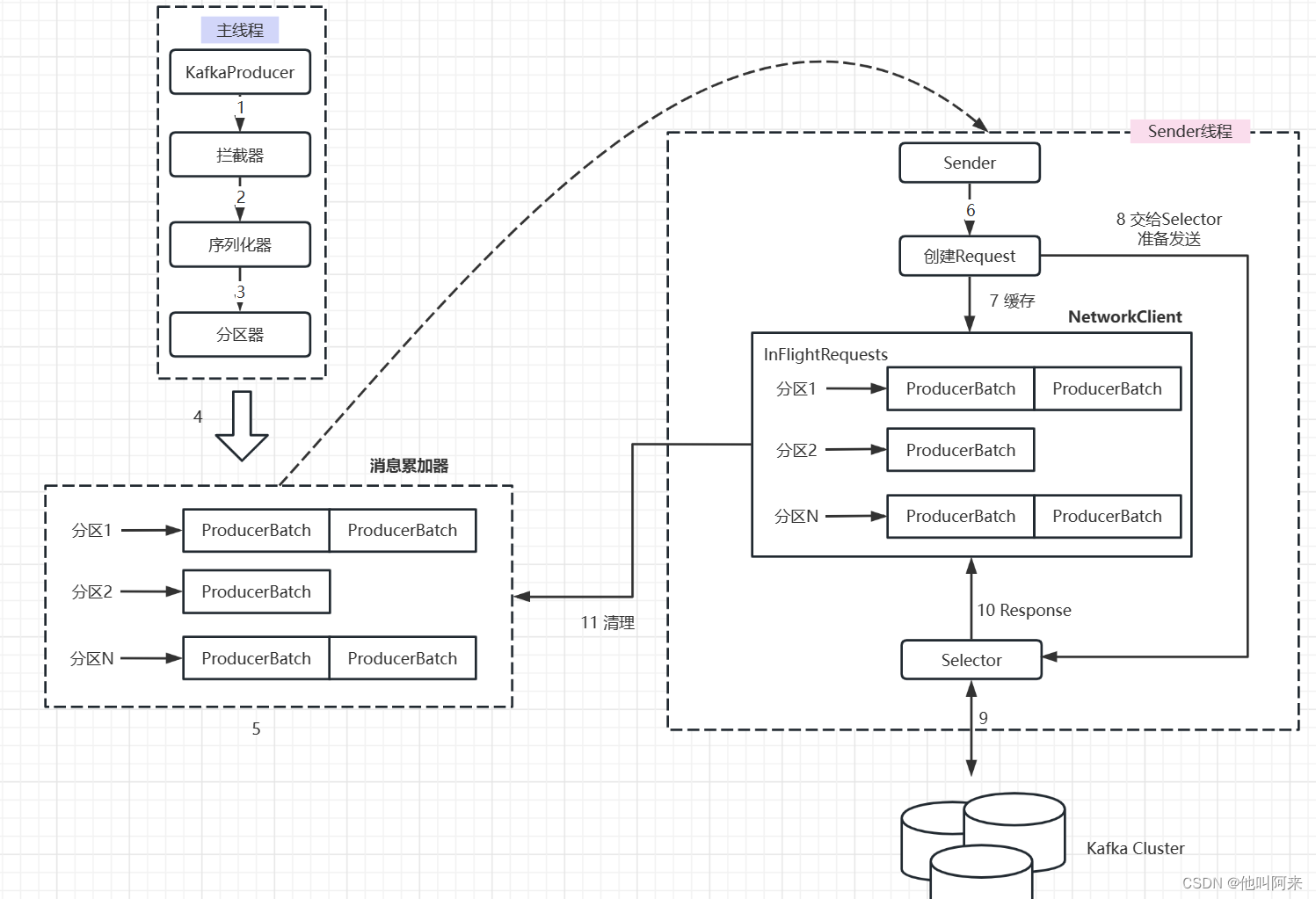
由上图可以看出:KafkaProducer有两个基本线程:
主线程:
- 负责消息创建,拦截器,序列化器,分区器等操作,并将消息追加到消息收集器
RecordAccumulator中; - RecordAccumulator
为每个分区都维护了一个Deque` 类型的双端队列。 - ProducerBatch
可以理解为是ProducerRecord` 的集合,批量发送有利于提升吞吐量,降低网络影响; - 由于生产者客户端使用
java.io.ByteBuffer在发送消息之前进行消息保存,并维护了一个BufferPool实现ByteBuffer的复用;该缓存池只针对特定大小( batch.size指定)的ByteBuffer进行管理,对于消息过大的缓存,不能做到重复利用。 - 每次追加一条
ProducerRecord消息,会寻找/新建对应的双端队列,从其尾部获取一个ProducerBatch,判断当前消息的大小是否可以写入该批次中。若可以写入则写入;若不可以写入,则新建一个ProducerBatch,判断该消息大小是否超过客户端参数配置batch.size的值,不超过,则以batch.size建立新的ProducerBatch,这样方便进行缓存重复利用;若超过,则以计算的消息大小建立对应的ProducerBatch,缺点就是该内存不能被复用了。
Sender线程:
- 该线程从消息收集器获取缓存的消息,将其处理为
<Node, List<ProducerBatch>的形式, Node 表示集群的broker节点。 - 进一步将
<Node, List<ProducerBatch>转化为<Node, Request>形式,此时才可以向服务端发送数据。 - 在发送之前,Sender线程将消息以
Map<NodeId, Deque<Request>>的形式保存到InFlightRequests中进行缓存,可以通过其获取leastLoadedNode,即当前Node中负载压力最小的一个,以实现消息的尽快发出。